脉冲强化学习总结(持续更新)
与本文相关的详细内容见脉冲强化学习算法研究综述 (ict.ac.cn)
引言
要将脉冲强化学习进行分类,首先要了解SNN学习算法以及强化学习本身的类别。
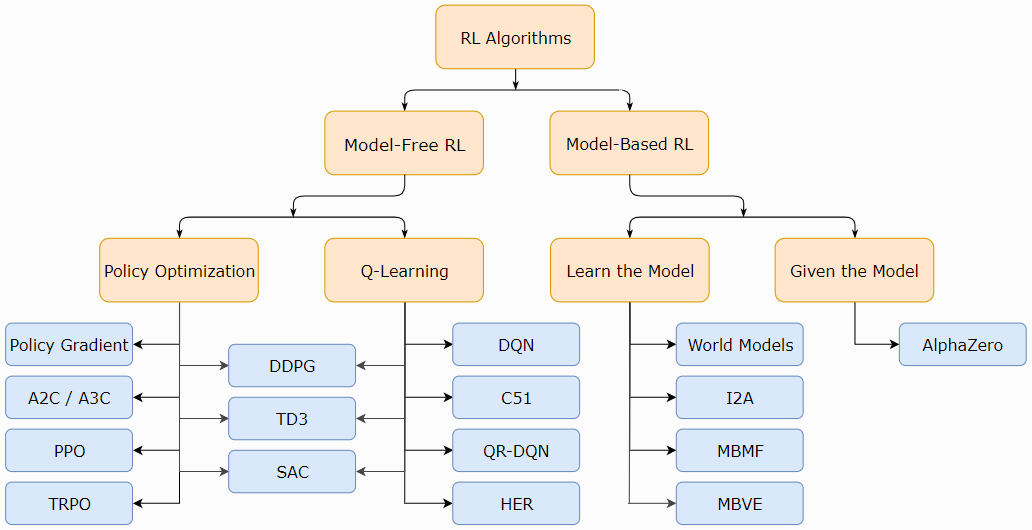
现代RL中一种非详尽但有用的算法分类法。
图片源自:OpenAI Spinning Up (https://spinningup.openai.com/en/latest/spinningup/rl_intro2.html#citations-below)
强化学习算法:
参考文献:Part 2: Kinds of RL Algorithms — Spinning Up documentation (openai.com)
译文:强化学习算法分类(Kinds of RL Algorithms) - 穷酸秀才大艹包 - 博客园 (cnblogs.com)
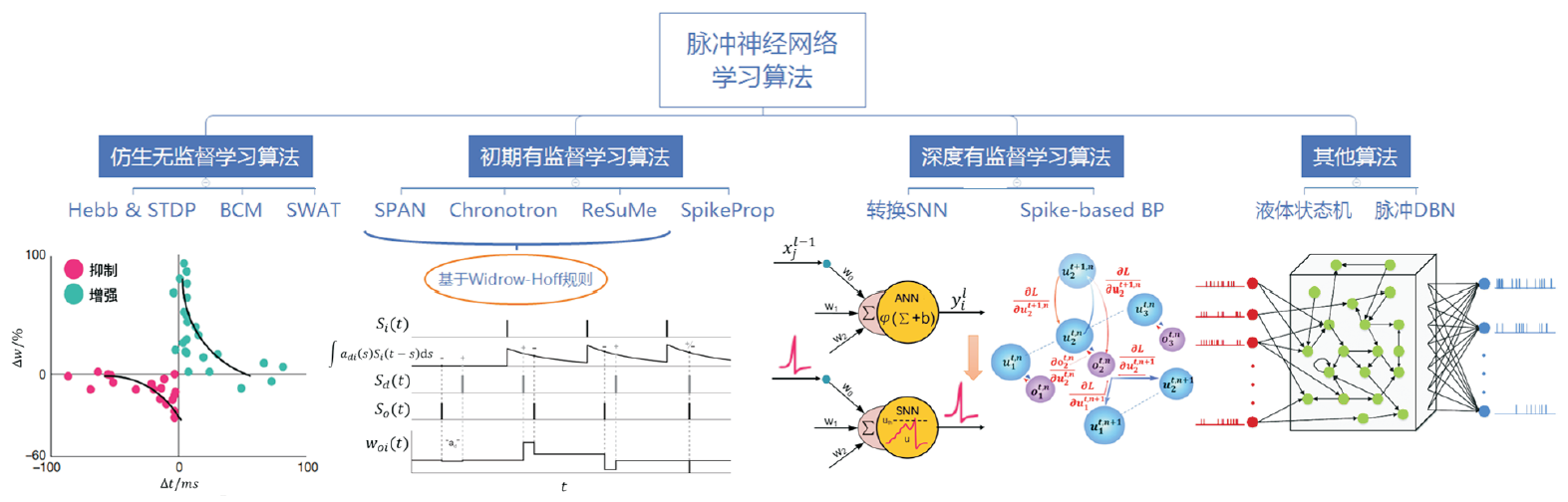
图片源自:胡一凡,李国齐,吴郁杰,等.脉冲神经网络研究进展综述[J].控制与决策,2021,36(1):1-26
SNN学习算法:
- 基于反向传播的算法
- Clock-driven
- Event-driven
- 基于突触可塑性的算法(赫布规则及其变种,STDP,R-STDP以及其他突触可塑性规则)
- ANN-SNN转换
PS:本文后续介绍的基于突触可塑性的算法一般都属于三因素学习规则;
脉冲强化学习
根据前两节对强化学习算法与SNN学习算法的分类,我们可以开始对现有的脉冲强化学习论文进行分类。
需要特别说明的是,由于Actor-Critic结构由Actor网络与Critic网络构成(引入critic网络可以减小策略梯度的方差),因此在部分工作中Actor网络用SNN实现,Critic网络用ANN实现。这样最终测试阶段可以仅使用Actor网络,充分发挥SNN的高能效优势以用于机器人控制等领域。
同样在当前的DQN方法(例如Rainbow)中,优势函数的使用也会使得模型由两个部分构成:优势网络以及价值网络。优势函数有助于提高学习效率,同时使学习更加稳定;同时经验表明,优势函数也有助于减小方差,而方差过大是导致过拟合的重要因素。如何对这些网络进行实现也是需要注意的点。
目前来看,现有的脉冲强化学习算法可以分为四大类(Chen et al., 2022):
- 基于三因素学习规则实现的强化学习算法
-
基于R-max学习规则实现的策略梯度算法;
-
基于R-STDP学习规则实现的现象学模型算法;
-
带基线的突触可塑性学习算法;
- 三因素学习规则下的时序差分学习;
-
结合多种突触可塑性的强化学习模型;
-
超越奖励的学习模型;
- 利用进化算法搜索最优的三因素学习规则;
- 利用ANN模型进行SNN学习
- 在强化学习中进行ANN到SNN的转换:基于IF神经元模型与ReLU激活函数之间对应关系的模型转换方法;
-
利用强化学习ANN教师网络训练SNN学生网络:从知识蒸馏中得到启发,将原来的ANN教师网络训练ANN学生网络的方式转变为ANN教师网络训练SNN学生网络的方式;
- 混合框架的协同训练
- 利用基于脉冲的反向传播进行训练的强化学习算法:利用不同的脉冲编码方案将脉冲序列解码成价值函数/动作概率
PS: 进化(EVOL)学习算法+R-STDP(在论文中被称为脉冲时序依赖强化学习,STDP-RL)交错更新突触权重未列入讨论中,因为其不属于严格意义的三因素学习规则实现,且笔者认为其生物学合理性不如利用进化算法搜素最优的三因素学习规则。
相关概念
- MDP:马尔可夫过程;
- POMDP:部分可观察的马尔可夫过程;
- GPOMDP:一种在参数化随机策略控制的通用POMDP中生成平均奖励梯度的有偏估计的算法;
- OLPOMDP:GPOMDP算法的在线变体;
- R-max:从奖励最大化导出的规则,该规则源于将策略梯度方法应用于随机脉冲神经元模型,旨在增加学习过程中的奖励;
- A2C:优势Actor-Critic算法;
相关论文
2003
1、Learning in Spiking Neural Networks by Reinforcement of Stochastic Synaptic Transmission (Neuron 2003)
- 学习算法:R-max学习规则——REINFORCE学习+享乐主义突触+IF神经元模型
2004
1、Learning in neural networks by reinforcement of irregular spiking (PHYSICAL REVIEW E, 2004)
- 学习算法:R-max学习规则——不规则脉冲的波动与全局奖励信号关联性
2005
1、A reinforcement learning algorithm for spiking neural networks (SYNASC 2005)
- 学习算法:R-max学习规则——OLPOMDP强化学习算法+随机IF神经元模型
2007
1、Reinforcement Learning Through Modulation of Spike-Timing-Dependent Synaptic Plasticity (Neural Computation, 2007)
- 学习算法:R-max学习规则——OLPOMDP强化学习算法+带逃逸噪声的脉冲响应模型(SRM),带有资格迹的调节STDP (MSTDPET) & 不带资格迹的简化学习规则(MSTDP)
2、Solving the Distal Reward Problem through Linkage of STDP and Dopamine Signaling (BMC Neuroscience, 2007)
- 学习算法:多巴胺(DA)调节的STDP学习规则,这被视为R-STDP学习规则的开端
PS:巴甫洛夫和工具式调节的生物学合理实现以及TD强化学习的可能脉冲网络实现。
3、Reinforcement Learning, Spike-Time-Dependent Plasticity, and the BCM Rule (Neural Computation, 2007)
- 学习算法:R-max学习规则——GPOMDP强化学习算法+广泛的神经元模型(包括Hodgkin-Huxley模型)
4、Reinforcement Learning With Modulated Spike Timing–Dependent Synaptic Plasticity (JOURNAL OF NEUROPHYSIOLOGY, 2007)
- 学习算法:带基线的R-STDP学习规则
2008
1、A Learning Theory for Reward-Modulated Spike-Timing-Dependent Plasticity with Application to Biofeedback (PLOS COMPUTATIONAL BIOLOGY, 2008)
- 学习算法:带基线的R-STDP学习规则
2009
1、A Spiking Neural Network Model of an Actor-Critic Learning Agent (Neural Computation, 2009)
- 学习算法:A2C (State-Critic Plasticity & State-Actor Plasticity),连续时间更新规则;基于奖励的差分Hebbian学习规则(取决于奖励与神经元活动的发放率),基于电流的LIF神经元,三因素学习规则
PS:状态神经元和Actor/Critic神经元之间的突触权重更新等效于离散时间TD(0)学习算法。
2、Reinforcement learning in populations of spiking neurons (Nature neuroscience, 2009)
- 学习算法:资格迹驱动的权重更新规则,群体强化 & 在线学习
PS:逃逸噪声神经元是LIF神经元,具有随机波动的脉冲阈值;可塑性由该全局反馈信号和每个突触处局部计算量(称为资格迹)驱动。
3、Spike-Based Reinforcement Learning in Continuous State and Action Space: When Policy Gradient Methods Fail (PLoS Computational Biology, 2009)
- 学习算法:标准策略梯度规则和朴素的赫布规则之间的过渡,连续时间的三因素规则
PS:带奖励基线的三因素学习规则——全局奖励信号减去期望奖励(运行均值)+两个在突触部位可用的局部因素。
2010
1、Functional Requirements for Reward-Modulated Spike-Timing-Dependent Plasticity (The Journal of neuroscience: the official journal of the Society for Neuroscience, 2010)
- 学习算法:带基线的R-STDP & R-max学习规则——内部Critic(利用奖励预测误差RPE进行学习)+具有指数逃逸率的简化脉冲响应模型(SRM0)神经元
PS:对RPE的定义与TD学习中的定义略有不同——给定输入脉冲序列和当前权重配置的平均奖励的内部估计(这个RPE定义不需要时间预测,唯一的功能是中和学习规则中的无监督倾向)。
2011
1、An Imperfect Dopaminergic Error Signal Can Drive Temporal-Difference Learning (PLOS COMPUTATIONAL BIOLOGY, 2011)
- 学习算法:基于Actor-Critic架构的脉冲时序差分学习模型,经典离散时间TD算法
2013
1、Reinforcement Learning Using a Continuous Time Actor-Critic Framework with Spiking Neurons (Plos Computational Biology, 2013)
- 学习算法:TD-LTP学习规则——A2C (Spiking Neuron Critic & Spiking Neuron Actor)+连续TD学习+简化的脉冲响应模型(SRM0),三因素学习规则
简介:本文通过将连续TD学习扩展到以连续时间操作的具有连续状态和动作表征的Actor-Critic网络中脉冲神经元的情况,成功解决了如何在非离散框架的自然情况下实现RL以及如何在神经元中计算奖励预测误差(RPE)的问题。在仿真中,本文通过许多与报道的动物表现相符的试验,证明了这种架构可以解决类似Morris水迷宫的导航任务,以及Acrobot和Cartpole这类经典控制问题。
PS:该SNN-RL学习方法被称为TD-LTP学习规则;状态编码为位置单元发放率;Actor和Critic输出遵循群体编码;为了确保明确选择动作,Actor使用N-winner-take-all横向连接方案。
2、A neural reinforcement learning model for tasks with unknown time delays (CogSci 2013)
- 强化学习算法:TD学习
- SNN学习算法:误差调节神经学习规则(伪Hebbian形式,三因素学习规则),LIF神经元
PS:伪Hebbian形式:学习率κ,突触前活动si(x),突触后因素αjej以及误差E。值得注意的是,该项不是接收神经元的发放,而是驱动该发放的亚阈值电流(因此是"伪"Hebbian)。换句话说,用于驱动神经元的脉冲活动的相同电流用于更新连接权重。与该规则一致,在实验工作中已经提出,突触后电位对于可塑性不是必需的。
3、A Spiking Neural Model for Stable Reinforcement of Synapses Based on Multiple Distal Rewards (Neural Computation, 2013)
- 学习算法:具有衰减奖励门控的R-STDP算法(利用类似Critic算法,ARG-STDP),并增加了短期可塑性(STP)以稳定学习动态
4、Biologically Inspired SNN for Robot Control (IEEE Transactions on Cybernetics, 2013)
- 强化学习算法:TD学习
- SNN学习算法:自组织SNN,LIF神经元模型
PS:沿墙绕行任务,Pioneer 3机器人(声纳,激光和电机)。
2014
1、Reinforcement learning in cortical networks (Encyclopedia of Computational Neuroscience, 2014)
- 学习算法:
- 策略梯度方法(享乐主义突触,脉冲强化,节点扰动,群体强化,在线学习和现象R-STDP模型)
- TD学习(假设基础决策过程是马尔可夫模型)
2015
1、Computation by Time (Neural Processing Letters, 2015)
- 学习算法:R-STDP,策略梯度方法和TD学习
2、A Spiking Neural Network Model of Model-Free Reinforcement Learning with High-Dimensional Sensory Input and Perceptual Ambiguity (PloS one, 2015)
- 强化学习算法:基于自由能的强化学习(FERL)
- SNN学习算法:带平均发放率的伪自由能(aFE) & 平均瞬时伪自由能(iFE),LIF神经元
PS:受限玻尔兹曼机(RBM),部分可观察的RL,NEST模拟器。
2016
1、Neuromodulated Spike-Timing-Dependent Plasticity, and Theory of Three-Factor Learning Rules (FRONTIERS IN NEURAL CIRCUITS, 2016)
- 学习算法:策略梯度算法(R-max) / 现象学模型(R-STDP) / TD-STDP学习 / 其他三因素学习规则
2017
1、Navigating Mobile Robots to Target in Near Shortest Time using Reinforcement Learning with Spiking Neural Networks (IJCNN 2017)
- 学习算法:R-STDP学习规则
PS:绕墙避障导航任务。
2、Hardware-Friendly Actor-Critic Reinforcement Learning Through Modulation of Spike-Timing-Dependent Plasticity (IEEE TRANSACTIONS ON COMPUTERS, 2017)
- 学习算法:Actor-Critic的SNN硬件实现(TD-STDP学习规则)
2018
1、A Survey of Robotics Control Based on Learning-Inspired Spiking Neural Networks (Front. Neurorobot., 2018)
- 学习算法:
- 赫布学习(无监督学习,监督学习,经典调节,操作条件反射,奖励调节的训练)
- 强化学习(时序差分,基于模型和其他)
2、End to End Learning of Spiking Neural Network based on R-STDP for a Lane Keeping Vehicle (ICRA 2018)
- 学习算法:R-STDP学习规则,LIF神经元
PS:车道保持任务,部署有动态视觉传感器(DVS)的Pioneer机器人;利用DVS作为输入,电机命令作为输出。
2019
1、Improved robustness of reinforcement learning policies upon conversion to spiking neuronal network platforms applied to Atari Breakout game (Neural Networks, 25 November 2019)
- 强化学习算法:DQN (Atari Breakout)
- SNN学习算法:ANN-SNN转换,随机LIF神经元
简介:本文将ANN-SNN转换扩展到深度Q学习的领域,提供了将标准NN转换为SNN的原理证明,并证明了SNN可以提高输入图像中遮挡的鲁棒性。
PS:本研究探索了几种搜索最优缩放参数的方法,包括粒子群优化(particle swarm optimization,PSO);在所研究的优化方法中,PSO产生了最优性能;使用基于PyTorch的开源库BindsNET模拟脉冲神经元;随机LIF神经元基于LIF神经元(如果神经元的膜电位低于阈值,则神经元可能会以与膜电位(逃逸噪声)成比例的概率发放脉冲)。
2、Reinforcement Learning in Spiking Neural Networks with Stochastic and Deterministic Synapses (Neural Computation, 2019)
- 学习算法:随机性-确定性协调(SDC)脉冲强化学习模型——享乐主义规则+半RSTDP规则
PS:随机性突触的可塑性是通过调节具有全局奖励的突触神经递质的释放概率来实现的。确定性突触的可塑性是通过R-STDP规则的变体实现的(Florian, 2007; Fremaux & Gerstner, 2015)。作者将其命名为半RSTDP规则,它根据一半STDP窗口的结果修改权重(突触前脉冲先于突触后脉冲的部分)。
3、Embodied Synaptic Plasticity with Online Reinforcement learning (Front. Neurorobot., 2019)
- 学习算法:R-max学习规则——基于突触采样的奖励学习规则,通过在线强化学习来评估突触可塑性(SPORE学习规则),用于两个视觉运动任务:目标到达和车道保持
PS:作者展示了这个框架,以通过在线强化学习来评估突触可塑性(Synaptic Plasticity with Online REinforcement learning, SPORE)。它结合了一种策略采样方法,该方法可以模拟关于多巴胺涌入的树突棘的生长。SPORE从精确的脉冲时间在线学习,并且完全由脉冲神经元实现。基于奖励的在线学习规则,用于脉冲神经网络,称为突触采样。SPORE是基于奖励的突触采样规则的实现,它使用NEST神经模拟器。SPORE针对闭环应用进行优化,形成在线策略梯度方法。
2020
1、Reinforcement co-Learning of Deep and Spiking Neural Networks for Energy-Efficient Mapless Navigation with Neuromorphic Hardware (2020 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS))
- 强化学习算法:Hybrid DDPG (Deep Critic Network & Spiking Actor Network)
- SNN学习算法:STBP算法,具有两个内部状态变量(电流和电压)的LIF神经元
简介:本文提出了一种神经形态方法,将SNN的能效与DRL的最优性相结合,并在无地图导航的学习控制策略中对其进行基准测试。网络使用的混合框架是脉冲确定性策略梯度(SDDPG),由脉冲Actor网络(SAN)和深度Critic网络组成,其中两个网络使用梯度下降共同训练。
PS:混合框架是脉冲确定性策略梯度(SDDPG);状态编码为Possion脉冲编码;任务为Gazebo模拟器与真实场景下的目标导航任务。
2、Training spiking neural networks for reinforcement learning (ArXiv 2020)
- 强化学习算法:A2C (Deep Critic Network & Spiking Actor Network),策略梯度合作者网络(Policy Gradient Coagent Network, PGCN)
- SNN学习算法:类似Hebbian/Anti-Hebbian学习规则,Memoryless Ising model;类似STDP学习规则,LIF神经元;Event-driven,Generalized Linear Model (GLM)
PS:由于权重更新还受全局TD误差控制,所以前两种学习规则仍属于三因素学习规则范畴。本文中还额外介绍了一种事件驱动的算法。假设每个脉冲神经元从一个发放策略中采样其动作,从而在网络中形成一个随机节点。通过使用重参数化技巧,能够将采样中的随机性建模为模型的输入,而不是将其归因于模型参数,从而使所有模型参数连续可微的,实现反向传播。但是,这种训练方法在其开源代码中并未进行实现,缺乏实验分析,网络实现部分介绍也十分有限,有待后续版本的查看。
3、A solution to the learning dilemma for recurrent networks of spiking neurons (NATURE COMMUNICATIONS, 2020)
- 学习算法:在线Actor-Critic方法(Reward-based e-prop, LSNN),三因素学习规则
简介:本文将局部资格迹和自上而下的学习信号进行结合,在循环连接的脉冲神经元网络上以通过梯度下降实现生物学合理的在线网络学习,尤其是深度强化学习。这种被称为e-prop的学习方法,其性能接近时间反向传播(BPTT)。
4、Reinforcement Learning with Feedback-modulated TD-STDP (ArXiv 2020)
- 学习算法:Actor-Critic (TD-STDP学习规则)
5、Evolving to learn: discovering interpretable plasticity rules for spiking networks (Bernstein Conference, 2020)
- 学习算法:采用笛卡尔遗传编程作为进化算法来发现脉冲神经网络中的可塑性规则(奖励驱动、误差驱动和相关驱动学习)
PS:这是一种基于任务族定义、相关性能测量和生物学约束的自动化方法。对于奖励驱动的任务,我们方法发现具有有效奖励基准的新可塑性规则执行具有竞争力(带奖励基准的R-STDP)。
2021
1、Strategy and Benchmark for Converting Deep Q-Networks to Event-Driven Spiking Neural Networks (AAAI 2021)
- 强化学习算法:DQN (Atari)
- SNN学习算法:ANN-SNN转换,IF神经元
简介:本文提出了发放率的可靠表征,以减少深度Q网络在ANN-SNN转换过程中的误差,在17项性能最优的Atari游戏中获得了相当的得分。
PS:BindsNET;虽然题目中带有Event-Driven,但是实际采用的仍为标准的ANN-SNN转换方法(ReLU激活函数/IF神经元)。
2、Deep Reinforcement Learning with Population-Coded Spiking Neural Network for Continuous Control (CoRL 2021)
- 强化学习算法:TD3/DDPG/SAC/PPO-PopSAN (Deep Critic Network & Population-coded Spiking Actor Network,MuJoCo)
- SNN学习算法:STBP算法,基于电流的LIF模型
简介:本文提出一个群体编码的脉冲Actor网络(PopSAN),该网络与使用深度强化学习(DRL)的深度Critic网络一起进行了训练。遍及大脑网络的群体编码方案极大地增强网络的表征能力,并且混合学习将深度网络的训练优势与脉冲网络的节能推断相结合,极大地提高了神经形态控制器的整体效率。实验结果证明,在能效和鲁棒性都很重要的情况下,混合RL方法可以替代深度学习。
PS:群体编码的脉冲Actor网络(PopSAN);将观察和动作空间的每个维度编码为脉冲神经元的各个输入和输出群体的活动。编码器模块将连续观测转换为输入群体中的脉冲,而解码器模块将输出群体活动解码为实值动作;编码器模块中的每个神经元具有高斯感受野(μ, σ),μ和σ都是任务特定的可训练参数;解码器模块分两个阶段:首先,每T个时间步骤计算发放率fr,然后将动作a作为计算出的fr的加权和返回(输出群体的感受野是由它们的连接权重形成的,这是在训练中学习的)。
3、Combining STDP and binary networks for reinforcement learning from images and sparse rewards (Neural Networks, 2021)
- 学习算法:R-STDP学习规则,其中用到了二值神经网络训练好的特征提取网络
4、On-chip trainable hardware-based deep Q-networks approximating a backpropagation algorithm (Neural Computing and Applications, 2021)
- 强化学习算法:DQN
- SNN学习算法:硬件实现的LTP/LTD
5、Multi-timescale biological learning algorithms train spiking neuronal network motor control (bioRxiv, November 20, 2021)
- 学习算法:进化(EVOL)学习算法+R-STDP(在论文中被称为脉冲时序依赖强化学习,STDP-RL)交错更新突触权重
简介:这项研究首先使用单个模型学习分别训练SNN,使用脉冲时序依赖强化学习(STDP-RL)和进化(EVOL)学习算法来解决CartPole任务。然后,本文开发了一种受生物进化启发的交错算法,该算法按顺序结合了EVOL和STDP-RL学习。
6、A Dual-Memory Architecture for Reinforcement Learning on Neuromorphic Platforms (Neuromorph. Comput., 2021)
- 强化学习算法:蒙特卡洛方法
- SNN学习算法:基于Loihi实现
简介:强化学习代表了生物系统学习的原生方式。人类和动物不是在部署之前通过大量标记数据进行训练,而是通过根据不断收集的数据更新策略来不断从经验中学习。这需要就地学习,而不是依赖于将新数据缓慢且成本高昂地上传到中央位置,在该位置将新信息嵌入到先前训练的模型中,然后将新模型下载到智能体。为了实现这些目标,本文描述了一个用于执行RL任务的高级系统,该系统受到生物计算的几个原则的启发,特别是互补学习系统理论,假设学习大脑中的新记忆取决于皮层和海马网络之间的相互作用。本文表明,这种"双记忆学习器"(DML)可以实现可以接近RL问题最佳解决方案的方法。然后以脉冲方式实现DML架构并在英特尔的Loihi处理器上执行。本文演示了它可以解决经典的多臂赌博机问题,以及更高级的任务,例如在迷宫中导航和纸牌游戏二十一点。
7、Distilling Neuron Spike with High Temperature in Reinforcement Learning Agents (ArXiv 2021)
- 强化学习算法:DQN (Atari)
- SNN学习算法:借鉴知识蒸馏,利用DNN教师网络训练SNN学生网络
8、Exploring Spiking Neural Networks in Single and Multi-agent RL Methods (International Conference on Rebooting Computing, 2021)
Abstract:Reinforcement Learning (RL) techniques can be used effectively to solve a class of optimization problems that require the trajectory of the solution rather than a single-point solution. In deep RL, traditional neural networks are used to model the agent's value function which can be used to obtain the optimal policy. However, traditional neural networks require more data and will take more time to train the network, especially in offline policy training. This paper investigates the effectiveness of implementing deep RL with spiking neural networks (SNNs) in single and multi-agent environments. The advantage of using SNNs is that we require fewer data to obtain good policy and also it is less time-consuming than the traditional neural networks. An important criterion to check for while using SNNs is proper hyperparameter tuning which controls the rate of convergence of SNNs. In this paper, we control the hyperparameter time-step (dt) which affects the spike train generation process in the SNN model. Results on both single-agent and multi-agent environments show that these SNN based models under different time-step (dt) require a lesser number of episodes training to achieve the higher average reward.
2022
1、Human-Level Control through Directly-Trained Deep Spiking Q-Networks (IEEE Transactions on Cybernetics 2022)
- 强化学习算法:DQN (Atari)
- SNN学习算法:STBP算法;用一个训练好的MLP作为解码器,解码器的输入为发放率,输出为价值函数
PS:实验结果证明了DSQN在性能、稳定性、泛化能力和能效方面优于基于转换的SNN。同时,DSQN在性能方面达到了与DQN相同的水平,在稳定性方面超过了DQN。
2、Deep Reinforcement Learning with Spiking Q-learning (ArXiv 2022)
- 强化学习算法:DQN (Atari)
- SNN学习算法:STBP算法(SpikingJelly框架)
PS:最后一层脉冲神经元不发放,用仿真时间T内的最大膜电压表示价值函数。
3、Evolving-to-Learn Reinforcement Learning Tasks with Spiking Neural Networks (ArXiv 2022)
- 学习算法:R-STDP,笛卡尔遗传编程过程(CGP)
4、Multi-scale Dynamic Coding improved Spiking Actor Network for Reinforcement Learning (AAAI 2022)
- 强化学习算法:Hybrid TD3 (Deep Critic Network & Multiscale Dynamic Coding improved Spiking Actor Network,MuJoCo)
- SNN学习算法:STBP算法,具有二阶膜电位方程的神经元模型(类似Izhikevich神经元模型)
PS:此篇即为Population-coding and Dynamic-neurons improved Spiking Actor Network for Reinforcement Learning的最终版本——MDC-SAN。
5、Solving the Spike Feature Information Vanishing Problem in Spiking Deep Q Network with Potential Based Normalization (Frontiers in Neuroscience 2022)
- 强化学习算法:DQN (Atari)
- SNN学习算法:STBP算法
PS:基于电位的层归一化(pbLN)方法来直接训练脉冲深度Q网络,其中层归一化(Layer Normalization)可以解决SNN中的梯度消失问题。
6、A Low Latency Adaptive Coding Spiking Framework for Deep Reinforcement Learning (IJCAI 2023)
- 强化学习算法:DQN (Atari),BCQ (Off-Policy Deep Reinforcement Learning without Exploration,MuJoCo)
- SNN学习算法:STBP算法
PS:本文提出了一个自适应编/解码器,先用一个可学习的矩阵在输入到SNN之前将原始状态沿时间维度拓展为原本的T倍(编码器),最后使用两个可学习的矩阵将输出脉冲序列在时间维度上压缩T倍(解码器)。
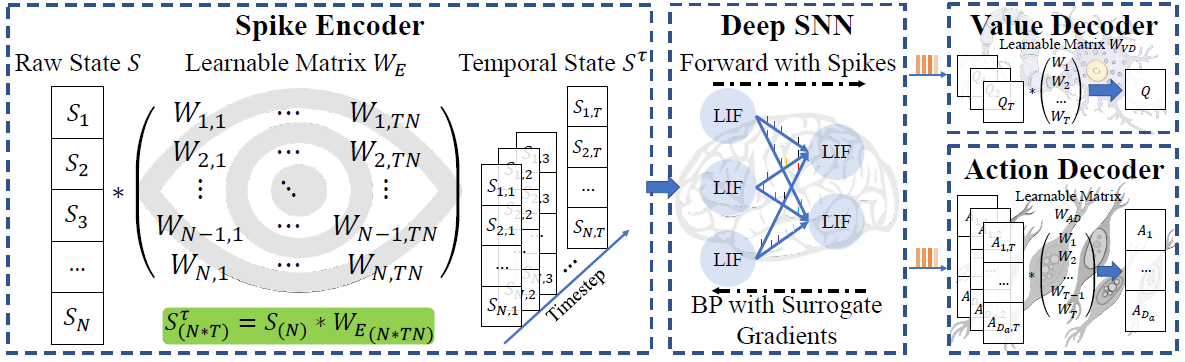
7、Dynamic Resistance Based Spiking Actor Network for Improving Reinforcement Learning (ICCAI 22)
Abstract:Designing algorithms for continuous control is a big challenge no matter in real robot controlling or simulation tasks. Deep reinforcement learning (DRL) is the most successful algorithm in dealing with such tasks for it utilizing the powerful ability of deep neuron network (DNN) in handling complex information. However, the more powerful ability the DNN has, the more energy it consumes. It’s a barrier for DRL to be realized in real-world control tasks. With more biological features, spiking neuron network (SNN) is one of the frontier fields of high-efficiency computing. The binary spike it used to represent information contains more temporal information and leads to greater computational efficiency on neuromorphic chips. Based on a hybrid architecture of SNN and DNN, we propose an actor-critic model to utilize the ability of SNN in dealing with complex continuous information and the ability of DNN in large scale accurate computation. The common Leaky Integrate-and-Fire (LIF) neuron model which is mainly used to build deep SNN neglects the resistance flexibility in the neuron. Considering that causes a descend capacity of representing continuous information which is of vital important in continuous control, we propose a new dynamic resistance LIF (R-LIF) model to compensate the temporal relation dependencies in neurons. With the same gradient updating rule, our R-LIF based spiking actor network (RSAN) shows a better performance when inferring in OpenAI benchmark tasks not only than the deep neuron actor network but also than the same LIF based spiking neuron actor network.
8、An Implementation of Actor-Critic Algorithm on Spiking Neural Network Using Temporal Coding Method (Appl. Sci. 2022)
Abstract:Taking advantage of faster speed, less resource consumption and better biological interpretability of spiking neural networks, this paper developed a novel spiking neural network reinforcement learning method using actor-critic architecture and temporal coding. The simple improved leaky integrate-and-fire (LIF) model was used to describe the behavior of a spike neuron. Then the actor-critic network structure and the update formulas using temporally encoded information were provided. The current model was finally examined in the decision-making task, the gridworld task, the UAV flying through a window task and the avoiding a flying basketball task. In the 5 × 5 grid map, the value function learned was close to the ideal situation and the quickest way from one state to another was found. A UAV trained by this method was able to fly through the window quickly in simulation. An actual flight test of a UAV avoiding a flying basketball was conducted. With this model, the success rate of the test was 96% and the average decision time was 41.3 ms. The results show the effectiveness and accuracy of the temporal coded spiking neural network RL method. In conclusion, an attempt was made to provide insights into developing spiking neural network reinforcement learning methods for decision-making and autonomous control of unmanned systems.
9、Tuning Synaptic Connections instead of Weights by Genetic Algorithm in Spiking Policy Network (中国科学:信息科学 2022)
- 学习算法:遗传算法,经典控制任务(CartPole)和MuJoCo任务
PS:用遗传算法调节突触连接。
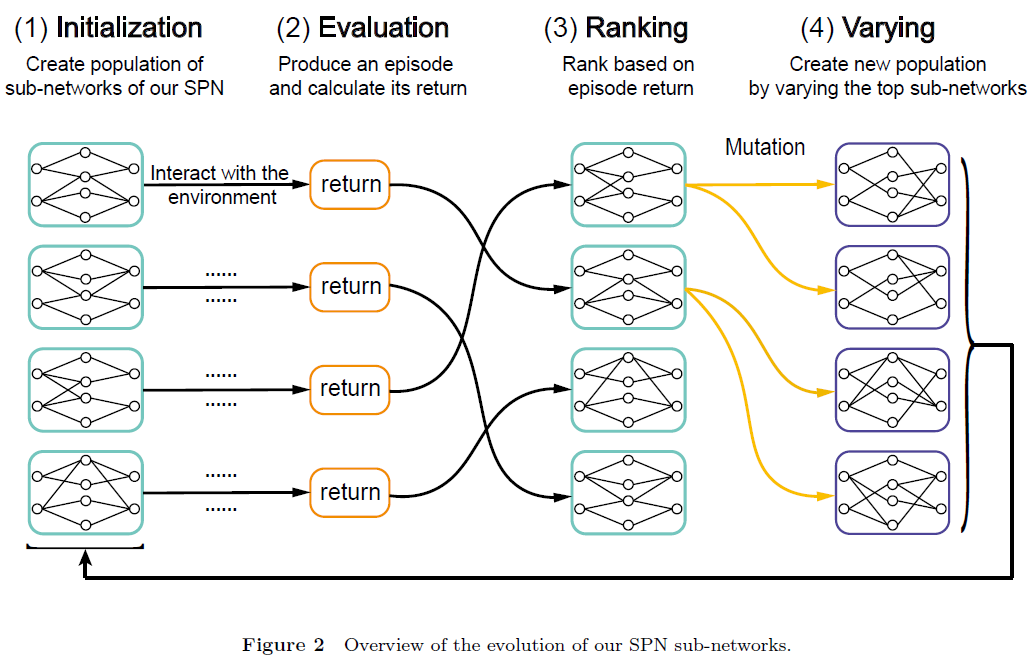
2023
1、A Hybrid Spiking Neural Network Reinforcement Learning Agent for Energy-Efficient Object Manipulation (Machines, 2023)
- 强化学习算法:Hybrid DDPG (Gazebo)
- SNN学习算法:STBP算法
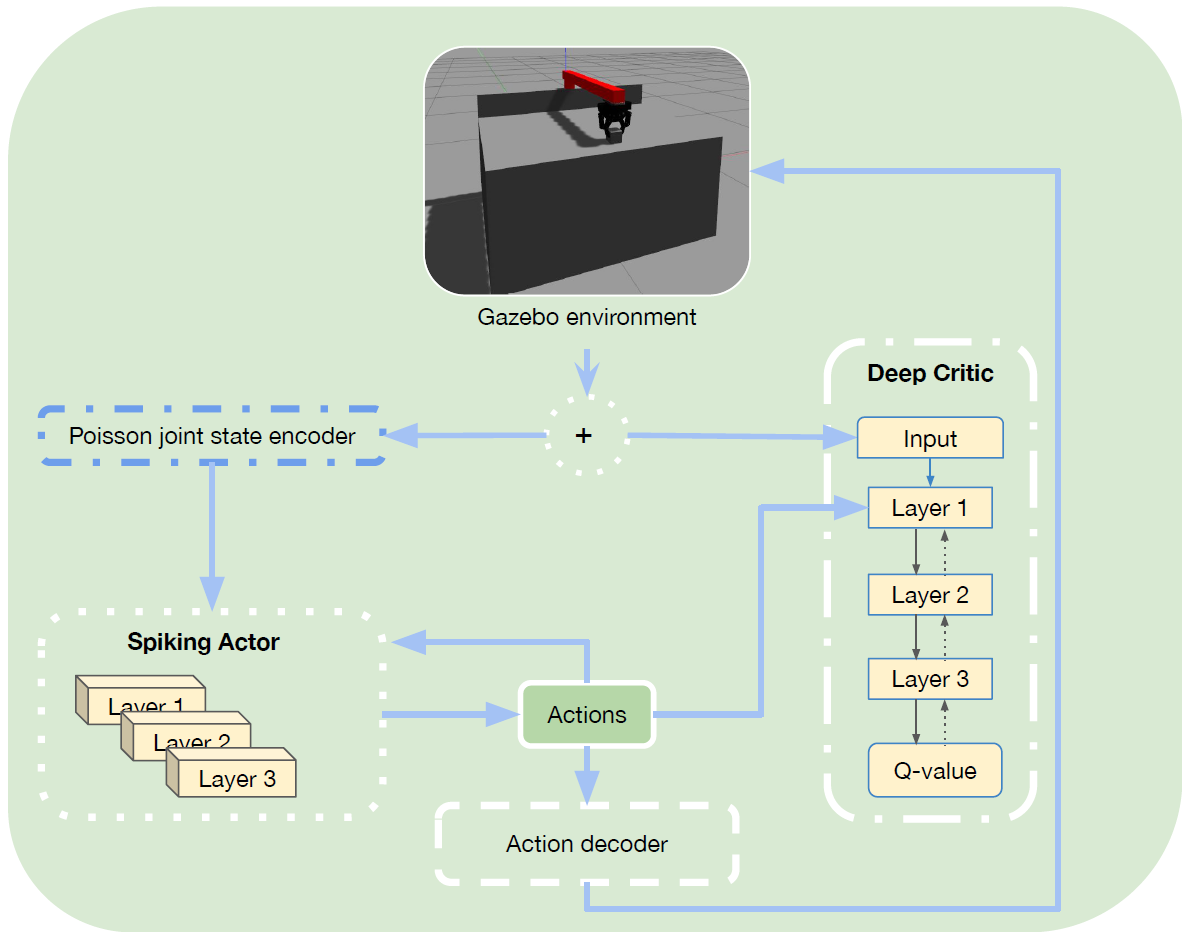
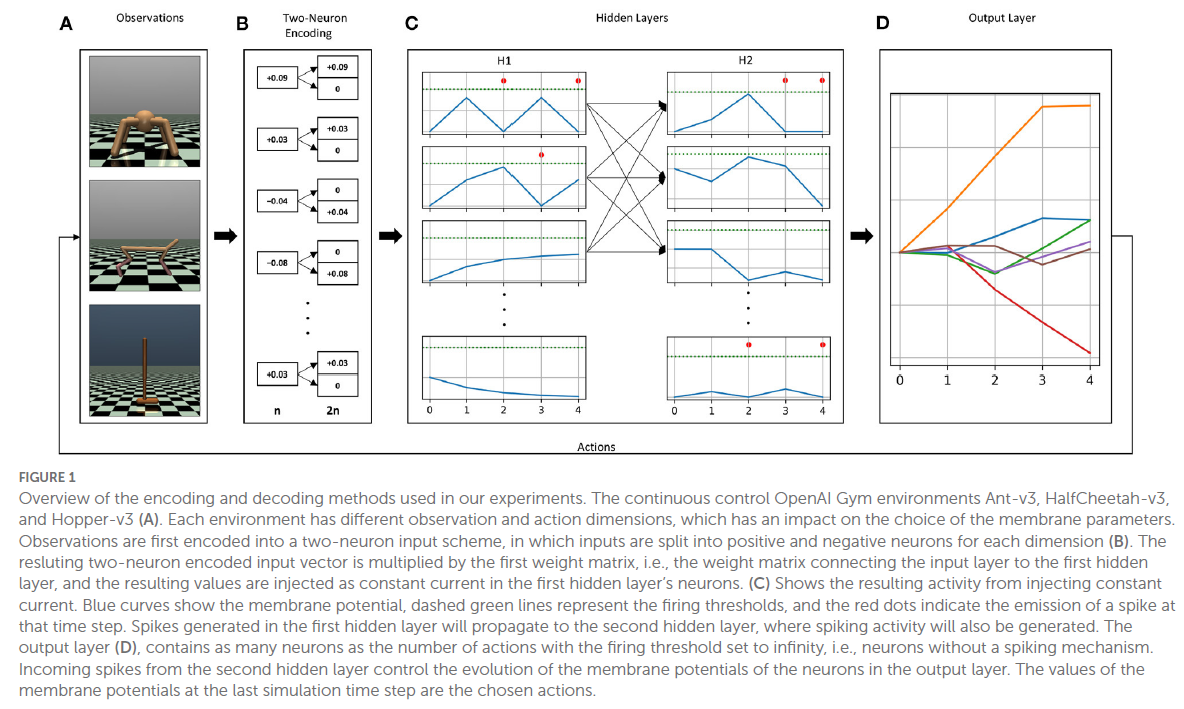
2、Toward robust and scalable deep spiking reinforcement learning (Frontiers in Neurorobotics, 2023)
- 强化学习算法:Hybrid TD3,经典控制任务(Pendulum)和MuJoCo任务
- SNN学习算法:STBP算法(SpyTorch框架)
PS:在本文中,作者考虑在初始化期间随机化每个神经元的膜参数值,并保持这些值固定,同时仅优化突触权重以解决连续控制问题;此外,作者将发放阈值以及时间常数(电流和电压衰减因子)随机化。
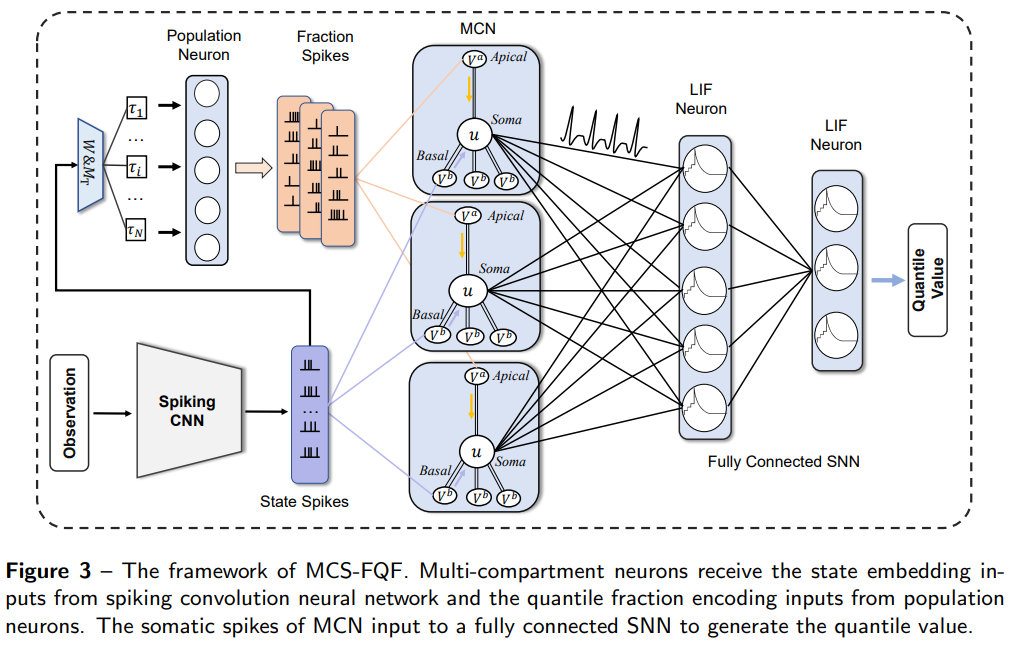
3、Multi-compartment Neuron and Population Encoding improved Spiking Neural Network for Deep Distributional Reinforcement Learning (Arxiv 2023)
- 强化学习算法:FQF算法(Fully parameterized quantile function for distributional reinforcement learning, Atari)
- SNN学习算法:STBP算法
PS:本文将生物启发多室神经元(MCN)模型和群体编码方法相结合,提出了一种脑启发的脉冲深度分布强化学习算法——多室脉冲全参数分位数函数网络(Multi-Compartment Spiking Fully parameterized Quantile Function network, MCS-FQF)。

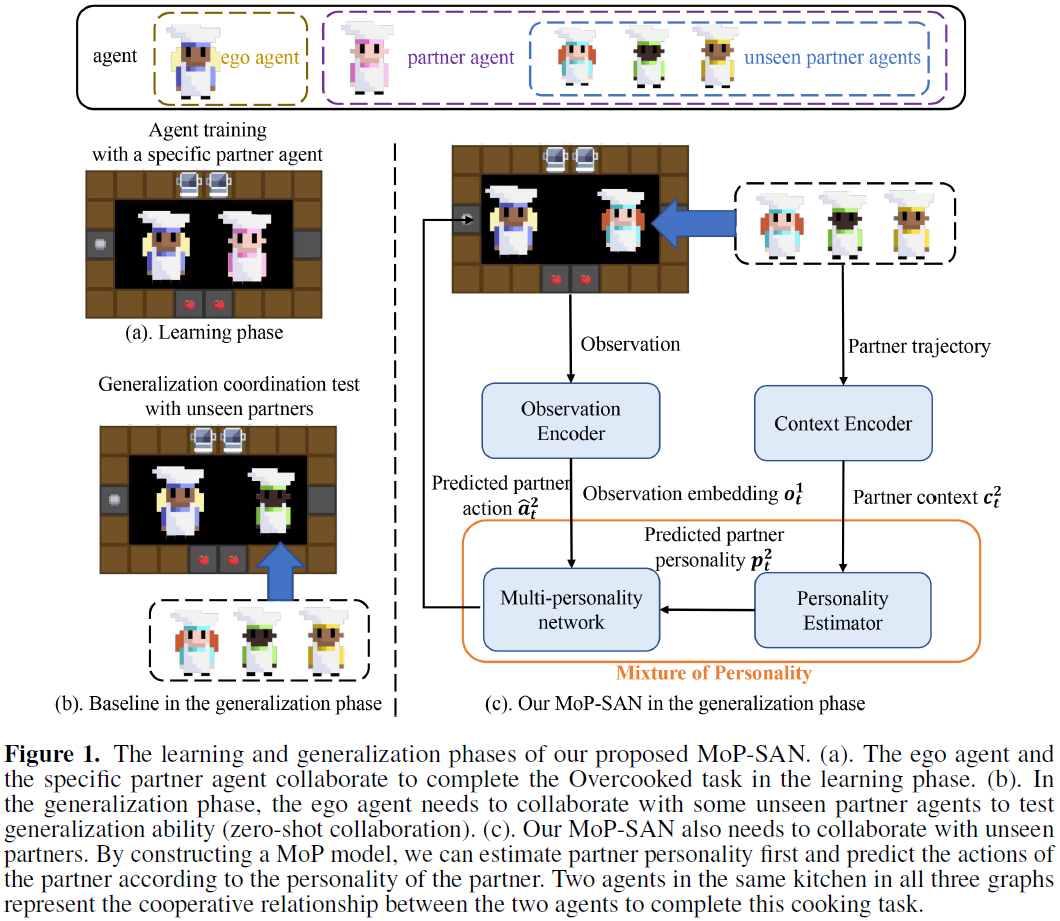
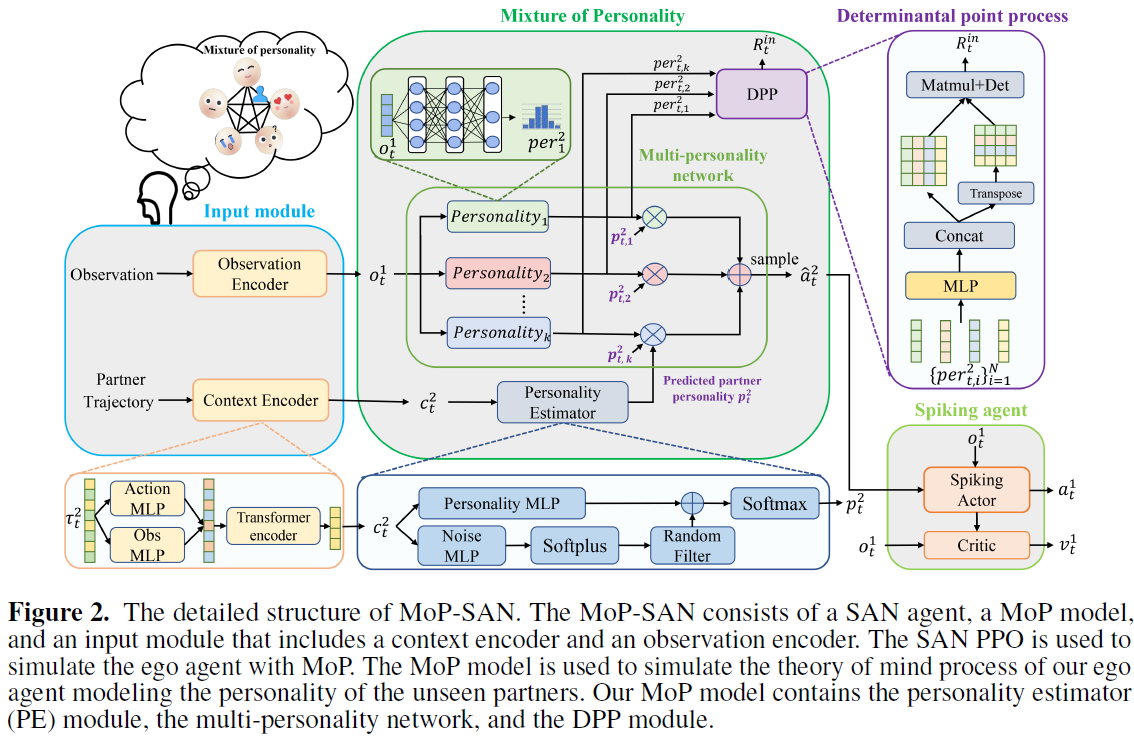
4、Mixture of personality improved spiking actor network for efficient multi-agent cooperation (Arxiv 2023)
- 强化学习算法:MoP模型(采用DPP和SAN),双人合作任务(Overcooked)
- SNN学习算法:STBP算法,LIF神经元
PS:生物学合理的人格混合改进的脉冲Actor网络——MoP-SAN。
5、Evolving Connectivity for Recurrent Spiking Neural Networks (Arxiv 2023)
- 学习算法:进化连接(Evolving Connectivity, EC),将权重调整重新表述为对参数化连接概率分布的搜索,并采用自然进化策略(Natural Evolution Strategies, NES)来优化这些分布,用于标准机器人运动任务(Humanoid、Walker2d和Hopper)
PS:进化连接(EC)框架是一种仅推理的方法,用于训练具有1位连接的循环脉冲神经网络(RSNN)。EC框架包括三个主要步骤:(1) 将神经网络结构从基于权重的参数化重新表述为连接概率分布,(2) 使用自然进化策略(NES)方法来优化重新表述的参数空间,以及 (3) 从分布中确定性地提取最终参数。

6、A Neuromorphic Architecture for Reinforcement Learning from Real-Valued Observations (Arxiv 2023)
- 学习算法:这种可塑性有两个驱动因素:i) 对输入信号的适应和 ii) 通过来自actor-critic层的反馈进行调节。第一个自适应规则是基于Afshar等人(2020)提出的具有自适应选择阈值的特征提取(FEAST),而actor-critic层是表格TD(λ)算法的脉冲神经元实现。
PS:在三个经典控制RL环境(Mountain car、Cart-pole和Acrobot)进行实验。
7、A Hybrid Reinforcement Learning Approach With a Spiking Actor Network for Efficient Robotic Arm Target Reaching (IEEE Robotics and Automation Letters, 2023)
Abstract:The increasing demand for applications in competitive fields, such as assisted living and aerial robots, drives contemporary research into the development, implementation and integration of power-constrained solutions. Although, deep neural networks (DNNs) have achieved remarkable performances in many robotics applications, energy consumption remains a major limitation. The letter at hand proposes a hybrid variation of the well-established deep deterministic policy gradient (DDPG) reinforcement learning approach to train a 6 <span id="MathJax-Span-2" class="mrow"><span id="MathJax-Span-3" class="msubsup"><span id="MathJax-Span-4" class="mi"><span id="MathJax-Span-5" class="texatom"><span id="MathJax-Span-6" class="mrow"><span id="MathJax-Span-7" class="mo">∘ of freedom robotic arm in the target-reach task available at: In particular, we introduce a spiking neural network (SNN) for the actor model and a DNN for the critic one, aiming to find an optimal set of actions for the robot. The deep critic network is employed only during training and discarded afterwards, allowing the deployment of the SNN in neuromorphic hardware for inference. The agent is supported by a combination of RGB and laser scan data exploited for collision avoidance and object detection. We compare the hybrid-DDPG model against a classic DDPG one, demonstrating the superiority of our approach.
8、Lateral Interactions Spiking Actor Network for Reinforcement Learning (ICONIP 2023)
Abstract:Spiking neural network (SNN) has been shown to be a biologically plausible and energy efficient alternative to Deep Neural Network in Reinforcement Learning (RL). In prevailing SNN models for RL, fully-connected architectures with inter-layer connections are commonly employed. However, the incorporation of intra-layer connections is neglected, which impedes the feature representation and information processing capacities of SNNs in the context of reinforcement learning. To address these limitations, we propose Lateral Interactions Spiking Actor Network (LISAN) to improve decision-making in reinforcement learning tasks with high performance. LISAN integrates lateral interactions between neighboring neurons into the spiking neuron membrane potential equation. Moreover, we incorporate soft reset mechanism to enhance model’s functionality recognizing the significance of residual potentials in preserving valuable information within biological neurons. To verify the effectiveness of our proposed framework, LISAN is evaluated using four continuous control tasks from OpenAI gym as well as different encoding methods. The results show that LISAN substantially improves the performance compared to state-of-the-art models. We hope that our work will contribute to a deeper understanding of the mechanisms involved in information capturing and processing in the brain.
2024
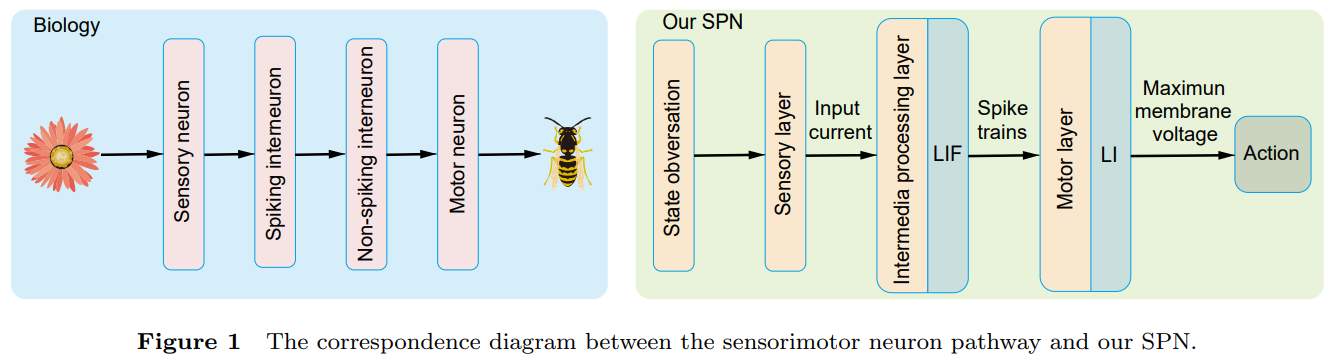
1、Fully Spiking Actor Network with Intra-layer Connections for Reinforcement Learning (TNNLS)
Abstract:With the help of special neuromorphic hardware, spiking neural networks (SNNs) are expected to realize artificial intelligence (AI) with less energy consumption. It provides a promising energy-efficient way for realistic control tasks by combining SNNs with deep reinforcement learning (DRL). In this paper, we focus on the task where the agent needs to learn multi-dimensional deterministic policies to control, which is very common in real scenarios. Recently, the surrogate gradient method has been utilized for training multi-layer SNNs, which allows SNNs to achieve comparable performance with the corresponding deep networks in this task. Most existing spike-based RL methods take the firing rate as the output of SNNs, and convert it to represent continuous action space (i.e., the deterministic policy) through a fully-connected (FC) layer. However, the decimal characteristic of the firing rate brings the floating-point matrix operations to the FC layer, making the whole SNN unable to deploy on the neuromorphic hardware directly. To develop a fully spiking actor network without any floating-point matrix operations, we draw inspiration from the non-spiking interneurons found in insects and employ the membrane voltage of the non-spiking neurons to represent the action. Before the non-spiking neurons, multiple population neurons are introduced to decode different dimensions of actions. Since each population is used to decode a dimension of action, we argue that the neurons in each population should be connected in time domain and space domain. Hence, the intra-layer connections are used in output populations to enhance the representation capacity. Finally, we propose a fully spiking actor network with intra-layer connections (ILC-SAN).
2、Noisy Spiking Actor Network for Exploration (Arxiv)
3、Multi-Attribute Dynamic Attenuation Learning Improved Spiking Actor Network (Available at SSRN)
相关开源代码
- 强化学习算法:DQN,策略梯度,Actor-Critic
- SNN学习算法:Clock-driven
PS:提供了多种非发放神经元,可以自由选择膜电压编码方法(最终膜电压、最大膜电压、具有最大绝对值的膜电压以及平均膜电压)。
2、BindsNET: A Machine Learning-Oriented Spiking Neural Networks Library in Python (Blog)
- SNN学习算法:PostPre, WeightDependentPostPre, Hebbian learning rules, MSTDP, MSTDPET, Rmax / ANN-SNN转换
- 脉冲神经元:McCullochPitts(对应的一般的ANN里的神经元), IFNodes, LIFNodes, CurrentLIFNodes, AdaptiveLIFNodes, DiehlAndCookNodes, IzhikevichNodes, SRM0Nodes
PS:具体学习算法参见(BindsNET学习系列 —— LearningRule),脉冲神经元参见(BindsNET学习系列 —— Nodes),强化学习代码参见(BindsNET Breakout)。
3、Norse: A library to do deep learning with spiking neural networks
- 强化学习算法:DQN,策略梯度,Actor-Critic
- SNN学习算法:Clock-driven
PS:最后一层脉冲神经元不发放,用仿真时间T内的最大膜电压表示连续值。
解码方式
- 直接利用发放率作为动作概率;
- 利用仿真时间T结束后的脉冲发放率+剩余膜电压作为价值函数;Ref:Strategy and Benchmark for Converting Deep Q-Networks to Event-Driven Spiking Neural Networks - 穷酸秀才大艹包 - 博客园 (cnblogs.com)
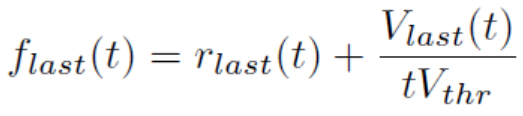
- 最后一层脉冲神经元不发放,用仿真时间T结束后的膜电压表示价值函数;
- 最后一层脉冲神经元不发放,用仿真时间T内的最大膜电压表示价值函数;
- 用一个训练好的MLP作为发放率的解码器;
- 用一个训练好的MLP作为脉冲序列的解码器。


 浙公网安备 33010602011771号
浙公网安备 33010602011771号