
End to End Learning of Spiking Neural Network based on R-STDP for a Lane Keeping Vehicle
郑重声明:原文参见标题,如有侵权,请联系作者,将会撤销发布!

IEEE International Conference on Robotics & Automation. IEEE, 2018.
Abstract
基于学习的方法已显示出在控制机器人任务方面的明显优势,例如信息融合能力,强大的鲁棒性和高精度。同时,机器人的车载系统具有有限的计算和能量资源,这与最新的学习方法相矛盾。它们太轻则无法解决复杂的问题,或者太笨重而无法用于移动应用程序。另一方面,训练具有生物合理性的脉冲神经网络(SNN)具有执行快速计算和能源效率的巨大潜力。但是,缺乏有效的SNN学习规则,阻碍了它们在移动机器人应用中的广泛使用。本文通过引入端到端学习脉冲神经网络的方法来解决这一问题,该方法用于车辆保持车道。我们认为,奖励调节的脉冲时序依赖可塑性(R-STDP)是训练SNN的有前途的解决方案,因为它结合了强化学习和著名的STDP的优点。我们在三种情况下测试了我们的方法,即控制Pioneer机器人以基于SNN保持车道。具体地,车道信息由来自神经形态视觉传感器的事件数据编码。SNN是使用R-STDP突触以all-to-all方式构建的。通过与基于SNN的其他最新学习算法进行比较,我们证明了该方法在横向定位精度方面的优势。
I. INTRODUCTION
追求自动执行复杂任务的机器人已成为现实的前景,例如以自动驾驶汽车,太空探索和协作型工业机器人的形式出现。为了获得这种高级智能并在现实世界中运行,机器人需要通过传感器来感知环境,传感器通常会传递高维数据。如今,深层网络结构已成为一种可能的解决方案,因为它具有从训练数据中提取高度非线性函数的优势。但是,深层网络的高计算需求仍然会付出巨大的代价,因为对其进行训练非常耗时,耗能,并且通常会产生高响应延迟。例如,在无人驾驶汽车中,与仅需要20瓦功率的人脑相比,整个计算要消耗几千瓦的功率[1]。这些都是相当大的缺点,尤其是在实时响应很重要且能源供应受到限制的移动应用中。
通过基于事件的脉冲神经网络可以更现实地模拟大脑的潜在机制,从而为解决这些缺陷提供了一个有希望的解决方案。在自然界中,通常使用冲动或脉冲来处理信息,从而使看似简单的生物能够很好地感知并在现实世界中发挥作用,并且在生活的各个方面都胜过最先进的机器人[2]。例如,尽管人类大脑从视网膜到颞叶至少涉及10个突触阶段,但人类大脑仅能在100毫秒内进行视觉模式分析和分类[3]。因此,就准确性和速度而言,SNN具有更有效地处理信息的巨大潜力。
另一方面,训练这类网络非常困难。由于脉冲时间的不可微性,常规神经网络中常用的误差反向传播机制无法直接传递到SNN。因此,已经没有实践的学习规则来训练SNN[4]。最初,基于SNN的控制任务是通过手动设置网络权重来完成的,例如在[5], [6]和[7]中。尽管这种方法能够解决简单的行为任务,例如墙跟踪[8]或车道保持[9],但仅对于连接很少的轻型网络才可行。在单个突触的水平上,实验表明,突触前和突触后脉冲的精确时间似乎在突触效能的变化中起着至关重要的作用[10]。借助此"脉冲时序依赖可塑性"(STDP)学习规则,已经对网络进行了各种任务的训练。例如,Wang使用接近传感器数据构造了一个单层SNN,作为条件刺激输入,然后在诸如避开障碍物和目标到达等任务中进行了训练[11, 12]。然而,仍不清楚大脑如何像反向传播一样有效地分配信度,即使一些初步研究也试图通过将反向传播与SNN结合来弥合差距[13, 4]。
之后,已经进行了一些研究,试图基于SNN中的实验结果来实现生物学合理的强化学习算法。最近提出了一种奖励调节的脉冲时序依赖可塑性(R-STDP)[14][15],它是一种结合了全局奖励信号和STDP的学习规则。这种方法旨在模仿那些神经调节剂的功能,这些调节剂是人脑中释放的化学物质,例如多巴胺。因此,R-STDP对于机器人控制非常有用,因为它可以简化外部训练信号的要求并导致更复杂的任务。
然而,由于基于R-STDP的实用机器人实现方式非常复杂,因为其将传感器数据输入SNN,构造和分配奖励给神经元以及训练SNN的复杂性。具体而言,典型的传感器数据是基于时间的,例如接近传感器和常规视觉传感器,而不是基于事件或脉冲的数据。为了将数据馈入SNN,必须以某种方式将其转换为脉冲。另外,应将奖励仔细分配给SNN,价值太高或太低都会使学习不稳定。网络权重对于学习也是至关重要的,否则学习过程将耗费更多时间甚至导致失败。
为此,本文着眼于探索基于R-STDP学习规则的SNN训练算法,并将其实现为机器人领域的端到端控制。我们的主要贡献概述如下。首先,构建一个模拟车道环境,并使用不同的车道模式进行评估,以评估算法,其中部署有动态视觉传感器(DVS)的Pioneer机器人可以直接产生视觉脉冲。其次,我们提出了一个基于事件的神经网络,该神经网络使用DVS[16]作为输入,并计算电机命令作为车道保持任务的输出。代替手动设置权重或诸如[9, 17]这样的连接,我们网络中的所有神经元都与R-STDP突触全连接,并且直接训练网络以独自学习突触权重。分别将每个电机的SNN奖励定义为车道中心距离的线性函数。该网络是在NEST中使用STDP多巴胺突触模型实现的,并使用根据机器人与车道之间的距离计算出的奖励进行训练。最后,我们分析了基于事件的神经网络的仿真结果,以证明在不同车道上的可行性,并与Braitenberg车辆控制器[9]进行了比较,以体现机器人相对于中心线的偏差的精度优势。
本文的其余部分结构如下:第二部分描述了车道保持任务的仿真环境。第三节介绍了SNN的结构和训练结果。在第四节中,分析了仿真结果,并将其与其他算法进行了比较。第五节总结了本文。
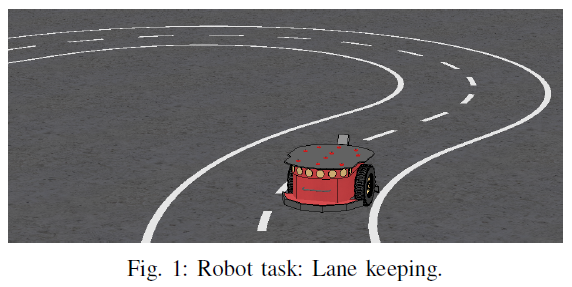
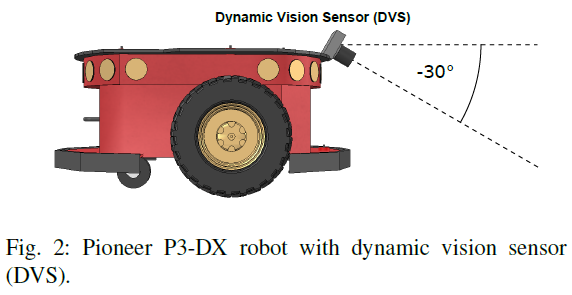
II. RIGHT LANE KEEPING TASKS
为了提供一个简单灵活的环境来测试和比较不同的算法,为案例研究机器人设置了具有不同车道模式的模拟右车道保持任务[18]作为案例研究(见图1)。
如图2所示,将DVS摄像机以30度俯角安装到机器人的前部,而不是使用板载超声波传感器。为进一步验证所提出方法的有效性和适应性,三种情况车道模式各不相同(请参见图3)。图3a中的第一种情况包括具有两车道的圆形航道。这条道路由两条实线和一条中间的虚线组成。从起始位置开始,外车道可分为六个部分,即(A) 直行,(B) 左转,(C) 直行,(D) 左转,(E) 右转,(F) 左转。在训练的每个阶段中,机器人将在每次重置时在内车道和外车道之间切换开始位置和移动方向。因此,它会同时经历左右两边的转弯,并且半径也不同。
基于相同的布局和尺寸,已经实现了第二种情况,即在缺少左实线和右实线的不同道路模式下测试算法(请参见图3b)。在第三种情况下,必须并行学习两种不同的道路模式(见图3c)。
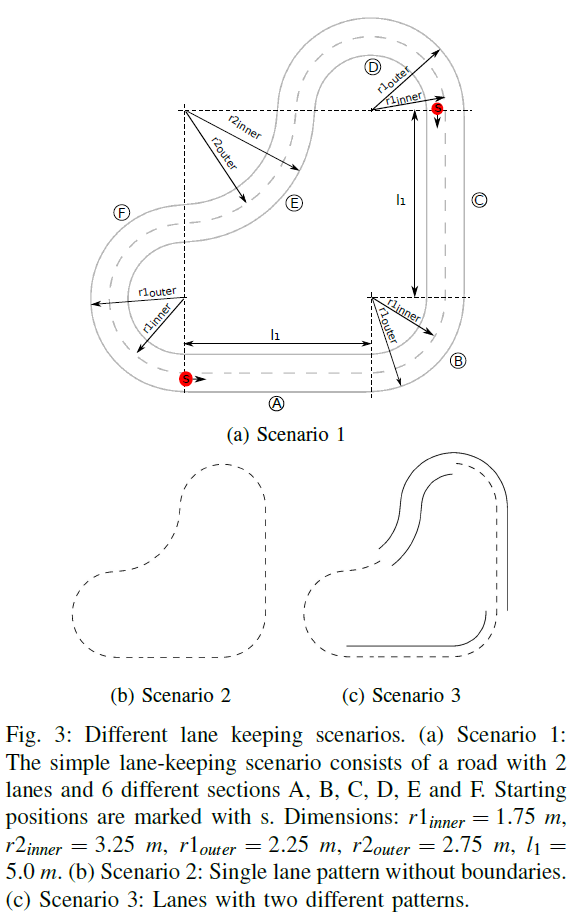
III. EVENT-BASED SNN CONTROLLER
在本节中,将对SNN控制器进行构造和训练,以使其在上述车道保持任务中操纵机器人。
A. R-STDP Learning Rule
作为神经科学中最重要的理论,它解释了大脑在学习过程中突触功效的适应性,脉冲时序依赖可塑性(STDP)学习规则[19]已通过神经科学实验成功证明[20, 21]。
对于这项工作,根据突触前和突触后脉冲之间时差的函数,将STDP下的权重更新规则定义为:
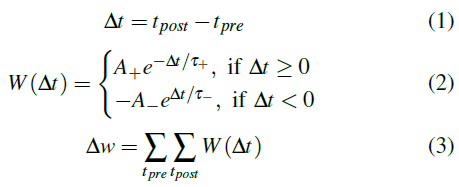
其中w是突触权重。Δw是突触权重的变化。tpre和tpost代表前神经元和后神经元的发放脉冲的时间。A+和A-分别代表正常数,可调节增强强度和抑制强度。τ+和τ-是正时间常数,定义了正负学习窗的宽度。
Izhikevich[22]和Florian[15]提出了一种结合STDP模型和全局奖励信号的简单学习规则。在R-STDP中,突触权重w随奖励信号R的变化而变化。突触的资格迹可定义为:

其中c是资格迹。spre/post表示突触前或突触后脉冲的时间。C1是常数。τc是资格迹的时间常数。Δ是狄拉克增量函数。
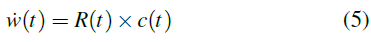
其中R(t)是奖励信号。R-STDP机制的更多细节可以在[23, 24]中找到。
B. DVS Input Generation
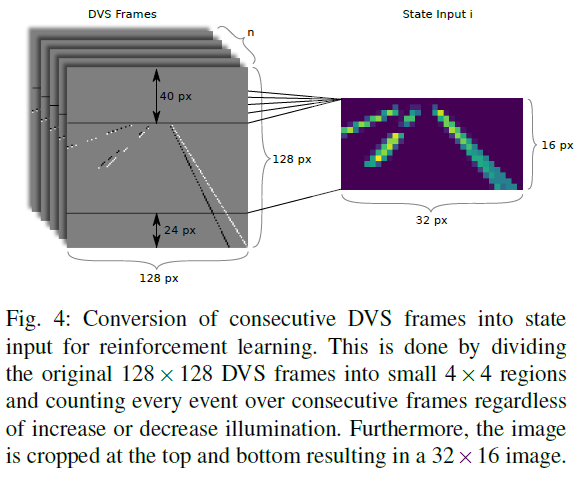
动态视觉传感器是具有生物启发性的视觉传感器,具有独立像素事件的连续输出和微秒级的时间分辨率。为了减少图像中的噪声,DVS摄像机设置为仅在模拟中检测道路标记和其他故意放置的对象。例如,地面上的强度变化将被忽略。首先,为了降低任务的计算复杂度,还将图像降低到较低的分辨率。其次,由于DVS数据的基于事件的性质,来自模拟的图像帧并不总是包含足够的信息以供网络做出有意义的决策。因此,通过将几个连续的DVS帧的信息压缩到单个图像中来计算状态输入。如图4所示,这是通过以与极性无关的方式将原始128 x 128个DVS帧划分为小的4 x 4个区域并计数十个连续帧中的每个事件来完成的。此外,图像在顶部和底部被裁剪,形成32 x 16图像。
每隔50毫秒计算和发布DVS帧(具有每个仿真时间步骤)。每500毫秒执行一次动作。因此,在一个动作步骤中,DVS帧存储在长度为10的先进先出(FIFO)队列中,然后将最后10个DVS帧转换为最终状态输入。

C. Reward Generation
代替将输入数据划分并将其馈入具有静态权重的两个单独的网络(如[9]),将其设计为基于R-STDP的单个SNN,如图5所示。对输入数据进行缩放,并用于刺激泊松神经元(在具有8 x 4 = 32个输入神经元的单个网络中)。然后,使用R-STDP突触以"all-to-all"方式将输入层连接到两个LIF输出神经元。每个仿真时间步骤给出的奖励信号如图6所示。该信号是为每个具有相反符号的电机定义的,取决于机器人到车道中心的距离。当机器人从车道中心向右行驶并应向左转以返回时,导致右侧运动神经元发放的连接会增强,导致左侧运动神经元发放的连接会减弱。在车道中心的另一侧,此过程被扭转。随着时间的流逝,机器人应学会将某些输入刺激与左转或右转关联起来并采取相应的动作。这些考虑因素导致对左右运动神经元连接的以下奖励,其中d是到车道中心的距离,而cr则是不断调整奖励的比例:
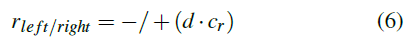

D. Encoding and Decoding
为了与SNN中的机器人传感器和电机进行通信,应将感官信息编码为输入脉冲,并将输出脉冲解码为电机命令。可以在[9]中找到类似的编码和解码处理过程。本文也实现了相同的模型,但只有一个改动。代替转向角,将计算左/右电机的转弯速度,并对其进行加法或减法。首先,输出脉冲计数![]() 由最大可能输出nmax缩放:
由最大可能输出nmax缩放:
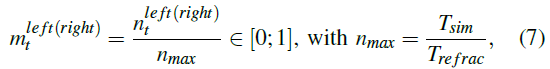
其中Tsim表示仿真时间步长,Trefrac表示LIF神经元的不应期长度。根据归一化活动![]() 和
和![]() 的差以及转弯常量cturn,将转弯速度定义为:
的差以及转弯常量cturn,将转弯速度定义为:
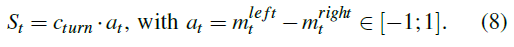
此外,为了确保依次降低速度,根据下式控制整体速度:
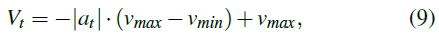
其中vmin和vmax是预定义的速度限制。由于控制汽车通常是一个连续的过程,因此可以根据以下活动来平滑总体速度和转弯速度(vt和st):
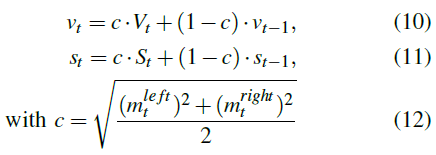
最后,左右电机的控制信号由下式计算:
![]()
E. Training
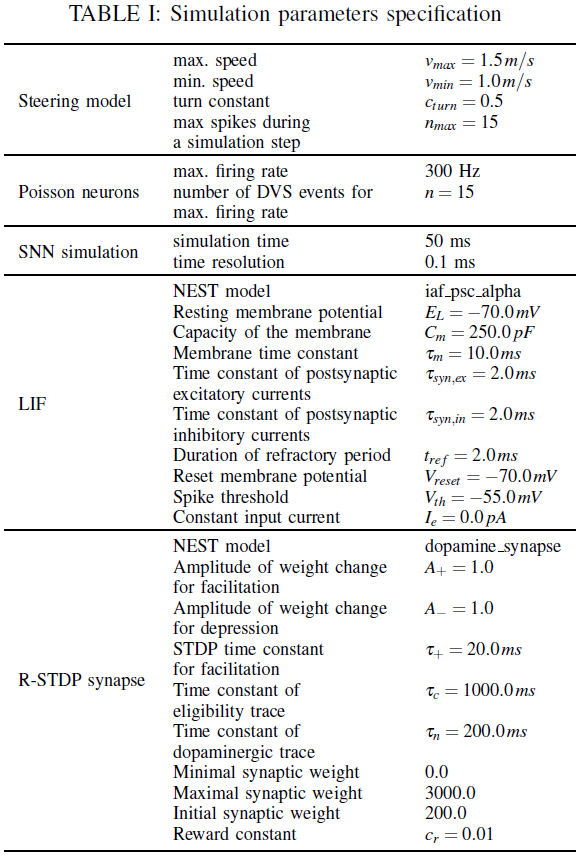
为了成功训练网络,必须仔细选择R-STDP控制器的参数(请参阅附录中的表I)。首先,训练结果与6中的奖励密切相关。如果值太低,则学习将花费太多时间,并且可能根本看不到任何进展。另一方面,如果设置得太高,学习将变得越来越不稳定,机器人将无法学习任何东西。其次,初始网络权重对于学习也至关重要。在这项工作中,权重统一以相对较低的值(200)进行初始化。权重必须大于零,因为两个运动神经元都必须从一开始就被激发,以便遵循R-STDP学习规则来引起权重变化。在最优情况下,初始权重值应在学习后尽可能接近其最终值。因此,初始权重值已被设置为学习后权重的估计均值。此外,权重被限制为[0 : 3000],仅允许进行兴奋性突触连接。
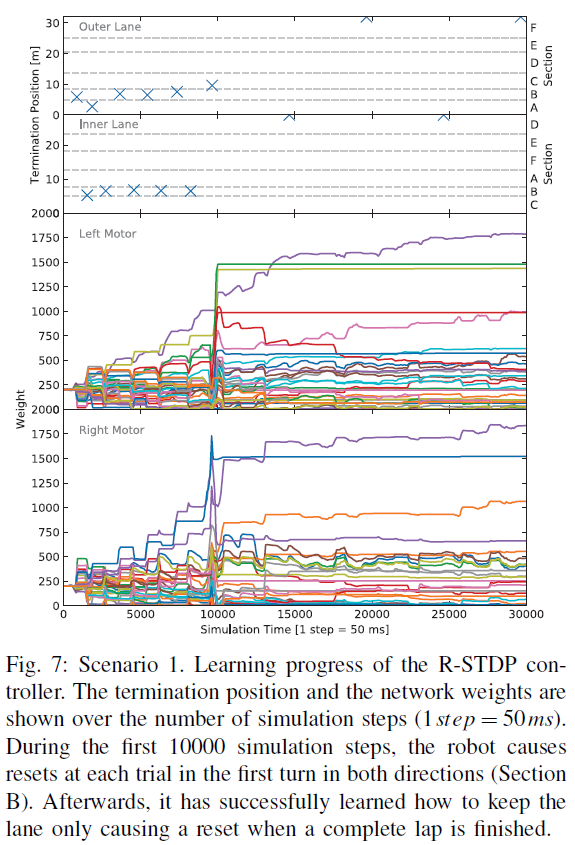
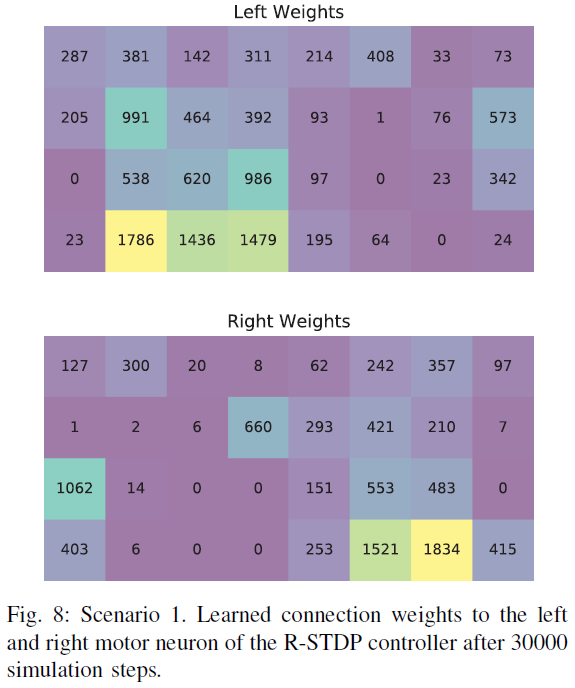
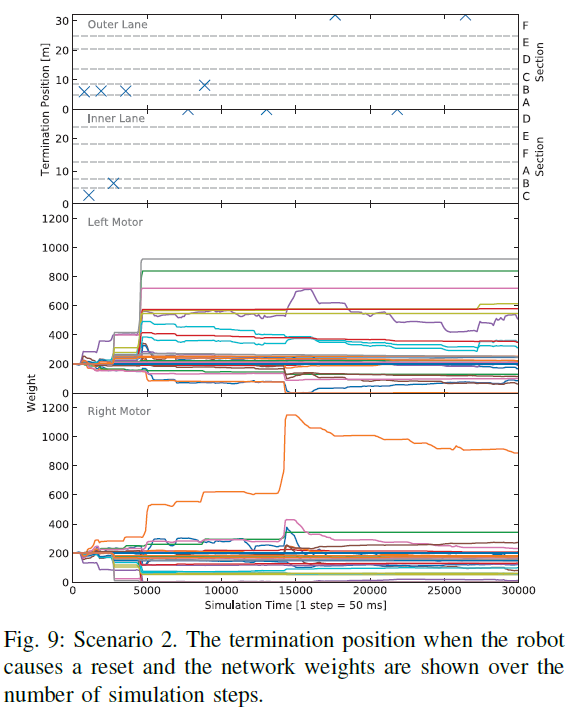
在图7中,显示了第一种情况下R-STDP控制器的训练进度。具体来说,当机器人超过车道中心距离0.2 m并导致重置时,它显示了机器人在每个路径上的终止位置。此外,在模拟过程中显示了突触权重的变化。SNN的模拟以及机器人模拟器本身的仿真步骤等效于50 ms。在训练过程的开始,由于两个运动神经元的所有连接权重都已设置为相同的值,因此机器人将直奔前进。因此,在前10000个仿真步骤中,当机器人错过转弯且车道中心距离超过0.2 m时,试验通常会在两个方向的第一个转弯处终止。每次机器人错过转弯时,它将在开始改变突触权重时周期性地诱导高奖励值。在步骤10000之前不久,机器人已经学会了转弯,但仍偏离最优车道中心位置。因此,较长时间段内的高奖励会导致连接值发生重大变化。也可以通过查看步骤10000之前不久在第一弯以外的外车道上的终止位置来找到证据。此后,控制器在两个方向上均沿车道行驶而不会引起复位。仅当机器人完成一圈后,回合才会终止。沿着两条车道接近最优车道中心位置也意味着较低的奖励值。因此,步骤10000之后的权重变化比以前小得多。经过30000个仿真步骤后获得的权重如图8所示。有趣的是,连接权重类似于Braitenberg控制器的理论得出的权重,在图像的一半处具有非常低的值,而在图像的另一半从上角到下中心增加值。此外,可以看出,左右运动神经元似乎主要是通过封闭车道的中线和右线触发的。
IV. DISCUSSION
在本节中,还将实现另外两个车道保持场景,以检查我们算法的实用性以及与Braitenberg控制器的性能比较[9]。

A. Different Task Scenarios
为了检验所提出算法的实用性,还实现了另外两种车道方案(见图3b和图3c)。
场景2中控制器的训练进度如图9所示,似乎与第一个场景非常相似,它在不到5000个仿真步骤中就完成了第一个满圈。 经过30000个仿真步骤后,控制器网络的权重如图10所示。虽然两个运动神经元左侧的网络权重类似于在方案1中学习到的连接权重,但可以很容易地看出,由于这种场景下缺少线以及在训练过程中缺乏活动,右侧的权重保持不变。
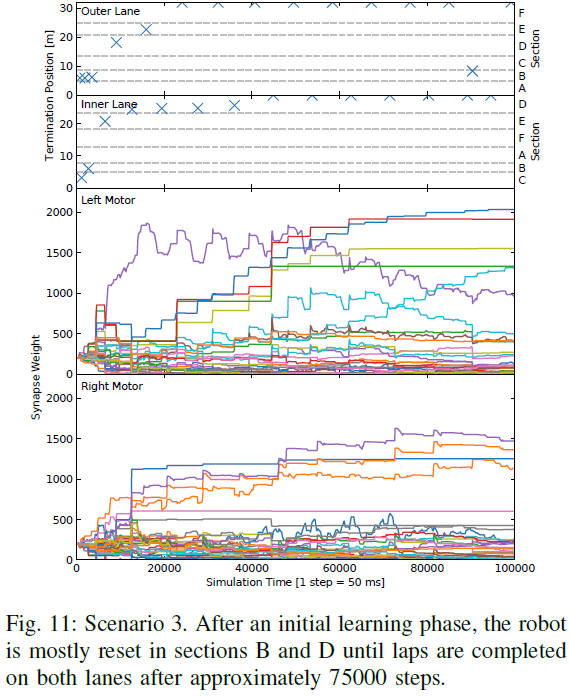
图11显示了场景3中训练期间的学习进度。首先,学习成功的控制策略所花的时间比前两个场景要多得多。对此的明显解释是,方案3合并了两种不同的道路模式,使环境更加复杂。因此,控制器必须在更多数量的不同情况之间进行区分,并减慢学习过程。此外,由于简单的事实,即直到机器人学会了如何到达那里,机器人才会遇到某些情况,因此它只会开始学习适用于两条车道的通用控制策略。在左侧的运动图中,可以看出,一些权重甚至可能在开始时就增加,然后再降低。 在初始学习阶段之后直到大约步骤20000,控制器大部分在B区(外部车道)和D区(内部车道)中复位。在大约75000步之后,当权重充分适应后,机器人将在两个车道上完成圈数。在图12中,展示了100000步之后的学习权重。与第一种方案相比,权重模式看起来非常相似,考虑到方案1中的道路模式是方案3中两种道路模式的组合这一事实,这是有道理的。

B. Performance Comparison
为了验证所提出算法的优越性,将性能与Braitenberg控制器进行了比较[9]。为了获得两个控制器的可比性能指标,在第一种场景下,对他们进行了完整的外圈评估。图13显示了在执行的一圈中机器人在预计路线位置上偏离车道中心的情况。此外,将流程分为三个部分,如图3a所示。机器人路径表示为车道中心线的投影,从而可以对控制器性能进行数值分析。具体地说,误差分布(到车道中心的距离)能够以直方图的形式显示,也可以以每个控制器的平均误差的形式显示。
首先,评估Braitenberg控制器执行相同的圈数。当控制器成功完成路线时,可以清楚地看到它强烈地倾向于车道的右侧(左:负,右:正,见图5),这可以通过机器人的视野来解释。在DVS图像的右半部分,机器人通常只能看到正确的实线。但是,在机器人的左半部分,机器人看到的是左实线以及中虚线,最终导致检测到的事件数量增加,最终导致左运动神经元的活动增加。这将使机器人向右移动,直到达到运动神经元活动的平衡为止。即使在右转弯(E部分),机器人通常也位于车道中心附近。在左转弯处,到车道中心的距离会不断增长,直到到达以前未受刺激的高权重神经元现在被激发的位置。这些将推动正确的运动神经元活动,导致运动矫正回到中心。这可以在所有3个左转弯处看到(B,D和F部分)。
在这两种控制器中,R-STDP控制器在此任务中均表现出更好的性能,并且与车道中心的偏差相对很小。当查看性能直方图和平均误差几乎比以前的误差低一个数量级时,这一点变得更加清晰。首先,可以在SNN的本质上找到对此行为的一种解释,这种SNN可以进行高频决策,而无需将时间分成离散的步骤。其次,R-STDP训练算法和相关奖励在很大程度上针对此特定问题而量身定制。基本上,R-STDP奖励可以解释为具有算法将寻求的全局最大值的预定义值函数。因此,R-STDP训练算法省去了每个经典强化学习算法所特有的状态评估步骤。
V. CONCLUSION AND OUTLOOK
R-STDP学习规则结合了强化学习和STDP机制的优点,为训练SNN提供了一个有前途的解决方案。但是,由于其在构造和训练SNN方面的复杂性,因此缺少实用的机器人实现。为了弥合这一差距,我们已经训练了一个基于R-STDP的SNN控制器,并在Pioneer机器人的车道保持任务中实现了该控制器。首先,利用DVS进行数据采集的优势,我们的算法在光照条件下趋于快速且鲁棒。此外,即使它们在单个场景中发生变化,该算法也能够学习遵循不同的道路模式。最后,与静态SNN控制器相比,该算法在机器人偏离中心线方面表现出更好的性能。
对于将来的工作,R-STDP控制器是朝着具有真正的强化学习功能的更复杂算法的第一步构建的。即使在大脑中观察到这种现象,目前的研究还没有纳入奖励预测误差。因此,将来也应使用深度架构来实现基于R-STDP的此类网络。
APPENDIX
表I中列出了所有模拟参数。


 浙公网安备 33010602011771号
浙公网安备 33010602011771号