Population-coding and Dynamic-neurons improved Spiking Actor Network for Reinforcement Learning
郑重声明:原文参见标题,如有侵权,请联系作者,将会撤销发布!

Arxiv 2021
Abstract
深度神经网络(DNN)作为强大的函数近似器,深度强化学习(DRL)在机器人控制任务中得到了出色的展示。与具有普通人工神经元的DNN相比,生物学合理的脉冲神经网络(SNN)包含多样化的脉冲神经元群体,使其在具有空间和时间信息的状态表征方面自然而然地强大。基于混合学习框架,其中脉冲actor网络从状态推断动作,深度critic网络评估actor,我们提出了群体编码和动态神经元改进的脉冲actor网络(PDSAN),用于两个不同尺度的有效状态表征:输入编码和神经元编码。对于输入编码,我们应用具有动态接受域的群体编码来直接编码每个输入状态分量。对于神经元编码,我们提出了不同类型的动态神经元(包含一阶和二阶神经元动态)来描述更复杂的神经元动态。最后,使用双延迟深度确定性策略梯度算法结合深度critic网络对PDSAN进行训练(TD3-PDSAN)。广泛的实验结果表明,我们的TD3-PDSAN模型在四个OpenAI gym基准任务上取得了比最先进模型更好的性能。使用SNN改进RL以实现满足生物学合理性的有效计算是一个重要的尝试。
1. Introduction
强化学习(RL)在机器学习算法的世界中占有一席之地[1],其中模型以试错的方式与环境交互,并通过最大化累积奖励来学习最优策略,从而达到优秀决策性能[2]。然而,对于传统的强化学习,在复杂的高维状态空间中有效地提取和表示特征是一个具有挑战性的问题。深度强化学习(DRL)通过使用深度神经网络(DNN)直接从高维原始输入中提取特征,在一定程度上解决了这个问题。因此,DRL可用于解决复杂任务[3]中智能体的决策问题,例如推荐系统[4, 5]、游戏[6, 7]和机器人控制[8, 9, 10]。
脉冲神经网络(SNN)的灵感来自于生物大脑,它自然是用于复杂环境交互强化学习的基本智能体。与具有普通人工神经元的DNN相比,SNN固有地传输和计算具有随时间分布的动态脉冲的信息[11]。SNN在时间和空间维度上基于脉冲的信息编码将有助于增强RL中更强大的状态表征[12, 13]。
SNN的输入编码尺度上有两大类信息编码(发放率和时间类型)。发放率编码使用时间窗口中脉冲序列的发放率对信息进行编码,其中输入实数被转换为频率与输入值成正比的脉冲序列[14, 15],时间编码用单独脉冲的相对时间来编码信息,其中输入值通常转换为具有精确时间的脉冲序列[16, 17, 18, 19]。除此之外,群体编码在整合这两种类型方面是特殊的。例如,群体中的每个神经元都可以生成具有精确时间的脉冲序列,并且还包含与其他神经元的关系(例如,高斯感受野),以便在全局范围内进行更好的信息编码[20, 21]。
对于SNN的神经元编码尺度,有多种类型的脉冲神经元[22, 23]。IF神经元是最简单的神经元类型。当膜电位超过发放阈值时IF神经元发放,电位会被重置为预定的静息膜电位[24]。另一个LIF神经元通过引入泄漏因子 ,允许膜电位随着时间的推移而不断缩小[22]。它们通常用作标准的一阶神经元。此外,提出了具有二阶膜电位公式的Izhikevich神经元,它可以更好地表示复杂的神经元动态,但需要一些预先定义的超参数[25]。
在本文中,基于混合学习框架,其中脉冲actor网络从状态推断动作,深度critic网络评估actor,我们提出了一种群体编码和动态神经元改进的脉冲actor网络(PDSAN)用于两个不同尺度的有效状态表征:网络外的输入编码和网络内的神经元编码。对于输入编码,我们将群体编码应用于输入状态,其中使用可学习的感受野组对每个输入组件进行编码。编码后的模拟信息直接输入网络,提高计算效率和状态表征能力。对于神经元编码,具有一阶或更高阶膜电位动态的不同类型的动态神经元(DNs)被提出,并结合群体编码以获得更强的状态表征能力。与预先定义的Izhikevich神经元不同,动态神经元从OpenAI gym[26]任务之一(例如,Antv3)中自学,然后扩展到其他类似的任务(例如,HalfCheetah-v3、Walker2d-v3和Hopper-v3)假设相似的任务很可能共享相似的参数。最后,所提出的PDSAN与双延迟深度确定性策略梯度算法(TD3-PDSAN)[27]相结合,以学习标准OpenAI gym[26]中四个连续控制任务的有效解决方案。与当前最先进的模型相比,我们提出的TD3PDSAN模型实现了更好的性能(获得的奖励)。
本文的主要贡献可以归纳为以下几个部分:
- 我们结合了空间编码和群体编码,其中输入向量(状态)中的每个模拟数字都被编码为一组具有可学习高斯感受野的模拟数字。我们还测试了空间编码和时间编码的差异(例如,进一步将模拟数字编码为脉冲序列)并得出结论,空间编码相对于其他时间编码更有效。
- 我们构建了一个具有动态神经元的多层脉冲actor网络,包含用于复杂空间和时间信息表征的一阶和高阶神经元动态。
- 凭借在输入和神经元尺度上的高效状态表征,我们提出的TD3-PDSAN模型在OpenAI gym基准测试任务上实现了新的最先进性能,包括Ant-v3、HalfCheetah-v3、Walker2d-v3和Hopper-v3。
2. Related Work
最近,文献围绕在各种RL算法中引入SNN的主题发展起来[28, 29, 30]。一些算法[31]已将连续时序差分(TD)学习[32]扩展到连续时间运行的actor-critic网络中脉冲神经元的情况。带有脉冲神经元的强化学习是通过两种不同的突触可塑性实现的:随机性和确定性[33]。这些方法通常基于奖励调节的局部可塑性规则,这些规则在简单的控制任务中表现良好,但由于优化能力有限,在复杂的机器人控制任务中通常会失败。
一些方法直接将深度Q网络(DQN)[6]转换为SNN,并在具有离散动作空间的Atari游戏中获得有竞争力的分数[34, 35]。然而,这些转换后的SNN通常表现出低于具有相同结构的DNN的性能[36]。其他方法利用反向传播(BP)算法通过用恒定微分变量替换非微分部分(近似BP)来训练SNN[37, 38]。
然后一种混合学习框架被提出,通过近似BP算法进行训练,用于移动机器人的无地图导航[39]。它包含两个独立的网络,其中具有基本LIF神经元的脉冲actor网络从发放率编码状态推断动作以表示策略,而深度critic网络通过计算动作价值来评估actor。然而,发放率编码状态的表示能力有限,这可能会影响策略的最优性,并且需要大量的时间表征以获得高性能,但代价是高推理延迟和能量成本[40, 24]。具有相同混合框架的群体编码脉冲actor网络(PopSAN)旨在增强状态表征并在复杂的连续控制任务上实现比较性能[40]。具体来说,首先将具有较低数据维度的输入状态转换为具有相对较高数据维度的每个值的刺激群体编码。然后使用计算出的刺激编码来生成神经元的脉冲序列。该方法主要在输入尺度上提高了脉冲actor网络的状态表征能力,但同时降低了计算效率。
相比之下,基于混合学习框架,我们提出的PDSAN从两个不同的尺度进一步提高了状态表征能力:网络外的输入编码和网络内的神经元编码。在输入编码尺度上,与PopSAN不同的是,在对输入状态应用群体编码后,编码后的模拟信息直接输入网络,具有较高的计算效率和表征能力。在神经元编码尺度上,动态神经元具有膜电位的一阶或更高阶动态,以描述更复杂的神经元动态,而不是具有标准一阶动态的LIF神经元。我们的模型在复杂的连续控制任务上实现了新的最先进的性能,并在输入和神经元尺度上具有有效的状态表征。此外,在SNN[41, 42, 43]中,还有其他关于有效编码以更好地表示信息的值得注意的工作。
3. Background
本节将介绍一些基本的强化学习理论及其相关的数学背景。一些可能有助于更好地理解我们模型的重要算法也得到了介绍,包括深度Q网络(DQN)[6]、深度确定性策略梯度算法(DDPG)[44]、双延迟深度确定性策略梯度算法(TD3)[27],以及混合学习框架[39, 40]。
3.1. Reinforcement learning foundation


3.2. DQNs


3.3. DDPG

3.4. TD3


3.5. Hybrid learning framework
与其深度网络对应物一样,混合学习框架中有两个独立的网络[39, 40],其中一个脉冲actor网络代表策略,一个深度critic网络评估actor。该框架中的两个网络可以使用近似BP联合训练。给定状态s,脉冲actor网络生成一个动作a,深度critic网络估计相关的动作-价值Q(s, a) (或状态-价值V(s)),进而优化脉冲actor网络使用特定的DRL算法。脉冲actor网络在功能上等同于深度actor网络,可以与任何基于actor-critic的DRL算法集成[40],例如DDPG、TD3等。
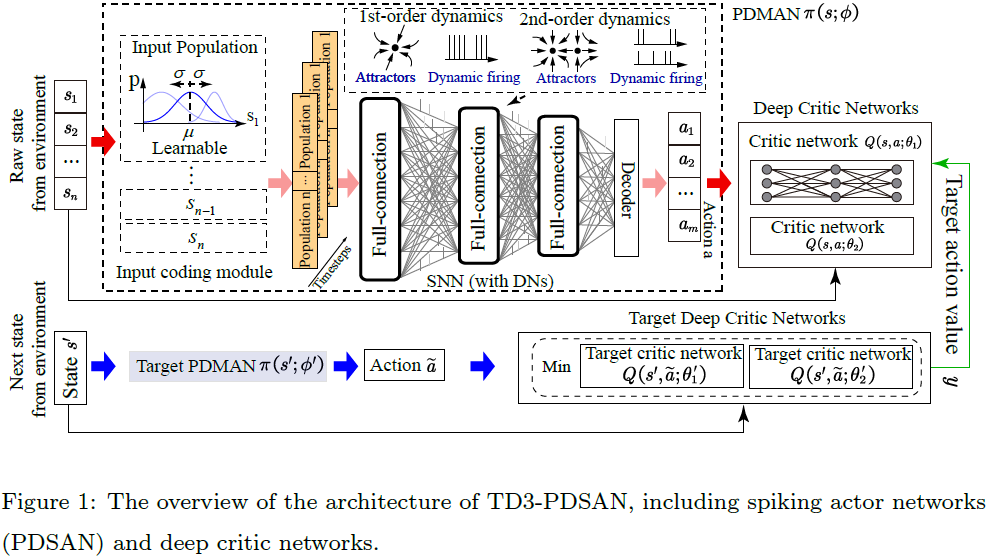
4. Methods
我们的TD3-PDSAN模型概述如图1所示。我们的PDSAN是使用TD3算法与深度critic网络(即多层全连接网络)一起训练的。在训练期间,PDSAN从给定状态s ∈ Rn推断出动作a ∈ Rm,并且深度critic网络估计相关的动作-价值Q(s, a)以指导PDSAN学习更好的策略。经过训练,学到的PDSAN可以应用到实际任务场景中,与环境进行交互。
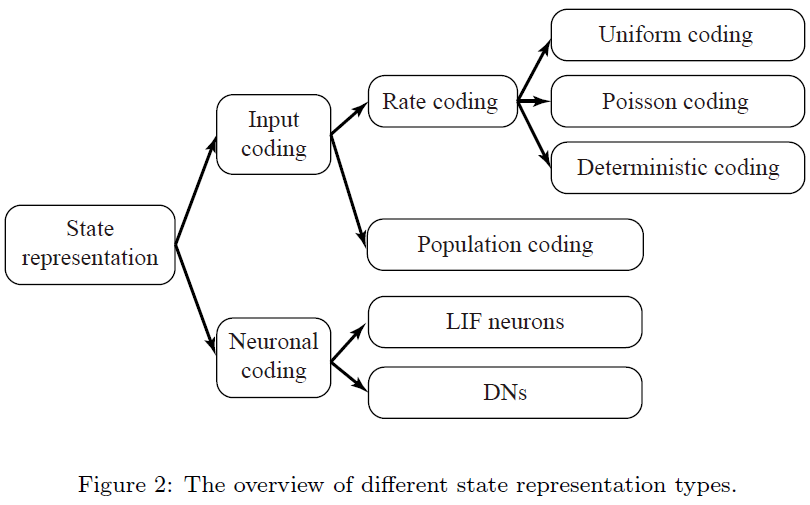
对于有效的状态表征,网络外的输入编码和网络内的神经元编码从不同的尺度提出,不同状态表征类型的概述如图2所示。在PDSAN的输入编码模块中,每个状态的维度直接使用群体编码进行编码,无需额外的发放率编码,然后馈入多层全连接SNN。SNN中的DN包含具有多达两个平衡点的二阶动态膜电位或具有多达一个平衡点的一阶动态膜电位,以描述复杂的神经元动态。与[40]类似,平均发放率被群体解码器解码为相应的动作维度。
4.1. Input coding
在本节中,我们将介绍SNN中的各种类型的输入编码方法。对于状态s ∈ Rn,每个时间步骤t = 1, 2, ... , T1,我们使用这些方法生成输入I(t), ,其中T1是SNN的时间窗口。
4.1.1. Uniform coding (uni)

4.1.2. Poisson coding (poi)

4.1.3. Deterministic coding (det)

4.1.4. Population coding (pop)

4.1.5. Population coding with rate

4.2. DNs
在本节中,我们首先介绍膜电位的常微分方程(ODE)为带有一个最大平衡点的传统一阶神经元(例如LIF神经元),然后定义改进的二阶神经元。这些神经元都被认为是SNN中神经元动态基本描述的DN。以下各节还将介绍构建这些DN的过程。
4.2.1. The traditional 1st-order neurons

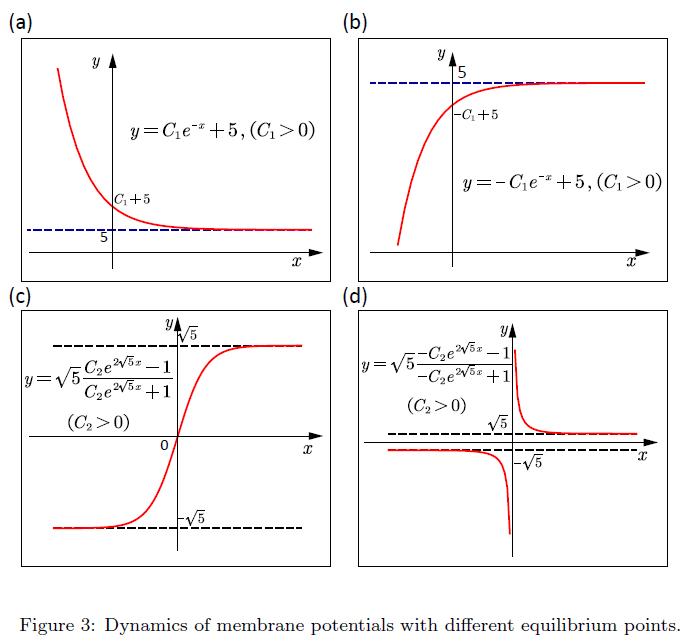
4.2.2. The designed 2nd-order neurons



4.2.3. The procedure for constructing the DNs
不同DN的构建主要基于动态神经元中一些关键参数的识别。例如,作为θa,b,c,d,这四个参数的每一个设置都描述了脉冲神经元的一个动态状态。因此,对于SNN,三层神经元(每层包含数百个神经元)将从0到1的均匀分布的随机参数初始化,如图1所示。
θa,b,c,d的这些可学习参数与其他突触权重Wi,j相结合,将使用TD3-PDSAN算法针对其中一项任务进行调整。学习之后,在大多数可学习变量到达稳定点的地方,这些参数将被绘制并用k-means方法聚类,以获得θa,b,c,d参数的最优中心。这四个关键参数将进一步用作所有任务的所有动态神经元的统一配置。
4.3. The forward propagation of PDSAN and the learning procedure of TD3-PDSAN
PDSAN的前向传播和TD3-PDSAN的学习过程分别显示在算法1和算法2(在第7节(附录)中)。

4.4. Training PDSAN with approximate BP
我们之前的工作讨论了调整多层SNN的不同方法,包括近似BP[41]、均衡平衡[51, 52]、Hopfield-like调整[53]和受生物学启发的可塑性规则[54]。在本文中,我们选择近似BP以有效学习大量参数,同时保留这些参数之间的关键关系。近似BP的关键特征是将标准BP转换为BP的分段版本,其中脉冲神经元的非微分部分可以用预先定义的梯度替换,如等式(23)所示。
在此,我们分析了PDSAN训练过程中梯度的逐步流动。![]() 是计算出的动作的损失梯度,用于优化PDSAN的参数。每个输出群体 j 的参数,j ∈ 1, ... , m,更新如下:
是计算出的动作的损失梯度,用于优化PDSAN的参数。每个输出群体 j 的参数,j ∈ 1, ... , m,更新如下:
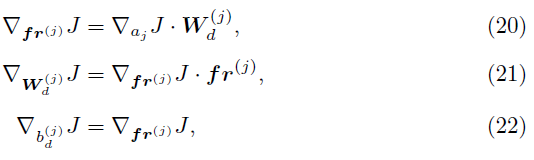
其中fr(j)是平均发放率,并且![]() 是每个输出群体的解码参数。
是每个输出群体的解码参数。
SNN的参数使用近似BP更新,其中我们使用矩形函数方程来近似脉冲的梯度。
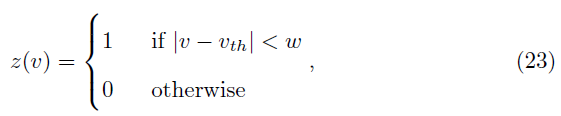
其中z是伪梯度,v是膜电压,vth是发放阈值,w是通过梯度的阈值窗口。
对于每个时间步骤t < T1,我们描述了通过SNN的梯度流。在输出群体层L,我们有:
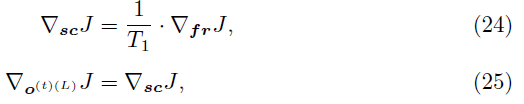
其中sc是时间窗口T1上输出脉冲的总和,o(t)(L)是第L层在时间 t 的输出脉冲。
然后对于每一层,l = L降到1:

其中 c 是电流,dc是电流衰减因子。
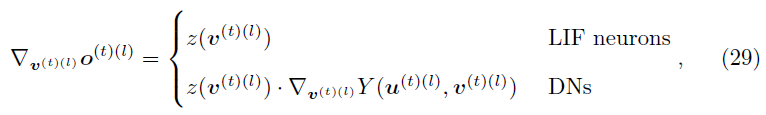
其中Y(u(t)(l), v(t)(l))的前向计算过程在算法1中。
当t = T1时,通过收集从所有时间步骤反向传播的梯度,可以计算每层 l 相对于SNN参数的损失梯度:
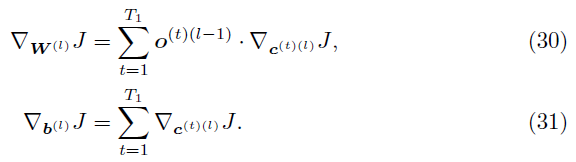
最后,我们计算了损失 J 相对于每个输入群体 i 的参数的梯度,i ∈ 1, ... , n:

我们在每个T1时间步骤之后更新PDSAN的所有参数。
5. Experiments


为了评估我们的模型,我们测量了它在来自OpenAI gym的四个连续控制任务上的性能(图4)[26]。这些任务的详细信息如表1所示。我们的实验目标如下:
- 从任务中学习DN的动态参数并分析DN的膜电位动态(第5.2节);
- 通过针对相应的深度actor网络和PopSAN(第5.3节)达到我们方法的基准性能,证明PDSAN与TD3算法的集成;
- 演示群体编码的(状态)表征能力,并比较第4.1节(第5.4节)中涉及的各种输入编码方法的性能影响;
- 验证类似任务最有可能共享类似参数的假设,即从任务中学到的DN的动态参数可以推广到其他类似任务,并展示DN对LIF神经元的(状态)表征能力(第5.5节);
5.1. Implement details
由于最近对可重复性的担忧[55],我们所有的实验都报告了超过10个网络初始化和gym模拟器的随机种子。每个任务运行100万步,每10k步评估一次,其中每个评估报告10个回合的平均奖励,没有探索噪声,每个回合最多持续1000个执行步骤。
我们将我们的TD3-PDSAN(将PDSAN与TD3算法集成)与TD3(将深度actor网络与TD3算法集成)、TD3-Pop(将群体编码和深度actor网络与TD3算法集成,它具有与TD3-PDSAN算法相同的参数量)和TD3-PopSAN(将PopSAN与TD3算法集成),其中深度actor网络和PopSAN的超参数配置与[40]中使用的相同。除非明确说明,PDSAN和PopSAN训练使用与深度actor网络相同的超参数。这些模型的超参数配置设置如下:
(1) TD3:
Actor网络是(256, relu, 256, relu, action dim m,tanh);Critic网络是(256, relu, 256, relu, 1, linear);Actor的学习率为10-3; Critic的学习率为10-3;奖励折扣因子为γ = 0.99;软目标更新因子为η = 0.005;回放缓存区的最大长度为T = 106;高斯探索噪声![]() ;噪声裁剪为c = 0.5;迷你批大小为N = 100;策略延迟因子为d = 2。
;噪声裁剪为c = 0.5;迷你批大小为N = 100;策略延迟因子为d = 2。
(2) TD3-Pop:
Actor网络是(Population Encoder, 256, relu, 256, relu, Population Decoder, action dim m, tanh);单个状态维度的输入群体规模为p = 10;输入编码使用群体编码(pop for all tasks);其他配置与TD3相同。
(3) TD3-PopSAN:
PopSAN是(Population Encoder, 256, LIF, 256, LIF, Population Decoder, action dim m, tanh),其中LIF神经元的电流衰减因子、电压因子和发放阈值分别为0.5、0.75和0.5;单个状态维度的输入群体规模为p = 10;时间窗口为T1 = 5;PopSAN的学习率为10-4;输入编码使用pop-det (HalfCheetah-v3 & Ant-v3)和 pop-poi (Hopper-v3 & Walker2d-v3)。
(4) TD3-PDSAN:
使用PDSAN (Population Encoder, 256, DNs, 256, DNs, Population Decoder, action dim m, tanh),其中MDN的电流衰减因子和发放阈值均为0.5;单个状态维度的输入群体规模为p = 10;时间窗口为T1 = 5;PDSAN的学习率为10-4;输入编码使用群体编码(pop for all tasks)。
5.2. Learn and analyze DNs

我们选择Ant-v3作为使用TD3-PDSAN预学习二阶DN的基本源任务,然后使用BP(或对于SAN的近似BP)一起训练所有参数(包括突触权重和DN的动态参数),如图5(a)所示。
如图5(b-c)所示,我们分别得到了图5(b)中参数θa和θb和图5(c)中参数θc和θd的聚类中心。为简单起见,我们在k-means中设置k = 1。DN的最优动态参数为![]() 。然后将θ*进一步用作以下经验中所有任务的所有动态神经元的统一配置。
。然后将θ*进一步用作以下经验中所有任务的所有动态神经元的统一配置。
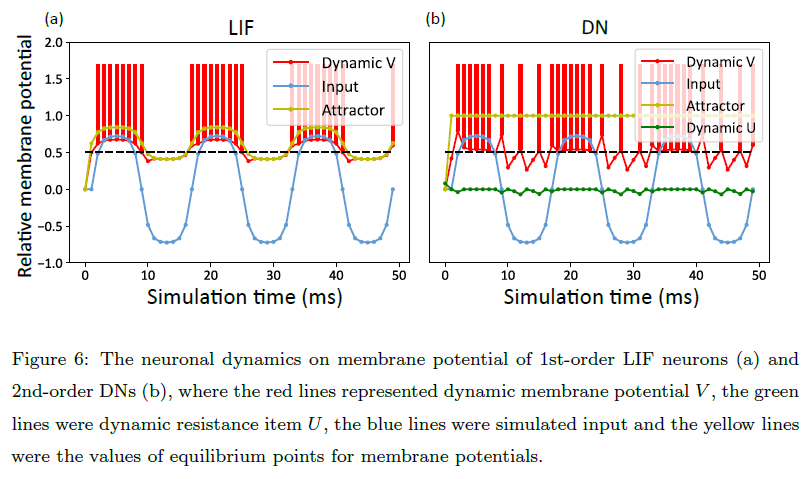
不同显性(例如,膜电位V和刺激输入I)和隐性变量(例如,电阻项U和平衡点值)的神经元动态如图6所示。
对于图6(a)中的标准LIF神经元,膜电位与神经元输入成正比。例如,对于值范围从-1到1的类sin输入,仅对于强正刺激,动态V被动态积分,直到达到发放阈值Vth,否则,相应地随着弱正或负刺激而衰减。
与LIF神经元不同,DN表现出更高的复杂性,具有额外的隐式U,使得平衡点的动态变化不同。根据DN的定义,U的微小差异会导致V的大更新,尤其是当公式(19)中的参数b较小时。因此,DN不仅会显示与正强刺激相似的发放模式,而且会在弱正和负刺激下表现出稀疏发放,而不是像LIF神经元那样停止发放。该结果表明,与LIF神经元相比,DN具有更好的动态表征。
5.3. Benchmarking PDSAN against deep actor networks and PopSAN

我们将TD3-PDSAN与TD3、TD3-Pop和TD3-PopSAN的性能进行了比较。如图7所示,我们的算法在所有测试任务中都取得了最优性能,这表明我们提出的算法对连续控制任务的有效性。另外,TD3-Pop在四项任务中的大部分(HalfCheetah-v3除外)相比TD3并没有带来任何明显的优势。图8中的进一步分析表明,与没有群体编码的网络相比,具有群体编码的脉冲actor网络实现了显着的性能改进。因此,总而言之,群体编码有助于脉冲actor网络,但对深度actor网络没有明显优势。这可能是因为当群体编码与深度actor网络相结合时,"过度参数化"网络可能难以在某些任务中训练。
5.4. The comparison of various input coding methods
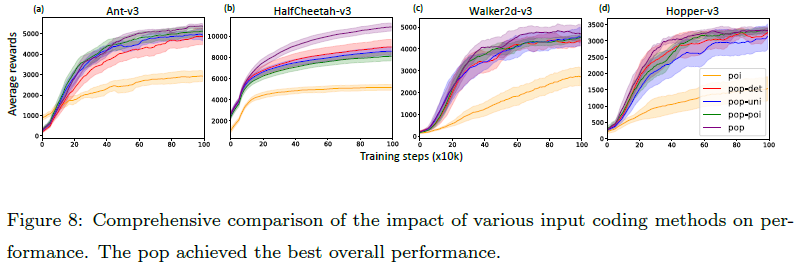
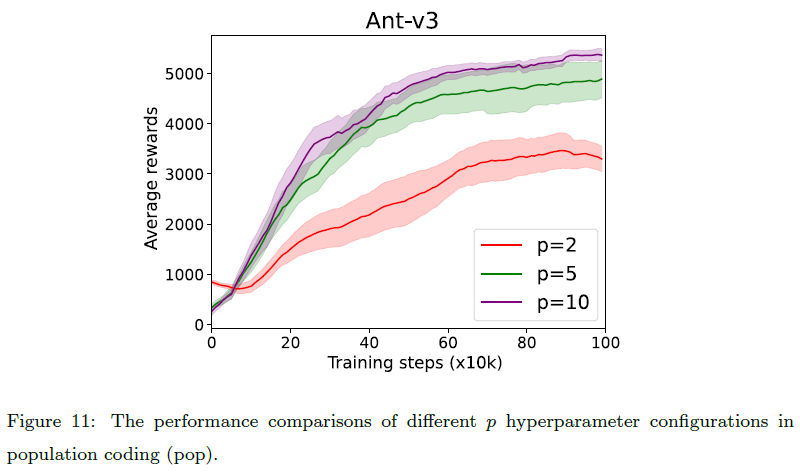
我们全面比较了各种输入编码方法对性能的影响,同时将神经元编码方法固定到DN。如图8所示,在所有四个任务上,单独的发放率编码方法(poi)的性能远不如基于群体编码的方法(pop-uni、pop-poi、pop-det、pop)。这可能是因为发放率编码方法对单个神经元的表征能力有固有的限制。对于基于群体编码的方法,pop在任务ANT-V3、HalfCheetah-v3和Walker2d-v3上取得了最优性能,在任务Hopper-v3上与其他基于群体编码的方法相当。其他三种基于群体编码的方法的性能因特定任务而异。直接使用群体编码后状态的模拟值作为网络输入似乎更有效,而无需进一步使用发放率编码将模拟值编码为脉冲序列。此外,我们评估了每个状态维度具有不同输入群体大小的pop:p = 2, 5, 10。图11(在附录7中)表明当减少输入群体的大小时,Ant-v3任务的性能下降。
5.5. The representation capabilities of DNs
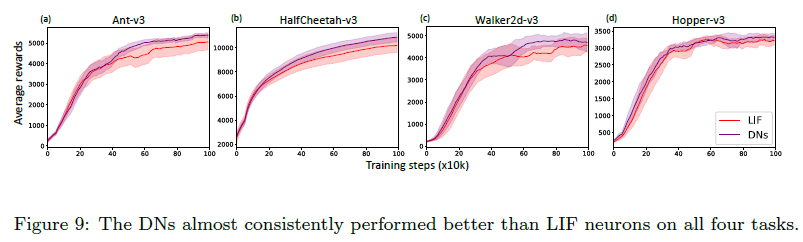
我们在所有四项任务上测试了构建的DN,并将它们与LIF神经元进行比较,同时保持输入编码方法与群体编码(pop)一致。如图9所示,DN在所有测试任务上都达到了比LIF神经元更好的性能,包括源任务(其中学习了DN的动态参数,即Ant-v3)和其他类似任务(即HalfCheetah-v3、Walker2d-v3和Hopper-v3)。这一结果最初验证了类似任务很可能共享类似参数的假设,即从任务中学到的DN的动态参数可以推广到其他类似任务。虽然没有严格的理论证明,但我们做了很多实验来进一步验证这个假设。我们收集了一组空间数据集,包括 MNIST、Fashion-MNIST、NETtalk和Cifar10,以及时序数据集,包括TIDigits和TIMIT。我们从MNIST和TIDigits中学习了一组动态神经元,分别称为空间动态神经元和时间动态神经元。然后我们测试了不同动态神经元在不同任务上的性能,结果总结在表2中。
我们可以从表2得出结论,空间动态神经元在空间任务上更强大,而时间动态神经元在时间任务上表现更好。这一结果与我们之前的假设一致,即当任务具有相似的属性和背景时,从其中一项任务中学到的动态参数可以推广到其他任务,并为其他任务带来性能提升(例如,空间动态神经元应用于空间任务)。当任务属于不同类型时,从其中一项任务中学到的动态参数会降低其他任务的性能(例如,应用于时间任务的空间动态神经元)。
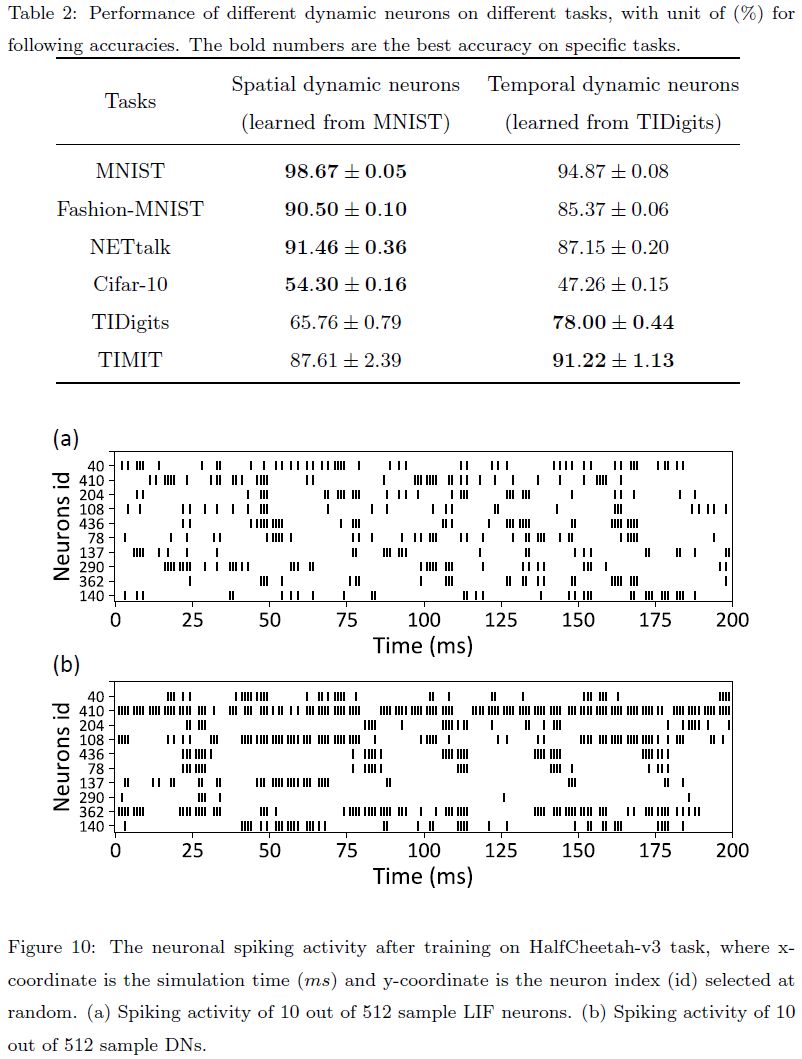
对于LIF神经元和DN之间的性能差距,了解这些神经元的性质非常重要。与具有标准一阶动态的LIF神经元不同,DN包含膜电位的一阶和更高阶动态,并表现出更高的复杂性,这有助于更强大的状态表征。此外,我们还记录了在图10中的HalfCheetah-v3任务训练后LIF神经元和DN的脉冲活动。可以观察到,LIF神经元的脉冲更稀疏,而LIF神经元的脉冲计数或发放率比DN更小,这可能是造成它们性能差距的原因之一。
6. Conclusion
状态表征在SNN和RL的研究中都很重要。本文将网络输入的群体编码和编码内部网络的DN集成到一个高效的脉冲actor网络(PDSAN)中,该网络在某些基准Open-AI gym任务。
DN使神经元具有更高的计算复杂性,显示出比简单LIF神经元更复杂的膜电位动态。我们认为在神经元尺度上共谋的增加对网络尺度的贡献更大。这一特性也可能显示出在节能计算方面的优势。此外,PDSAN中DN产生的脉冲使神经元之间的计算成本低于对应的DNN。我们认为生物学的灵感将为我们提供更多关于更好算法的提示,这些算法具有更快的学习收敛性、更低的能量成本、更强的适应性、更高的鲁棒性和更好的可解释性。
7. Appendix



 浙公网安备 33010602011771号
浙公网安备 33010602011771号