Reinforcement Learning in Spiking Neural Networks with Stochastic and Deterministic Synapses
郑重声明:原文参见标题,如有侵权,请联系作者,将会撤销发布!

Neural Computation, no. 12 (2019): 2368-2389
Abstract
尽管成功解决了各种学习任务,但大多数现有的强化学习(RL)模型未能考虑到神经系统中突触可塑性的复杂性。使用脉冲神经元实现强化学习的模型仅涉及单一的可塑性机制。在此,我们提出了一种神经合理强化学习模型,该模型可以协调两种突触的可塑性:随机性和确定性。随机性突触的可塑性是通过享乐规则以调节突触神经递质的释放概率来实现的,而确定性突触的可塑性是通过调节突触强度的奖励调节脉冲时序依赖可塑性规则的变体来实现的。我们在两个基准任务上评估所提出的学习模型:学习逻辑门函数和19态随机游走问题。实验结果表明,多种突触可塑性的协调可以使强化学习模型以快速稳定的形式学习。
1 Introduction
强化学习(RL)在机器学习领域广为人知(Sutton & Barto, 2018; Dayan & Niv, 2008; Dayan & Nakahara, 2018)。它植根于神经科学的研究,至少可以提供对Thorndike效应定律的回顾(Thorndike, 1911)。但大多数RL模型至少在两个关键方面不同于生物学习。首先,大多数强化学习模型都缺少突触可塑性,即假定的学习基础(Yu, Tang, Tan, & Li, 2013; Yu, Yan, Tang, Tan, & Li, 2016; Zenke & Ganguli, 2018)。其次,这些RL模型中的神经元产生连续可微的输出,而生物神经元通过脉冲进行交流。为了探索如何在大脑中实现RL,脉冲神经元已被引入各种RL模型(Florian, 2007; Potjans, Morrison, & Diesmann, 2009; El-Laithy & Bogdan, 2010; Potjans, Diesmann, & Morrison, 2011; O'Brien & Srinivasa, 2013; 另见表1中的摘要)。
一些方法使用基于TD学习变体的脉冲神经元实现RL (Sutton, 1988; Schultz, Dayan, & Montague, 1997)。TD学习在RL学习算法中特别有吸引力,它假设智能体通过在离散时间步骤中选择适当的动作在状态之间移动(Fremaux, Sprekeler, & Gerstner, 2013)。相比之下,脉冲神经网络(SNN)中的决策取决于连续时间的整合过程(Gold & Shadlen, 2007)。当积分值达到阈值时,触发决策。因此,在TD学习算法中直接应用脉冲神经元是困难的。为了解决这个问题,已经通过使用连续时间actor-critic架构进行TD学习开发了几种模型。例如,通过实现具有局部可塑性规则的actor-critic TD学习智能体提出了脉冲神经网络模型(Potjans, Morrison, & Diesmann, 2009)。脉冲TD学习模型是基于actor-critic架构提出的,通过动态生成多巴胺能信号并利用该信号来调节突触的可塑性作为第三个因素(Potjans et al., 2011)。
一些工作通过用第三个因素(例如全局奖励)调节脉冲时序依赖可塑性(STDP)来使用脉冲神经元实现强化学习。这种由多巴胺(与奖励相关)支持的机制已被实验证明可以调节STDP (Pawlak & Kerr, 2008; Zhang, Lau, & Bi, 2009; Pawlak, Wickens, Kirkwood, & Kerr, 2010; Fremaux & Gerstner, 2015)。已经基于这种机制提出了一些模型。例如,具有性能调节修改STDP的RL模型被提出来训练网络以学习对几种不同输入模式的不同响应(Farries & Fairhall, 2007)。涉及奖励调节的脉冲时间依赖可塑性(R-STDP)的学习规则被推导出来解决XOR问题(Florian, 2007)。R-STDP的主要思想是通过奖励项来调节STDP的结果。神经活动和奖励之间的协方差最终将推动学习朝着正确的方向发展(Fremaux & Gerstner, 2015)。
还有一些基于随机性突触传递强化的工作(Seung, 2003; Vasilaki, Fremaux, Urbanczik, Senn, & Gerstner, 2009)。假设突触传递的随机性被大脑用于学习,并且已经提出了享乐突触模型来具体实现这一想法。享乐性突触通过增加囊泡释放或失败的概率来响应全局奖励信号,具体取决于奖励之前的哪个动作。
然而,这些使用脉冲神经元的强化学习模型只涉及单一的可塑性机制,而忽略了大脑中的学习是由多种突触可塑性的合作产生的(Zenke, Agnes, & Gerstner, 2015; Hu, Tang, Tan, & Li, 2016)。此外,具有单一可塑性的模型可能有一些局限性。例如,通过享乐突触模型进行随机突触传输的RL模型受输出神经元发出的脉冲数量的影响很大,因此当模拟过程中突触后脉冲很少(或很多)时,学习变得不稳定。
构建具有多种可塑性的RL模型尚未得到很好的解决,部分原因是神经动态和突触可塑性的复杂性。在此,我们通过协调两种不同形式的突触可塑性:随机性和确定性来展示RL的新实现。随机性突触的可塑性是通过调节具有全局奖励的突触神经递质的释放概率来实现的。确定性突触的可塑性是通过R-STDP规则的变体实现的(Florian, 2007; Fremaux & Gerstner, 2015)。我们将其命名为半RSTDP规则,它根据STDP窗口的一半结果修改权重(突触前脉冲先于突触后脉冲的部分)。资格迹是事件发生的临时记录,例如采取动作或访问状态(Sutton & Barto, 2018),用于记录随机性突触的动作以及突触前和突触后确定性突触的脉冲事件。这两种不同的突触可塑性几乎在同一时间尺度上起作用。在最优情况下,半RSTDP规则的时间尺度略大于享乐规则的时间尺度。实验结果表明,多种突触可塑性的协调可以使强化学习模型以快速稳定的形式学习。
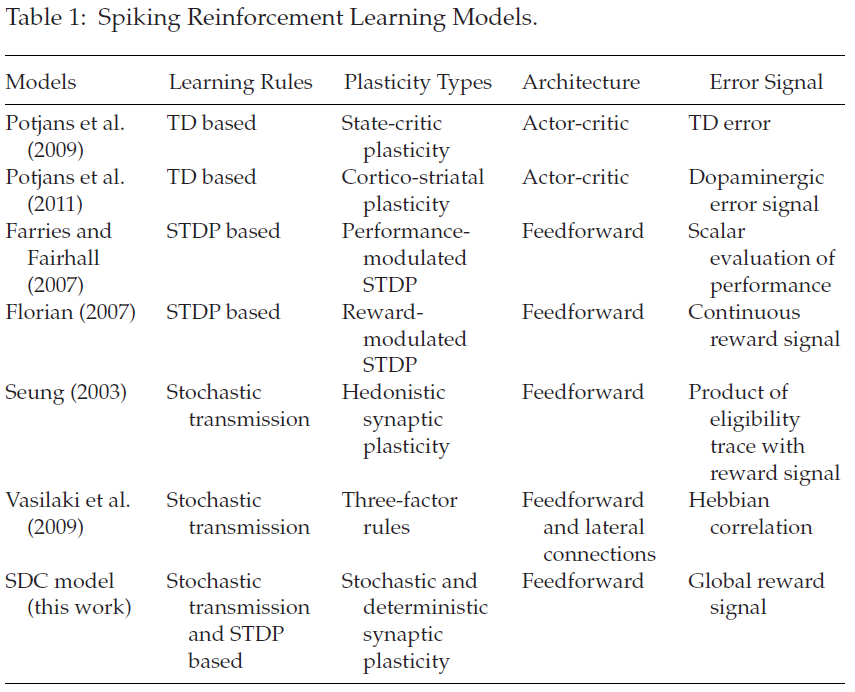
2 The Spiking Reinforcement Learning Model
如图1a所示,我们提出了一个随机性-确定性协调(SDC)脉冲强化学习模型(SDC模型),其中第一层全连接到第二层。在这个模型中,我们将第一层的突触和第二层的神经元定义为智能体,将释放神经递质(或不释放)和发放脉冲(或不发放)视为动作,将来自其他神经元的脉冲序列视为状态,将全局奖励信号作为奖励,并将网络中的学习路径视为策略(见图1b)。对于第一层,突触接收脉冲并根据释放概率参数q选择是否释放神经递质。这些动作是否会导致输出神经元的脉冲,然后可以预测奖励以更新释放概率。对于第二层,神经元根据突触权重W选择是否发放脉冲,并在收到奖励时更新权重。由于两层突触的动态不同,它们被设计为执行不同的学习函数。
2.1 The Neuron Model.
SDC模型中的神经元通过LIF公式建模;
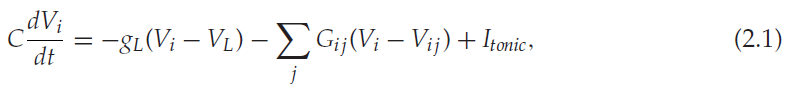
其中Vi是神经元 i 的膜电位,dt是时间步骤,C是膜电容,gL是漏电导,VL是泄漏电势,Gij是突触前神经元 j 和突触后神经元 i 之间的突触电导 , Vij是突触从神经元 j 到神经元 i 的反转电位,Itonic用于模拟来自网络外部源的tonic输入的随机火力网。
在接收到来自神经元 j 的突触前脉冲时,突触电导Gij通过下式更新:
![]()
其中Wij是突触强度,rij是突触的释放变量。随机性和确定性突触中rij的设置是不同的。如果没有突触前脉冲,则Gij随时间常数τs呈指数衰减:

当膜电位Vi达到阈值Vthr时,神经元 i 将发放一个脉冲,Vi将重置为Vreset。
2.2 Stochastic and Deterministic Synapses.
当受到突触前脉冲刺激时,随机性突触可能会释放或不释放神经递质囊泡(Stevens, 1993)。如果它释放(r = 1),神经递质将调节突触电导,有助于增强或抑制突触后膜电位。如果它不能释放(r = 0),突触前脉冲将不会对突触后膜造成影响。神经元中突触囊泡的不可靠释放被认为是大脑随机性的主要来源(Neftci, Pedroni, Joshi, Alshedivat, & Cauwenberghs, 2016)。我们的随机性突触模型基于简化的享乐突触模型,该模型对囊泡的状态进行建模(Seung, 2003; 见图2, 左)。突触以概率pij随机释放神经递质,这是参数qij的sigmoid函数。并且释放变量rij (在等式2.2中)取值为1,概率为pij,否则为0。
该模型的可塑性是由享乐主义规则驱动的。根据"享乐主义"假设(Seung, 2003),随机性突触调整其释放概率以最大化奖励:
- 如果奖励跟随释放或惩罚跟随失败,则释放概率将增加。
- 如果失败后奖励或释放后惩罚,则释放概率将降低。
因此,除了全局奖励之外,还需要一个局部资格迹(Sutton & Barto, 2018)eq来记录最近的释放和失败(见图2, 左)。由于随机性突触利用突触传输进行学习,因此这些突触的权重W不会随时间变化。
对于确定性突触模型,突触在被突触前脉冲去极化时总是会释放神经递质。因此,释放变量rij (在等式2.2中)设置为1。该模型的可塑性是通过半RSTDP规则实现的。一旦收到全局奖励信号,突触权重就会根据pre-before-post突触发放的历史进行修改,这些历史存储在资格迹ew中(见图2, 右)。下一节将介绍享乐主义规则和半RSTDP规则。
3 The RL Algorithm
为了训练SDC脉冲强化学习模型,我们提出了一种结合享乐主义规则(Seung, 2003)和半RSTDP规则的学习方法。
3.1 The Hedonistic Rule.
如果突触是享乐主义的,它们将倾向于增加在奖励之前立即执行的动作(释放或失败)的可能性。享乐规则调节释放概率以最大化奖励。当受到突触前脉冲刺激时,随机性突触以概率p释放神经递质囊泡:

这是参数q的sigmoid函数。释放参数q更新为:
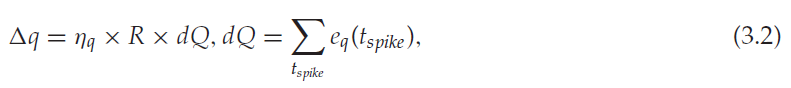
其中ηq是正学习率,tspike表示输出脉冲的时间。一旦输出神经元发放一个脉冲,突触的动作就会被资格迹eq(tspike)记录下来。它表示突触何时有资格获得强化并阶跃:

当没有突触前脉冲时,eq随时间常数τe呈指数衰减:

在输入模式呈现后,当有奖励信号R时,将使用eq(tspike)的累积来更新q。
应该注意的是,全局奖励R决定了学习方向、促进或抑制,而资格迹eq(tspike)取决于输出脉冲,决定学习量(见等式3.2)。享乐规则有一个问题:它的性能很大程度上受输出神经元发出的脉冲数量的影响。当模拟期间很少(或很多)输出脉冲时,Δq会很小(或很大),这使得精确学习奖励变得困难并导致学习不稳定。这种缺陷可以通过使用半RSTDP规则调节突触权重来弥补,该规则考虑了更多的历史信息。
3.2 The Semi-RSTDP Rule.
根据STDP模型,突触前和突触后神经元的共同激活可诱导长时程增强(LTP)或长时程抑制(LTD; Bi & Poo, 1998)。在突触后脉冲(pre-before-post脉冲对)之前的突触前脉冲发放导致LTP,而突触前和突触后脉冲(post-before-pre脉冲对)的相反顺序将导致LTD。R-STDP规则结合STDP和强化信号来调节突触变化(Fremaux & Gerstner, 2015; Florian, 2007)。它涉及pre-before-post脉冲对和post-before-pre脉冲对的结果(见图3a)。突触资格迹存储STDP结果的记忆。R-STDP的一般描述由以下等式控制:
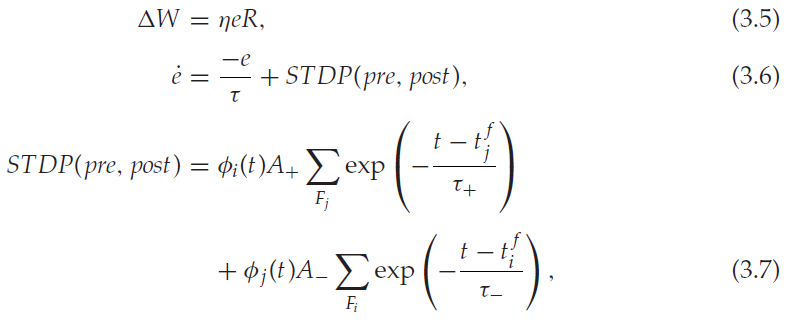
其中η是学习率,R是奖励信号,e是突触资格迹。STDP(pre, post)表示STDP的学习窗口,其中φi(t)是突触后神经元 i 的脉冲序列,由Dirac delta函数之和![]() 表示。正常数A+和负常数A−分别决定增强和抑制的强度,正时间常数τ+和τ−分别决定正负学习窗口的宽度(Florian, 2007)。
表示。正常数A+和负常数A−分别决定增强和抑制的强度,正时间常数τ+和τ−分别决定正负学习窗口的宽度(Florian, 2007)。
最近,已经发现包括post-before-pre学习窗口通常既无帮助也无害(Farries & Fairhall, 2007; Fremaux et al., 2013)。因此,在我们的模型中,确定性突触的可塑性由简化版的R-STDP规则实现,该规则仅考虑STDP窗口的pre-before-post脉冲对的记忆,称为半RSTDP规则。它被描述为:

其中ηw是正学习率,R是全局奖励信号,ew仅记录了pre-before-post脉冲对的影响(见图3b)。等式3.9中的![]() 表示第 i 个输出神经元生成的第 k 个脉冲的时间,tpre表示一个小时间窗口,它决定了发生突触后脉冲时突触修改所涉及的突触前脉冲的范围(见图3c)。在学习过程中,ew随时间常数τw呈指数衰减:
表示第 i 个输出神经元生成的第 k 个脉冲的时间,tpre表示一个小时间窗口,它决定了发生突触后脉冲时突触修改所涉及的突触前脉冲的范围(见图3c)。在学习过程中,ew随时间常数τw呈指数衰减:

对于确定性突触,突触在被突触前脉冲去极化时总是释放神经递质,即rij = 1。因此,当在时间 t 出现突触前脉冲时,突触电导更新为:
![]()
否则,如上所述,Gij(t)呈指数衰减。
当有奖励信号R时,权重Wij将被更新。如果奖励为正,则有助于输出脉冲的权重将根据ew加强,如果奖励为负,则权重将被压低。因此,半RSTDP规则训练输出神经元为奖励行为发放更多的脉冲信号,或为惩罚行为发放更少的脉冲信号。
3.3 Integration of the Two Plasticities.
由于不同的可塑性导致不同的特征,不同可塑性的相互作用已被证明是记忆回忆和检索等认知功能所必需的(Zenke et al., 2015; Hu et al., 2016)。在Zenke et al. (2015)的工作中,赫布可塑性、快速非赫布可塑性和较慢稳态变化的相互作用导致脉冲神经网络中的记忆形成和回忆。
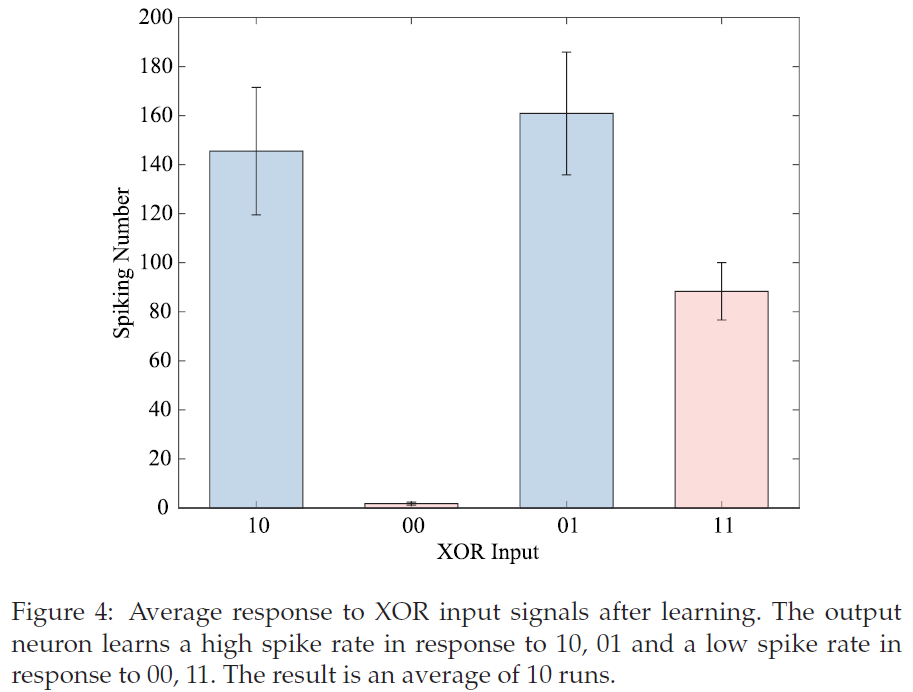
在我们的模型中,随机性突触的可塑性由享乐规则产生,确定性突触的可塑性由半RSTDP规则产生。这两种不同的可塑性可以在几乎相同的时间范围内很好地协同工作。在最优情况下,享乐规则的时间尺度略小于半RSTDP规则,即τe略小于τw (见图9)。根据公式3.4和3.10,τe和τw实际上分别用于决定资格迹eq和ew的有效范围。时间尺度越大,历史事件的记忆衰减越慢,资格迹的有效范围越大。第一层的享乐规则主要用于快速学习,而输出层的半RSTDP规则主要用于奖励的精确学习,所以需要考虑稍长的历史信息。我们也考虑使用两个学习规则的不同学习率。享乐主义规则的学习率将大于半RSTDP规则的学习率。因此,可以使用半RSTDP规则进行微调。图5和图7的结果表明,该模型以快速且稳定的形式学习。
我们提出的学习算法在算法1中以伪代码的形式给出。


4 Results
所提出的学习模型协调了两种不同形式的突触可塑性,为脉冲神经网络中的RL提供了一种新模型。半RSTDP规则补充享乐规则以实现稳定学习,而享乐规则补充半RSTDP规则使得学习速度快。为了验证所提出模型的学习效果,我们设计了几个实验,包括学习逻辑门和学习19态随机游走。
4.1 Learning a LogicGate.
活动瞬变的可靠门控是正常大脑功能的先决条件(Kremkow, Aertsen, & Kumar, 2010)。这要求信号路径根据信号的信息内容和接收器的处理需求动态改变(Vogels & Abbott, 2005, 2009)。这需要对信号传输路径进行精确控制和门控。学习XOR门是人工神经网络的一个基准问题。还有一些其他的RL方法可以解决这个问题(Florian, 2007; Seung, 2003; Xie & Seung, 2004)。
首先,我们考虑与Seung (2003)中设置类似的发放率编码输入。信号1由频率为40 Hz的泊松脉冲序列表示,信号0由频率为0 Hz的泊松脉冲序列表示。有四种信号模式:10, 00, 01, 11。网络结构设置为[60, 60, 1],60个输入神经元的前半部分代表第一个输入信号,后半部分代表第二个输入信号。模拟是通过依赖输出神经元的活动产生奖励或惩罚来完成的。例如,当信号模式为10或01并且输出神经元发出脉冲时,突触将得到奖励。当输入为00或11且有输出脉冲时,突触会受到惩罚。随机性突触的兴奋性Wij呈指数分布,平均为2.4 nS,而抑制性Wij呈指数分布,平均为45 nS。确定性突触的初始兴奋性和抑制性Wij的值正态分布,均值为0.8,标准差为0.1。享乐规则和半RSTDP规则的学习率分别设置为0.1和0.0001。算法1的主要参数总结在表2中。
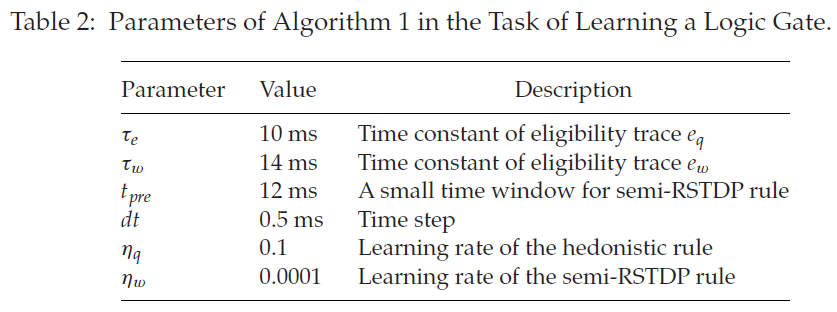
在学习期间,对于每个epoch,随机生成的四种信号模式各呈现500毫秒。我们认为,如果输出神经元激发更多脉冲以响应信号模式10、01而非00、11,则网络成功地学习了XOR逻辑门。
图4显示网络成功地学习了逻辑门。学习过程如图5a所示。有两个学习阶段。一开始,输出神经元发出比其他三种信号模式更多的脉冲来响应11。在这个阶段,享乐规则对抑制脉冲起到了重要作用,因为更多的脉冲对随机性突触给予更高的惩罚。同时,半RSTDP规则与享乐规则共同作用来训练网络。在100个epoch内,响应11的脉冲可能比响应10和01的脉冲少,并且脉冲在随后的epoch中保持稳定。然而,Seung (2003)中描述的网络通过单个突触可塑性(随机性突触传输)实现任务,需要多达200个epoch才能获得一个好的解决方案。此外,确定性突触的平均权重变化也反映了这种趋势(见图5b)。
4.2 Learning 19-State Random Walk.
在强化学习中广泛研究了具有一维马尔可夫决策过程环境的19态随机游走(De Asis et al., 2018; Sutton & Barto, 2018)。每个状态的智能体都有两个相邻的状态,如图6所示,并以相等的概率向左或向右移动。中心状态被设置为起点。环境的每一端都有一个终止状态。当达到正确的终止状态时,会发出奖励信号。当达到左终止状态时,发出惩罚信号。在所有其他状态下,学习阶段只是以没有奖励或惩罚的方式结束。
在模拟中,我们将网络结构设置为[190, 100, 10]。动作由10个输出神经元编码。前半部分代表向左走,后半部分代表向右走。每个状态由10个泊松神经元编码,发放率为50 Hz。由于网络中的G,W,q等参数是随机初始化的,对方向没有偏好,所以动作由输出活动随机决定。更具体地说,如果前半部分输出神经元的平均发放率比后半部分大,智能体会往左走,否则往右走。如果前半部分输出神经元的平均发放率等于后半部分,则智能体将随机选择一个方向。
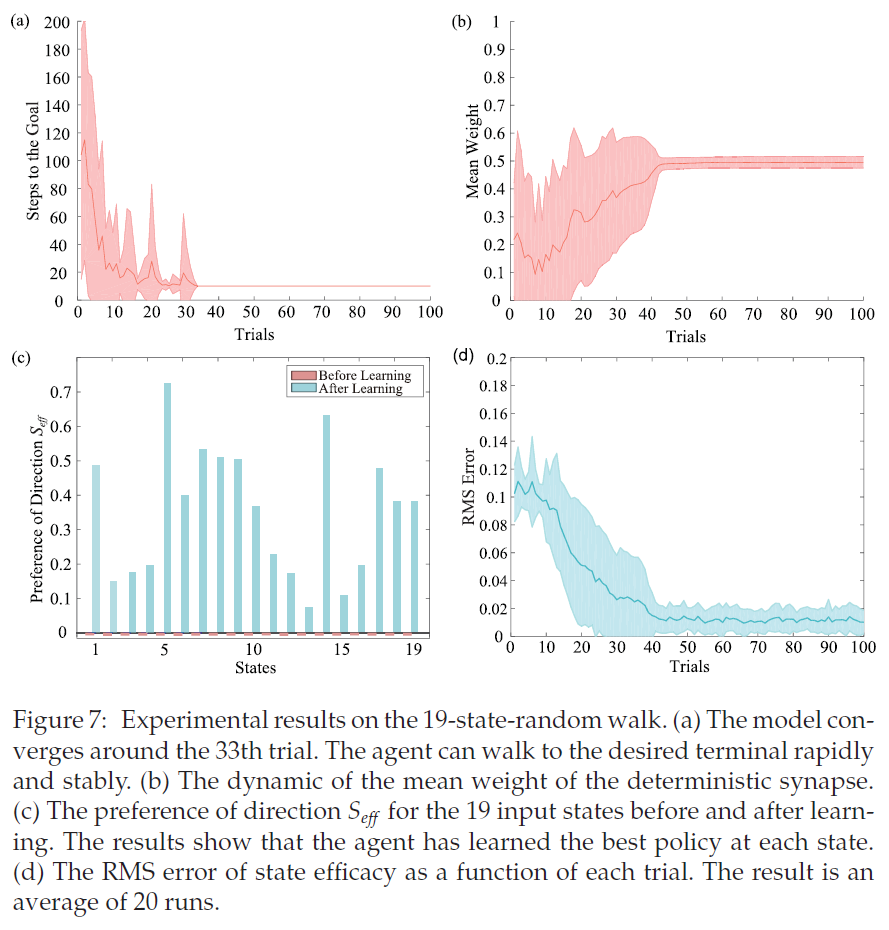
图7a说明了学习算法的收敛速度。一开始,智能体在状态空间中随机行走。因此,网络需要许多步骤才能到达所需的终端或无法步行到所需的终端。一旦智能体到达所需的终端,它将获得奖励信号以加强突触参数。最后,智能体只需10步就可以到达所需的终端。随机性和确定性突触可塑性的配合使网络能够快速稳定地学习具有最优策略的所需路径。平均权重的变化说明了这个过程(见图7b)。
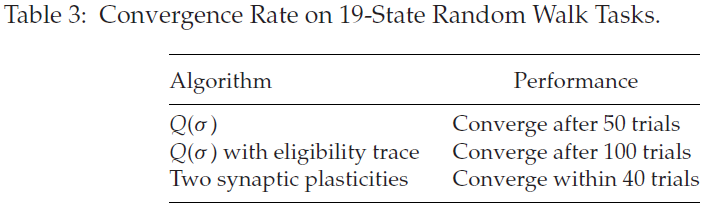
表3总结了不同算法在19态随机游走上的性能。在De Asis et al. (2018)的工作中,Q(σ)是一种改进的多步时序学习算法,它统一了n步Tree-Backup和n步Sarsa,在对这个任务进行了大约50次试验后收敛。在Yang, Shi, Zheng, Meng和Pan (2018)中,Q(σ )结合资格迹在此任务上进行了大约100次试验后收敛。所提出的协调两个突触可塑性的模型在40次试验中学习任务,这优于前面这些方法。
为了进一步分析网络如何学习19态随机游走任务,我们定义了Weff来表示每个输入状态的网络效率。网络效能整合了学习参数q和W的效能。Weff被描述为:

其中Vrs和Vrd分别存储随机性和确定性突触的类型。对于兴奋性突触,Vrs(Vrd) = 1;否则,Vrs(Vrd) = −1。第一项表示随机性突触的效能,第二项表示确定性突触的效能。如上所述,动作(左或右)由前半和后半部分输出神经元的平均发放率决定。我们测量每个状态下的方向偏好为![]() ,其中
,其中![]() 是前半部分输出神经元的平均网络效能,
是前半部分输出神经元的平均网络效能,![]() 是后半个输出神经元的平均网络效能。Seff的负值表示对左方向的偏好,正值表示对右方向的偏好。如果Seff的值接近于零,则智能体在这些状态下没有偏好。
是后半个输出神经元的平均网络效能。Seff的负值表示对左方向的偏好,正值表示对右方向的偏好。如果Seff的值接近于零,则智能体在这些状态下没有偏好。
图7c显示19个状态的Seff在学习前接近于零,这意味着输出神经元对方向没有选择性。即,智能体最初在每个中间状态中以相同的概率向左或向右移动。学习后,Seff大于零,输出神经元表现出对正确方向的选择性。因此,智能体倾向于在每个状态下选择正确的方向。图7d说明了实验的均方根(RMS)误差。在传统的RL模型中,RMS误差用于评估学习值函数和目标值函数之间的误差。在我们的模拟中,Seff表示反映首选方向的学习值。目标值设置为正,表示所需的方向(右)。学习后,每个状态的智能体都有对正确方向的偏好,这会导致快速步行到所需的终端。
5 Exploring the Learning in SDCModel
为了更详细地研究所提出的SDC模型的特性,我们重复了19态随机游走实验,改变了模型的参数。我们认为,如果学习值和目标值之间的RMS误差小于0.01并且在随后的5次试验中保持稳定,则网络实现收敛。从学习的角度来看,收敛时的RMS误差越小,性能越好。
5.1 The Influence of Parameter tpre.
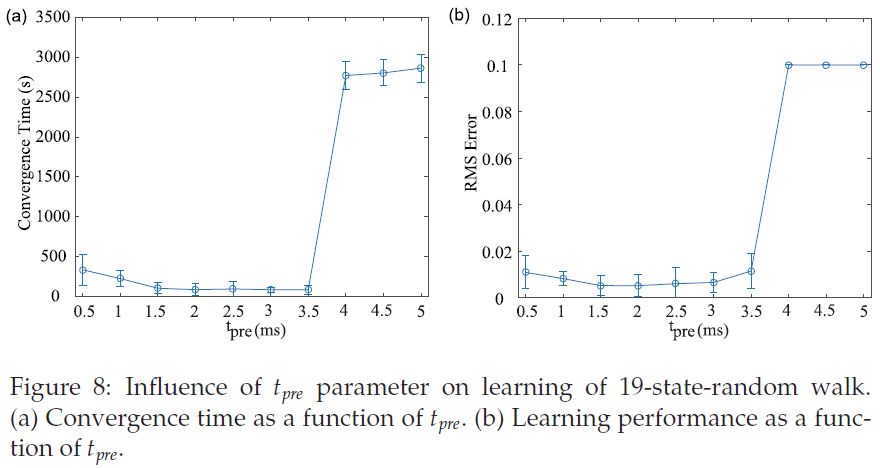
参数tpre是半RSTDP规则所涉及的pre-before-post部分的学习窗口。当发生突触后脉冲时,它确定了符合突触修改条件的突触前脉冲范围(见图3c)。在此,我们通过重复不同值的19态随机游走实验来研究对学习速度和性能的影响。收敛时间和学习性能分别如图8a和8b所示。当tpre的值小到0.5 ms (一个时间步长)时,即考虑当前突触后脉冲之前仅一个时间步骤内的突触前脉冲,由于被包括的突触前脉冲很少而一些信息被忽略,需要更多时间达到收敛。同时,突触变化很小,需要更多的时间才能达到收敛。增加tpre的值(从1.5 ms到3 ms)会导致更快的收敛和更好的性能。对于这个任务,1.5ms到3ms是tpre的合理范围。当tpre的值大于这个范围时,收敛时间变慢,性能变差,因为考虑了太多的突触前脉冲,突触变化太大。这使得收敛变得困难。
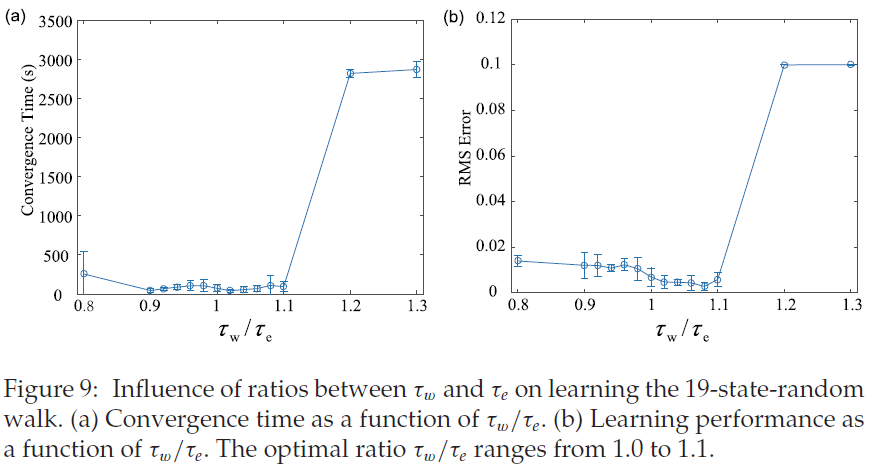
5.2 The Effect of Ratios between τe and τw.
如上所述,τe和τw分别是资格迹eq和ew指数衰减的时间常数。它们实际上用于决定资格迹的有效范围。为了研究τe和τw之间的比率对学习性能的影响,我们重复了19态随机游走实验的学习,将τe的值固定为500 ms,并通过改变τw的值来考虑不同的比率。当这些比率范围为1到1.1时,即τw略大于τe时,可以实现最快收敛和最优性能。实验表明,当τw略小于τe时,网络也能达到较好的性能,但不如最优性能(见图9)。原因是较低的τw会导致ew的衰减更快,因此有关pre-before-post脉冲对的历史信息会迅速丢失,从而导致振荡。当τw取最大值时——本实验中为600 ms或650 ms——网络性能相当差,因为考虑了大量冗余的历史信息。在这种情况下,所有突触都倾向于采用最大或最小允许值,而对于学习有效的情况,学习后突触的分布应该趋于均匀,如图7b所示。
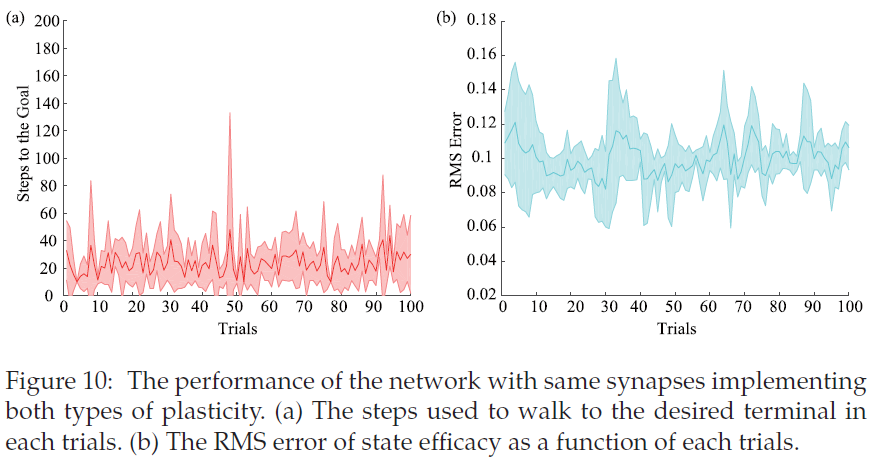
5.3 The Same Synapses Implement Both Types of Plasticity.
我们在SDC模型中考虑具有不同可塑性的不同突触,因为生物学习依赖于不同突触可塑性的合作。由于不同的学习动态,单个突触仅实现单个可塑性。为了研究实现这两种可塑性的突触的学习性能,我们设计了一个具有相同神经元的新模型,并重复了19态随机游走实验。在新模型中,每个突触都有两个可训练的参数q和W,学习规则如前所述。
如图10a和10b所示,具有两种可塑性的突触不能很好地解决19态随机行走任务。学习过程波动不规则,没有收敛的趋势。原因可能是,尽管这两个塑性是由相同的奖励,他们在自己的方向上分别发展,造成波动附近的局部最小值。
6 Discussion
使用生物模型和突触可塑性的强化学习是一个未充分探索的问题。现有模型(Potjans et al., 2009, 2011; Farries & Fairhall, 2007; Florian, 2007; Vasilaki et al., 2009)涉及单一的可塑性机制,忽略了大脑中的学习是由多种突触可塑性的合作产生的(Zenke et al., 2015; Hu et al., 2016)。在此,我们提出了一种新颖的RL模型,该模型具有用于脉冲神经网络的随机性和确定性突触。在我们的模型中,随机性突触的可塑性是通过享乐规则通过全局奖励调节突触传递的释放概率来实现的。确定性突触的可塑性是通过半RSTDP规则通过调节突触强度来实现的。网络通过反复试验来调整选择,从而学习最大化长期平均回报。学习逻辑门函数和19态随机游走任务的实验结果表明,与现有模型相比,我们具有随机性和确定性突触的RL模型可以快速稳定地获得最大奖励。该模型为如何协调不同的突触可塑性以构建复杂任务的神经现实RL提供了新的见解。也就是说,具有适当时间尺度的不同形式的突触可塑性可以协调神经活动以实现快速稳定的学习。


 浙公网安备 33010602011771号
浙公网安备 33010602011771号