
On-chip trainable hardware-based deep Q-networks approximating a backpropagation algorithm
郑重声明:原文参见标题,如有侵权,请联系作者,将会撤销发布!

Neural Computing and Applications, pp.1-12, (2021)
Abstract
使用深度Q网络(DQN)的强化学习(RL)在许多复杂问题中表现出超越人类水平的性能。此外,鉴于这些技术能够实现并行操作和低功耗,许多研究都集中在基于仿生硬件的脉冲神经网络(SNN)。在此,我们提出了一种适用于基于硬件的SNN的DQN片上训练方法。由于传统的反向传播(BP)算法是近似的,基于两个简单游戏的性能评估表明,所提出的系统实现了与基于软件的系统相似的性能。所提出的训练方法可以最大限度地减少内存使用并降低功耗和面积占用水平。特别是对于简单的问题,在不使用回放内存的情况下实现高性能,可以显着降低内存依赖性。此外,我们研究了非线性特性和非理想突触装置的两种变化对性能结果的影响。在这项工作中,薄膜晶体管(TFT)型闪存单元被用作突触器件。还使用IF神经元的全连接神经网络进行模拟。由于采用了片上训练方案,因此所提出的系统对设备变化具有很强的免疫力。
Keywords Reinforcement learning (RL) • Hardware-based deep Q-networks (DQNs) • On-chip training • Synaptic devices
1 Introduction
最近,受人脑启发的神经形态计算已成为最有前途的计算架构类型之一。它克服了传统冯诺依曼架构的局限性,该架构与内存和处理器之间的瓶颈有关,并在时间和功耗方面具有优势[1-3]。两种训练方法最常用于训练神经网络:反向传播(BP)算法和脉冲时序相关可塑性(STDP)学习规则[4, 5]。BP算法反向传播从输出层获得的误差值,并通过这些误差值更新突触权重。适用于处理标记数据,主要用于离线监督学习。使用BP算法的基于软件的深度神经网络(DNN)在许多领域都表现出高性能[6-8]。然而,这种训练算法需要大量的时间和功率来确定误差值[4]。STDP学习规则受到生物突触权重变化的启发,主要用于在线无监督学习。与BP算法不同,突触权重根据突触前和突触后脉冲之间的时间差进行更新[9]。STDP学习规则的优势在于,通过启用事件驱动操作和片上训练,神经网络消耗更少的功率。然而,与BP算法[10-13]相比,它仍然缺乏性能。
为了低功耗和高速度,使用电子突触设备的电导作为突触权重的基于硬件的脉冲神经网络(SNN)已得到积极研究[14-17]。基于硬件的神经网络可以以低功耗执行大规模并行计算。在使用BP算法训练基于硬件的神经网络时,最常用两种方法:片外训练方法,将使用BP算法在软件中训练的权重值简单地传输到突触设备,以及片上训练方法在训练过程中不断更新突触权重的方法[4]。片外训练使用更多功率,因为权重更新的训练过程发生在软件中。此外,由于非理想突触装置的变化,性能可能会降低[5, 18]。另一方面,片上训练不受非理想突触装置变化的影响[10, 19-22]。鉴于其低功耗和高速训练能力,这种方法也具有优势,因为加权和与权重更新都发生在基于硬件的神经网络[5, 23, 24]中。最近,几项研究调查了低功耗和良好性能结果的片上训练[25-27]。基于硬件的神经网络的片上训练表现出与传统的基于软件的神经网络非常相似的性能。
因此,我们专注于在基于硬件的神经网络中使用BP算法的片上训练方法。鉴于其与STDP学习规则相比具有相对较高的性能、低功耗、高速训练能力以及与片外训练方法相比对非理想突触设备的变化具有很强的免疫力,这是有利的。虽然已经在各种网络上进行了多项与片上训练相关的研究,但据我们所知,还没有关于片上强化学习(RL)的研究报告。RL实现了人类级别的性能,这是使用简单的DNN难以实现的[28, 29]。在具有复杂问题的RL中,首选使用深度Q网络(DQN)进行训练,因为使用这种方法时的性能水平已经在多个领域超过了人类水平[28-32]。
在这项工作中,我们提出了一种使用普通DQN的RL片上训练方法,同时最大限度地减少内存使用。虽然已经报道了几种适用于RL的训练方法,但普通DQN被用作一种简单的训练方法,适用于实现基于硬件的RL[31-38]。此外,还考虑了非理想突触装置的非线性特性和变化。考虑了非理想突触设备的两种类型的变化:脉冲到脉冲的变化和设备到设备的变化。整个训练过程分为四个阶段:两个前向阶段、一个后向阶段和一个更新阶段。而且,对于简单的问题,可以在不使用回放内存的情况下训练网络,从而显著降低内存依赖性。我们使用先前提出的神经元电路[39]和突触装置[40]来评估提出的训练方法。训练方法的性能通过两个示例游戏进行评估:"Fruit Catching"游戏和"Rush Hour"游戏。
本文组织如下。第2节介绍了这项工作中使用的突触设备的特征以及针对基于硬件的DQN提出的训练方法。第3节提供了基于两个简单游戏的所提出的基于硬件的神经网络的系统级仿真结果以及对结果的讨论。第4节总结了整篇论文和未来的工作。
2 Device characteristics and training method
2.1 Synaptic device
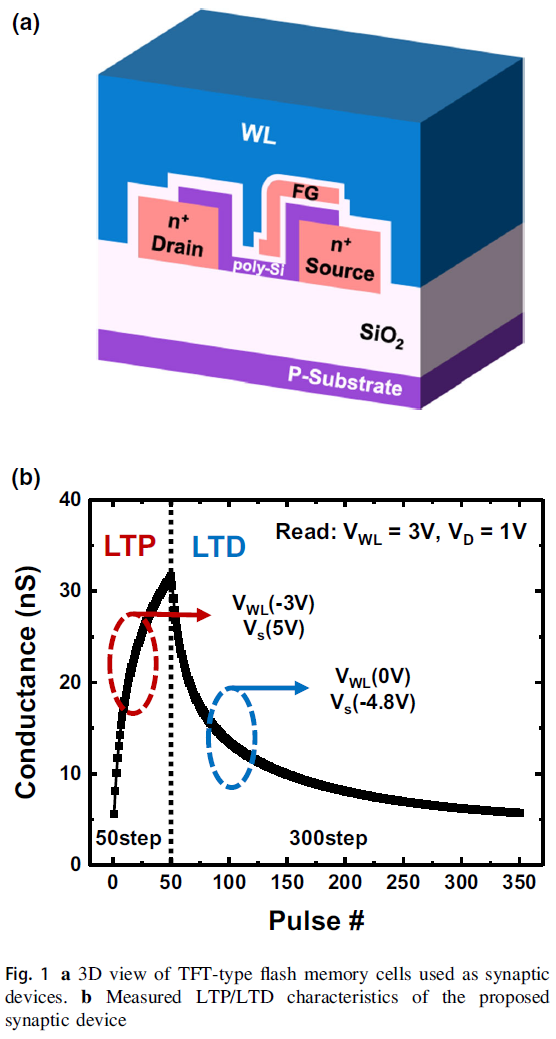
在基于硬件的神经网络中,表示权重值的突触设备非常重要。在这项工作中,我们使用利用作者早期报告中发表的方法制造的薄膜晶体管(TFT)型闪存单元作为突触设备[40]。所提出的突触装置的示意性3D视图如图1a所示。TFT型闪存单元采用传统CMOS工艺技术在6英寸硅晶片上制造。在字线(WL)和源线(SL)之间,有一个半覆盖的n+多晶硅浮点门(FG)形成为电荷存储层。由于FG仅覆盖多晶硅通道的一半,因此在完全擦除状态下阈值电压不会低于0。这可以防止泄漏电流并降低训练过程中的待机功耗。多晶硅有源层、隧道SiO2层、阻挡SiO2的厚度分别为20 nm、7 nm和15 nm。源与漏之间的距离为0.5 μm,控制门的宽度为2 μm。如果将控制门的宽度缩小到最小特征尺寸(F),则一个突触设备可以缩小到8 F2。图1b显示了所提出的突触装置的测量长期增强(LTP)和长期抑制(LTD)特性作为应用于WL和SL的脉冲数量的参数。在此测量中应用了50个重复擦除脉冲(VWL = - 3 V,VSL = 5 V)和300个重复编程脉冲(VWL = 0 V,VSL = - 4.8 V)。
非线性突触装置的行为模型一般用以下公式表示[10]:
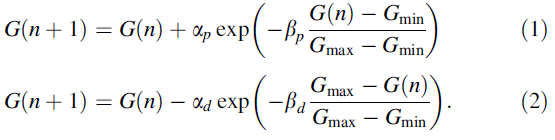
公式(1)和(2)分别表示突触装置的LTP和LTD行为。G(n)表示当施加n次增强或抑制脉冲时突触装置的电导,Gmax和Gmin分别是最大和最小电导值。αp和βp表示增强特性的拟合参数。类似地,αd和βd表示抑制特征的拟合参数。突触装置的非线性由这些公式中的βp和βd决定。所提出的TFT型突触装置的LTP和LTD特性符合βp等于2.5和βd等于5。此外,突触装置平均消耗~100 fJ/spike的能量(当1 V幅度和10 μs宽度的脉冲,大约10 nA电流)。
2.2 Training method
在介绍训练方法之前,我们描述了神经网络中使用的IF神经元模型的行为。突触前神经元的脉冲信号被整合到突触后IF神经元的膜电容器中。当膜电位超过阈值电压时,IF神经元会产生突触后脉冲信号并传递到下一层。SNN中IF神经元的行为可以近似于传统DNN的ReLU激活函数,因为突触后脉冲的数量与IF神经元的膜电位成正比。在此,膜电位初始化为零,下限设置为零。
第 l 层中第 j 个IF神经元的膜电位![]() 行为的详细信息如下所示。
行为的详细信息如下所示。
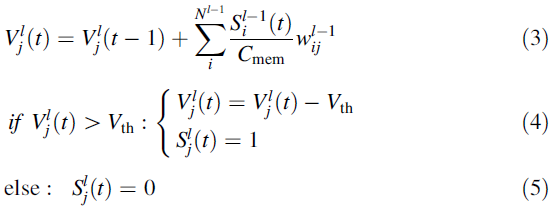
在此,![]() 表示在时间 t 以电压脉冲的形式在 l 层中的第 j 个神经元中产生的脉冲。
表示在时间 t 以电压脉冲的形式在 l 层中的第 j 个神经元中产生的脉冲。![]() 表示l-1层第 i 个神经元与 l 层第 j 个神经元之间的突触权重。Cmem和Nl-1分别代表IF神经元的膜电容和l-1层的神经元总数。公式(4)表示当膜电位超过阈值电压(Vth)时,l 层中第 j 个神经元的行为。此时,膜电位下降Vth,神经元产生突触后脉冲
表示l-1层第 i 个神经元与 l 层第 j 个神经元之间的突触权重。Cmem和Nl-1分别代表IF神经元的膜电容和l-1层的神经元总数。公式(4)表示当膜电位超过阈值电压(Vth)时,l 层中第 j 个神经元的行为。此时,膜电位下降Vth,神经元产生突触后脉冲![]() 。
。
通过累加教学信号(Zk(t))和输出脉冲,我们可以得到输出层(l = L)的误差值![]() ,如下所示:
,如下所示:

其中 T 是训练一组输入像素所采取的总时间步数。在本文中,图像用作输入数据,输入像素表示为值为0或1的二值数据。训练过程中神经元在每一层中发放的总次数![]() 被限制为最多 T 次。教学信号监督训练方向,并通过第2.3节中描述的方法获得。
被限制为最多 T 次。教学信号监督训练方向,并通过第2.3节中描述的方法获得。
前几层(l ∈ 1, 2, ... , L-1)的误差值通过反向加权求和得到,如下:
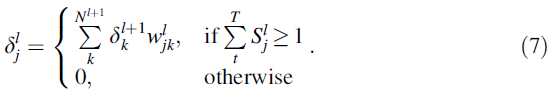
当 l 层中的第 j 个神经元在时间 T ![]() 内发放不止一次时,误差值通过反向加权求和获得。另一方面,当 l 层中的第 j 个神经元在时间 T
内发放不止一次时,误差值通过反向加权求和获得。另一方面,当 l 层中的第 j 个神经元在时间 T ![]() 期间没有发放时,误差值为0。这反映了ReLU激活函数的导数值。
期间没有发放时,误差值为0。这反映了ReLU激活函数的导数值。
突触权重使用公式(7)中获得的误差值更新如下:
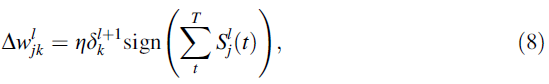
其中η表示将误差值的大小转换为脉冲宽度时使用的比率。转换率η的含义类似于基于软件的网络中的学习率。此外,当时间 T ![]() 期间产生的突触前脉冲的数量为0时,权重更新值
期间产生的突触前脉冲的数量为0时,权重更新值![]() 变为0。那么,l 层中第 j 个神经元与l+1层中第 k 个神经元之间的突触权重使用以下公式进行更新:
变为0。那么,l 层中第 j 个神经元与l+1层中第 k 个神经元之间的突触权重使用以下公式进行更新:
![]()
整个训练过程中不使用激活函数的导数值,因为ReLU函数的导数值为1或0。当![]() 为0时,公式(7)中
为0时,公式(7)中![]() 变为0,并且
变为0,并且![]() 在公式(8)中变为0,结果与反映ReLU函数的导数值0相同。当
在公式(8)中变为0,结果与反映ReLU函数的导数值0相同。当![]() 超过1时,得到
超过1时,得到![]() 作为ReLU函数的导数值1的反映,
作为ReLU函数的导数值1的反映,![]() 通过等式(8)得到。
通过等式(8)得到。
在基于硬件的神经网络中,第 i 个突触前神经元和第 j 个突触后神经元之间的权重值由两个突触装置的电导差表示,如下所示:
![]()
其中![]() 和
和![]() 分别代表正负权重值。每个权重值需要两个突触装置来表达负的突触权重,因为突触装置的电导只有正值。G+和G-的更新和重置方法遵循Lim [41]提出的方法。需要增加权重时增加G+,需要减少权重时增加G-。如果G+达到Gmax和增加权重是必要的,G-被初始化,然后增加到比之前的值低一级的电导水平。当两个G+和G-达到Gmax,它们被初始化为Gmin。
分别代表正负权重值。每个权重值需要两个突触装置来表达负的突触权重,因为突触装置的电导只有正值。G+和G-的更新和重置方法遵循Lim [41]提出的方法。需要增加权重时增加G+,需要减少权重时增加G-。如果G+达到Gmax和增加权重是必要的,G-被初始化,然后增加到比之前的值低一级的电导水平。当两个G+和G-达到Gmax,它们被初始化为Gmin。

2.3 Hardware-based deep Q-network
图2表示基于硬件的DQN的整体训练过程。它由三个要素组成:游戏进行的环境、进行训练和选择适当动作的DQN,以及用于经验回放的回放缓存。
首先,环境的当前状态应用于DQN的输入并存储在回放缓存中(图2中的①)。在网络中,发生前向传播,并且根据学习规则选择第一个发放的输出神经元作为动作(a)。该动作应用于环境并存储在回放缓存中(图2中的②)。接下来,执行给定动作时出现的奖励(r)和下一个状态(s')存储在回放缓存中(图2中的③)。通过这个过程,一组(s, a, r, s')数据存储在回放缓存中。最后,使用存储在回放缓存中的数据,使用上一节2.2中描述的方法训练DQN(图2中的④)。
在这个基于硬件的网络中,整个训练过程分为四个阶段。每个阶段分为五个时间步骤(T = 5),总长度为150 μs。每个时间步骤只能产生一个脉冲,输入像素以二值数据表示,值为0或1。当一个像素的输入数据为0时,不产生输入脉冲,如果为1,每个时间步骤都会产生输入脉冲。图3a为具有一个隐藏层的全连接网络的示意图。以第二阶段的情况为例,每个阶段的时间步骤总数为5,来自像素的输入数据为1(相当于3 V幅度的5个脉冲)作为示例,如图3b所示。图3c显示了第四阶段权重更新的脉冲方案。
第一阶段是前向阶段,接收状态s'作为输入并获得输出值(Q)的最大值。该输出值Q表示从给定状态s'执行动作a'的长期预期回报。Q值越高,在执行相应的动作a'时,状态s'的长期结果就越好。为了获得最大的结果,智能体选择一个动作,在每个状态下都会导致最高的Q值。当来自突触前神经元的加权和存储在突触后神经元的前向膜电容器中并且膜电位超过阈值电压时,通过IF神经元电路产生突触后脉冲。当第 k 个输出神经元中产生第一个脉冲时,其他输出神经元的膜电位设置为0。第 k 个输出神经元产生的脉冲然后为连接的电容器充电。连接到第 k 个输出神经元的电容器中存储的电荷量代表最大Q值,用作下一阶段的教学信号。
第二阶段也是前向阶段,接收状态 s 作为输入,获取误差值进行反向传播。除了输入数据不同外,发生与第一阶段相同的过程。在除最后一层(l ∈ {1, 2, ... , L -1})之外的所有层的神经元中,是否每个神经元在时间![]() 期间发放都存储为单个比特。换句话说,在时间 T 内多次发放的神经元存储为1,而在时间 T 内没有发放的神经元存储为值0。在这个阶段,通过脉冲-宽度调制(PWM)电路生成教学信号,误差值是从输出脉冲和教学信号之差中获得的。使用在第一阶段获得的最大Q值和在状态 s 中采取动作 a 时获得的奖励 r,获得教学信号Zj如下所示:
期间发放都存储为单个比特。换句话说,在时间 T 内多次发放的神经元存储为1,而在时间 T 内没有发放的神经元存储为值0。在这个阶段,通过脉冲-宽度调制(PWM)电路生成教学信号,误差值是从输出脉冲和教学信号之差中获得的。使用在第一阶段获得的最大Q值和在状态 s 中采取动作 a 时获得的奖励 r,获得教学信号Zj如下所示:
![]()
其中 γ 代表一个折扣因子,它会随着时间的推移降低未来奖励的价值。γ在0到1之间,通常取值为0.9。这个方程被称为贝尔曼方程。教学信号仅应用于第 m 个输出神经元,并且仅计算第 m 个误差值。这个第 m 个输出神经元是对应于从状态 s 变为状态s'时采取的动作 a 的神经元。其他输出神经元的误差值设置为0。
第三阶段是反向阶段,它传播在第二阶段获得的误差值。在这个阶段,下一层得到的误差值的加权和存储在反向膜电容器中。隐藏层有两个薄膜电容:前向薄膜电容存储加权和,反向薄膜电容存储下一层得到的误差值的加权和。
第四阶段是更新阶段,它使用第三阶段获得的误差值更新突触权重。当误差值为正或为负时,会产生相应值为5.0 V或-1.8 V的误差脉冲。误差脉冲的脉冲宽度与使用PWM电路的误差值的幅度成正比。在这个阶段,这些误差脉冲被两次应用于突触装置的源,如图3c所示。在10 μs后应用第二个误差脉冲。当存储在第二阶段的每个神经元的单比特值![]() 为1时,两个10 μs宽度的脉冲分别为3 V和-3 V,依次施加到突触装置的栅极。如果误差脉冲为正,则通过将施加到源极线的误差脉冲和施加到突触装置栅极的脉冲负部分重叠,将擦除脉冲施加到突触装置,从而增强突触权重,如图3c所示。在相反的情况下,当误差脉冲为负时,通过将施加到源极线的误差脉冲和施加到突触装置栅极的脉冲的正部分重叠,将编程脉冲施加到突触装置,从而抑制突触权重。然而,当单比特值为0时,突触设备的门不会施加脉冲,并且不会发生权重更新。
为1时,两个10 μs宽度的脉冲分别为3 V和-3 V,依次施加到突触装置的栅极。如果误差脉冲为正,则通过将施加到源极线的误差脉冲和施加到突触装置栅极的脉冲负部分重叠,将擦除脉冲施加到突触装置,从而增强突触权重,如图3c所示。在相反的情况下,当误差脉冲为负时,通过将施加到源极线的误差脉冲和施加到突触装置栅极的脉冲的正部分重叠,将编程脉冲施加到突触装置,从而抑制突触权重。然而,当单比特值为0时,突触设备的门不会施加脉冲,并且不会发生权重更新。

3 Results and discussion
使用Python(一种编程语言)和PyTorch库进行了两个系统级模拟,以评估在Fruit Catching游戏和Rush Hour游戏期间提出的训练方法和基于硬件的网络架构。本次模拟中使用的参数如表1所示。所有模拟的突触权重均使用He [42]提出的初始化方法进行初始化。
3.1 Fruit catching game
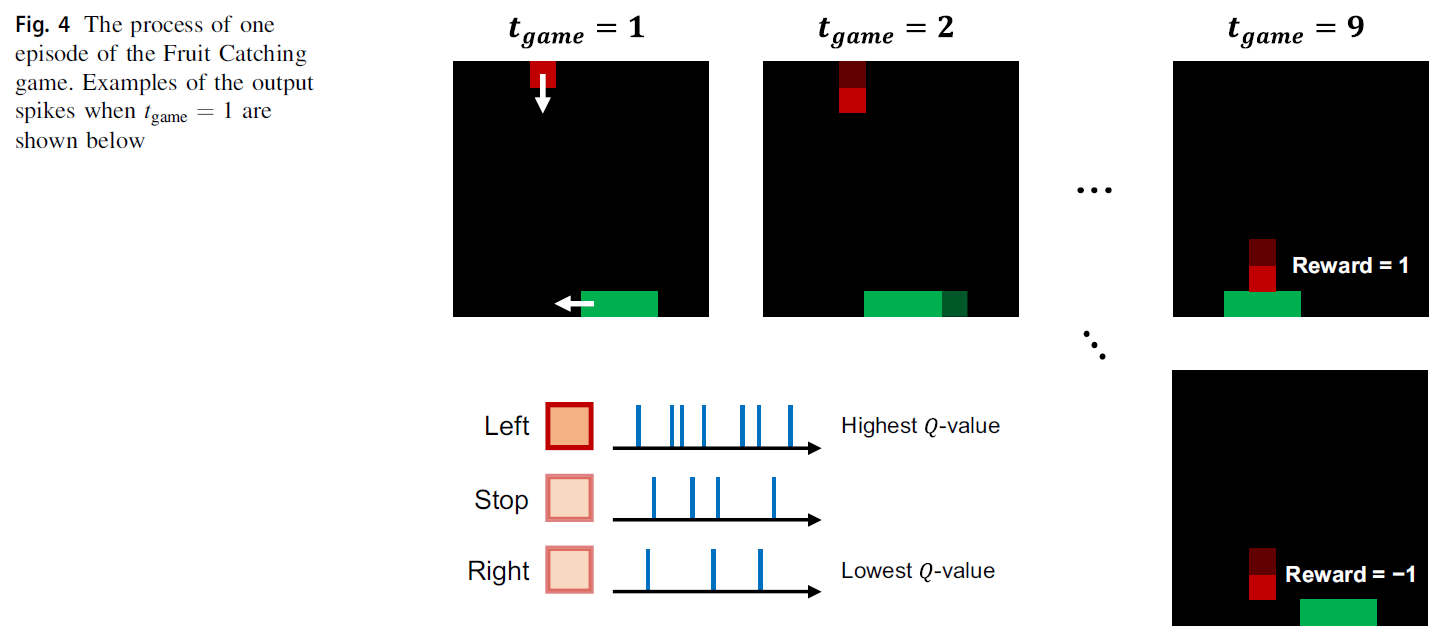
图4显示了一个关于Fruit Catching游戏如何进行的示例。在10 x 10网格世界中,水果的大小为1 x 1,篮子的大小为1 x 3。当一个新游戏开始时(tgame = 1),在第一行的十列中的随机位置创建一个水果,随着时间的推移,每经过一个时间步骤,这个水果就会落下一行。对于每个时间步骤,篮子可以在底行执行三个动作:停止或向左或向右移动一列。图4的底部展示了当tgame = 1时输出神经元中产生输出脉冲的例子。在这种情况下,因为代表向左移动动作的输出神经元的发放率最高,智能体采取移动篮子到左边的动作。当水果到达第9行时(tgame = 9),如图4最右边部分所示,如果水果下方存在篮子,则智能体获得1的奖励。反之,如果水果下不存在篮子,智能体获得-1的奖励。在所有其他情况下,智能体收到的奖励为0。一个回合以这个过程结束,新的游戏重新开始。
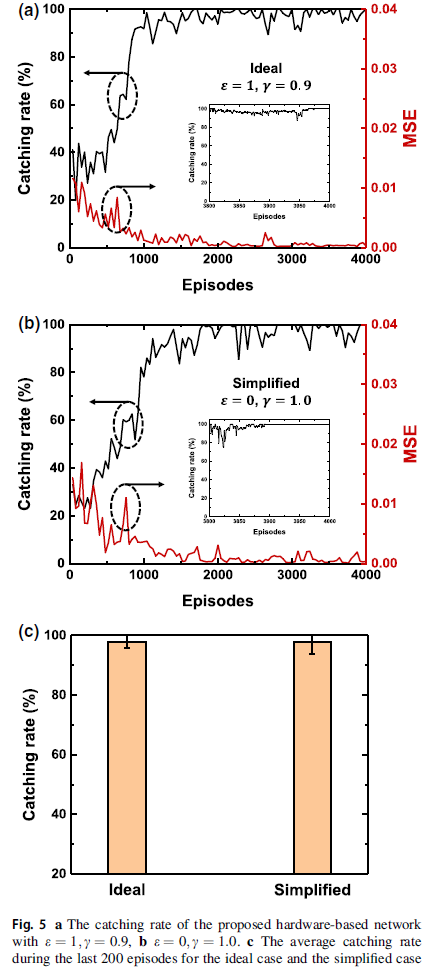
图5a和b表示具有不同epsilon值(ε)和折扣因子(γ)的所提出的基于硬件的神经网络的捕获率。图5a是一个理想情况,epsilon值为1,折扣因子为0.9,图5b是一个简化情况,epsilon值为0,折扣因子为1.0。捕获率是通过1000次测试游戏获得的。模拟中使用的网络大小为100-100-100-3。在这项工作中使用了大小为500的回放缓存,并且网络使用50个随机选择的数据集为每个动作进行训练。例如,在此,大小为1的回放缓存具有存储一个(s, a, r, s')数据集所需的位数。随着训练的进行,错误会减少,捕获率会增加,如图5a和图b 所示。图5a中的插图显示了最近200个回合的捕获率。图5c显示了理想情况(ε = 1, γ = 0.9)和简化情况(ε = 0, γ = 1.0)的最后200个回合的捕获率的平均值。由于具有理想情况和简化情况的网络训练得很好,没有显著差异,很明显,即使不使用探索,并且在Fruit Catching游戏中将折扣因子设置为1,网络也得到了很好的训练,这是一个相对简单的游戏。
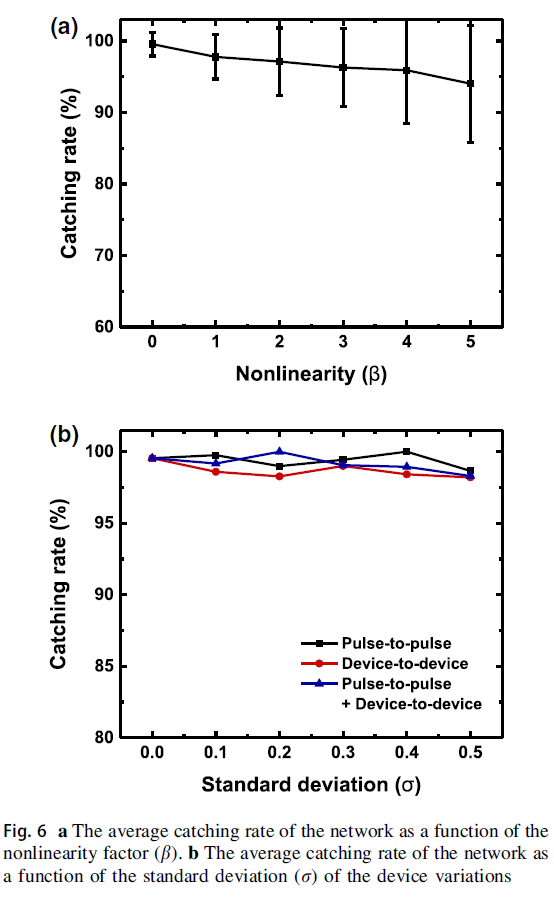
还研究了作为非线性因子(b)参数的网络捕获率,如图6a所示。训练是在与图5b相同的条件下进行的,结果显示了过去200个回合的平均捕获率。随着非线性因子的增加,捕获率略有下降(β = 5时约为5%)。
图6b显示了最近200个回合的平均捕获率与突触权重的变化。考虑了脉冲到脉冲的变化和设备到设备的变化。脉冲到脉冲的变化建模如下:
![]()
设备到设备的变化建模如下:
![]()
图6b中的x轴代表标准差(r)。对于这两种变化情况,由于采用了片上训练方案,即使 r 增加到0.5,捕获率也几乎没有下降并且几乎保持不变。
3.2 Rush hour game
用于验证所提出的训练方法的第二个示例是一个简单的Rush Hour游戏。在6 x 6位置,水平或垂直放置几辆长度为2或3的汽车。一次只能移动一辆车一个位置。游戏的目标是以最少的移动次数将目标汽车(红色汽车)移动到出口。如果目标汽车和出口之间的道路没有被阻塞,则智能体将获得1的奖励并结束一个回合。在所有其他情况下,智能体收到的奖励为0。
图7a和d显示了Rush Hour游戏的两个示例。图7a是一个相对简单的游戏示例,普通成年人只需不到几分钟即可解决问题。另一方面,图7d是一个比较复杂的例子,很难知道哪辆车先移动。模拟中使用的神经网络有288个输入神经元和16个输出神经元,没有隐藏层。这里使用288 (6 x 6 x 8)个输入神经元,因为每辆车可以有36 (6 x 6)个位置,使用16 (8 x 2)个输出神经元,因为每辆车可以向两个方向移动,即向上/左或下/右。
图7b和e表示将目标汽车移动到出口所需的移动次数。图7b和e是理想情况,epsilon值为1,折扣因子为0.9。如上,使用大小为500的回放缓存,并使用50个随机选择的数据集为每个动作训练网络。随着训练的进行,将目标车移动到出口所需的移动次数减少到最佳值(图7b中的9和图7e中的14)。图7c和f是简化的情况,其中智能体仅在第一个回合中采取随机动作(ε = 1,仅探索)。在随后的回合中,智能体不采取随机动作,只发生开发(ε = 0,仅开发)。在简化的情况下,将目标汽车移动到出口所需的移动次数收敛到最佳值,就像在理想情况下一样。这意味着能够以更简单的方式很好地进行训练,因为探索仅在第一个回合中进行。使用这种简化的方法执行后续的训练模拟。
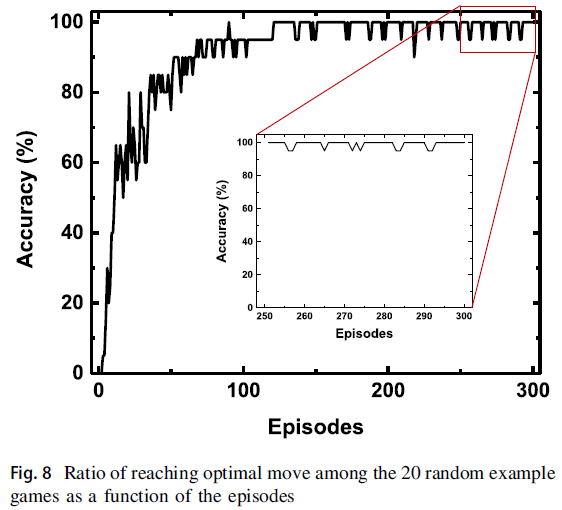
除了上面讨论的两个示例之外,还在相同条件下训练了18个随机示例。当每个样本达到最优移动次数时,就认为训练做得很好。否则,认为网络需要更多的训练。图8显示了20个示例中有多少达到了最佳移动次数。图8中的插图显示了最近50个回合的准确性。随着训练的进行,准确率收敛到100%。这表明网络可以针对各种游戏示例进行良好的训练。

3.3 Network without replay memory
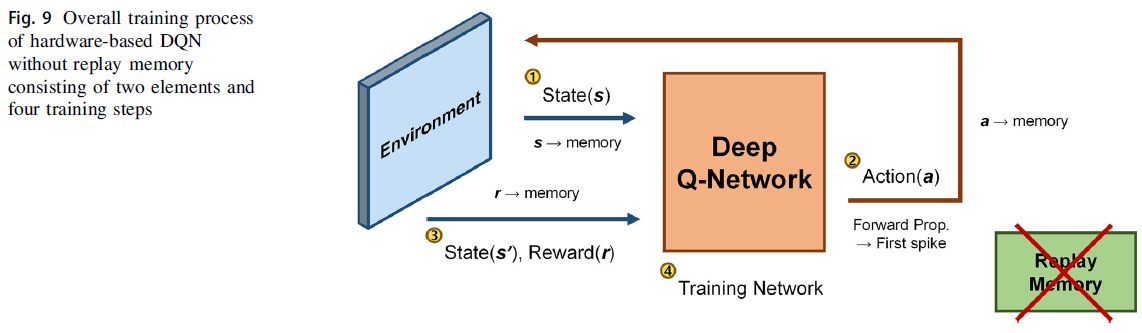
到目前为止,我们已经在所有模拟中使用大小为500的回放缓存训练了网络。但是,对于一个比较简单的问题,比如一个Fruit Catching游戏,通过不使用回放缓存,可以获得各种优势,比如更好的功耗、占用面积和更快的学习速度等结果。图9显示了不使用回放缓存时的整个训练过程。只有一组(s, a, r, s')数据存储在每个时刻,用于网络训练。如图2中的③所示,具有回放缓存的网络首先接收s'并将其存储在回放缓存中,然后对网络进行训练(图2中的④)。然而,在没有回放缓存的网络中,s'没有被存储,而是立即应用于DQN的输入(图9中的③),这成为四阶段训练过程的第一阶段。因此,在图9中,从第二阶段开始训练就足够了,这提高了整体训练速度。
图10a显示了没有回放缓存的网络捕获率。模拟中使用的网络大小和所有其他参数与图5b中的相同,除了不使用回放缓存并且网络仅针对每个动作使用一个数据集进行训练。因此,与具有回放缓存的网络相比,训练需要更多的回合。然而,由于每个回合训练所需的内存访问显著减少,因此训练所需的总时间减少了。捕获率是通过1000次测试游戏获得的。图10a中的插图显示了最近200个回合的捕获率。图10b显示了具有和不具有回放缓存的网络在过去200个回合中的捕获率均值。对于一个简单的问题,无论是否使用回放缓存,都可以很好地训练网络。

4 Conclusion
在本文中,我们提出了一种用于片上可训练的基于硬件的DQN的训练方法。整个训练过程分为四个阶段:两个前向阶段、一个后向阶段和一个更新阶段。在每个前向阶段,每种情况下存储两个值:目标脉冲的值![]() 和脉冲的生成
和脉冲的生成![]() 用于权重更新。在反向阶段和更新阶段,使用近似于传统反向传播算法的训练方法。为了实现片上训练,每个神经元只使用一位内存,并且内存的依赖性很低。
用于权重更新。在反向阶段和更新阶段,使用近似于传统反向传播算法的训练方法。为了实现片上训练,每个神经元只使用一位内存,并且内存的依赖性很低。
所提出的训练方法的性能通过两个示例游戏进行评估:Fruit Catching游戏和Rush Hour游戏。评估结果表明,在两种情况下,网络训练良好,相对于基于软件的训练方法的结果没有显著的性能差异。特别是,对于这里的其中一款简单游戏,特别是Rush Hour游戏,尽管没有使用回放缓存,但仍以大约98%的捕捉率的形式实现了高性能。这意味着可以对网络进行适当的训练,同时显著减少内存的使用,从而减少内存使用带来的功耗和面积占用。此外,还可以通过优化仿真中使用的参数来实现进一步的性能改进。处理大型输入图像数据是一项具有挑战性的未来研究。它可能需要大量的回放缓存和额外的卷积神经网络(CNN)。这个问题将在未来的工作中得到更彻底的解决。
在这项工作中,TFT型闪存单元被用作突触器件。由于FG只覆盖了一半的通道,在完全擦除状态下阈值电压不会降到0以下,通过防止漏电流降低待机功耗。此外,双向电导更新特性使该设备适合用作电导更新频繁发生的突触设备。
还研究了突触装置的非理想特性的影响。考虑了突触装置的非线性特性和两种变化。在将表示突触装置非线性的因子β增加到5时,评估了所提出的训练方法的性能。随着b的增加,性能略有下降,但总体而言,结果表明仍具有良好的性能。此外,由于采用了片上训练方案,所提出的系统对设备变化表现出很强的免疫力。


 浙公网安备 33010602011771号
浙公网安备 33010602011771号