Spike-Based Reinforcement Learning in Continuous State and Action Space: When Policy Gradient Methods Fail
郑重声明:原文参见标题,如有侵权,请联系作者,将会撤销发布!

PLoS Computational Biology, no. 12 (2009): e1000586-e1000586
Abstract
神经元之间的突触连接的变化被认为是学习的生理基础。这些变化可以由编码奖励存在的神经调节剂控制。我们研究了一系列奖励调节的突触学习规则(针对在受Morris水迷宫启发的连续空间学习任务中的脉冲神经元)。突触更新规则修改突触传递的释放概率,并取决于突触前脉冲到达的时间,突触后动作电压以及突触后神经元的膜电压。学习规则族包括从策略梯度方法以及奖励调节的Hebbian学习推导的最优规则。使用将前馈输入与横向连接相结合的网络结构,在脉冲神经元群体中实现突触更新规则。动作由具有强大的"墨西哥帽"连接性的假设动作单元组成,并以theta频率读出。我们证明,在这种结构中,标准的策略梯度规则无法解决Morris水迷宫任务,而具有Hebbian偏差的变体可以在20个试验中学习该任务,与实验一致。该结果不取决于实现细节,例如神经元群体的大小。我们的理论方法表明,如何在单个突触水平上将学习新行为与奖励调节的可塑性联系起来,并对突触可塑性的电压和脉冲时序依赖性以及神经调节剂(如多巴胺)的影响做出预测。这是将强化学习的正式理论与神经元和突触特性联系起来的重要一步。
Author Summary
人和动物了解他们是否获得奖励。这种奖励很可能通过神经调节信号传达到整个大脑。在本文中,我们介绍了一个模型神经元网络,该网络通过脉冲进行通信。如果在一系列动作后跟随奖励,则可以根据输入连接发出和接收的信号来修改输入连接,从而实现学习。利用这样的学习规则,模拟动物学会寻找(从任意初始条件开始)过去发生奖励的目标位置。
Introduction
动物可以通过在奖励信号存在下探索可用的动作来学习新的行为。典型的条件性实验的结构设计使得动物可以通过试错来学习,方法是通过正奖励来强化期望的行为(寻找食物,避免压力大的情况下逃避),或者通过负奖励信号来惩罚不良动作(电击或不舒服的水温)。奖励学习在机器学习领域中被称为RL[1],但其根源可以至少追溯到Thorndike的效果定律[2]的行为心理学。这些早期的思想影响了Rescorla and Wagner[3],Klopf的"享乐神经元"[4,5]或Sutton and Barto[6-8]的动物学习和适应的早期心理学理论对经典条件的数学描述。在转向本文所考虑的特定学习范式之前,我们在本简介部分中花一些篇幅对脉冲神经元模型中的三因素规则及其与无监督Hebbian模型和经典RL模型的关系进行广泛的回顾。本文的贡献是在此早期工作的背景下进行概述的。
Didactic Review of three-factor rules. 在细胞水平上,学习和记忆被认为是通过改变成对的神经元之间的突触连接强度来实现的[9,10]。许多关于长期增强和抑制的经典实验(LTP和LTD)都受到Hebb的启发,即两个神经元的共同激活应导致它们之间的联系增强[11]。因此,根据Hebb原理,权重wij从突触前神经元 j 变为突触后神经元 i 的变化仅取决于突触前和突触后神经元的状态:
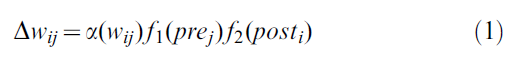
其中一些学习率α > 0。即使未指定函数f1和f2以及两个神经元的状态prej和posti的确切性质,等式(1)仍可得到Hebb规则的本质,即权重变化仅取决于两个神经元的状态,也可能取决于权重本身的当前值,而不取决于其他神经元或其他信号的值。这样的"两因素"Hebb规则是无监督[12,13]和发展性学习[14,15]的经典模型的基础。在这些经典模型中,函数f1和f2分别是突触前和突触后神经元发放率的线性或二次函数。脉冲时序依赖可塑性(STDP)的现代模型可以被视为Hebb规则关于脉冲水平的一种实现[16-21]。
但是,无论是基于脉冲水平还是发放率水平制定的Hebbian两因素规则都不能考虑奖励信号的存在与否。人们认为奖励情况由大脑中神经调节剂浓度的变化所代表,而神经调节剂的浓度可为大量神经元所共享。更准确地说,在某些大脑区域,多巴胺已被确定为信号分子,预示着意外的奖励情况[22]。因此,很容易通过第三个因素R - b扩展公式(1)中的"局部"Hebbian规则,其中R代表表征奖励情况的"全局"神经调节信号,b代表基准:
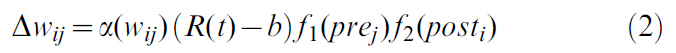
假设如果动物最近获得奖励,此时R = 1,否则为0,并且b = 0。三因素规则(2)的结果是,只有在奖励存在的情况下,才能执行由Hebbian规则(1)预测的权重变化。没有奖励,就不会发生权重变化。
在实验中,已使用经典的基于发放率的协议在皮质-纹状体突触中广泛研究了诸如(2)之类的三因素规则[23-26]。有关海马体突触标记的另一项研究[27]表明,仅在存在神经调节剂(如多巴胺)的情况下,LTP的强直方案引起的突触变化才能稳定[28–30],这表明Hebbian变化需要神经调节剂作为稳定的第三个因素。最近,在皮层纹状体突触中研究了三因素规则的时序依赖性,该水平依赖于脉冲水平,产生一种多巴胺依赖性STDP[31]。
毫秒时间尺度上的三因素规则的理论已经由许多不同的组提出[32-37]。可以区分三种不同的理论方法。第一个方法是通过梯度下降从奖励优化中推导出学习规则[32-34,38],该方法可以与机器学习中的策略梯度方法相关联[39,40];第二个假设一种形式的STDP,可以通过奖励来调节[33,35,36,41],这种方法可以被认为是经典STDP模型的扩展[16,17,42]。第三个将TD模型框架[1,43],特别是actor-critic模型[1,7,44]转换为SNN[37,45]。顺便说一句,梯度规则也可以在节点和权重扰动的情况下制定,在这种情况下突触后活动没有明确输入,产生修改的两因素规则而不是三因素规则[46,47]。我们还想提到STDP对突触后活动派生的敏感性,这种敏感性与TD学习有关[48-50]。
在本文中,我们研究了脉冲神经元网络,该网络必须解决到隐藏目标的导航问题。奖励被延迟,即动物必须在收到正或负奖励信号之前执行一系列动作。我们的方法可能与脉冲神经元的策略梯度方法有关[32-34],但由于以下两个原因而超出了这些早期研究的范围:首先,我们考虑一种更通用的学习规则,其中包含策略梯度规则和幼稚的奖励调节Hebbian规则(作为特殊情况)。其次,我们考虑动作神经元之间强烈的横向交互,这种情况会导致在进行动作选择的层中活动凸起的自发形成。
可以将产生的突触更新规则公式化为连续时间的三因素规则形式的微分方程:
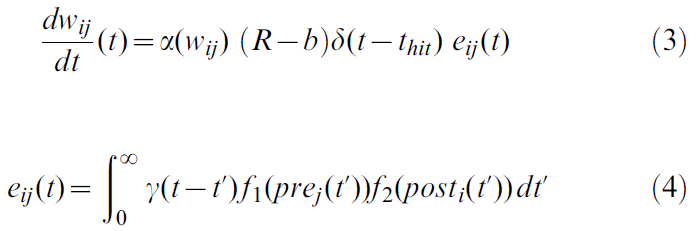
其中eij项(称为资格迹)可以像在Hebbian学习规则中那样获取突触前和突触后活动之间的相关性,并将其与低通滤波器γ进行卷积。然而,最终的权重改变仅在奖励信号R - b的存在下实现,奖励信号在动物达到目标的时间thit发出。本文考虑的b的选择是:b = 0和![]() ,其中
,其中![]() 是在许多试验中平均的奖励信号。
是在许多试验中平均的奖励信号。
与Xie and Seung的早期工作[32]相反,但与[33-35]相似,我们的方法考虑了具有不应期的脉冲神经元,并包括诸如标准的IF模型。在一定的不应期条件下[34],我们的学习规则可以用标准STDP模型确定,但受第三个因素调节[33-36]。与大多数早期工作[33,34,36]相反,我们的学习规则适用于将前馈输入与横向交互结合起来的神经元网络。
Learning paradigm. 为了显示本文研究的时序依赖的三因素规则族的潜力,我们将其应用于Morris水迷宫范式[51]。它是行为学习和导航的标准范例,也已被用作TD学习模型的挑战范例[52-55]。在这种行为模式中,将大鼠(或小鼠)放在乳白色(非透明)的水中。为了从水中逃脱,它必须找到隐藏在水面下方的不可见平台。在隐蔽的平台上攀爬可以被认为是有益的,因为它会结束令人讨厌的体验。在实验的第一次尝试中,大鼠偶然发现平台。在随后的试验中,每次将大鼠置于不同的起始位置。然而,在多次试验中,大鼠学会根据远端周围线索向隐藏平台导航[52,56]。与具有固定初始条件的任务变体相反[57],本文考虑的具有可变起始条件的Morris水迷宫任务取决于海马体[51]。
在本文中,我们使用脉冲神经元的最小海马体模型对Morris水迷宫范式进行建模。我们提出的模型具有以下特征:
- 大鼠的位置是一个连续值,由具有重叠位置场(粗略编码)的位置单元的集合表示。这些位置单元与动作单元具有前馈连接。
- 动作由代表粗略编码范例中不同运动方向的动作单元组成。新的动作被定义为跨动作细胞的群体矢量活动,它定期以theta频率进行选择。
- 动作单元组织在一个具有横向连接性的环上,显示出局部激发和长期抑制。作为结果,动作单元群体以凸起状的活动分布响应来自位置单元的输入。
- 位置单元与动作单元的前馈连接根据脉冲水平的三因素学习规则而变化,这可以认为是奖励最大化产生的Hebbian可塑性的奖励调节形式。
- 前馈连接中的突触传递是随机的,并且通过改变释放概率来进行学习。
- 当仅在序列末端给出奖励时,学习一系列动作的问题可以通过在学习规则的推导中自然出现的资格迹解决。资格迹被实现为突触点上的局部记忆。
对于具有有限数量(离散)状态和少量动作的人工系统,已经开发了很大一部分经典的强化模型。但是,真实的动物会在连续空间中移动,并且在某些范例中还具有多种动作选择,最好将其描述为连续体。诸如Q学习[1,43]之类的经典TD模型不适用于这种情况:如果连续状态被分辨率提高的离散状态空间近似(状态数量更多),则学习速度会减慢,除非将资格迹引入算法和/或使用函数近似[1]。相反,我们在此处采用的架构允许动物在不降低性能的情况下在连续的活动场所上移动。
此外,尽管在存在资格迹的情况下保证了TD模型的收敛性[58,59],但在这些算法中添加资格迹有些特殊,而资格迹自然出现在策略梯度框架中。出人意料的是,用于脉冲神经元的标准策略梯度方法[32,34]不适用于以下情况:通过动作单元层中活动凸起的形成来决定动作选择。但是,我们将证明,具有修改后的学习规则并带有"Hebbian偏差"的模型网络确实可以在20个试验中学会导航到一个不可见的目标,类似于Morris水迷宫任务中老鼠的表现[52]。由于具有重叠位置场和"动作场"的单元对状态和动作进行粗略编码,因此该模型允许对连续状态和动作空间中的位置和动作进行编码。我们将证明,使用我们的粗略编码方法,学习性能与单元数无关。因此,性能稳定且不依赖于实现细节。我们认为,一方面,这种结构稳定性的关键因素是动作单元环中的横向相互作用。另一方面,恰恰是事实是基于稳定的活动凸起的位置来选择动作,这使得标准策略梯度方法失败。
Results
本节分为三个主要部分。首先,我们讨论用于脉冲神经元的三因素学习规则的主要特征。为了在现实的范式中测试该学习规则,我们在第二部分中介绍Morris水迷宫学习任务以及具有适合解决任务的位置单元和动作单元的模型结构。最后,介绍该任务中学习规则的执行情况。
Three-factor learning rule for spiking neurons
我们考虑索引为 i 的脉冲响应模型神经元,该神经元从其他神经元 j 接收输入。来自神经元 j 的第 f 个输入脉冲在时间![]() 到达神经元 i 上的突触,并在那里引起时间过程
到达神经元 i 上的突触,并在那里引起时间过程![]() 和振幅wij的兴奋性(或抑制性)突触后电位(EPSP或IPSP)。将所有传入脉冲的EPSP和IPSP加到神经元 i 的膜电位ui上。脉冲以瞬时发放率(或随机强度)随机生成:
和振幅wij的兴奋性(或抑制性)突触后电位(EPSP或IPSP)。将所有传入脉冲的EPSP和IPSP加到神经元 i 的膜电位ui上。脉冲以瞬时发放率(或随机强度)随机生成:

其中g(ui)是随膜电位ui增大的正函数,另请参见等式(24)。在时间![]() 出现神经元 i 脉冲之后,神经元立即进入相对不应状态,这是通过电位之后的超极化脉冲
出现神经元 i 脉冲之后,神经元立即进入相对不应状态,这是通过电位之后的超极化脉冲![]() 实现的。因此,脉冲反应模型神经元的总膜电位为[20]:
实现的。因此,脉冲反应模型神经元的总膜电位为[20]:
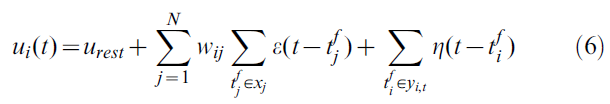
其中urest是静息电位,xj是突触前脉冲的集合,![]() 是直到时间 t 的突触后脉冲的集合。
是直到时间 t 的突触后脉冲的集合。
使用这个神经元模型,我们可以计算出在持续时间为T的试验中神经元 i 产生特定的脉冲序列且发放时间为![]() 的概率[34],请参见Methods,等式(25)。在奖励发放之前不久神经元 i 就出现了一些脉冲,而其他则没有。学习的目的是改变突触权重wij,以便增加获得奖励R的可能性。我们考虑学习形式的规则:
的概率[34],请参见Methods,等式(25)。在奖励发放之前不久神经元 i 就出现了一些脉冲,而其他则没有。学习的目的是改变突触权重wij,以便增加获得奖励R的可能性。我们考虑学习形式的规则:
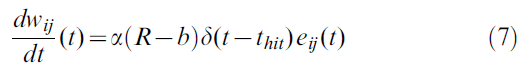
其中α是学习率(控制权重更新的幅度),thit是动物到达目标或墙的时刻,R = 1是发现目标的正奖励,R = -1是对碰壁的(负)奖励,并且b为奖励基准,例如根据过去的经验对正奖励的估计。资格迹eij(t)根据:
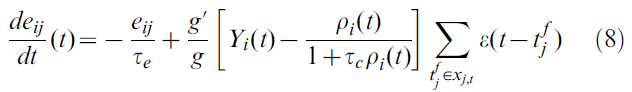
其中![]() 是突触后神经元的脉冲序列,δ(t)是狄拉克函数,τe是资格迹时间常数,τc是时间单位的参数,并且g' = dg/du是函数g(u)的导数。
是突触后神经元的脉冲序列,δ(t)是狄拉克函数,τe是资格迹时间常数,τc是时间单位的参数,并且g' = dg/du是函数g(u)的导数。
由于参数τc,学习公式(9)和(8)定义了一组学习规则,而不是一个规则的单个实例。参数τc > 0是我们模型的一个特征,它允许将模型从严格的策略梯度方法(τc = 0,[33,34]请参见方法)转换为朴素的Hebbian模型(τc → ∞,请参见下文突触后因素的讨论)。因此,我们可以通过修改τc来链接和比较这些概念上不同的规则。我们注意到,对于小发放率![]() ,等式(9)逼近[33,34]的最优策略梯度规则,而对于较大的发放率,它增强了规则的Hebbian成分。对于
,等式(9)逼近[33,34]的最优策略梯度规则,而对于较大的发放率,它增强了规则的Hebbian成分。对于![]() ,方括号中的项变为
,方括号中的项变为![]() ,因此对于τc → ∞,学习由Hebbian相关项
,因此对于τc → ∞,学习由Hebbian相关项![]() 驱动。在仿真结果的主体中,我们选择了τc = 5ms的固定值,这表明我们使用带有Hebbian偏差的策略梯度方法。
驱动。在仿真结果的主体中,我们选择了τc = 5ms的固定值,这表明我们使用带有Hebbian偏差的策略梯度方法。
正奖励的估计值是根据以下公式在试验结束时更新的移动平均值:![]() ,其中n是试验次数,RT(n)是第n次试验结束时的奖励(1或0),mr是平均窗口的宽度。
,其中n是试验次数,RT(n)是第n次试验结束时的奖励(1或0),mr是平均窗口的宽度。
现在,我们将显示等式(7)和(8)可以解释为脉冲神经元的三因素学习规则(在导言中概述的一般框架内)。
Presynaptic factor. 突触前脉冲到达会导致EPSP。EPSP的时间过程![]() 表示突触前活动在突触位置的影响。我们强调,突触前因素项并不意味着该因素是突触前实现的,而是指由突触前神经元 j 的活动引起的项。
表示突触前活动在突触位置的影响。我们强调,突触前因素项并不意味着该因素是突触前实现的,而是指由突触前神经元 j 的活动引起的项。
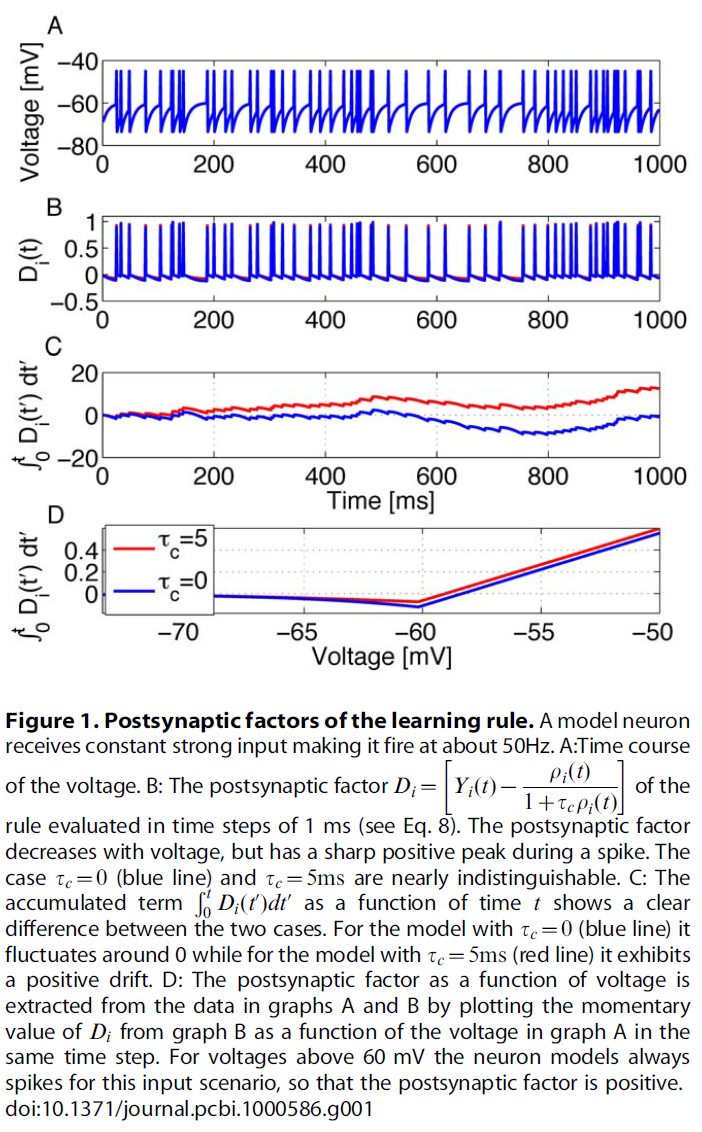
Postsynaptic factor. 突触后活动由突触后动作电位的时间![]() 和突触后膜电位ui(t)表示。膜电位输入函数g(ui)以决定瞬时发放率ρi(t) = g(ui(t))。突触后脉冲被视为事件,并由函数
和突触后膜电位ui(t)表示。膜电位输入函数g(ui)以决定瞬时发放率ρi(t) = g(ui(t))。突触后脉冲被视为事件,并由函数![]() 描述。突触后因素用Di表示,用等式(8)中的方括号封装,可视化为膜电位的函数,如图1所示。对于τc → ∞而言,突触后因素仅取决于脉冲时间,而不取决于突触后神经元的膜电位。
描述。突触后因素用Di表示,用等式(8)中的方括号封装,可视化为膜电位的函数,如图1所示。对于τc → ∞而言,突触后因素仅取决于脉冲时间,而不取决于突触后神经元的膜电位。
突触前和突触后因素均输入等式(8)的资格迹eij,这是必须在神经元 j 到神经元 i 的突触处局部存储的量。只要在EPSP的时间跨度内发生突触后动作电位,就将 j 到 i 的突触的资格迹更新为有限的正数。因此,资格迹在突触前脉冲到达与突触后脉冲发放之间具有(潜在的因果)相关性。如果发生EPSP时没有突触后脉冲,则资格迹以![]() 的比例平滑衰减。特别是,如果膜电位高,但没有发放突触后脉冲,则资格迹会大大降低。但是,在极限τc → ∞这样的突触抑制不会发生。因此,对于τc → ∞,如果突触后脉冲到达后不久(并可能由后者触发)突触前脉冲到达,则资格迹是朴素的Hebbian。如果突触未激活(即,在突触处没有EPSP),则资格迹始终以秒为单位的慢时间常数τe衰减。无论选择哪种τc,资格迹都仅使用突触部位可用的局部量,并在局部存储突触前和突触后活动之间的相关性(在数秒内取平均)。在τc → ∞的极限中,这些相关性平均为零,因为以发放率ρ(t)产生脉冲Y(t),使得期望<Y(t) - ρ(t)>消失。但是,在单个试验中,资格迹记录存储的相关性通常为非零。
的比例平滑衰减。特别是,如果膜电位高,但没有发放突触后脉冲,则资格迹会大大降低。但是,在极限τc → ∞这样的突触抑制不会发生。因此,对于τc → ∞,如果突触后脉冲到达后不久(并可能由后者触发)突触前脉冲到达,则资格迹是朴素的Hebbian。如果突触未激活(即,在突触处没有EPSP),则资格迹始终以秒为单位的慢时间常数τe衰减。无论选择哪种τc,资格迹都仅使用突触部位可用的局部量,并在局部存储突触前和突触后活动之间的相关性(在数秒内取平均)。在τc → ∞的极限中,这些相关性平均为零,因为以发放率ρ(t)产生脉冲Y(t),使得期望<Y(t) - ρ(t)>消失。但是,在单个试验中,资格迹记录存储的相关性通常为非零。
Global factor. 我们的突触学习规则中的第三个因素是由表达式R(t) = [R - b]δ(t - thit)描述的全局奖励项。在我们的理论中,它表示(外部)奖励交付的时间过程。神经调节剂(如多巴胺)代表大脑大区域的与奖励相关的弥散性信号[22]。在我们的理论中,突触在局部计算和存储资格迹。但是,只有在资格迹中"提出"的更改被全局神经调节信号"确认"的情况下,才执行权重更改。
Stochastic binary synapses. 信息在突触中的传递不是确定性事件,而是具有随机成分的。上面讨论的突触"权重"wij的变化很可能对应于在突触间隙中释放固定量的神经递质的概率qij的变化[60]。让我们假设突触传输的是固定量的神经递质b或根本不传输。学习会影响神经递质的释放,因此通过上述更新规则增加突触的权重wij将增加释放概率,因此平均权重可以表示为wij = qijβ。因此,对于我们仿真中使用的随机二值突触,我们得出以下学习规则:
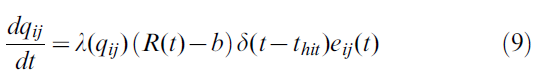
其中资格迹与等式(8)中相同。由于qij是一个概率,因此最大值限制为1。我们还设置了下限qij > 0.15。对于0.15 < qij < 1,我们以学习率λ(qij) = α/β实现这些约束,否则为零。
Learning rule parameters. 自由参数包括:学习率λ,资格迹时间常数τe,可调整学习规则的Hebbian偏差的参数τc和神经元响应的噪声水平(由参数Δu控制,请参见Model结构,Action Cells)。其他参数固定为先验[34,61]。
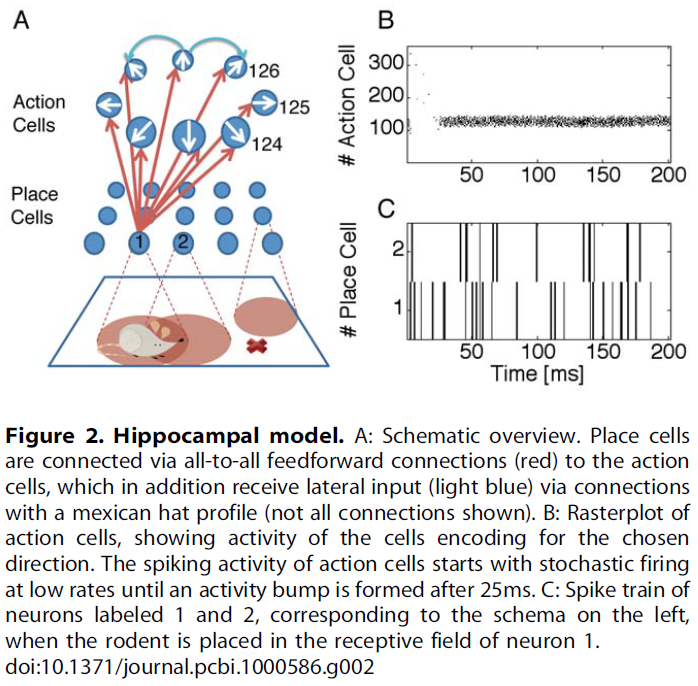
Model architecture
前面小节中讨论的学习规则(τc = 0, 5ms, ∞)是在仿真的具有可变初始条件的Morris水迷宫任务上测试的,该任务已知涉及海马体[51]。海马体表示为位置单元群体,位置单元的中心组织在矩形网格上。这些模型位置单元投影到"动作"单元上,该单元被假定放置在伏隔核中。动作单元群体代表模型大鼠要选择的下一个动作,并以环状结构组织,并具有"墨西哥帽"的横向连接性;参见图2。
Hippocampal place cells (HPC). 将海马体位置单元建模为Poisson神经元,其发放率vf是环境中动物位置的高斯函数:

其中(x, y)是动物的当前位置,(xi, yi)是第 i 个位置单元响应最强的位置,v0 = 110Hz是位置单元的最大发放率。除非另有说明,否则我们在仿真中将100个这样的神经元放置在10×10个单元的网格上,两个相邻单元之间的距离为10cm,而每个位置场的宽度为σ = 12cm。环境是100×100cm的方框。位置单元的集成活动编码动物的位置(x, y)。
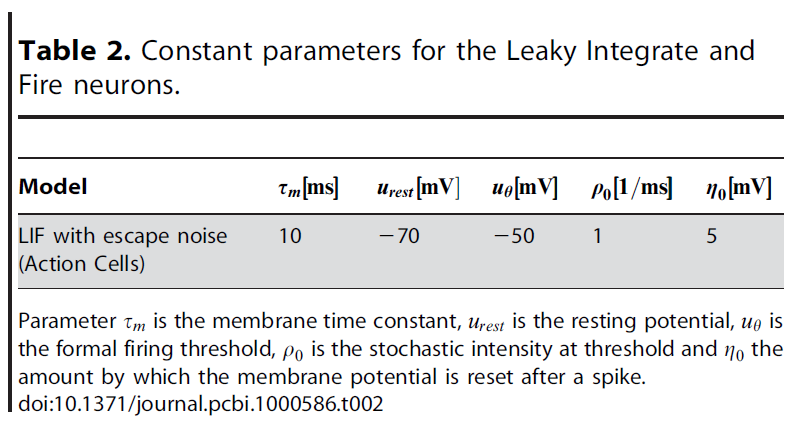
Action cells (AC). 动作单元被建模为LIF单元[62],这是脉冲响应模型[20]的特例。神经元 i 的膜电位变化由下式给出:
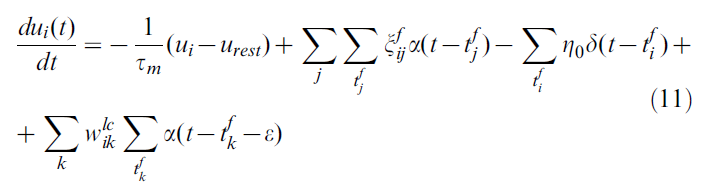
其中膜时间常数τm = 10ms,静息电位urest = -70mV,![]() 是一个随机变量,如果突触前位置单元 i 引起脉冲,则取值为1的概率为qij,否则
是一个随机变量,如果突触前位置单元 i 引起脉冲,则取值为1的概率为qij,否则![]() ,
,![]() 为神经元 i 和 j 之间的横向连接的突触强度,
为神经元 i 和 j 之间的横向连接的突触强度,![]() 和
和![]() 分别对应于突触前神经元 j 和 k 的脉冲,
分别对应于突触前神经元 j 和 k 的脉冲,![]() 为在时间 t 之前的突触后脉冲,并且ε为小正数。我们注意到,右侧第二项中的项
为在时间 t 之前的突触后脉冲,并且ε为小正数。我们注意到,右侧第二项中的项![]() 是指位置单元发放,而第四项中的
是指位置单元发放,而第四项中的![]() 是动作单元发放。我们假设突触后电流是短脉冲:
是动作单元发放。我们假设突触后电流是短脉冲:
 其中ε0 = 1mV和δ(t)是Dirac δ函数。如果神经元 i 发出脉冲信号,其膜电位将重置η0 = 5mV。我们注意到,使用这些定义,我们的模型等效于带有脉冲输入的标准LIF模型,以及等式(6)中定义的脉冲响应模型的一般情况。
其中ε0 = 1mV和δ(t)是Dirac δ函数。如果神经元 i 发出脉冲信号,其膜电位将重置η0 = 5mV。我们注意到,使用这些定义,我们的模型等效于带有脉冲输入的标准LIF模型,以及等式(6)中定义的脉冲响应模型的一般情况。
为了解决不属于模型的其他突触前神经元产生的固有噪声或突触噪声,我们使用了随机发放阈值[20,63],也称为逃逸噪声。突触后神经元 i 的动作电位由具有随机强度ρi = g(ui)的点过程生成,其中ui是膜电位的指数函数[20,64]:
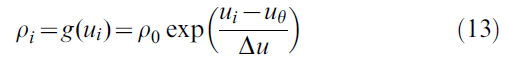
其中ρ0 = 1/ms是阈值处的随机强度,uθ = -50mV是正式发放阈值,Δu = 5mV是阈值区域的宽度。我们注意到,对于选择(13),在等式(8)的资格迹中,因素g'/g是可被学习率吸纳的常数。除非另有说明,否则我们将使用NAC = 360个动作单元进行仿真。
Lateral connections. 动作神经元与"墨西哥帽"型的横向连接成环状连接。对动作单元 i 进行局部弱化的前馈就足以在25-200ms内引起活动blob的形成。活动blob的位置代表大鼠的下一个动作。由于广泛的活动状况,不仅最大活动的一个神经元,而且相邻的活动神经元都可以在学习过程中得到增强。为简单起见,我们在模型中将横向连接保持固定(即,它们不经历突触可塑性),并使用以下公式:
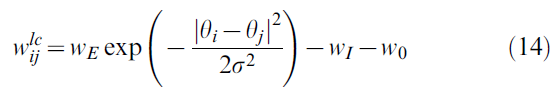
其中![]() 为神经元 i 和 j 之间的连接,θi和θj为它们相应的首选方向(取模360o的差),σ = 17o,wE = 1.5(弱连接)或wE ≥ 2(强连接)和wI = 0.9。局部连接(即
为神经元 i 和 j 之间的连接,θi和θj为它们相应的首选方向(取模360o的差),σ = 17o,wE = 1.5(弱连接)或wE ≥ 2(强连接)和wI = 0.9。局部连接(即![]() )是兴奋性的(w0 = 0),而较长距离的连接是抑制性的,等式(14)中w0 = 0.5。
)是兴奋性的(w0 = 0),而较长距离的连接是抑制性的,等式(14)中w0 = 0.5。
我们选择了一些参数,以便在学习过程开始时就已经形成blob。横向连接的效果类似于赢家通吃机制。
Decision making. 在迷宫中的每个位置,老鼠都必须选择下一步行动的方向。该决定是在动作层中形成凹凸样活动概况后做出的。我们假设在theta频率范围内,抑制性背景输入调节了动作单元的数量。如果抑制作用很强,则不会形成活动概况,并且神经元也不会活动。当背景抑制降低到零时,会形成活动概况,并以前馈输入最强的动作神经元为中心——这些代表了大鼠接下来要选择的动作。
为了使模型尽可能简单,我们通过每200毫秒将所有动作单元的活动重置为零来模拟算法在theta-频率上对抑制的调制。否则,动态将根据上述动力学方程自由发展。200毫秒后,大鼠根据动作单元发放率的群体向量决定下一步行动。更具体地,根据脉冲活动的低通来估计动作单元1 ≤ i ≤ NAC的发放率:
 其中τd是设置为10ms(或200ms)的时间常数,Y(t)是动作单元的整个突触后序列,定义为
其中τd是设置为10ms(或200ms)的时间常数,Y(t)是动作单元的整个突触后序列,定义为![]() ,其中
,其中![]() 是第 i 个动作单元的第 f 次发放时间。大鼠的走动方向由同心轴坐标系中的角度θ来描述,即相对于房间坐标,并根据群体矢量计算得出:
是第 i 个动作单元的第 f 次发放时间。大鼠的走动方向由同心轴坐标系中的角度θ来描述,即相对于房间坐标,并根据群体矢量计算得出:
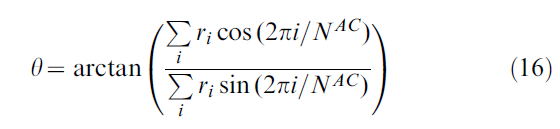
其中NAC是动作单元的总数(除非另有说明,通常为360),而2πi/NAC是第 i 个动作单元的方向。θ是在决策时间T ≤ 200ms之后计算的。在图3C-E中,T是所有动作单元的总活动![]() (Θ = 200Hz)的时刻(如果例如10个单元以超过20Hz的频率发放,这就会发生),这很好地指示了何时形成决策(活动凸起)。对于所有其他仿真,T = 200ms,但通常每种情况下这些条件中的任何一种都是可能的。
(Θ = 200Hz)的时刻(如果例如10个单元以超过20Hz的频率发放,这就会发生),这很好地指示了何时形成决策(活动凸起)。对于所有其他仿真,T = 200ms,但通常每种情况下这些条件中的任何一种都是可能的。

Watermaze performance
我们以20cm/s的恒定速度在1m2的方形迷宫中行动的模型老鼠进行仿真。大鼠进行了多次试验,每次试验都包括试图在90秒的时限内找到目标的尝试。在每次试验开始时,将大鼠放在迷宫壁之一附近。选择动作的频率为theta频率(每200ms)。在两个动作选择之间,模拟的老鼠移动了大约4厘米。奖励位置(目标)位于迷宫中心区域附近的随机位置,并且在一组试验中保持固定在相同位置,而大鼠的初始位置则有所不同,如实验范式[51,65,66]。只有在老鼠达到目标时才给出正奖励(R = 1),如果碰到墙壁则给予负奖励(R = -1)。因此,在大鼠到达平台时tgoal或在大鼠撞到壁时twall发生突触修改。有关该算法的概述,请参见图4。
当开始一组新的试验时,将重新初始化大鼠和目标的位置以及模型中所有可塑突触的突触释放。因此,每组新的试验都对应于不同的动物。
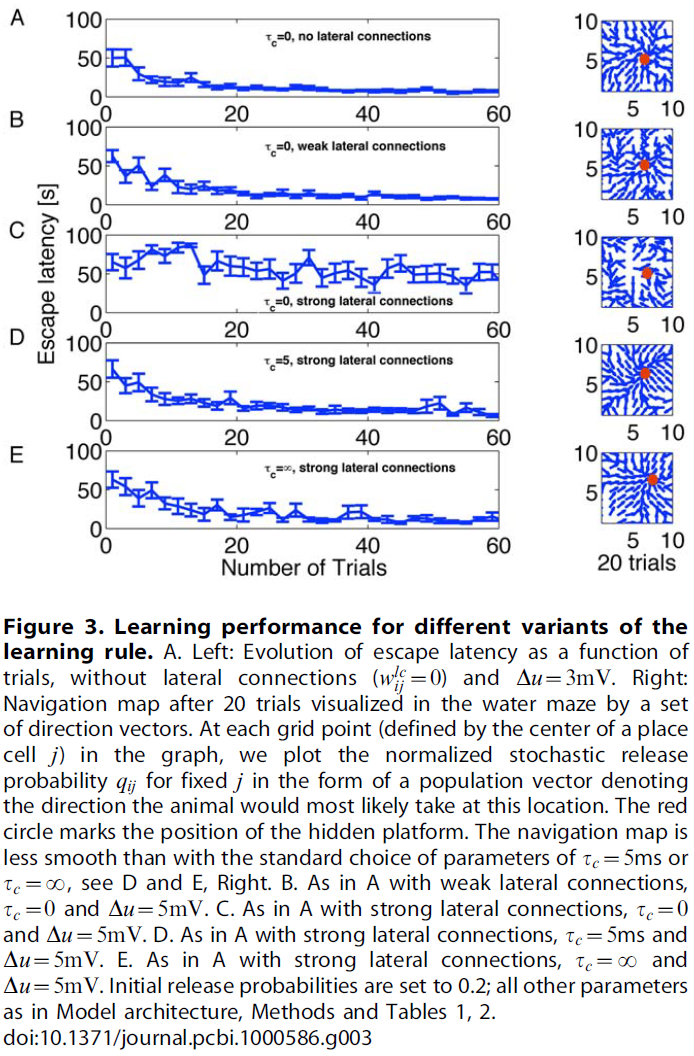
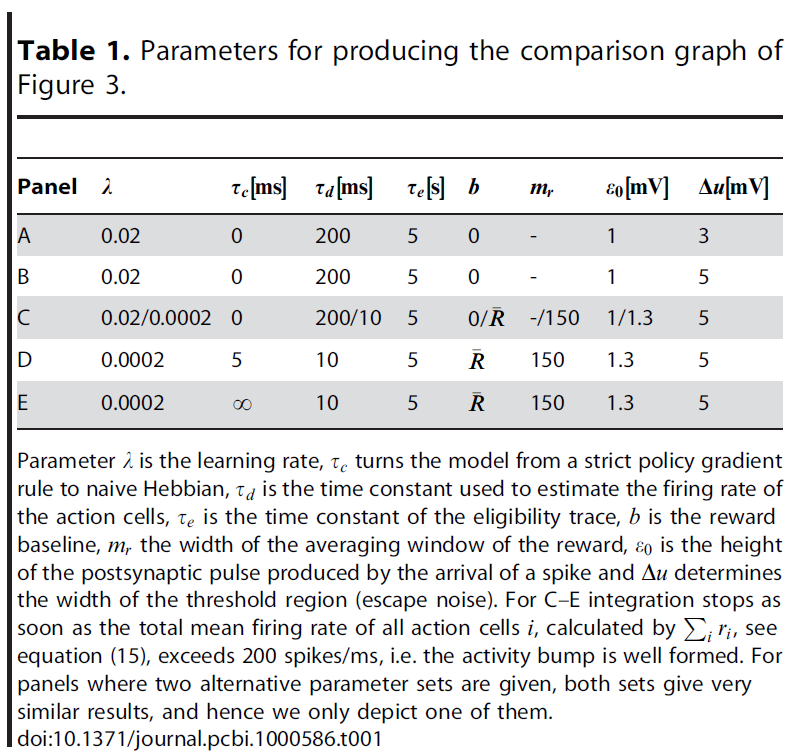
Speed of learning. 通过达到目标所需的时间来测量大鼠的性能,这对应于实验文献中的逃避延迟[51,65,66]。在图3A–E的面板中,我们绘制了参数τc的三个值和"墨西哥帽"连接的三个条件:零(wE = 0, wI = 0和w0 = 0),弱(wE = 1.5, wI = 0.5和w0 = 0)和强(wE = 2, wI = 0.9和w0 = 0.5)。对于零或弱横向连接,学习在20次试验中以任何τc值进行(图3A, B)。该性能类似于实验数据[51]和以前的模型[52,55]。在学习任务时,从10次重复的学习实验中提取的性能标准差减小。
出乎意料的是,对于横向连接而言,其强度足以在动作单元层中形成活动凸起,只有具有主要Hebbian分量(τc > 0)的规则版本才能够学习任务(图3D, E), 而不是脉冲神经元的标准策略梯度规则(τc = 0, 图3C)。我们认为,策略梯度规则的良好性能的关键参数既不是横向连通性也不是总输入。相反,它是动作选择规则(此处为:基于发放率的群体向量)与资格迹中编码的信息之间的微妙相互作用(请参阅Discussion以获取更多详细信息)。
在我们的模型中,动作取决于动作单元的群体矢量,该群体是根据每个单元大约200ms的脉冲计数计算得出的。发出最多脉冲的动作单元最有可能在给定位置主导动作选择。因此,当突触前和突触后神经元共同活跃时增加权重的标准Hebbian学习规则将为最有可能在此位置确定动作的动作神经元设置一个最强的资格迹。如果这一动作带来了奖励,那么这些权重将得到加强。因此,τc → ∞的模型确实有效就不足为奇。τc = 0的标准策略梯度规则会是什么样的情况?只要在持续时间T的决策周期内期望脉冲次数ρiT小于1,对于所有发放脉冲的神经元,资格迹中的yi(t) - ρi(t)项都是正值——确切地是通过群体矢量确定下一步动作的神经元。但是,如果发放率较高,则在标准策略梯度规则的单次试验中不能保证资格迹中保留的记忆与所选动作之间的这种匹配(有关更多详细信息,请参见Discussion)。我们报告说,不进行横向连接的网络的平均瞬时发放率(计算为第20次和第30次试验之间所有动作单元之间的均值)为ρ = 0.002 Spikes/ms。对于相同的网络(但横向连接较弱)是ρ = 0.006 Spikes/ms(三倍),而横向连接较强的则更高一个数量级,即ρ = 0.032 Spikes/ms。更重要的是,在图3C–D中,活动凸起内的神经元发放率ρ = 80 Hz,产生ρT ≈ 16脉冲,T = 200ms。因此,最活跃的突触资格迹累积了约16个突触后神经元的脉冲。
对于τc = 5ms的情况,我们比较了没有基准减法b = 0和有基准减法![]() 的情况,结果相似(数据未显示)。但是,如果我们在学习中进行了100多次试验,则因素
的情况,结果相似(数据未显示)。但是,如果我们在学习中进行了100多次试验,则因素![]() 会如预期的那样增加长期稳定性。
会如预期的那样增加长期稳定性。
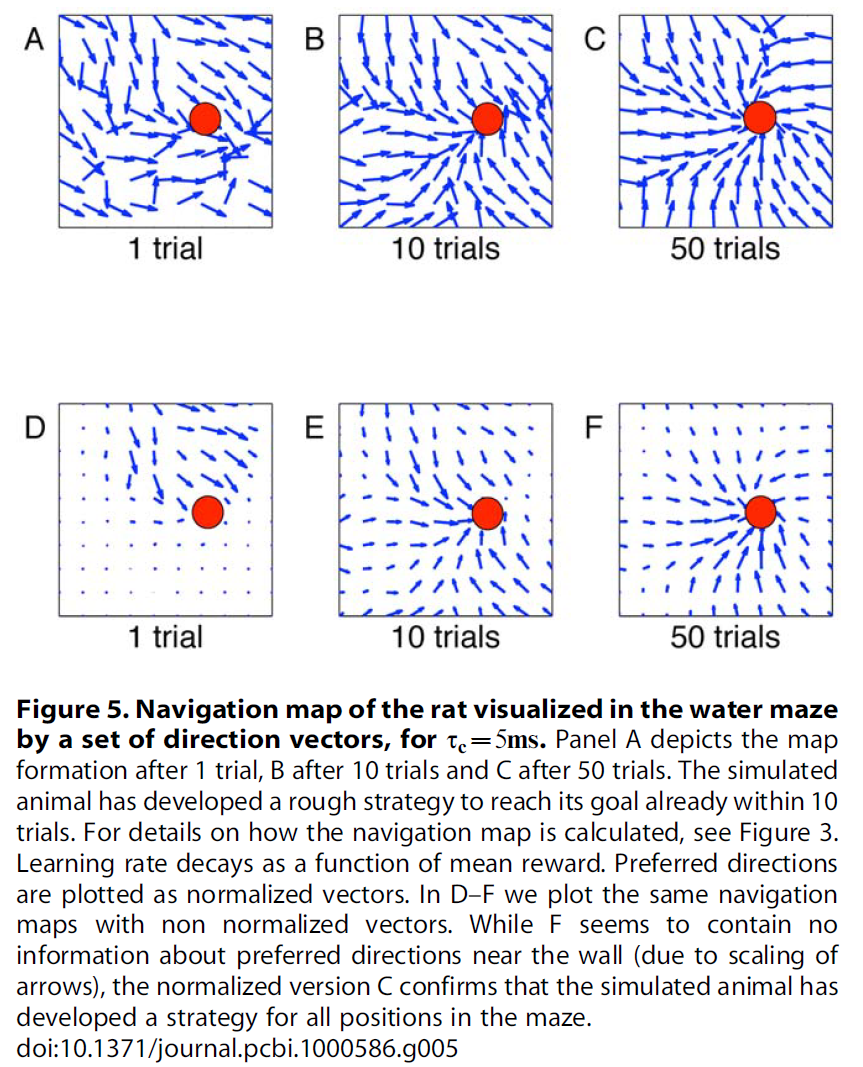
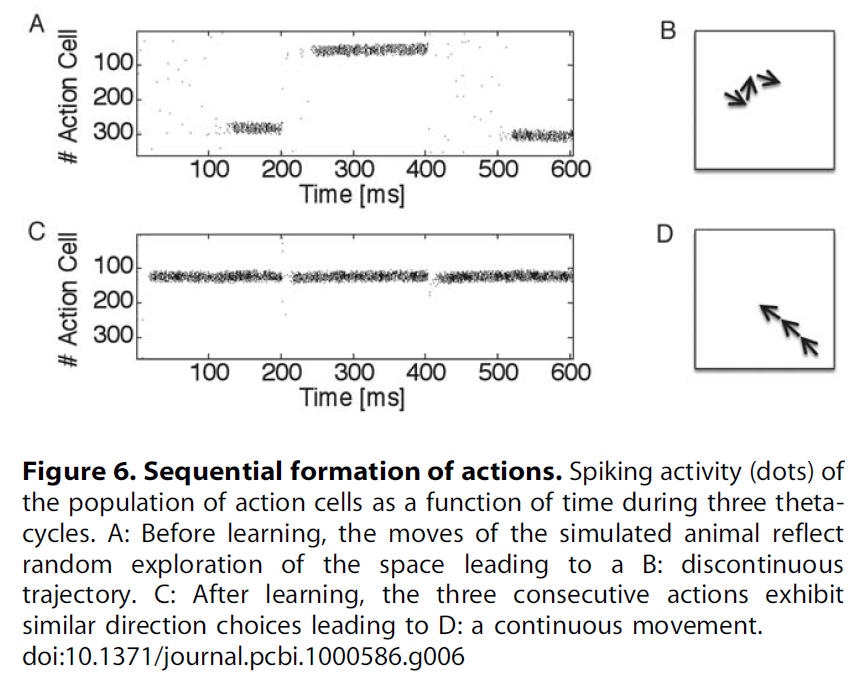
Navigation map. 给定老鼠的位置,下一步行动的方向就取决于动作单元的群体矢量。假设老鼠在单元 j 的位置场的中心。然后,动作单元的群体活动在很大程度上受到将位置细胞 j 连接到不同动作单元的突触强度控制:对于动作单元 i,突触权重wij越强,则代表 i 的动作越可能被选中。因此,我们使用来自给定位置单元的前馈连接的突触强度的群体矢量来可视化从该位置开始的运动方向。向量的组合给出了流程图,对应于大鼠的导航图。在图3A–E右侧,我们显示了第20次试验后不同τc值和横向连接的导航图。值得注意的是,在存在牢固连接(和τc > 0)的情况下,导航地图的质量会提高。图5显示了大鼠导航图在1, 10, 50和100之后的τc = 5ms内的演变情况,其中A–C表示首选方向为归一化向量,而D–F为非归一化向量。A–C表明,在10个试验中,仿真动物已经制定了实现目标的策略,而D–F显示了群体活动的相对强度,该强度随着动物向目标的靠近而增加。如果对于任何起始条件,流都朝向目标区域,则可以实现足够的学习。我们发现,经过10次试验,已经为Morris水迷宫任务制定了一个粗略的策略,并在后续试验中对其进行了完善。图6证实了在学习过程中轨迹变得更平滑。3个动作选择的序列在开始时具有很强的随机成分,但在100次试验后几乎是连续的。

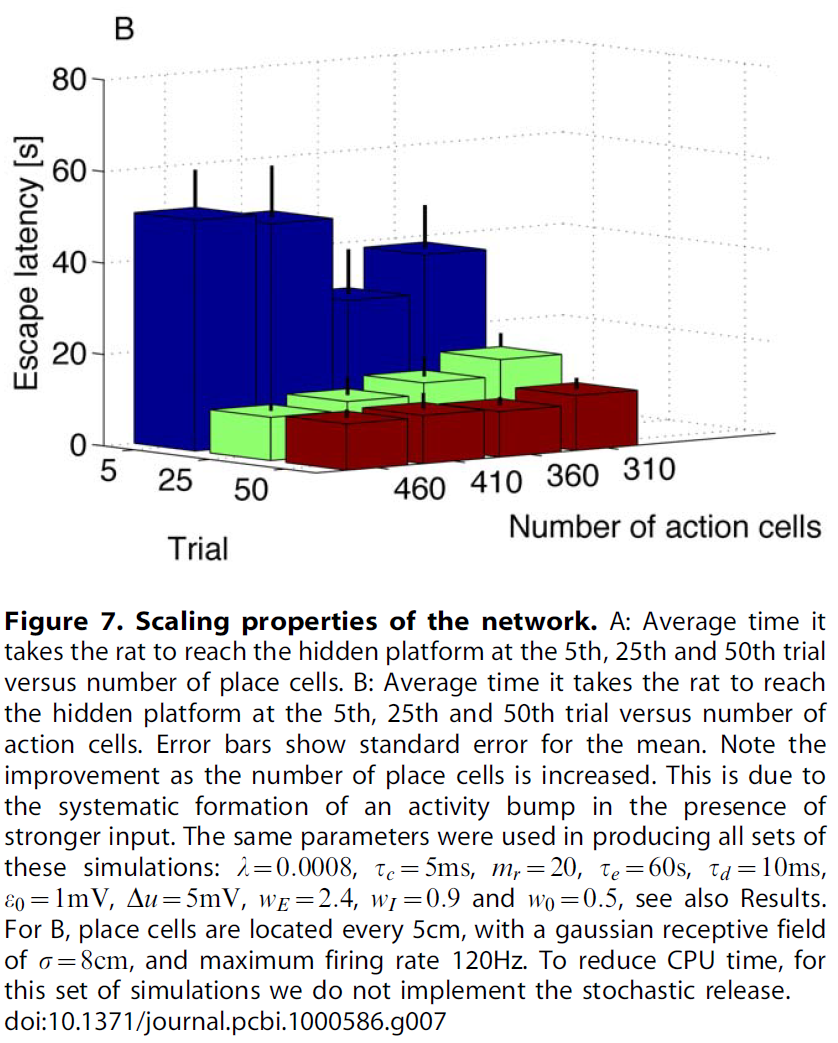
Performance vs number of place and action cells. 性能如何取决于位置和动作单元的数量?对于位置单元,我们要求水迷宫的表面将被具有重叠感受野的神经元充分覆盖。这种连续的空间表征(由于重叠的感受野)导致同时学习附近的神经元,即使在每个维度上将神经元的数量加倍,也不会导致性能的显著变化,请参见图7左侧。类似地,需要最少数量的动作单元,这样才能创建活动概况,但是将单元的数量增加到300左右不会改变性能。原因是活动概况在动作空间中始终具有大致相同的宽度(约30度)。添加更多单元只会增加活动凸起中的单元数量。在图7右侧中,我们绘制了在第5, 25和50次试验中大鼠到达隐藏平台所需的平均时间与动作单元的数量之间的关系。我们注意到性能没有明显变化。这与离散状态和动作空间中的标准强化学习相反,在标准状态中,增加状态或动作的数量会增加自由参数的数量,从而使学习变慢[1]。
Discussion
我们提出了一个基于脉冲的强化规则,该规则将全局奖励信号与两个在突触部位可用的局部因素结合在一起。第一个局部成分是突触前脉冲到达所产生的贡献,并以EPSP的形式输入更新规则。第二个局部成分正向依赖于突触后脉冲发放,而负向依赖于突触后膜电位。膜电位的相关性随τc的降低而下降,而对τc → ∞则消失。学习规则的第三个因素是可与神经调节剂(如多巴胺)相关的全局奖励信号[22]。因此,结合了两个局部因素的资格迹标志着可以经历LTP或LTD的突触。实际权重变化仅在通过可能会出现显著延迟的全局奖励信号确认后才执行。这样的图片与突触标记和捕获的模型有着有趣的关系[27],其中突触连接经历了早期LTP或LTD的初步变化,这些变化会衰减,除非在可塑性相关蛋白可用的情况下稳定下来。这些可塑性相关蛋白的合成可能会延迟发生,并需要神经调节剂,如多巴胺[28,61]。
Global factors, neuromodulators, and TD-learning
在引言中,我们提到了两类理论RL算法,即TD学习方法[1,43]和策略梯度方法[39,40]。我们的模型任务和模型结构将允许以三因素规则的形式测试两种算法(有关此任务的TD算法示例,请参见[45,52–54])。TD算法与本文算法之间的主要区别在于全局因素如何编码有关奖励的神经调节反馈。在TD学习的情况下,全局因素表示收到的奖励和期望奖励之差(其中期望奖励是根据后续状态的奖励期望之间的时序差异计算的[1]),而对于本文的梯度学习算法,全局因素对应于奖励本身,可能是在减去基准之后得出的。在此,我们使用了基准概念的变体,因为我们减去了先前试验中次序m的平均奖励,另请参见[41]。在学习任务发生变化的情况下(例如,通过将逃生平台移动到其他位置),减去期望奖励应有助于快速重新学习[67]。与TD学习类似,在这种情况下,全局因素可以解释为奖励减去期望奖励。与TD学习相反,期望奖励来自运行均值,而不是像基于脉冲的TD算法一样,不同状态之间的奖励期望有所不同[37,45]。对多巴胺能神经元的实验表明,尽管多巴胺信号的其他解释[68]和其他神经调节剂的参与也是可能的[69],但相位多巴胺信号确实编码了类似TD的误差信号。
我们基于脉冲的导航模型具有对状态和动作的连续描述。与具有离散状态和动作空间的传统TD模型不同,在保持位置场的宽度和动作单元之间的横向交互作用的宽度恒定的同时,增加神经元数量不会改变我们模型的性能。此外,该模型为研究导航环境中的决策提供了见识。我们假设活动是在theta频率下调节的。请注意,我们实现了一种极端情况,即在每个theta周期结束时都选择了动作。但是,很容易让大鼠在形成活动概况后立即采取动作。然后,创建活动概况所需的时间决定了决定新动作的最短时间。如果是这样的话,那么我们的模型将预测学习后选择下一个动作所花费的时间比学习前要快得多,这是因为通过强大的前馈输入,活动概况会更快地形成(就像学习后那样)。
Morris water maze task
为了测试基于脉冲的强化规则的潜力,我们已将其应用于生物学相关的导航问题,即具有可变起始条件的Morris水迷宫任务[51]。我们的模型基于位置单元和动作单元的简化模型,以逃避时延与学习时间的关系再现了真实大鼠的行为数据。该模型由大约700个脉冲神经元组成,分为两层,包括前馈和横向连接。在第一个试验中,模型大鼠以随机轨迹运动并通过探索找到隐藏平台。在几次试验中,都加强了通向平台的进场路径,从而减少了逃生时延。
当模型老鼠到达目标位置时,将获得正奖励。在模型中,我们还在迷宫的边界处使用了负奖励,以便仿真老鼠学会避开墙壁。这方面没有反映出这样一个事实,通常,在发育过程中(甚至由于出生时出现反射),我们可以假设老鼠在开始进行水迷宫任务之前已经知道如何避免障碍。但是,由于我们不想将有关避障的先验知识纳入模型中,因此我们让仿真老鼠"发现"墙的影响。由于我们的模型假设存在位置单元,因此,我们必须假设老鼠已经对环境进行过一定程度的预暴露,足以建立位置场。实验表明,在第一次探索环境期间会建立位置场,因此在学习任务期间,可以将它们视为给定的。此外,典型的实验要求动物先适应环境,以便可以形成位置单元。从视觉输入和路径整合中学习位置单元的模型也是可能的[53]。
虽然在我们的模型中,位置单元可以很容易地与海马体中的单元相连,但是用生物学底物直接鉴定动作单元则存在更多问题。在啮齿动物中,水迷宫任务中的导航涉及两个相互竞争的途径[70-72]。第一个涉及分类群导航(例如,接近可见目标,可以通过刺激-响应习惯[73](也称为响应学习[71]来实现)),并将视觉输入与运动动作直接关联。它独立于海马体,并且该导航策略的动作选择可能与基底神经节的背侧纹状体(大鼠中的尾足)相关。第二个问题与语言环境导航(也称为位置学习[71]或认知图[74])有关,这是本模型中的相关途径。它依赖海马体[51,70,71],在这里海马体的位置单元的活动可能编码了仿真动物的位置。运动动作的选择大概编码在我们假设的动作单元可能位于的腹侧纹状体的伏核(NA)中。动作单元之间的"墨西哥帽"连接性简化了更复杂的接线方案,其中兴奋性神经元投影到抑制性神经元,而抑制性神经元又抑制了编码"不同"方向的其他动作单元,例如,生物学合理的赢家通吃[75]。但是,为了减少网络中的连接性,我们选择仿真等效但更简单的"墨西哥帽"方案。
该模型的一个局限性是,学习仅在奖励信号存在的情况下发生,结果是学习只能在奖励周围有限的半径内发生。半径与资格迹的时间尺度有关,由时间尺度τe决定。在以固定速度v0穿越环境所需时间比τe长得多的大型环境中,有关目标的信息以空间比例r = τev0呈指数下降。在我们的案例中,仅当环境缩放比例明显大于2时,我们才会遇到此限制。
在TD框架中,情况会有所不同:即使没有资格迹,有关奖励存在的信息也可以在估计的奖励期望值V(x)的范围内缓慢扩散,其中x是位置,甚至超过以上讨论的半径 r。奖励信息的这种缓慢扩散是可能的,因为更新与奖励本身不成比例,而是与因素δ = R + γV(x') - V(x)成比例,其中V(x') - V(x)给出了位置x'和先前位置x的奖励估计之差,0 < γ < 1是折扣因子。可以使用actor-critic方案在脉冲神经元中实现TD学习结构[37,45]。如果在具有时间步骤的离散时间Δ中实现TD算法,并且如果大鼠以恒定速度v0像以前一样奔跑,则两个时间步骤之间的行进距离为Δx = v0Δ。收敛后,价值函数在距目标的距离上以指数尺度![]() 减小。(换句话说,一旦达到指数衰减的V相关性,更新规则中的δ就会消失)。与上一段中的结果进行比较表明,在我们的模型中资格迹的时间尺度τe的作用类似于TD模型中的Δ/(1 - γ)。资格迹的作用已在[35]中进行了广泛的讨论。在我们的解释中,资格迹是在突触中实现的,其时间常数τe对应于某些生化物质的衰减时间。
减小。(换句话说,一旦达到指数衰减的V相关性,更新规则中的δ就会消失)。与上一段中的结果进行比较表明,在我们的模型中资格迹的时间尺度τe的作用类似于TD模型中的Δ/(1 - γ)。资格迹的作用已在[35]中进行了广泛的讨论。在我们的解释中,资格迹是在突触中实现的,其时间常数τe对应于某些生化物质的衰减时间。
参数τc是一个临时参数,允许我们从策略梯度理论的意义上将学习规则的行为从纯Hebbian更改为最优。我们不希望将其与生物学底物明确关联,但是在我们的模型中,它将与LTD的电压依赖性密切相关。
最近,在少数研究中已经研究了神经调节剂对脉冲时序依赖突触可塑性的影响[31,76]。这些研究表明,多巴胺作用于STDP的时间分布,而不是作用于STDP的简单缩放。该结果与标准奖励调节STDP的一些假设相反[35,36],但与策略梯度规则[33,34,38]和本文讨论的学习规则不同。对于皮质-纹状体突触的可塑性[31],而不是海马体神经元的谷氨酸能突触[76],多巴胺对于突触可塑性是必需的。换句话说,多巴胺的存在限制了学习。在这方面,皮质-纹状体突触中的可塑性规则类似于本文中的奖励门控可塑性规则。有趣的是,纹状体可能参与动作选择。
应该注意的是,在标准皮质STDP实验中[77,78]并未明确控制多巴胺和其他神经调节剂的水平,并且不能排除多巴胺的背景水平。因此,尚不清楚皮质STDP是否不受监督或对神经调节剂的依赖性可能弱。
Limitations of policy gradient methods
我们的学习规则系列中的一个重要参数是参数τc,它可以调整学习率,从而降低以高学习率激发的神经元LTD。要看到这一点,请考虑瞬时发放率![]() 。然后,项
。然后,项![]() 收敛为
收敛为![]() 。因此,在不存在脉冲的情况下资格迹的减少受到限制。注意,由于ρ = g(u),高发放率对应于膜电位的大去极化。对于τc → ∞,项
。因此,在不存在脉冲的情况下资格迹的减少受到限制。注意,由于ρ = g(u),高发放率对应于膜电位的大去极化。对于τc → ∞,项![]() 消失,并且膜电势u不再进入资格迹的更新。在这种情况下,资格迹记录由突触前脉冲到达和突触后发放引起的EPSP之间的Hebbian相关性
消失,并且膜电势u不再进入资格迹的更新。在这种情况下,资格迹记录由突触前脉冲到达和突触后发放引起的EPSP之间的Hebbian相关性![]() 。
。
情况τc = 0对应于方法部分中所示的从奖励最大化推出的学习规则,即![]() 。对于τc = 0,两个突触后项(即脉冲发放和电压依赖性)平均相互抵消,因为产生的脉冲具有随机强度ρi = g(ui),因此<Yi(t) - ρi(t)> = 0,其中尖括号表示期望值。但是,脉冲序列的特定实现(例如,脉冲比预期多的脉冲序列)可能会产生奖励,而另一种(脉冲比预期少的脉冲序列)则不会产生奖励。在这种情况下,只学习了有奖励的,这使得更有可能针对相同的输入再次再现相同的脉冲序列[34]。实际上,用于调节的一大类学习规则可以解释为奖励与噪声引起的输出变化之间协方差的增强[79]。
。对于τc = 0,两个突触后项(即脉冲发放和电压依赖性)平均相互抵消,因为产生的脉冲具有随机强度ρi = g(ui),因此<Yi(t) - ρi(t)> = 0,其中尖括号表示期望值。但是,脉冲序列的特定实现(例如,脉冲比预期多的脉冲序列)可能会产生奖励,而另一种(脉冲比预期少的脉冲序列)则不会产生奖励。在这种情况下,只学习了有奖励的,这使得更有可能针对相同的输入再次再现相同的脉冲序列[34]。实际上,用于调节的一大类学习规则可以解释为奖励与噪声引起的输出变化之间协方差的增强[79]。
有三种原因导致从奖励最大化中得出τc = 0的标准策略梯度规则不适用于我们的情况。
(i)高学习率。从奖励优化中推导出的学习规则是一个批处理规则,即,它假设在多个实现和许多输入之间求均值。为了过渡到在线规则,我们必须假设学习率很小,以便使学习自我平均。如果学习缓慢,那么在权重发生显著变化之前,需要进行成千上万次试验,以便在线和批量试验具有几乎相同的效果。
为了解释生物学学习范式,我们需要经过最少十次尝试才能获得学习。如果我们以较大的学习率λ进行工作,那么在批处理规则中取均值Yi(t) - ρi(t)项可以对每个单项试验的资格迹做出重大贡献,并且可以导致权重变化与奖励没有因果关系。因此,资格迹对噪声进行编码,而不是对相关性进行编码。学习率小的情况下,这些相关性将平均化(只有与奖励有系统关联的那些相关性才能幸存),而学习率大的情况下,这些变化就像扩散过程一样。此外,扩散的效果随着决策窗口中脉冲数量增加而增加,因此对于具有较大发放率ρi的神经元来说,扩散效果最高。大的发放率ρi尤其是在学习活动凸起内的神经元后出现,因为强大的横向输入被添加到强大的前馈输入中。因此,如图8B所示,资格迹在凸起的中心最嘈杂。
(ii)由发放率决定,而不是由脉冲决定。策略梯度规则的奖励最大化与监督学习之间的密切关系表明,基于脉冲的规则(τc = 0)对于学习特定的时空脉冲模式是最优的[34]。但是,在我们的仿真中,对于动作选择而言至关重要的是200ms内累积的发放率。为了理解这种区别的重要性,让我们考虑两个分别对动作"左"和"右"进行编码的Poisson神经元。动作"右"是有奖励的。假设神经元接收输入,这些输入驱动神经元以ρleft = 5Hz的强度编码另一个信号,而另一个以ρright = 50Hz的强度编码。假设由于固有噪声,编码"左"的神经元在T = 200ms的决策间隔内发放2个脉冲,而编码"右"的神经元在相同的时间间隔内发放9个脉冲。如果根据最大发放率选择动作,则神经元编码为右的获胜,系统将执行动作"右"并获得奖励。但是,项![]() 对于编码为"右"的神经元为负,对于编码为"左"的神经元为"正"。因此,在获得奖励后,动作"右"被削弱,而动作"左"被加强,这与事实相反,动作"右"是应当加强的正确事实。换句话说,动作神经元必须了解(a)精确的脉冲时间是不相关的,并且(b)甚至是绝对发放率也不相关,因为重要的是相对于其他神经元的发放率。由于策略梯度规则倾向于学习精确的时空脉冲模式,因此它并不理想地适合于我们的范例。相比之下,奖励调节的Hebbian学习只会使以高频率发放(并影响动作)的神经元以更高的频率发放。在特定的任务中,我们认为这恰好是一种可行的策略。
对于编码为"右"的神经元为负,对于编码为"左"的神经元为"正"。因此,在获得奖励后,动作"右"被削弱,而动作"左"被加强,这与事实相反,动作"右"是应当加强的正确事实。换句话说,动作神经元必须了解(a)精确的脉冲时间是不相关的,并且(b)甚至是绝对发放率也不相关,因为重要的是相对于其他神经元的发放率。由于策略梯度规则倾向于学习精确的时空脉冲模式,因此它并不理想地适合于我们的范例。相比之下,奖励调节的Hebbian学习只会使以高频率发放(并影响动作)的神经元以更高的频率发放。在特定的任务中,我们认为这恰好是一种可行的策略。
(iii)神经元群体而不是单个神经元。此外,由于形成了活动凸起,并通过群体矢量进行了读取,因此有关决策的决定权是由神经元群体而不是单个神经元来决定的。在群体中学习存在以下问题:单个神经元发放可能不同于导致动作的多数投票,因此给予适当的反馈是不平凡的[80]。
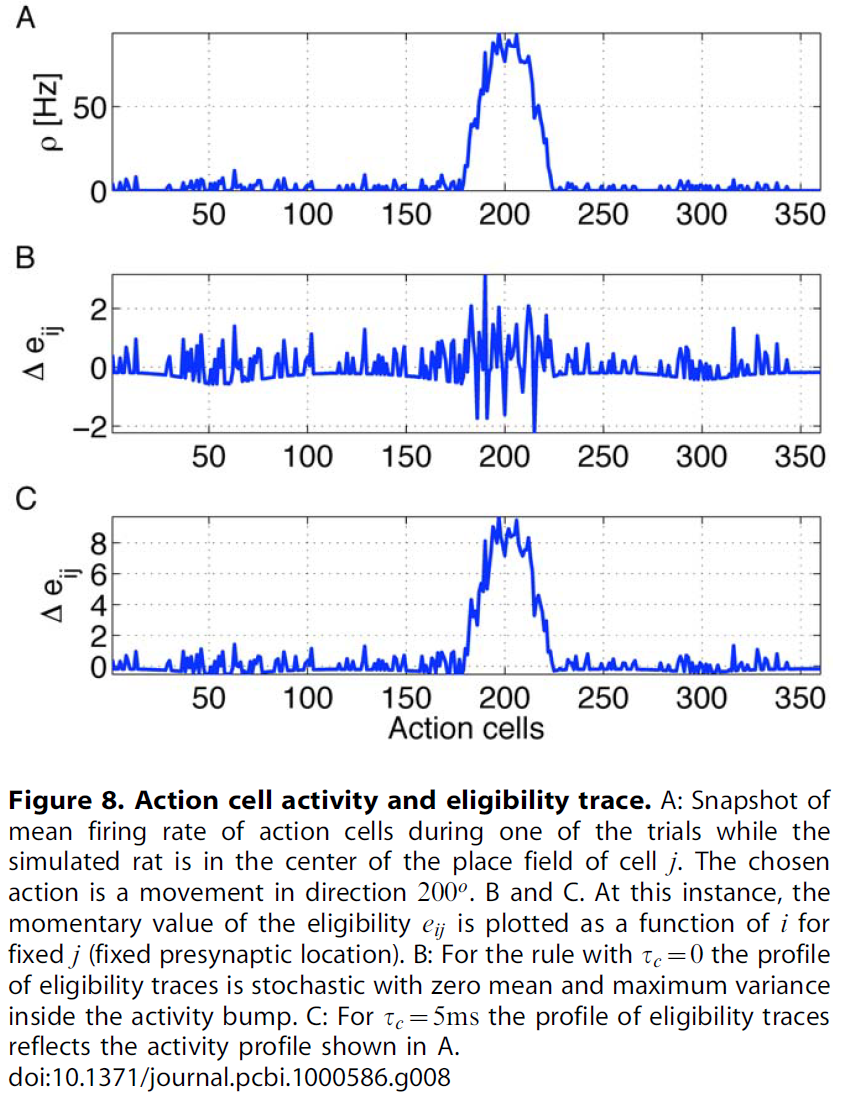
图8说明了标准策略梯度规则的点(i)-(iii)的有害相互作用。我们专注于突触前神经元 j,它编码大鼠的当前位置,从而使从 j 到所有动作神经元 i 的突触活跃。瞬时发放率ρi表示活性凸起(图8A)。尽管项Yi(t) - ρi(t)的期望值为零,但项Yi(t) - ρi(t)在每个试验中均具有不可忽略的贡献,另请参见图1C——应该是因为策略梯度规则需要利用波动。但是,我们要强调两个方面。 首先,类似于扩散过程,|Yi(t) - ρi(t)|的标准差随时间增长。其次,扩散常数随瞬时发放率ρ增加。因此,与<Yi(t) - ρi(t)> = 0期望值的偏差随神经元在长度T的决策间隔内发出的期望脉冲数量ρiT而增加。资格迹对此偏差很敏感。在我们的动作学习模型的情况下,上述论证的结果是,针对固定的突触前神经元 j 的一组显著的正资格迹eij不仅包括活动凸起内的动作神经元,还包括代表其他方向的那些动作神经元。参见图8B。此外,活动凸起内相邻神经元之间的资格迹变化很大,因为活动凸起内神经元的期望脉冲数量更高。特别是,从固定的突触前神经元到突触中的神经元的多个突触具有明显的负资格迹(对应于以下事实,即突触中的一些神经元发出的脉冲少于发放率ρi的期望脉冲,请参见上面的(ii)点)。这导致了一个问题,即单个神经元的资格迹不能反映出活跃神经元群体所代表的动作选择[80]。简而言之,凸起内部的神经元是决定动作的神经元,即使其资格迹可能为负。
我们的学习规则中的参数τc对那些具有高发放率的突触后神经元给出了突触后项的系统正偏差。因此,对于活动凸起内的神经元(即那些代表实际选择的动作的神经元),资格迹最大;参见图8C。因此,如果一系列动作导致以后的奖励,那么实际上导致这些动作序列的那些突触前位置单元和突触后动作单元之间的突触权重将得到最大增强。由于权重动态的界限,这些权重最终将收敛到qij = 1的释放概率。我们注意到,该活动凸起之外的所有神经元的活动都很低,因此![]() 的均值为零,且波动很小。因此,对于大学习率λ,高发放率ρ以及基于长时间计算的群体向量的决策标准的情况下,预期学习规则(τc > 0)会更好地工作。
的均值为零,且波动很小。因此,对于大学习率λ,高发放率ρ以及基于长时间计算的群体向量的决策标准的情况下,预期学习规则(τc > 0)会更好地工作。
在一般的基于脉冲的学习问题中,其目的是学习时空脉冲模式,资格迹的高度可变性将允许探索较大的发放模式空间。但是,在我们的情况下,横向交互和决策不是基于详细的发放模式,而是仅基于200ms以上的群体矢量数据,偏向高活动会识别出凸起中参与动作选择的神经元。
确实,在(a) 动作单元之间没有横向相互作用或(b) 决策基于平均每个神经元少于一个脉冲的情况下,具有τc = 0的学习规则确实有效。在后一种情况下,每个脉冲都是不可预料的,并且基于群体向量的决策会选择确实由波动引起的动作。
原则上,四个动作神经元足以编码下一个动作的方向(例如[45,53])。在这种情况下,基于策略梯度[45]或朴素的Hebb[53]学习规则起作用。但是,很可能在生物大脑中,动作是由大量神经元编码的。为了在动作神经元数量众多的情况下仍能实现快速学习,动作神经元必须在学习过程中共享信息,而这可以通过形成活动凸起来实现。本文的结果表明,在存在活动凸起和基于脉冲计数的群体矢量读出的情况下,基于脉冲的策略梯度规则不再起作用,而偏向于Hebbian相关性的规则起作用。
从技术角度来看,随机突触和电压依赖性可塑性对模型的功能都不重要,但是对于规则的生物物理学合理性而言,它们都是理想的属性。在我们的模型中,突触的随机释放概率是严格限制的,以便维持合理的值,有关这种界限的生物物理学实现,请参见[46]。
同样,不必每200毫秒精确地进行一次重置。原则上可以在形成活动凸起的任何点发生。我们仅需要重置动作神经元层中的活动(或等效地,我们可以将AC活动截断为10ms),以使活动概括不会变成"粘性",而不会以其他任何方式影响学习。如果不重置,老鼠最终将再次学习平台的位置,但是其运动将变得更加弯曲。在做出决定后,需要一个负输入,以便在学习开始时,下一个动作将不依赖于前一个动作。此负输入可能会在决策(活动凸起)形成后的任何时候到达。我们选择了200ms,以便它可以与theta节奏一致,但是可能是150ms或300ms,或者是一个随机间隔(如我们在仿真中所示)。
Methods
策略梯度方法[39,40]已多次应用于脉冲神经元,并导致基于脉冲的奖励式学习[32-34,38]。在下面的小节中,我们再次推导出相同的规则,但目的是表明该推导即使在具有强大的横向连接性的脉冲神经元网络中也成立(另请参见[40]中的注释)。在下面的两个小节中,我们过渡到具有资格迹和随机突触传递的在线公式。在小节中,我们通过引入参数τc离开策略梯度框架,以实现标准策略梯度规则和朴素的Hebbian规则之间的平滑过渡,该规则直接测量EPSP时间尺度上突触前脉冲到达与突触后发放之间的相关性。本文主体中使用的规则是策略梯度和朴素的Hebbian规则之间的混合体。
Derivation of the learning rule
为了得出一个高度连接的网络的学习规则,该网络具有从位置单元 j 的输入接收到的横向连接的动作单元 i,我们首先要考虑一种受限的情况,即老鼠总是在相同的初始位置开始试验,并且要在固定的持续时间T内四处移动。我们用xT(yT)表示所有位置(动作)单元在此期间生成的时空脉冲模式。在每个试验结束时给予的奖励取决于水迷宫中大鼠的运动轨迹。在给定固定的初始位置的情况下,该轨迹由动作单元的发放来确定。因此,我们将奖励写成函数R(yT) - b,其中b是强化基准[39],而没有明确指出对大鼠初始位置的依赖性。那么,期望奖励是[32,34]:
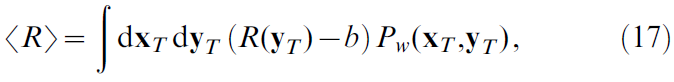
这里w表示将动作连接到位置单元的突触强度,而Pw(xT, yT)是网络生成总脉冲模式(xT, yT)的概率。
在我们的模型中,Pw(xT, yT)可以分解为(另请参见概率分解):
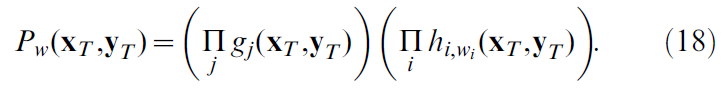
在此,![]() 是为动作单元 i 提供单个神经元概率的函数,它会生成其脉冲序列
是为动作单元 i 提供单个神经元概率的函数,它会生成其脉冲序列![]() ,其中输入包含网络产生的所有其他脉冲。类似地,gj(xT, yT)是第 j 个位置单元在给定其输入(由网络中的其他脉冲确定)的情况下产生的脉冲序列的单个神经元概率函数。
,其中输入包含网络产生的所有其他脉冲。类似地,gj(xT, yT)是第 j 个位置单元在给定其输入(由网络中的其他脉冲确定)的情况下产生的脉冲序列的单个神经元概率函数。
请注意,以上乘积形式并不意味着脉冲序列在统计上是独立的。显然不是这样:首先,由于动作单元之间的横向连接,更重要的是,由于动作单元决定了大鼠的轨迹从而影响了位置单元的发放这一简单事实。乘积形式简单地表示以下事实:内部随机过程(其调节突触前输入到突触后输出的转变)被认为在不同细胞之间是独立的。换句话说,给定来自所有其他神经元的输入脉冲以及直到时间 t 之前其自身的脉冲,神经元 i 会本地决定是否在 t 和t+Δt之间发放(即,在仿真的每个时间步骤里,我们为每个神经元激活独立的随机过程),请参见"概率分解"部分。
gj(xT, yT)的显式形式非常复杂,这是由于所涉及的计算将动作单元发放映射到大鼠的轨迹。幸运的是,我们仅明确需要![]() 。注意,这实际上是分解的关键特征,
。注意,这实际上是分解的关键特征,![]() 不取决于所有前馈权重,而仅取决于实际投影到神经元 i 上的突触的权重向量wi。
不取决于所有前馈权重,而仅取决于实际投影到神经元 i 上的突触的权重向量wi。
为了计算期望奖励的梯度(17),我们首先将概率Pw(xT, yT)重写为:
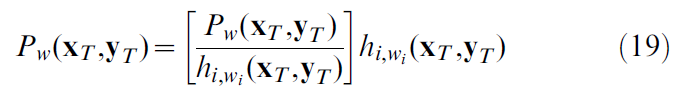
并请注意,鉴于(18),方括号中的项实际上并不取决于wi(即使从符号中看不出来)。现在,对于将位置单元 j 连接到动作单元 i 的突触,梯度计算为:
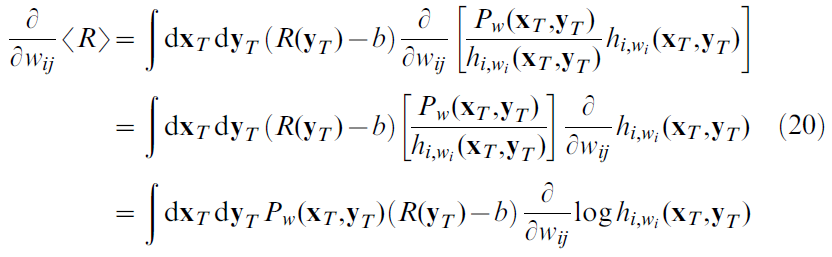
最后一行产生突触变化的批处理规则。我们先求均值:
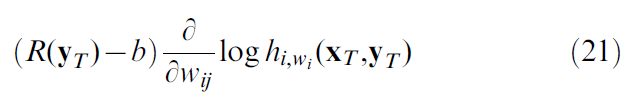
在许多试验中,然后使用结果更新突触强度。生物学合理的在线版本已在每个单次试验后更新,即:

通常,我们会根据过去的经验![]() [39],用即将来临的强化估计来替换强化基准b。在线学习的背景下,不再需要我们对固定初始位置的初始要求,因为我们不仅通过对具有相同初始位置的试验,而且还对具有不同初始位置的试验求均值,来计算期望奖励。
[39],用即将来临的强化估计来替换强化基准b。在线学习的背景下,不再需要我们对固定初始位置的初始要求,因为我们不仅通过对具有相同初始位置的试验,而且还对具有不同初始位置的试验求均值,来计算期望奖励。
学习规则的关键要素是在给定输入xT的情况下创建某些输出yT(并因此采取某些动作)的条件概率。为了计算给定过去神经元 i 发出脉冲的条件概率![]() ,我们需要引入一个神经元模型。遵循Pfister et al. [34]的方法,我们假设神经元活动可以由脉冲响应模型(SRM)[20]描述:
,我们需要引入一个神经元模型。遵循Pfister et al. [34]的方法,我们假设神经元活动可以由脉冲响应模型(SRM)[20]描述:
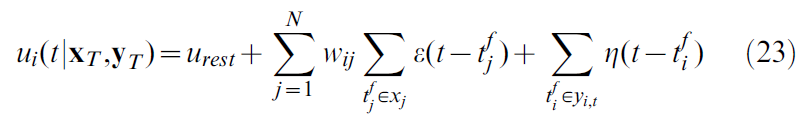
其中ui(t)是神经元 i 的膜电位,urest = -70mV是静息电位,xj是突触后脉冲的集合,![]() 是直到时间 t 的突触后脉冲的集合,wij是突触前神经元 j 和突触后神经元 i 之间的突触强度,
是直到时间 t 的突触后脉冲的集合,wij是突触前神经元 j 和突触后神经元 i 之间的突触强度,![]() 是突触前神经元 j 的第 f 个发放时间,
是突触前神经元 j 的第 f 个发放时间,![]() 是突触后神经元 i 的第 f 个发放时间。 总和仅限于时间 t 之前的发放时间。核ε(t)描述了关于兴奋性突触后电位(EPSP)和η(t)电位后脉冲的时间过程。我们要强调的是,对于指数核ε(t) = ε0 exp(-t / τm)和指数电势后脉冲η(t) = η0 exp(-t / τm),SRM等于结果部分的公式(11)中使用的膜时间常数为τm[20]的LIF模型。
是突触后神经元 i 的第 f 个发放时间。 总和仅限于时间 t 之前的发放时间。核ε(t)描述了关于兴奋性突触后电位(EPSP)和η(t)电位后脉冲的时间过程。我们要强调的是,对于指数核ε(t) = ε0 exp(-t / τm)和指数电势后脉冲η(t) = η0 exp(-t / τm),SRM等于结果部分的公式(11)中使用的膜时间常数为τm[20]的LIF模型。
给定膜电位ui,动作电位通过具有随机强度![]() 的点过程生成,其中g(u)是一些正非线性函数。具体来说,我们采用指数函数:
的点过程生成,其中g(u)是一些正非线性函数。具体来说,我们采用指数函数:
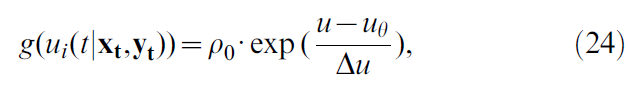
其中,uθ是正式发放阈值,以及ρ0,Δu > 0参数。因此,膜电位越高,神经元模型发放的可能性就越大。
使用上述神经元模型,在给定网络中除神经元 i 之外的所有神经元的输入xT和yT的情况下,神经元 i 在时段T内发出一组特定的突触后脉冲yi,T的概率为:
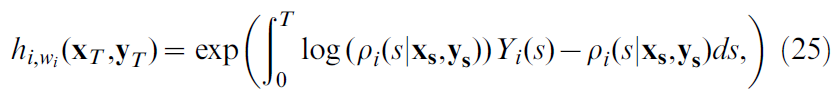
其中Yi(s)代表神经元 i 的突触后脉冲序列,作为Dirac δ函数之和(到时间s),即![]() 。取关于突触权重wij的偏导数,我们有以下等式[34]:
。取关于突触权重wij的偏导数,我们有以下等式[34]:
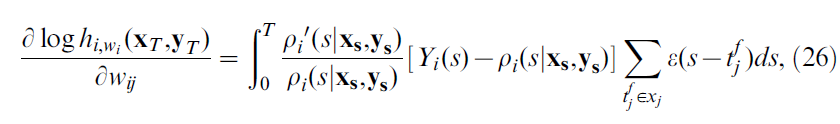
其中![]() ,yi(s)是在s之前出现的突触后脉冲的集合,ε(t)是EPSP核。请注意,对于指数函数
,yi(s)是在s之前出现的突触后脉冲的集合,ε(t)是EPSP核。请注意,对于指数函数![]() ,我们有
,我们有![]() ,因此学习规则变为:
,因此学习规则变为:
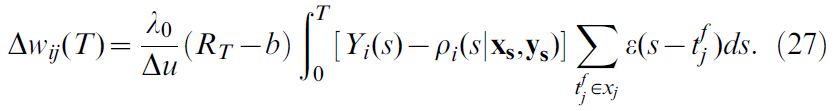
此处,RT是总持续时间为T的试验期间或之后的总奖励。
Eligibility trace
为了说明等式(27)的数学结构,我们考虑到试验结束时的时间点t = T并在时间上向后积分:

其中R(t)是时间 t 的瞬时奖励。这里γ(t - s)是一个加权函数,它使我们可以为过去的事件赋予不同的权重。如果我们设置γ(t - s') = 1 (对于0 < t - s' < T),否则取零,然后在t = T时刻求值,假设奖励是根据以下两个时间表之一给出的,则我们将精确地得到等式(27):(a) 所有奖励R(t)在时间T交付,即R(t) = RTδ(t - T)且在每个时间步骤都应用负数b;这就是我们在方法其余部分中使用的符号R(t) - b想到的场景,因为它简化了理论的发展。或者,(b) 在时间间隔(0, T)中没有给出奖励,并且在时间T施加了有效奖励RT - b,即R(t) = (RT - b)δ(t - T)。这是本文主体仿真中使用的场景。基准是b = 0或![]() 。
。
从解释(a)开始,我们可以在连续时间内转向在线规则,在该规则下可以在任意时刻提供奖励。为了更清楚地表示规则,我们将step函数γ替换为指数核![]() (对于x = t - s' > 0),否则取零。那我们有:
(对于x = t - s' > 0),否则取零。那我们有:
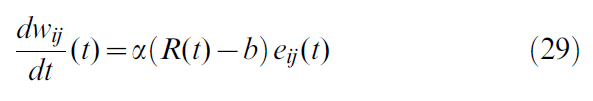
![]() 是学习率,eij被称为资格迹[1,32]。对于我们的特定模型,我们有:
是学习率,eij被称为资格迹[1,32]。对于我们的特定模型,我们有:
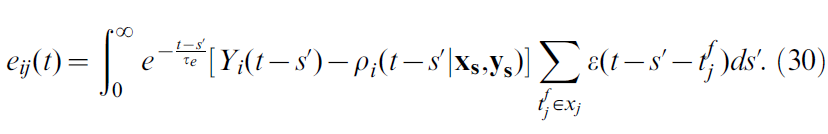
由于积分中的指数,资格迹可以重写为微分方程:
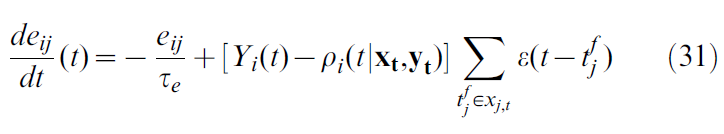
Stochastic versus continuous synapses
我们考虑具有![]() 的随机二值突触Jij。突触传递是随机的,具有释放概率qij。学习影响释放特性,因此通过上述更新规则增加突触的权重wij将增加释放概率。我们选择比例因子,以便使二值突触传递随时间的期望等于连续突触权重wij,即
的随机二值突触Jij。突触传递是随机的,具有释放概率qij。学习影响释放特性,因此通过上述更新规则增加突触的权重wij将增加释放概率。我们选择比例因子,以便使二值突触传递随时间的期望等于连续突触权重wij,即![]() 。因此,对于Δwij = βΔqij,我们对于二值突触使用以下学习法则代替公式29:
。因此,对于Δwij = βΔqij,我们对于二值突触使用以下学习法则代替公式29:
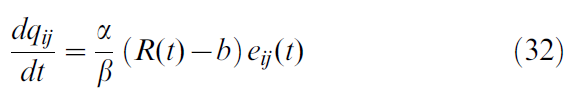
我们强加了一个硬边界qij < 1,它反映了对qij的解释是发放器释放的概率。为了保证足够的探索,我们还强加了一个非零的下限qij > 0.15。
可以通过学习率λ吸收因子![]() ,得出最终的在线规则:
,得出最终的在线规则:
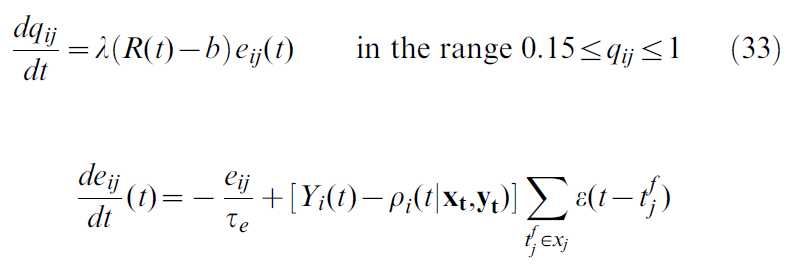
我们注意到三因素学习规则的典型结构。根据STDP学习规则[34],资格迹获得了由突触前脉冲到达![]() 引起的EPSP ε与突触后发放时间
引起的EPSP ε与突触后发放时间![]() 之间的相关性,然后将其与奖励信号组合在一起[33-35]。
之间的相关性,然后将其与奖励信号组合在一起[33-35]。
From a single rule to a family of rules
我们通过引入带有参数τc的临时变量来扩展规则:
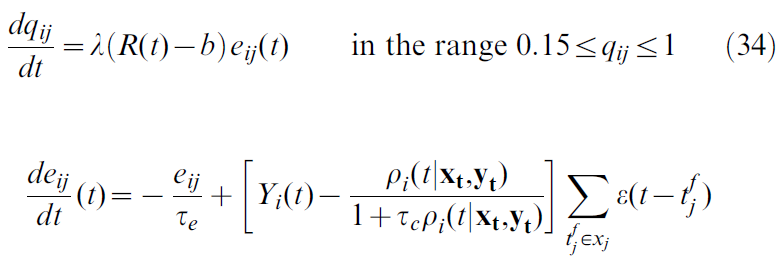
在τc → 0的极限内,这变成上面得出的规则。
等式 (34)以离散形式变为:
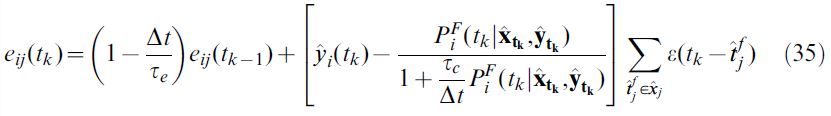
其中Δt为时间步骤,如果在间隔[tk, tk+1]内发放脉冲,则![]() 为1,否则为0,并且hat(^)运算符表示离散的发放时间。
为1,否则为0,并且hat(^)运算符表示离散的发放时间。![]() 量是给定输入脉冲序列(离散时间表示为
量是给定输入脉冲序列(离散时间表示为![]() )时突触后神经元在[tk, tk+1]间隔内发出脉冲的概率,并计算为:
)时突触后神经元在[tk, tk+1]间隔内发出脉冲的概率,并计算为:
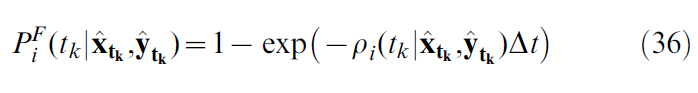
对于较大的时间步骤而言,在计算上是有利的,另请参见[20]。
在图1中,我们绘制了因素:

电压迹线是通过对恒定输入的等式(11)求积分获得的,即突触前脉冲到达被正常数代替。
Relationship to other rules
有趣的是,由[34]开发的规则以及此处介绍的变化可以在离散时间内映射到关联奖励无动作(ARI)[39,81]。与等式 (27),并且忽略基准减法,我们有:
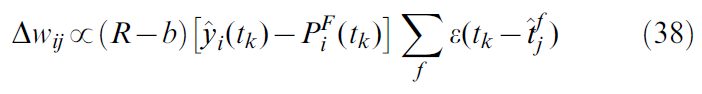
让我们假设一个持续时间为一个时间步骤和单位幅度的矩形EPSP。因此,如果脉冲在时间tk到达突触 j,则EPSP ε可以用二值变量![]() 代替,而在没有脉冲的情况下,可以用
代替,而在没有脉冲的情况下,可以用![]() 代替。然后我们有:
代替。然后我们有:
![]()
我们注意到,根据上述推导,![]() 是膜电位u的sigmoid函数。因此,丢掉hat符号(我们曾经用来表示离散时间),我们便有了ARI的更新规则:
是膜电位u的sigmoid函数。因此,丢掉hat符号(我们曾经用来表示离散时间),我们便有了ARI的更新规则:
![]()
同样,[32, 33]的学习规则也对应于ARI或其策略梯度的现代形式。实际上,[33]中的规则源自[40]的框架。[32]的规则是[33,34]的规则的特例,因为它利用了无记忆的Poisson神经模型,其中我们的推导包括通过核η的不应期。
Decomposition of probability
在这里我们表明,位置单元脉冲模式xT和动作单元脉冲模式yT发生的概率Pw(xT, yT)可以分解为乘积:
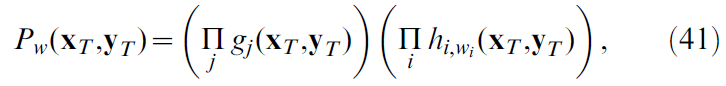
如正文方法中的等式(18)中所述。该论点与Williams [39]使用的时间展开相似,不同之处在于脉冲神经元的网络不是马尔可夫式的。我们声称上述分解适用于包括循环连接的任意网络结构。
令zi,t是离散随机变量的集合,位置索引 i = 1, ..., n,时间索引t = 1, ..., ∞。用zT表示直到时间T的整个集合。在我们的示例中,索引 i 包含位置和动作单元。此外,如果对应的单元(没有)在时间 t 发出脉冲,则![]() 。我们假设该序列是通过在时间T+1选择概率为P(zi,T+1 | zT)的值zi,T+1生成的。对于脉冲神经元,序列zT确定在时间T+1的内部状态(膜电位),并在给定先前的脉冲历史记录P(zi,z+1 = 1 | zT)的情况下调节在时间T+1发放的概率。我们进一步假设给定膜电位,触发脉冲的内部随机过程是独立的。因此,
。我们假设该序列是通过在时间T+1选择概率为P(zi,T+1 | zT)的值zi,T+1生成的。对于脉冲神经元,序列zT确定在时间T+1的内部状态(膜电位),并在给定先前的脉冲历史记录P(zi,z+1 = 1 | zT)的情况下调节在时间T+1发放的概率。我们进一步假设给定膜电位,触发脉冲的内部随机过程是独立的。因此,
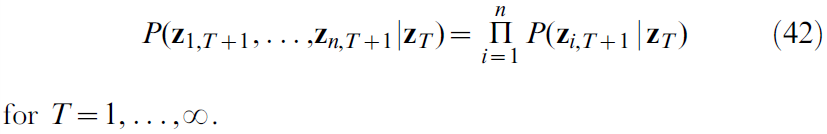
因为我们总能写出P(zT+1) = P(z1,T+1, ..., zn,T+1 | zT)P(zT) = ![]() (带有一个因素P(zT)),我们可以迭代地对P(zT), P(zT-1), ... 进行类似的乘法分解,并接收P(zT+1)的乘积表征。为了锚定乘积,我们假设(42)也在T = 0处成立,并将其表示为初始值z1,1, ... , zn,1在统计上独立于P(zi,1 | Ø)给出的概率。在分解的每个步骤连续应用(42)时,我们得出:
(带有一个因素P(zT)),我们可以迭代地对P(zT), P(zT-1), ... 进行类似的乘法分解,并接收P(zT+1)的乘积表征。为了锚定乘积,我们假设(42)也在T = 0处成立,并将其表示为初始值z1,1, ... , zn,1在统计上独立于P(zi,1 | Ø)给出的概率。在分解的每个步骤连续应用(42)时,我们得出:

设置![]() 并重排乘积项,我们可以将(43)写为:
并重排乘积项,我们可以将(43)写为:
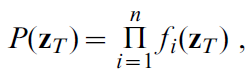
而这只是分解为(41)中表达的位置和动作单元的乘积。

Implementation
使用MathWorks开发的Matlab R2008b (Linux版本)制作模型和图形。该模型是使用定制代码实现的。有关实现的详细信息,请参见图4和9。表1和表2总结了参数值。使用Euler方法进行积分。我们根据"从一条规则到一系列规则"中的方法离散化学习规则公式,以便留出大量时间。仿真中的标准时间步骤为Δt = 1ms。我们在较小时间步骤(Δt = 0.1ms)的额外仿真中检查得出结果不取决于步长(数据未显示)。


 浙公网安备 33010602011771号
浙公网安备 33010602011771号