A Spiking Neural Network Model of Model-Free Reinforcement Learning with High-Dimensional Sensory Input and Perceptual Ambiguity
郑重声明:原文参见标题,如有侵权,请联系作者,将会撤销发布!

PloS one, no. 3 (2015): e0115620-e0115620
Abstract
RL的理论框架在理解动物的动作选择中起着重要作用。SNN提供了一种基于理论的手段,可以通过数值仿真对RL的神经学合理算法进行计算假设测试。但是,尽管这些模型是不可避免的,并且限制了实际环境中的学习功能,但是大多数模型无法处理嘈杂的或过去发生的观察。此类问题在形式上被称为部分可观察的RL (PORL)问题。它提供了对部分可观察领域的RL的泛化。另外,现实世界中的观察往往是丰富且高维的。在这项工作中,我们使用SNN模型来近似受限玻尔兹曼机的自由能,并将其应用于具有高维观测的PORL问题的求解。我们的脉冲网络模型通过感觉上模棱两可的高维观测来解决迷宫任务,而无需了解真实的环境。具有工作记忆的扩展模型还可以解决与历史相关的任务。SNN处理PORL问题的方式可能使你了解神经信息处理的基本规律,而只有通过这种自上而下的方法才能发现这些规律。
Introduction
当面对一个新颖的环境时,动物会通过试错来学习采取什么动作。这种不完全了解环境的奖励驱动学习称为RL [1]。从表明奖励预测误差与多巴胺信号相关的突出实验结果开始[2],许多研究已经研究了如何在大脑中实现RL算法[3-5]。
SNN的数值仿真可用于测试奖励学习算法在神经上是否合理,并在理论上研究计算假设的有效性。在SNN中,有几种成功实现RL的方法[6-11]。
但是,在许多现实情况下,动物所面临的问题比用RL可以解决的问题更具挑战性。观察通常是嘈杂且随机的,而最优的决策通常取决于过去的经验。RL泛化到这种部分可观察的域被称为部分可观察的RL (PORL)[12]。根据任务难度,可以将PORL问题分为两个子类。当最优策略取决于当前观察时,我们称这种情况为历史独立的PORL问题。另一方面,当最优策略取决于过去的观察时,我们称这种情况为历史依赖的PORL问题。PORL问题提供了一个框架,可以在不完全了解环境的情况下解决部分可观察的马尔可夫决策过程(POMDP)。它在理论上牢固扎实,并且也足以在现实世界中对动物的决策建模。已经提出了几种算法来解决PORL问题[13-16]。这些算法从过去的观察,执行的动作和获得的奖励的序列内部构造一个近似的马尔可夫状态。
其中,有一种算法可以使用基于随机系统自由能的方法(例如,受限玻尔兹曼机:RBM)解决PORL问题[15]。这是Sallans and Hinton方法[17]的扩展,该方法能够处理高维二值状态和动作。我们称这些方法为基于自由能的强化学习(FERL)框架。使用FERL,已知感觉信息以目标导向的方式编码在神经群体的激活模式中。这种方法在SNN中的实现应提供自上而下的一瞥,以了解基于奖励的学习的神经算法。在这项工作中,我们提出了FERL的SNN实现,并将其应用于几种类型的PORL任务的解决方案。
该论文的组织方式如下:首先,在Material and Methods部分中,我们介绍了FERL以及如何扩展它来解决PORL问题。我们还介绍了在SNN中实现其所需的概念,例如伪自由能。然后,在Results部分中,我们在难度增加的三个任务上测试我们的SNN模型:中心到达任务(RL问题),数字中心到达任务(独立于历史的PORL问题)和数字匹配T迷宫任务(历史相关的PORL问题)。最后,在Discussion部分中,我们解释我们的结果以阐明该方法的其余问题,并从生物学的角度对我们的结果进行解释。
Methods
Free-energy-based reinforcement learning
Sallans and Hinton[17]将受限玻尔兹曼机(RBM)框架的应用从无监督学习和监督学习扩展到RL。我们称其为在RL中使用基于能量的建模的方法基于自由能的RL (FERL)。这是因为它使用随机系统的自由能来捕获在RL中出现的重要量。RBM是基于能量的统计模型(也称为"无向图模型"或"Markov随机域"),其中二值节点被分为可见层和隐含层。可见层中的节点全连接到隐含层中的节点,但是同一层中的节点之间没有连接。由于这种受限的连通性,给定可见节点的值,隐含节点上的后验分布变得有条件独立,并且无需大量计算就可以精确地进行计算。在FERL中,可见层中的二值节点进一步分类为状态节点s和动作节点a。
RBM的能量函数为:


![]()
Implementation with spiking neuron
Leaky integrate-and-fire neuron

Network architecture
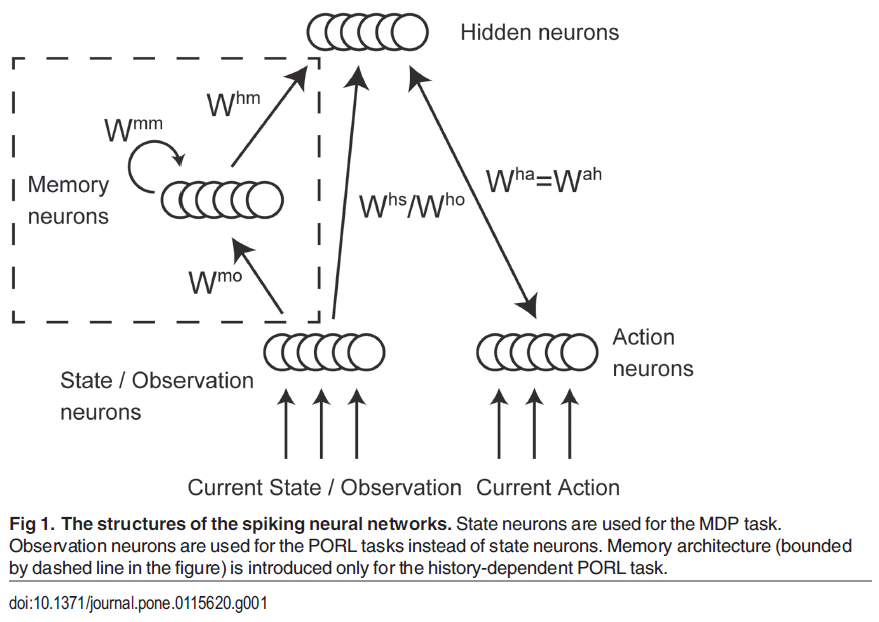
在我们提出的网络模型中,RBM中的二值随机节点被LIF神经元取代(图1)。网络由状态、动作和隐含神经元组成。根据定义,状态应包含做出最优决策所需的所有信息。因此,在MDP任务中,状态层由状态神经元组成。另一方面,在历史独立的PORL任务的情况下,状态层由观察神经元组成,而在历史相关的PORL任务中,状态层由观察和记忆神经元组成。当智能体进行观察或执行动作时,与特定观察或动作相关的神经元接收直流电。此外,所有状态和动作神经元都会不断接收带噪的输入,以确保它们在正常的发放机制下运行。所有观察和记忆神经元都单向连接到所有隐含神经元。动作神经元与隐含神经元双向连接,以反映所选动作影响隐含神经元活动的事实。
Approximation of free-energy
![]()



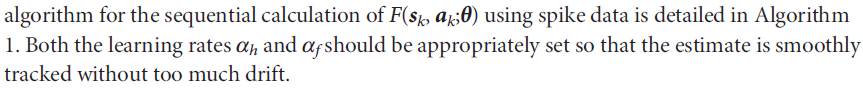

Working memory

Observation
我们使用MNIST数据集(可以从http://yann.lecun.com/expdb/mnist/下载)作为PORL任务中使用的高维观察。原始MNIST数据集的训练数据集用于特征提取。我们从原始MNIST数据集的测试数据集创建了用于PORL任务中基于奖励的学习的训练和测试集。对于每个数据集,我们为每个数字选择了10个不同的图像。通过裁剪所有四个边来减少每个图像的大小以加快计算速度。对于数字中心到达任务和数字匹配T迷宫任务,图像分别裁剪为22 × 22像素和20 × 15像素。在PORL任务的训练和测试阶段,数字是从每个时间步骤的相应数据集中随机选择的。
为了使用工作记忆处理高维观察,网络需要支持特征提取和基于提取特征的记忆层的地形组织激活。地形结构不太可能出现在使用对比散度训练的普通RBM中,因为该过程在隐含节点上生成最大程度独立的后验分布。为了同时产生特征提取和地形映射,观察层和记忆层之间的权重使用对比散度算法(CD-3)[19]进行预训练,约束条件由地形RBM[20]给出。图S1描述了在给定减少MNIST数字的测试集的情况下重建观察期间隐含节点的激活。权重是在减少MNIST数字的训练集上训练的。
Simulation settings
我们使用了三个任务来测试我们的模型:一个简单的中心到达任务作为一个MDP任务的例子,一个数字中心到达任务作为一个历史独立的PORL任务的例子,一个数字匹配T迷宫任务作为一个历史相关的PORL任务的例子。这些代码可在ModelDB (http://senselab.med.yale.edu/modeldb)上免费获得。我们为每个任务使用了不同数量的神经元(表1)。网络权重根据均值为20且标准差为11.88的正态分布进行初始化。选择这些参数以使初始权重为正值并确保脉冲神经元在正常发放机制下运行。
所有神经元采用相同的参数并具有相同的响应特性。在模拟中使用了NEST模拟器(http://www.nest-initiative.org)默认的LIF神经元。膜时间常数τm设置为10 ms。脉冲阈值Vthres设置为-55 mV。静息电位Vrest设置为-70 mV。绝对不应期设定为2 ms。脉冲后的复位电位设置为-70 mV。膜电容Cm设置为250 pF。
模拟包括重复的观察-动作循环。一个周期持续1000 ms,分为500 ms观察阶段和500 ms动作阶段。在观察阶段,一些状态/观察神经元被外部注入的电流Ie激活,并根据动作神经元的激活来选择动作。另一方面,在动作阶段,观察和动作神经元都被输入电流激活。伪自由能是根据动作阶段最后100 ms的神经活动计算得出的。
我们将以下参数用于等式(18)中记忆神经元的循环权重:![]()
Results
Center reaching task
Digit center reaching task
Digit matching T-maze task
Discussion
我们构建了一个受基于自由能的强化学习(FERL)框架启发的脉冲神经网络模型。首先,我们证明了我们的SNN模型有能力在简单的中心到达任务中处理强化学习任务。然后我们展示了我们的SNN模型可以处理数字中心到达任务中的高维输入。最后,我们证明了SNN能够解决数字匹配T迷宫任务中的PORL任务。我们的结果表明FERL可以通过SNN模型很好地近似。
我们在这项工作中做出了三项贡献。首先,我们提出了FERL的SNN实现来解决PORL问题。其次,我们对SNN和RBM进行了比较。第三,我们介绍了伪自由能及其近似值(aFE和iFE)以将RBM转换为SNN。在本节中,我们将讨论FERL的SNN实现及其可能性。
Comparison with the original RBM
Learning ability with aFE and iFE
Working memory architecture
Biological plausibility
Supporting Information
S1 Fig. Characteristics of the pretrained weights between the observation layer and the memory layer.
S2 Fig. Estimation of iFE by sequential manner.


 浙公网安备 33010602011771号
浙公网安备 33010602011771号