A Dual-Memory Architecture for Reinforcement Learning on Neuromorphic Platforms
郑重声明:原文参见标题,如有侵权,请联系作者,将会撤销发布!

Neuromorph. Comput. Eng., no. 2 (2021): 24003
Abstract:
强化学习(RL)是生物系统学习的基础,并提供了一个框架来解决现实世界人工智能应用程序的众多挑战。强化学习技术的有效实现可以让部署在边缘用例中的智能体获得新的能力,例如改进导航、理解复杂情况和关键决策。为了这个目标,我们描述了一个灵活的架构来在神经形态平台上进行强化学习。该架构是使用英特尔神经拟态处理器实现的,并演示了如何使用脉冲动态解决各种任务。我们的研究为现实世界的RL应用提出了一种可用的节能解决方案,并证明了神经形态平台对RL问题的适用性。
Introduction:
随着数据收集设备数量的增加,对高效数据处理的需求也在增加。不需要在中央位置处理从远程设备收集的所有数据,就地执行数据处理的需要正在成为优先事项;在"智能体"收集数据可能需要根据这些输入以低延迟做出关键决策的情况下尤其如此(例如在自动驾驶汽车或空中无人机中)。对于此类用例,数据处理效率变得至关重要,因为能源和物理空间("尺寸、重量和功率")非常重要1。
神经形态架构为满足这一需求提供了一条途径。尽管对于神经形态架构的构成没有统一的定义,但这些系统通常旨在提供高效且大规模并行的处理方案,这些方案通常使用二值"脉冲"来传输信息2。 鉴于神经形态架构的明确定义尚未得到普遍认可,因此很难设计一个可以编译为任何神经形态系统的程序(就像标准计算机架构的情况一样)。但是,通过将我们自己限制在几乎所有神经形态系统的共同特征的大规模并行操作上,我们可以创建一个程序,该程序可能适用于满足构成神经形态系统的新兴定义的任何平台3。在这项工作中,我们使用英特尔代号为"Loihi"的神经形态处理器。4
强化学习(RL)代表了生物系统学习的原生方式。人类和动物不是在部署之前通过大量标记数据进行训练,而是通过根据不断收集的数据更新策略来不断从经验中学习。这需要就地学习,而不是依赖于将新数据缓慢且成本高昂地上传到中央位置,在该位置将新信息嵌入到先前训练的模型中,然后将新模型下载到智能体。
为了实现这些目标,我们描述了一个用于执行RL任务的高级系统,该系统受到生物计算的几个原则的启发,特别是互补学习系统理论5,假设学习大脑中的新记忆取决于皮层和海马网络之间的相互作用。我们表明,这种"双记忆学习器"(DML)可以实现可以接近RL问题最佳解决方案的方法。然后以脉冲方式实现DML架构并在英特尔的Loihi处理器上执行。我们演示了它可以解决经典的多臂赌博机问题,以及更高级的任务,例如在迷宫中导航和纸牌游戏二十一点。据我们所知,这些先进的多步问题以前没有被证明可以单独由神经形态系统解决。我们描述了它当前实现的性能,评论了它的特性和局限性,并描述了它在未来工作中可以进行的改进。
Results:
Dual-memory learner (DML) framework
Monte Carlo (MC)方法提供了特征明确的RL技术,用于通过回合式经验学习最佳策略;智能体不需要配备一个完整的模型来了解环境将如何对其动作做出反应以进行学习。相反,智能体会跟踪它进入了哪些状态,它采取了哪些动作,一旦一个回合结束,根据它在状态空间中的轨迹,更新它的价值估计。这为强化学习提供了一个简单但有效的基础,我们专注于在我们的架构中实现这种方法(尽管它也可以扩展到更现代的TD和 n 步算法)。6
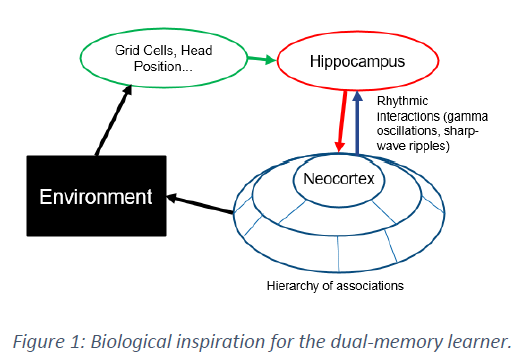
我们提出了一种双记忆学习器(DML)框架,它模仿生物大脑中学习功能的高级组织,即所谓的互补学习系统理论(图1)5,以使用脉冲网络实现MC学习技术。所提出的DML架构包含四个主要部分,它们处理和存储在神经形态平台上执行强化学习所需的信息(图2)。
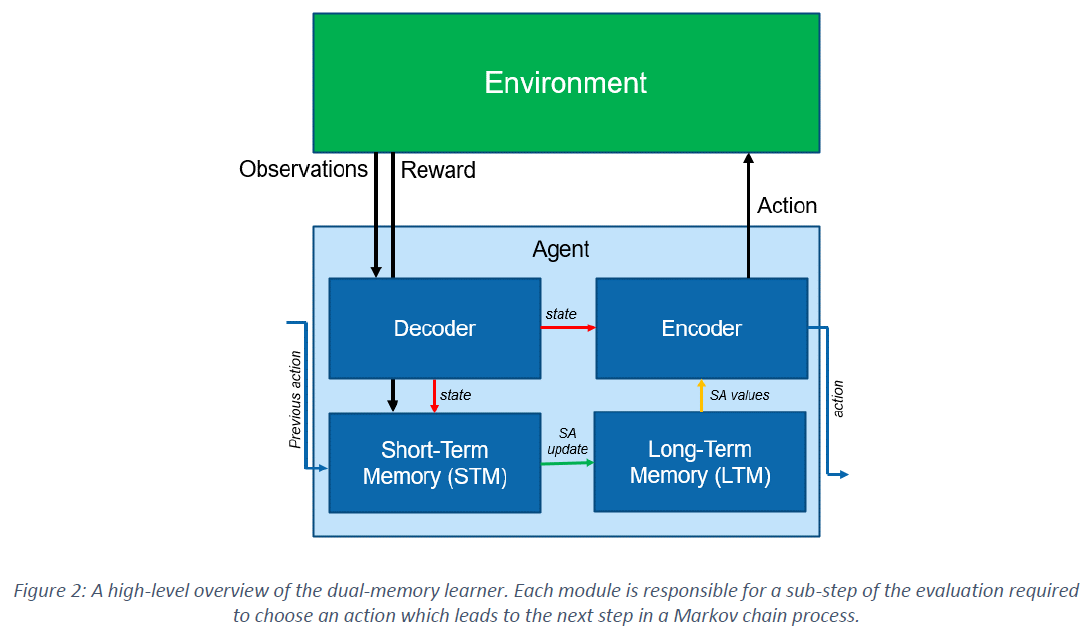
对马尔可夫决策过程建模的RL智能体中的基本时期或"步骤"需要几个子步骤:识别智能体的当前状态,使用此信息来决定给定当前策略的适当动作,将此动作以有意义的方式返回到环境中,并可能应用奖励信号来更新内部价值估计和策略。我们定义了特定的模块和/或交互来满足这些需求中的每一个,形成DML的核心结构并允许它通过并行和本地操作来实现。我们定义的四个模块是解码器、短期记忆(STM)、长期记忆(LTM)和编码器(图2)。
Architectural Implementation
神经形态系统的关键方面之一是如何表示信息的问题,特别是当所有信息必须以"脉冲"编码时,"脉冲"是负责人脑中神经元之间几乎所有信息传输的二值全有或全无信号7。在这个初始实现中,使用了所有信息都进行发放率编码的约定。虽然与其他编码策略相比,发放率编码的成本可能很高,并且可能不会在大脑的许多区域使用8,9,但我们在这里使用它是因为它易于解释且功能强大。使用此假设并遵循先前布局的要求,我们独立演示了构成DML的每个模块的操作。除了最终的编码器模块外,所有模块都完全使用脉冲逻辑实现,这些逻辑在Loihi架构的大规模并行"神经核"中运行。
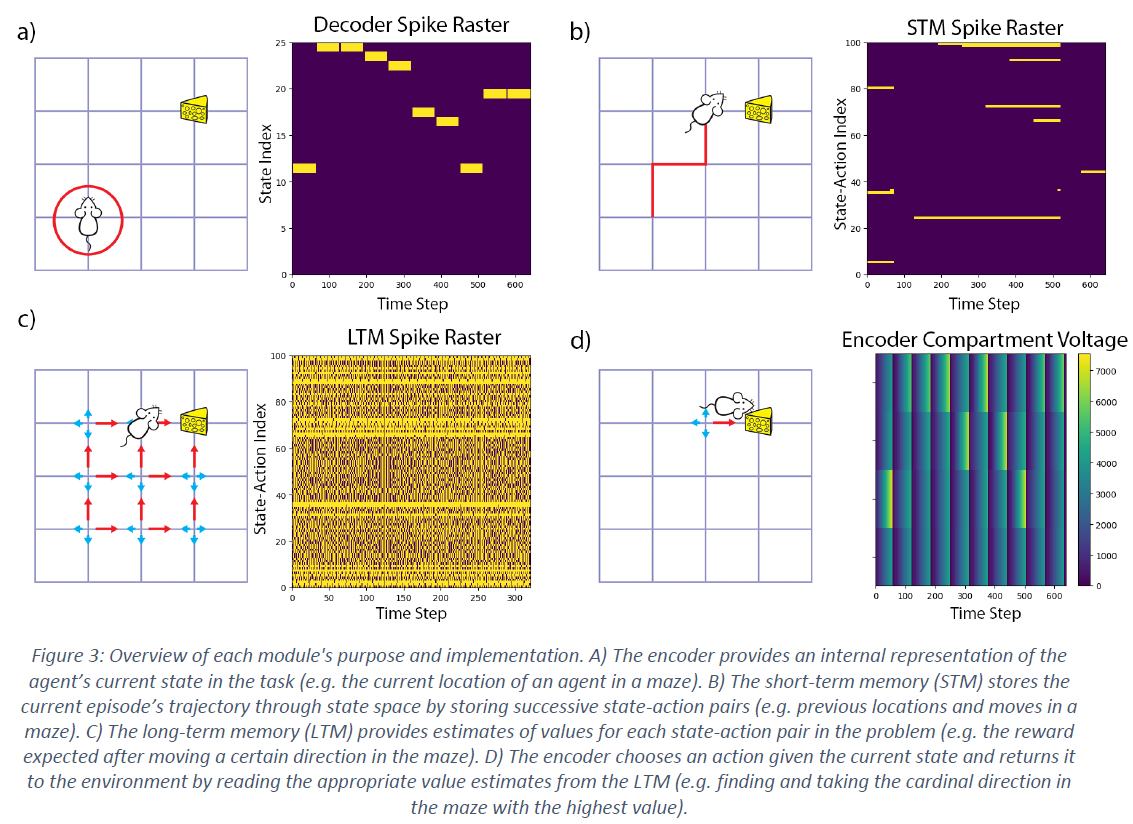
Decoder
在最简单的情况下,解码器提供一个简单的整数值,它对应于问题中的唯一状态。来自环境的指示状态变化的信号被假定为及时稀疏的,解码器必须获取这些稀疏信号并将它们扩展为恒定的内部表征(图3a)。这是通过创建一系列双稳态神经元来完成的,这些神经元提供当前状态的one-hot表征(例如,如果迷宫中的智能体处于第四个可能的位置,则其在编码器中的第四个神经元将处于活动状态)。
Short-Term Memory (STM)
当与在当前状态之后采取的类似的one-hot表征相结合时,可以通过获取解码器状态表征的外积和编码器的后续动作来构建智能体通过每一个回合的轨迹(图3b)。同样,使用双稳态神经元,一旦遍历状态-动作对就会激活,一旦回合完成就会重置(例如,在迷宫中,如果智能体进入某个位置并进行特定运动,则STM神经元变得活跃)。在此处提供的所有示例中,回合的结束由来自环境的信号指示,可选地伴随着正或负奖励。
Long-Term Memory (LTM)
在LTM中,二值轨迹和奖励信号必须转换为分级价值表征。目前这是通过为每个状态-动作对维护一个价值估计的表格数组来完成的。这避免了需要一个函数近似器,其训练和实现本身目前是神经形态计算中的一个密集研究领域10,11。
为了表示单个价值估计,使用了几个神经元的电路。这个"价值电路"(VC)的动态配置方式允许输出隔间收敛到一个发放率,该发放率对应于电路从所有强化信号中接收到的奖励信号的比例。如果没有新的强化信号,VC会保持其当前的发放率。材料中提供了VC的确切细节及其收敛性的证明。
一组VC表示遵循当前策略的所有状态-动作对的期望回报(图3c)。智能体策略是在给定当前状态的情况下,由对动作价值估计的简单贪婪或ε-贪婪选择形成的。在一个回合结束时,这些价值期望通过使用存储在STM中的轨迹将奖励信号路由到其相应的VC来更新。然后,这些信号可以根据需要逐步调整每个VC,创建新的价值估计并允许推导出新的策略。
Encoder
为了选择适合当前状态的动作,编码器使用来自解码器的信息来过滤LTM的输出(图3d)。仅读取与当前状态下可能的动作相对应的LTM的输出,解码器选择具有最高价值的动作(贪婪),或者可选地,可以选择具有设定概率的随机动作(ε-贪婪)。目前,所需的argmax和随机选择操作是通过在Loihi芯片上共同集成的x86处理器完成的,尽管它们可以通过赢家通吃(WTA)或带噪WTA电路来代替,以实现DML12的纯脉冲实现。
Modular Integration
在演示了每个DML模块的单独操作之后,剩下的挑战是将这些模块集成到一个协同工作以实现完整DML的系统中。此外,这应该通过以高抽象级别描述模块来实现,允许解决方案根据手头的问题自动扩展,并防止它成为可能希望将程序部署到新场景中的最终用户的负担。这在神经形态系统中仍然是一个挑战,其中"完整性"是有争议的,并且将任意程序编译到终端平台可能并不总是可行的。
我们通过根据计算图描述神经元电路和电路层次结构,在程序集成中保持高度抽象。这些图的元素是具有任意维度的节点,与刻板的连接模式和预定义的兴奋性特征相关联。然后,这些电路可以很容易地扩展到手头的给定问题,并编译成在Loihi等平台上定义可执行程序所需的单独隔间和突触连接。方法中提供了表示这些图的框图。
这种高级组织允许RC-DML解决各种不同的问题,同时需要最少的代码更新并保持神经形态硬件的可执行性。允许智能体解决不同问题所需的唯一代码更改是更新环境模拟和控制智能体、环境和主机之间的通信的例程。Loihi上RC-DML的完整源代码是公开可用的(参见方法)。
Problem Solving
Multi-Arm Bandit
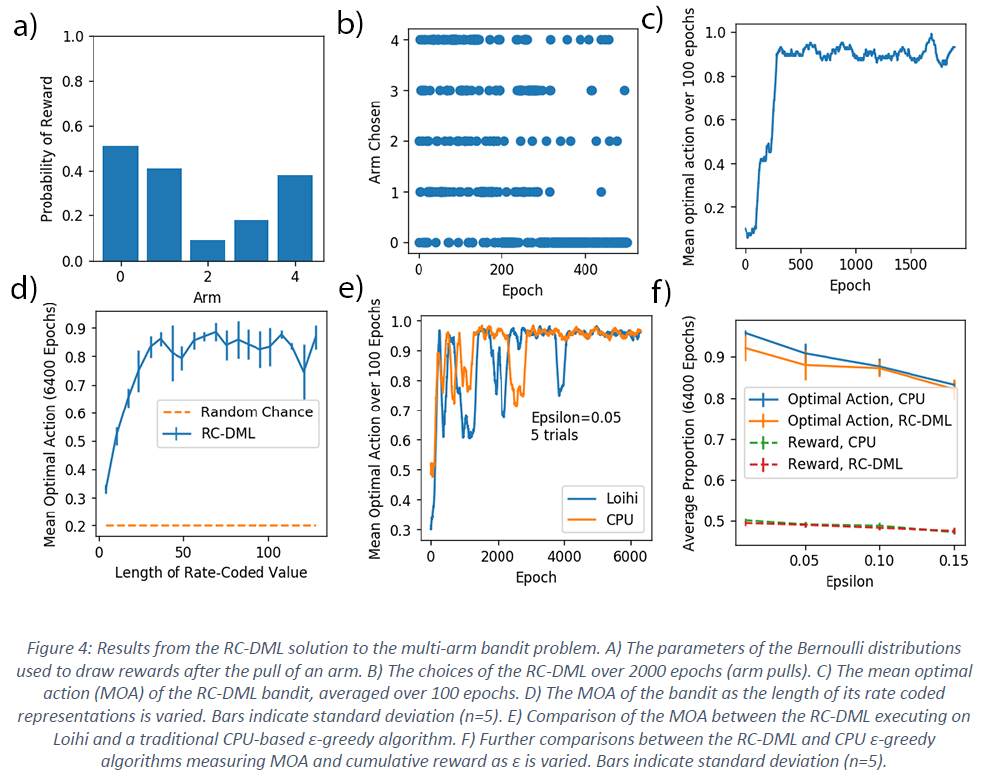
作为其功能的基本演示,我们首先将发放率编码DML (RC-DML)应用于多臂读博机(MAB)问题。虽然它没有将"状态"的概念纳入问题,但MAB本身就是一个复杂的问题,它解决了RL的许多基本方面6。在MAB中,向智能体呈现了一系列"臂",每个臂都有一个隐藏的真实参数,该参数控制当臂被"拉动13"时获得奖励的概率。在此,基本的学习问题是使用与赌博机的最少交互次数来找到哪个臂给出最高奖励,以最大化累积奖励。
我们使用ε-贪婪算法演示RC-DML来解决MAB。由于问题是无状态的,它只是向系统指示它在每次操作后保持在相同(单一)状态。然后使用在该状态下为每个动作学习到的价值估计来估计每个臂的奖励(图4a)。使用ε-贪婪策略,RC-DML被迫探索每个臂并最终收敛于选择正确的臂(图4b, c)。
只要用于对价值进行发放率编码的周期长度在大约40步以上,神经形态RC-DML就展示了MAB的学习性能,这与在CPU上运行的传统非脉冲ε-贪婪算法相当(图4d, e)。基于CPU的算法在各种 ε 值的前6400个学习epoch中,在最优动作的比例和平均奖励方面保持较小的性能领先(图4f)。这是由于RC-DML中的价值表征的准确性有限,因为它使用了发放率编码,这后来限制了它在Blackjack中的性能。在使用64位浮点值表示的基于CPU的算法中不存在这样的障碍。
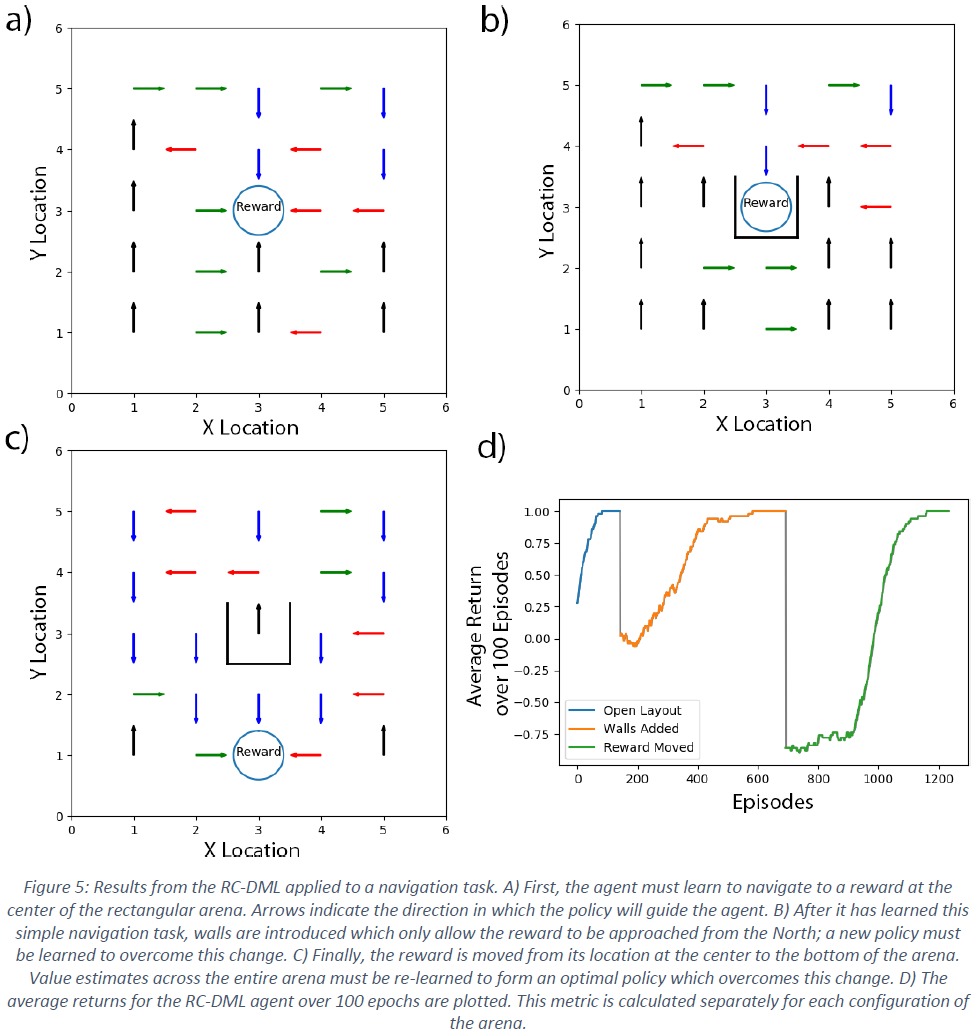
Dynamic Maze
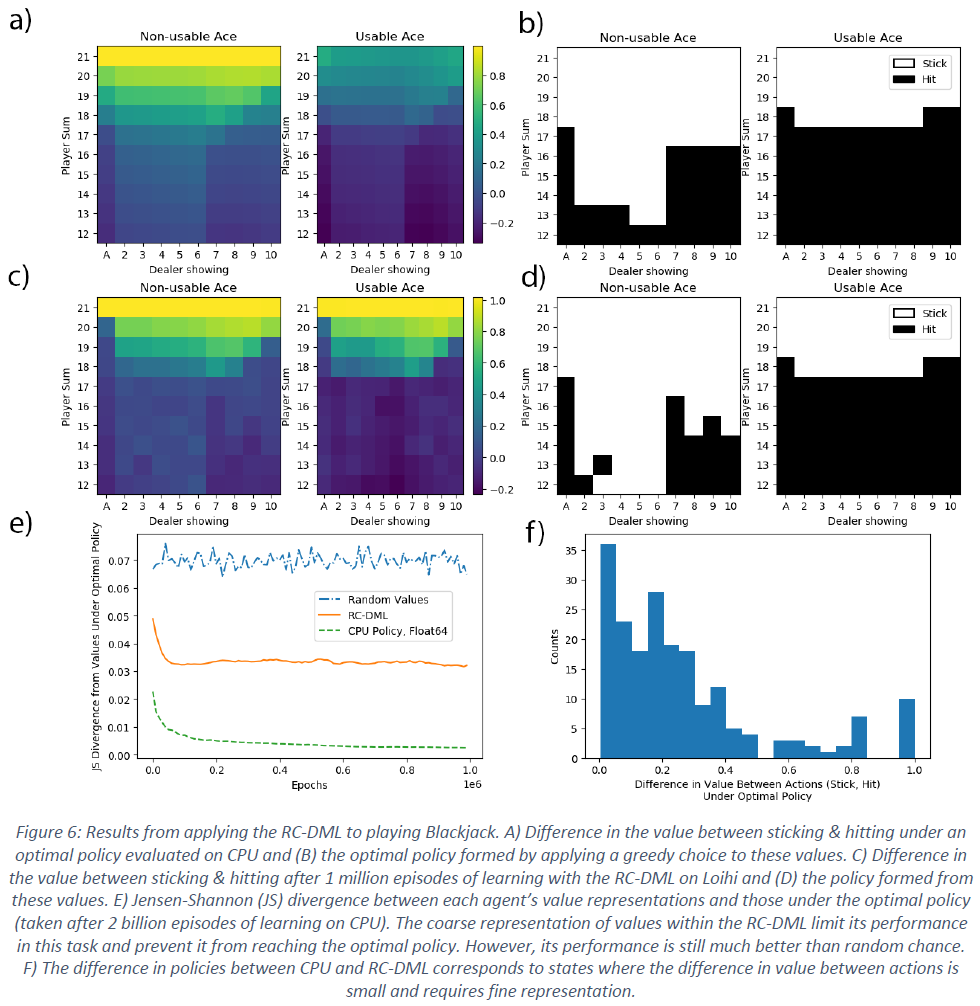
Blackjack
Discussion:
我们提出了一种使用脉冲神经形态硬件解决强化学习(RL)问题的新框架。该方法实现了互补学习系统理论的关键要素和原则,该理论旨在解释生物大脑中的陈述性记忆学习。该方法使用英特尔的Loihi神经拟态处理器成功应用于三个经典的强化学习问题——多臂赌博机、动态迷宫和二十一点。我们发现,除非成功学习策略需要高精度,否则基于Loihi的实现与基于CPU的算法具有相似的性能。虽然运行该算法的Loihi芯片的有功功耗比传统CPU低得多,但对于更复杂的问题,例如二十一点,CPU上等效的蒙特卡罗程序执行速度更快,这使它在总能耗上占优。最后一个限制被发现是信息处理的发放率编码实现的结果,我们在这里使用它是因为它易于解释和功能性。初步分析表明,使用不同的信息表示可以成功地使所提出的RL实现在学习能力和能源效率方面与传统CPU解决方案相竞争。
Reinforcement learning in machine learning solutions
Learning in biological brain and complimentary learning systems theory
Power Consumption
Current Issues and Future Directions
Conclusion
强化学习提供了独特的学习能力,其发展在过去十年中取得了许多具有里程碑意义的成功。因此,神经形态系统必须证明它们能够使用RL技术,并且可以展示这些技术相对于传统硬件的优势。在这项工作中,我们展示了神经形态硬件上的RL灵活架构,该架构在英特尔Loihi平台上实现并完全执行。这种发放率编码的双记忆学习器(RC-DML)能够成功地学习策略以最大化从多臂赌博机那里获得的奖励,在不断变化的迷宫中导航,并玩纸牌游戏二十一点。但是,虽然这表明神经形态架构目前能够使用RL技术,但当前实现的价值表征的发放率编码和表格方法使其无法与传统技术竞争。然而,我们相信神经形态系统研究的进一步进展(例如通过向量符号架构和基于脉冲的深度学习的价值表征)可以在未来的工作中克服这一障碍,以创建一个可以与传统方法的性能相匹配并具有更高能源效率的系统。
Materials & Methods
所有脉冲网络均使用Python 3.5.2、Intel NxSDK v0.9.5-v0.9.9开发,并通过英特尔神经拟态研究社区(INRC)云在英特尔Loihi处理器上执行。RC-DML和每个任务的代码可在线获取(https://github.com/wilkieolin/loihi_rl)。
Value Circuit
Block Diagrams
Power Estimates


 浙公网安备 33010602011771号
浙公网安备 33010602011771号