
Navigating Mobile Robots to Target in Near Shortest Time using Reinforcement Learning with Spiking Neural Networks
郑重声明:原文参见标题,如有侵权,请联系作者,将会撤销发布!

IJCNN, pp.2243-2250, (2017)
Abstract
移动机器人在未知环境中的自主导航是移动机器人技术的一个重要课题。本文讨论了一种在未知环境中导航到已知目标位置的新策略,结合使用"go-to-goal"方法、强化学习与生物学合理的脉冲神经网络。虽然"go-to-goal"方法本身可能会为大多数环境提供解决方案,但这项工作中增加的神经强化学习产生了一种策略,可以在尽可能短的时间内将机器人从起始位置带到目标位置。为了实现这一目标,我们提出了一种基于脉冲神经网络的强化学习方法。本文所提出的使用资格迹的生物动机延迟奖励机制产生的贪婪方法,使得机器人可以在接近尽可能短的时间内到达目标。

I. INTRODUCTION
由于自动驾驶汽车、外星探索、救援任务和类似领域的出现,关于无人驾驶汽车在已知和未知环境中自主导航的研究正在迅速发展。在本文中,考虑了移动机器人在包含障碍物的环境中朝向给定目标位置的自主导航问题。该问题的一个示例如图1所示。
在图1中,移动机器人是圆形物体"Robot"。从机器人中心发出的线条是超声波传感器光束,用于检测任何障碍物。超声波传感器的检测范围有限。矩形物体是可以被超声波传感器感应到的壁状障碍物。标记为"Start"的点是机器人的初始位置。图中标有"Goal"的方形物体是机器人必须导航到的全局目标。假设机器人有办法检测目标相对于自身的位置。机器人不知道障碍物的形状和位置,这使得这成为一个具有挑战性的问题。
A. Previous Work
已经使用各种方法提出了针对类似问题的现有解决方案。[1]提出了人工势场方法,它本质上将障碍物视为排斥机器人,而目标则吸引机器人。[2]和[3]为机器人提供了避免机器人卡在[1]中的局部最小值问题的策略。这些方法假设机器人了解障碍物的形状和位置。我们的问题版本假设没有此类信息。
强化学习也以多种方式应用于移动机器人导航问题。例如在[7]中,Q学习[8]是一种形式的时序差分强化学习算法,用于在没有任何目标的未知环境中学习无碰撞路径。其他工作包括[9]、[10],它们使用某种形式的Q学习来学习避开障碍物。在所有这些工作中,目的是通过避免碰撞来学习穿越障碍物。图片中没有目标。
B. Overview of the Proposed Solution
我们首先讨论[11]中提出的导航策略,然后讨论改进该策略的强化学习算法。
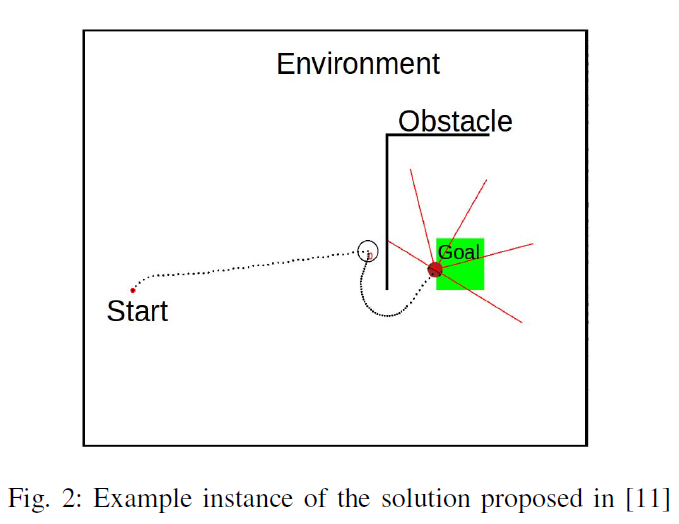
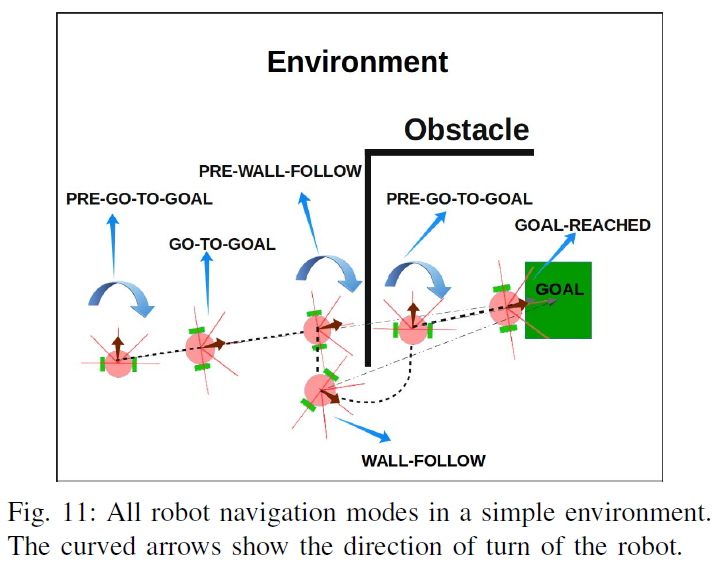
在"go-to-goal"方法[11]中,移动机器人在没有障碍物的情况下朝着目标导航。当遇到障碍物时,它会原地转动(向左或向右)并使用墙壁跟随控制器跟随障碍物。机器人在满足后续部分中讨论的特定条件后离开墙壁跟随模式。然后朝着目标前进。图2说明了这个简单环境的解决方案。
在这种策略下,要在最短的时间内导航到目标,机器人必须在遇到障碍物时做出智能的转弯决策。例如,在图2中,如果机器人在圆圈位置左转,则需要更长的时间才能到达目标。
为了促进这个决策过程,我们提出了一种生物激励的强化学习策略,使用脉冲神经网络来做出转弯决策。所提出的强化学习算法的状态集是机器人做出转弯决定的位置。机器人在每个状态下的动作是:1)向左转并跟随其右侧的墙,以及 2)向右转并跟随其左侧的墙。我们的算法利用类似于Q学习中的Q值的状态-动作价值来选择每个状态下的动作。
学习算法是使用脉冲神经网络实现的[12]。机器人的状态用输入层表示,使用[18]中使用的状态编码方法,并在第III节中详细讨论。输出层有两个神经元用于两个机器人转动动作。每个状态下输出神经元的发放率被视为状态-动作价值。
在每个状态下,机器人通过模拟我们的神经网络来选择一个动作。网络的突触连接为每个状态-动作对生成衰减的资格迹。机器人在达到目标时获得奖励,该奖励与资格迹相乘并添加到突触权重中,最终确保所有动作的高状态-动作价值,这些动作引导机器人在尽可能短的时间内到达目标。
我们的神经学习机制的细节在第二节和第三节中讨论。
II. BACKGROUND
在强化学习中,智能体通过发现最大化其收到的总期望奖励的动作来学习。在强化学习算法Q学习中,智能体的状态-动作价值函数,即Q值在每次状态转换后更新。因此,在达到某个状态时,只会更新前一个状态的Q值。然而,由于它发生在包括导航问题在内的许多问题中,智能体经常采取奖励延迟的动作。这个问题被称为"信度分配问题"或"延迟奖励问题"[4]。
为了解决"延迟奖励问题",Izhikevich [13]提出了一种称为带资格迹的多巴胺调节的Hebbian脉冲时序依赖可塑性(STDP)的机制。这将在以下小节中简要说明。

A. Hebbian STDP



B. Dopamine Modulated STDP
脉冲神经网络中的强化学习被认为是通过一种称为多巴胺调节STDP[13]的机制发生的。在多巴胺神经调节剂的存在下,突触权重的变化会增强,这与强化学习中的奖励有关。我们将奖励视为分别对奖励和惩罚取正值和负值,如[15]中所做的那样。突触强度由STDP变化定义的量改变,随着资格迹与标量奖励相乘(调节)而衰减[13]。图4A显示了突触前和突触后脉冲对的这个想法。我们可以看到图4B中的资格迹。在pre-before-post脉冲模式上更新,并随着时间的推移而衰减。当应用奖励时,它会乘以资格迹并更新权重。这显示在下面的等式中:
![]()
在每个时间步骤,STDP权重变化都会衰减。
![]()
其中,ΔWstdp在我们的网络1000 ms的每次模拟后使用(1)和(2)计算,β是资格迹衰减参数,奖励是应用的数字奖励。
我们在我们的脉冲神经网络中使用这种多巴胺调节的STDP来做出移动机器人转弯决策,之前在第1.B节中讨论过。
III. REINFORCEMENT LEARNING USING SPIKING NEURAL NETWORK
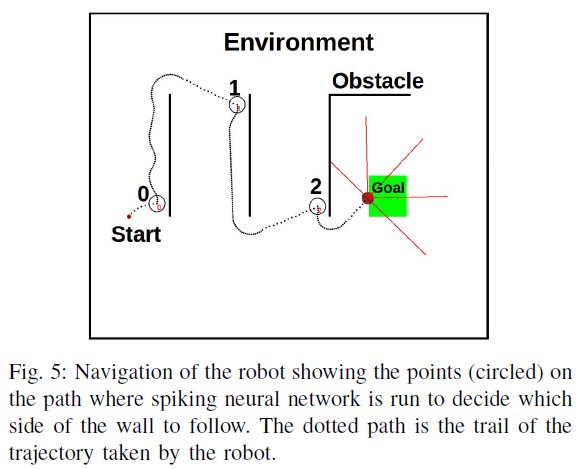
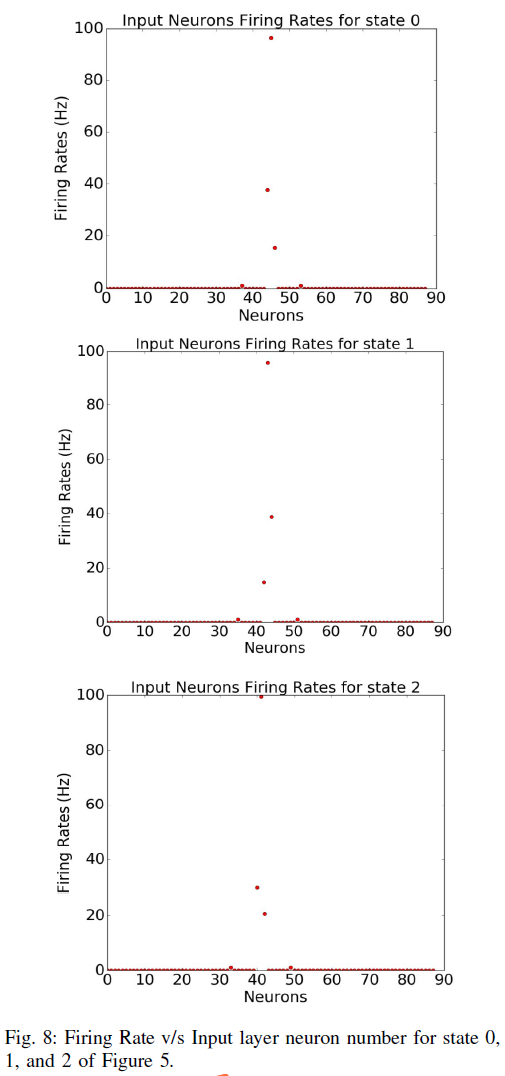
这项工作中提出的导航问题的解决方案涉及一个学习部分,其中机器人做出以下决定:当直接面对障碍物时,1)通过右转跟随左侧有障碍物的障碍物或 2)通过左转跟随右侧有障碍物的障碍物。该决策场景如图5所示。机器人在标有圆圈的区域(图5中标记为"0"、"1"和"2")处做出跟随墙的决策。
设计的脉冲神经网络如图6所示。它是一个两层网络:一个输入层有88个兴奋性泊松脉冲神经元,一个输出层有2个兴奋性脉冲神经元。输入层以全连接方式连接到输出层。输入神经元编号为0到87,输出神经元标记为LEFT和RIGHT。强化学习问题的状态由输入层表示。这是通过以这样一种方式计算输入发放率来实现的,即对于每个状态,不同的输入神经元群体都会发放。这种状态的编码已经在[18]中完成。对于每个输入神经元 i,使用频率fi来生成泊松脉冲序列。fi计算如下:

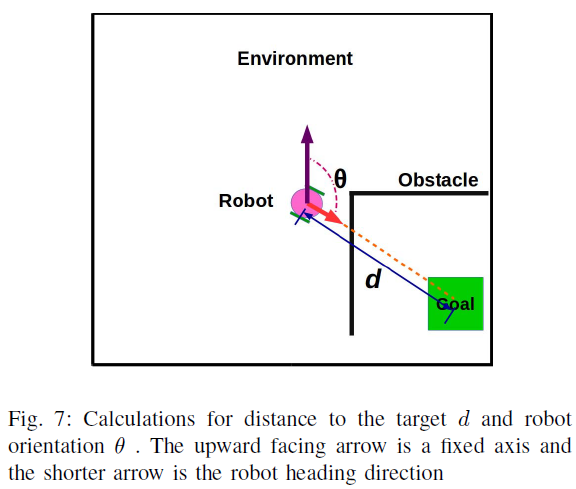
其中θ是机器人航向方向相对于固定轴的方向,以度为单位,d是机器人中心到目标位置(方形目标的中心)的距离,以像素为单位。这两个参数的计算如图7所示。对于θ,以模拟环境平面中指向上方的固定轴为参考,沿顺时针方向测量。θ可以从0°到360°取值。
参数di和θi使得(di, θi) ∈ D × Θ,其中:
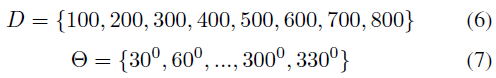
换句话说,D是机器人智能体到目标的离散距离集合,Θ是机器人航向方向的离散方向集合。因此,可能对(di, θi)的总数为n(D)n(θ) = (8)(11) = 88,这决定了图6中网络输入层的神经元数量。这里n(S)表示集合S的基数。σ1和σ2是确定曲线fi v/s (d, θ)的扩展的设计参数。
因此,强化学习问题中的每个状态都由有序对(d, θ)表示,并且计算出的输入发放率fi使得不同的输入神经元组被不同的有序对(d, θ)激发。例如,在图5中,标记为"0"、"1"和"2"的圆圈是测量d和θ并为88个输入神经元中的每一个计算fi的位置。 对于点"0"、"1"和"2",激发的神经元数量是不同的。为了可视化这种发放行为,图8中显示了图5中每个状态"0"、"1"和"2"的发放率与输入神经元数量的关系图。
当神经网络运行时,其输出层会产生两个输出发放率:fleft和fright,对应于图6中标记为"LEFT"和"RIGHT"的输出神经元。在做墙壁跟随决策时,如果fleft大于fright,则机器人决定通过右转来跟随其左侧的障碍物。否则,机器人决定通过左转来跟随其右侧的障碍物。

IV. THE COMPLETE PROPOSED SOLUTION
在本节中,我们将结合"go-to-goal"方法[11]和脉冲神经网络实现的强化学习,使沿墙绕行决策。在[19]中提出的工作中也使用了类似"go-to-goal"的解决方案。
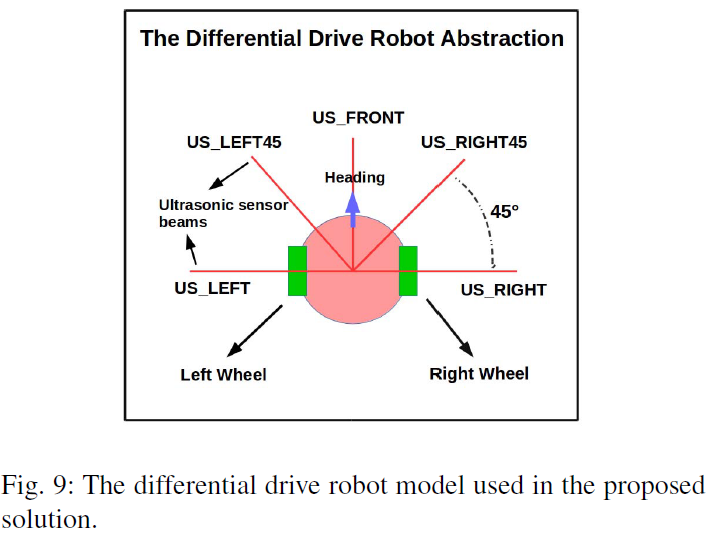
图9显示了用于解决方案的机器人抽象。它是一个简单的差动驱动机器人,装有5个超声波传感器,它们之间的夹角为45°。它们被指定为US_LEFT、US_LEFT45、US_FRONT、US_RIGHT45、US_RIGHT,如图9所示。还假定机器人具有确定其相对于固定轴的方向的传感器,并假定它可以感应它相对于目标的方向和距离。
所提出的导航算法被设计为具有5个状态的状态机,我们将其称为"导航模式",即PRE-GO-TO-GOAL、GO-TO-GOAL、PRE-WALL-FOLLOW、WALL-FOLLOW和TARGET-REACHED。这些状态下的机器人行为将在以下详细算法中讨论。
A. Detailed Algorithm



![]()



V. SIMULATION SETUP, RESULTS AND DISCUSSION
模拟环境使用C++编写,使用2D游戏库Allegro http://liballeg.org。用于脉冲神经网络模拟的模拟器是CARLsim [16],网址为http://www.socsci.uci.edu/jkrichma/CARLsim。CARLsim使用神经元的Izhikevich模型[17],该模型具有合理的生物学现实性,但计算效率高。
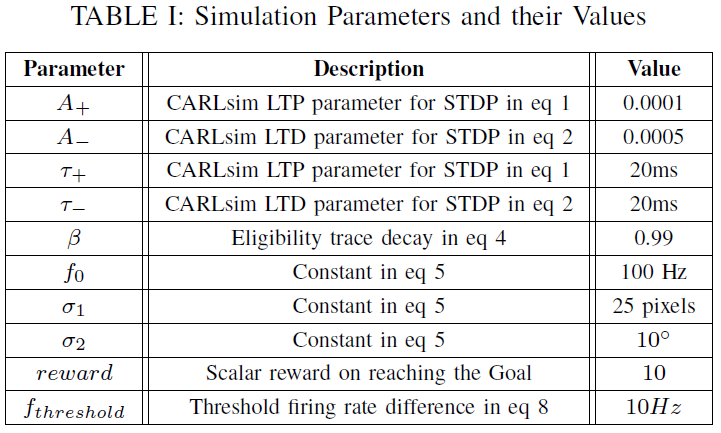
导航环境是一个二维矩形空间,尺寸为1000像素 x 800像素。所考虑的障碍物是墙状的、矩形的(机器人不知道)。无障碍空间以白色显示,障碍物以黑色显示。目标位置标记为"GOAL"。机器人呈圆形,带有5个超声波传感器,如图9所示。5个超声波传感器中的每一个都有40个像素的检测距离范围。即检测到超声波传感器40像素内的任何物体。用于模拟脉冲神经网络学习算法的参数值如表 I 所示。

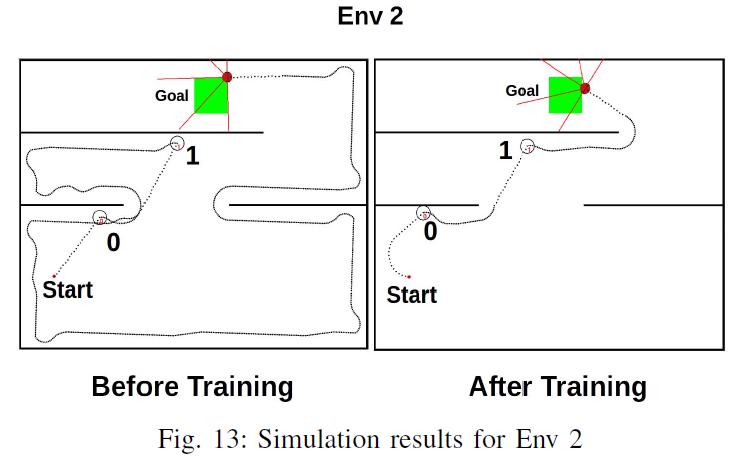
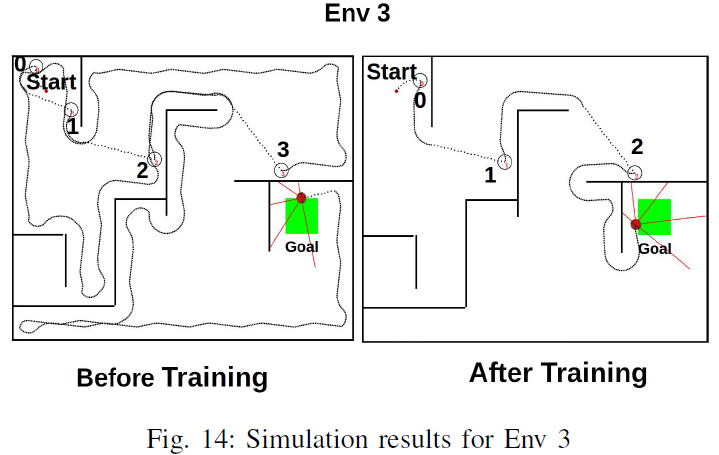
模拟使用3个不同的环境执行:Env 1、Env 2和Env 3。训练前后的模拟快照如图12、13和14所示。
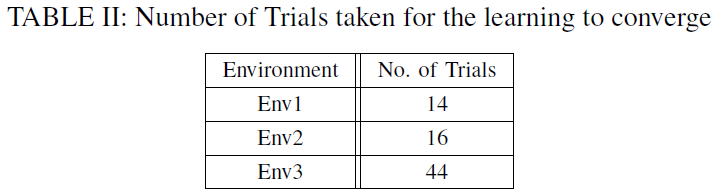
表 II 中显示了这些环境中每一个的收敛试验次数。当等式(8)对机器人遇到的所有PRE-WALLFOLLOW状态成立时,训练过程被设定为终止。
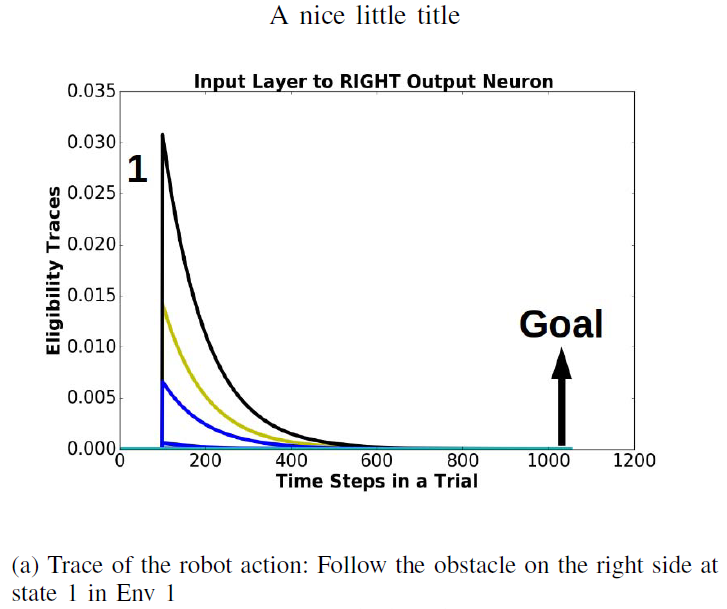
为了分析算法的工作,请考虑在图12"训练前"和"训练后"图中标记为"1"的状态下采取的动作的资格迹。这些迹绘制在图15中。
图15(a)显示了在Env 1中的状态1处采取的机器人动作"跟随右侧障碍物"的轨迹。标签"1"表示机器人处于状态1的时间步长,"目标"表示机器人到达目标的时间步长。此时此动作的资格迹几乎为零。相比之下,图15(b)中相同状态1的机器人动作"跟随左侧的障碍物"有一条轨迹,该轨迹对于在状态1产生的所有轨迹都具有正值。因此在图15(b)输入层和左输出神经元之间的突触比图15(a)场景中输入层和右输出神经元之间的突触更强。这导致在随后的网络模拟中,左输出神经元的输出发放率高于右输出神经元。因此,状态1下的状态-动作价值对于"跟随左侧的障碍物"动作比"跟随右侧的障碍物"动作要高。这主要是因为当机器人做出导致相对较短路径的转弯决策时,与机器人做出导致更长时间路径的转弯决策时相比,资格迹衰减的量更小。因此,机器人最终会在近乎最短的时间内学习导致其到达目标的动作。

VI. CONCLUSION
可以使用配备资格迹机制的基于脉冲神经网络的强化学习解决方案来增强导航问题的目标方法。所提出的解决方案被证明为机器人提供了一种算法,可以在尽可能短的时间内到达其目的地。
如表II所示,实现解决方案收敛所需的试验次数取决于环境的复杂性。
所提出的解决方案的局限性是:
1)不考虑复杂的障碍物形状,
2)假设环境以墙壁为界,
3)不考虑机器人可能卡住的危险区域,
4)所提出的方法没有给出绝对最短的时间路径,因此终止条件(8)不能保证。
我们打算在未来的工作中解决这些限制。目前的工作可以看作是探索使用资格迹机制来解决导航问题。


 浙公网安备 33010602011771号
浙公网安备 33010602011771号