Reinforcement Learning Through Modulation of Spike-Timing-Dependent Synaptic Plasticity
郑重声明:原文参见标题,如有侵权,请联系作者,将会撤销发布!

Neural Computation, no. 6 (2007): 1468-1502
Abstract
突触效应的持续改变(作为突触前和突触后相对时间的函数关系)是一种被称为脉冲时序依赖可塑性(STDP)的现象。在此,我们显示了通过全局奖励信号对STDP的调节会导致强化学习。我们首先通过将强化学习算法应用于脉冲神经元的随机脉冲响应模型,得出涉及奖励调节的脉冲时序依赖突触和内在可塑性的分析性学习规则。这些规则具有大脑实验发现的可塑性机制共有的几个特征。然后,我们在IF神经元网络的仿真中证明了两种简单的学习规则的有效性,这些规则涉及调节STDP。一个规则是标准STDP模型的直接扩展(调节STDP),另一条规则涉及存储在每个突触中的资格迹,该迹保留对最近的突触前和突触后脉冲对之间关系的递减记忆(资格迹调节的STDP)。即使奖励信号被延迟,后一个规则也允许学习。所提出的规则能够解决频率编码和时序编码输入的异或问题,并能够学习目标输出发放率模式。这些学习规则是生物学合理的,可用于训练通用人工脉冲神经网络,而与所使用的神经模型无关,并提出对动物进行奖励调节STDP的实验研究。
1 Introduction
在生物神经系统中已通过实验观察到突触变化对突触前和突触后动作电位的相对时间的依赖性(Markram, Lübke, Frotscher, & Sakmann, 1997; Bi & Poo, 1998; Dan & Poo, 2004)。脉冲时序依赖可塑性(STDP)的一个典型示例是当突触后脉冲在几十毫秒的时间窗口内跟随突触前脉冲时突触会增强,而当脉冲次序反转时突触会减弱。这种类型的STDP有时被称为赫布学习,因为它与Hebb的原始假设相一致,后者在突触前神经元引起突触后神经元发放时预测了突触的增强。它也是反对称的,因为突触变化的符号随相对脉冲时间的符号而变化。实验还发现了反赫布STDP的突触(与赫布STDP相比,变化的符号是相反的)以及对称STDP的突触(Dan & Poo, 1992; Bell, Han, Sugawara, & Grant, 1997; Egger, Feldmeyer, & Sakmann, 1999; Roberts & Bell, 2002)。
理论研究主要集中在赫布STDP的计算特性上,并显示了其在神经稳态、无监督学习和监督学习中的功能。这种机制可以调节突触后发放的频率和可变性,并可能引起传入突触之间的竞争(Kempter, Gerstner, & van Hemmen, 1999, 2001; Song, Miller, & Abbott, 2000)。 赫布STDP也可能导致无监督学习与序列预测(Roberts, 1999; Rao & Sejnowski, 2001)。理论上,通过优化突触前输入与突触后神经元活动之间的互信息,可以得出类似于赫布STDP的可塑性规则(Toyoizumi, Pfister, Aihara, & Gerstner, 2005; Bell & Parrara, 2005; Chechik, 2003),以最小化突触后神经元对给定输入的可变性(Bohte & Mozer, 2005),优化了在一个或几个所需发放时间的突触后发放的可能性(Pfister, Toyoizumi, Barber, & Gerstner, 2006)或自动修复分类器网络(Hopfield & Brody, 2004)。这还显示,通过将突触后神经元截断到目标信号,赫布STDP可以在一定条件下导致学习特定的脉冲模式(Legenstein, Naeger, & Maass, 2005)。乍一看,反赫布STDP并不像赫布机制那么有趣,因为它本身会导致突触的整体抑制,从而达到零效能(Abbott & Gerstner, 2005)。
赫布STDP对因果关系特别敏感:如果突触前神经元有助于突触后神经元的发放,则可塑性机制将增强突触,因此突触前神经元将更有效地引起突触后神经元发放。该机制可以决定将稳定输出与特定输入相关联的网络。但是让我们想象一下,只有在导致良好结果时(例如,如果由神经网络控制的智能体获得正奖励),因果关系才会得到加强,而导致失败的因果关系则会减弱,以避免错误行为。当奖励为正时,突触应以赫布STDP为特征;而当奖励为负时,突触应以反赫布STDP为特征。在这种情况下,神经网络可以学会将特定输入不是与例如由网络的初始状态决定的任意输出相关联,而是将其与由奖励决定的期望输出相关联。
或者,我们可能会考虑理论结果,即在某些条件下,赫布STDP会最小化突触后神经元对给定突触前输入的可变性(Bohte & Mozer, 2005)。类似于该研究中进行的分析,可以显示反赫布STDP最大化可变性。在网络级别的模拟中也观察到了赫布/反赫布STDP对可变性的这种影响(Daucé, Soula, & Beslon, 2005; Soula, Alwan, & Beslon, 2005)。通过在网络获得正奖励时使用赫布STDP,可以减少输出的可变性,并且网络可以利用导致正奖励的特定配置。当网络收到负奖励时,通过使用反赫布STDP,网络行为的可变性会增加,因此它可以探索各种策略,直到找到导致正奖励的策略。
因此,试图验证使用奖励信号对STDP的调节是否确实可以导致强化学习。对这一机制的探索是这篇文章的主题。
该假说得到了一系列关于非脉冲人工神经网络中强化学习研究的支持,这些学习中的学习机制在定量上与奖励调节STDP相似,通过在奖励与突触前和突触后活动相关时加强突触来实现。这些研究集中于由二值随机元素组成的网络(Barto, 1985; Barto & Anandan, 1985; Barto & Anderson, 1985; Barto & Jordan, 1987; Mazzoni, Andersen, & Jordan, 1991; Pouget, Deffayet, & Sejnowski, 1995; Williams, 1992; Bartlett & Baxter, 1999b, 2000b)或阈值门(Alstrøm & Stassinopoulos, 1995; Stassinopoulos & Bak, 1995, 1996)。这些先前的结果是令人鼓舞的,但它们并未研究生物学合理的奖励调节STDP,并且使用无记忆神经元在离散时间内工作。
另一项研究表明,可以通过将不规则脉冲的波动与发放泊松脉冲序列的神经元组成的网络中的奖励信号相关联来获得强化学习(Xie & Seung, 2004)。所得的学习规则在定量上也类似于奖励调节STDP。但是,研究结果高度依赖于神经元的泊松特性。同样,该学习模型假定神经元通过调节其发放率对输入进行瞬时响应。这部分忽略了神经膜电位的记忆,这是脉冲神经模型的重要特征。
通过增强随机突触传递,还可以在脉冲神经网络中实现强化学习(Seung, 2003)。这种生物学合理的学习机制与我们提出的机制具有几个共同的特征,我们将在后面展示,但这与STDP没有直接关系。另一种现有的用于脉冲神经网络的强化学习算法需要具有固定层数的特定前馈网络结构,并且与STDP也无关(Takita, Osana, & Hagiwara, 2001; Takita & Hagiwara, 2002, 2005)。
之前的其他两项研究似乎将STDP视为一种强化学习机制,但实际上却并非如此。Strósslin和Gerstner (2003)开发了一种基于强化学习的空间学习和导航模型,该模型的灵感来自使用多巴胺调节的STDP来实现资格迹的假设。但是,该模型不使用脉冲神经元,仅代表神经元的连续发放率。当奖励与突触前和突触后活动相关时,通过增强突触,学习机制在定量上类似于调节STDP,就像已经提到的其他一些研究一样。Rao和Sejnowski (2001)表明,与树突反向传播动作电位结合使用的TD规则可重现赫布STDP。TD学习通常与强化学习相关联,用于预测价值函数(Sutton & Barto, 1998)。但总的来说,TD方法用于预测问题,从而实现了一种监督学习的形式(Sutton, 1998)。在Rao和Sejnowski的研究(2001)中,神经元学会了预测其自身的膜电位。因此,由于神经元提供了自己的教学信号,因此可以将其解释为无监督学习的一种形式。无论如何,由于没有外部奖励信号,这项工作不会将STDP作为强化学习机制进行研究。
在先前的初步研究中,我们已经分析得出了包含调节STDP的概率IF神经元网络的学习规则,并在生物学启发的背景下在模拟中测试了它们并对其进行了泛化(Florian, 2005)。振荡神经网络中的赫布和反赫布STDP的研究(Florian & Muresan, 2006)。在此,我们更深入地研究了奖励调节STDP及其对强化学习的效能。我们首先在第2节中通过分析得出派生的学习规则,该规则涉及奖励调节的脉冲时序依赖突触和内在可塑性,方法是将强化学习算法应用于脉冲神经元的随机峰值响应模型,并讨论这些规则与其他强化学习算法之间的关系。然后,在第3节中,我们将介绍基于调节STDP的两个更简单的学习规则,并在第4节中的仿真中对其进行研究,以测试它们解决某些基准问题的效能并探索其性质。结果在第5节中讨论。
在我们的研究过程中,我们发现另外两个小组通过模拟独立地观察了调节STDP的强化学习性质。Soula, Alwan和Beslon (2004, 2005)已经训练了一个由脉冲神经网络控制的机器人,当机器人前进时应用STDP来避免障碍,而当机器人撞到障碍物时则应用反赫布STDP。Farries和Fairhall (2005a, 2005b)研究了两层前馈网络,其中输入单元被视为独立的非均匀泊松过程,输出单元是基于电导率的单室模型。网络通过对性能进行标量评估来调节STDP,从而学会具有特定的输出活动模式。后者的研究仅以抽象形式发表,因此尚不清楚该工作的细节。与这些研究相反,在这篇文章中,我们还提出了将奖励调节STDP引入强化学习机制的分析论据,并且我们还研究了一种调节STDP形式,其中包括即使在延迟奖励下也可以学习的资格迹。
2 Analytical Derivation of a Reinforcement Learning Algorithm for Spiking Neural Networks
为了激励引入奖励调节STDP作为强化学习机制,我们从分析上推导出用于脉冲神经网络的强化学习算法。
2.1 Derivation of the Basic Learning Rule.
该算法是作为OLPOMDP强化学习算法的应用(Baxter, Bartlett, & Weaver, 2001; Baxter, Weaver, & Bartlett, 1999)而衍生的,该算法是GPOMDP算法的在线变体(Bartlett & Baxter, 1999a; Baxter & Bartlett , 2001)。GPOMDP假定智能体与环境的交互是部分可观察的马尔可夫决策过程(POMDP),并且智能体根据概率策略μ选择动作,该概率策略μ依赖于几个真实参数的向量w。智能体收到的外部奖励的长期均值相对于参数w的梯度。已经获得了与OLPOMDP收敛到局部最大值有关的结果(Bartlett & Baxter, 2000a; Marbach & Tsitsiklis, 1999, 2000)。
结果表明,将算法应用于寻求最大化相同奖励信号r(t)的交互智能体系统,等同于将算法独立应用于每个智能体 i (Bartlett & Baxter, 1999b, 2000b)。OLPOMDP提出参数wij(智能体 i 的向量wi的分量)应根据下式进化:
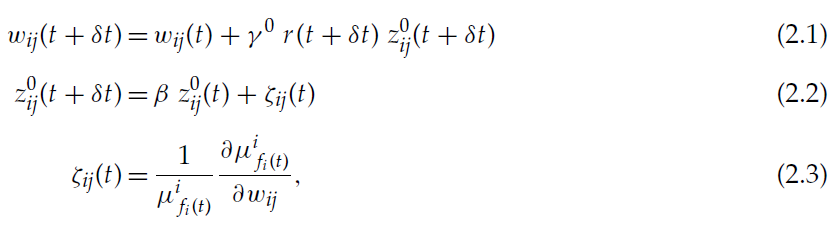
其中δt是一个时间步骤的持续时间(系统在离散时间内进化),学习率γ0是一个小的常数参数,z0是资格迹(Sutton & Barto, 1998),ζ是由上一个时间步骤中的活动导致z0变化的符号,![]() 是策略决定智能体 i 选择动作fi(t)的概率,fi(t)是在时间 t 实际选择的动作。折扣因子β是一个参数,可以取0到1之间的值。
是策略决定智能体 i 选择动作fi(t)的概率,fi(t)是在时间 t 实际选择的动作。折扣因子β是一个参数,可以取0到1之间的值。
为了适应未来的发展,我们对标准的OLPOMDP符号进行了以下更改:

其中τz是z的指数衰减的时间常数。
因此,我们有:
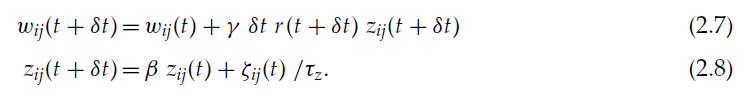
选择参数β和γ0使得δt/(1-β)和δt/γ0与系统的混合时间τm相比更大(Baxter et al., 2001; Baxter & Bartlett, 2001; Bartlett & Baxter, 2000a, 2000c)。用我们的符号表示,对于δt « τz,如果τz比τm大且0<γ<1,则满足这些条件。对于马尔可夫过程,可以严格定义混合时间,可以认为是从发生某个动作到该动作的效果消失的时间。
我们将此算法应用于神经网络的情况。我们认为,在每个时间步骤 t 处,神经元 i 要么以概率pi(t)发放(fi(t) = 1),要么以概率1 - pi(t)不发放(fi(t) = 0)。神经元通过可塑性突触与效能wij(t)连接,其中 i 是突触后神经元的索引。wij的效能可以是正或负(分别对应于兴奋性突触和抑制性突触)。全局奖励信号r(t)被广播到所有突触。
通过将每个神经元 i 作为独立智能体,并将神经元的发放和不发放概率决定相应智能体的策略μi ![]() ,我们得到以下形式的ζij:
,我们得到以下形式的ζij:
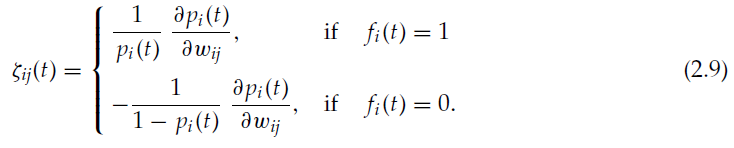
公式2.9与公式2.7和2.8一起建立了可塑性规则,该规则可更新突触,从而优化网络所接收奖励的长期均值。
到目前为止,我们遵循了Bartlett和Baxter (1999b, 2000b)对无记忆二值随机单元网络进行的推导,尽管他们称它们为脉冲神经元。与这些研究不同,我们在此考虑的是脉冲神经元,其中膜电位像真实神经元一样保留过去输入的衰减记忆。特别是,我们考虑了神经元的脉冲响应模型(SRM),该模型可以精确地重现复杂的Hodgkin-Huxley神经模型的动态,同时可以进行分析处理(Gerstner, 2001; Gerstner & Kistler, 2002)。根据SRM,每个神经元的特征在于其膜电位u,其被定义为:
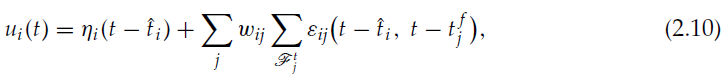
其中![]() 是神经元 i 的最后一个脉冲的时间,ηi是由于该最后一个脉冲引起的不应期反应,
是神经元 i 的最后一个脉冲的时间,ηi是由于该最后一个脉冲引起的不应期反应,![]() 是突触前神经元 j 在 t 之前发出的脉冲时刻,
是突触前神经元 j 在 t 之前发出的脉冲时刻,![]() 是由于在时间
是由于在时间![]() 时来自神经元 j 的输入脉冲而在神经元 i 中诱导的突触后电位。第一个总和遍及所有突触前神经元,最后一个总和遍及 t 之前的神经元 j 的所有脉冲(由集合
时来自神经元 j 的输入脉冲而在神经元 i 中诱导的突触后电位。第一个总和遍及所有突触前神经元,最后一个总和遍及 t 之前的神经元 j 的所有脉冲(由集合![]() 表示)。
表示)。
根据逃逸噪声模型(Gerstner & Kistler, 2002),我们认为神经元具有噪声阈值,并且它是随机发放的。神经元在间隔δt以概率pi(t)=ρi(ui(t)-θi)δt发放,其中ρi是概率密度,也称为发放强度,而θi是神经元的发放阈值。我们注意到:

而且我们有:

从等式2.10我们得到:
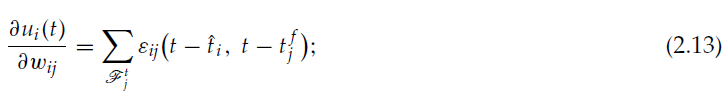
因此,等式2.9可改写为:
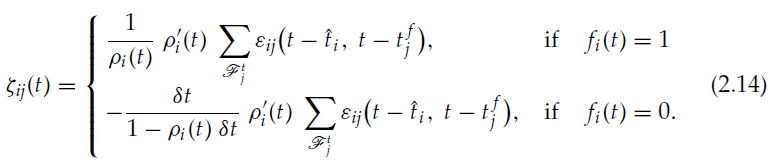
与公式2.7和2.8一起,定义了强化学习的可塑性规则。
我们考虑δt«τz,并将等式2.8重写为:
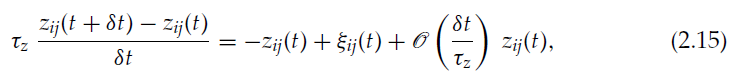
其中我们注意到:
![]()
通过取极限δt→0,并使用公式2.7、2.14、2.15和2.16,我们最终获得了连续时间的强化学习规则:
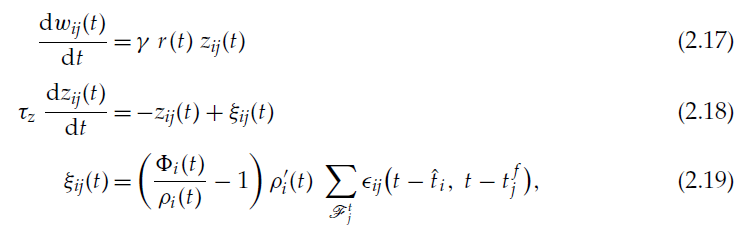
其中![]() 代表作为Dirac函数之和的突触后神经元的脉冲序列。
代表作为Dirac函数之和的突触后神经元的脉冲序列。
我们看到,当在![]() 发出的突触后脉冲跟随在
发出的突触后脉冲跟随在![]() 发出的突触前脉冲时,z会在
发出的突触前脉冲时,z会在![]() 突然增长,其中:
突然增长,其中:
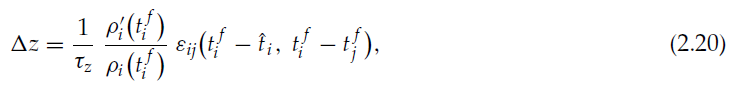
它会随着时间常数τz呈指数衰减。从长远来看,在完全衰减之后,该事件会导致整个突触的改变:
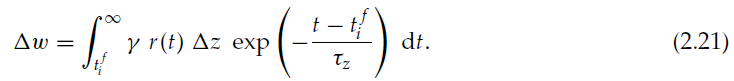
如果r为常数,则为Δw = γ r Δz τz。因此,如果r为正,则该算法表明,突触应该像实验观察到的赫布STDP一样经历一个脉冲时序依赖的增强。因为它是概率密度,所以我们总是有ρ≥0,而由于膜电位越高,发放概率越大,我们就总是有ρ'≥0。
增强的脉冲时序依赖性取决于ε,并且与实验观察到的STDP近似,呈指数关系,因为ε建模突触前脉冲后突触后电位的指数衰减(有关详细信息,请参见Gerstner & Kistler, 2002)。与标准STDP模型相反,增强幅度也由![]() 调节,但与实验观察到的突触修改依赖性不仅取决于相对脉冲时间,而且还取决于脉冲间的间隔(Froemke & Dan, 2002),ρi间接依赖于该间隔。
调节,但与实验观察到的突触修改依赖性不仅取决于相对脉冲时间,而且还取决于脉冲间的间隔(Froemke & Dan, 2002),ρi间接依赖于该间隔。
与在赫布STDP中不同,该算法提出的z降低(以及随后的突触降低,如果r为正)是非关联的,因为每个突触前脉冲会连续降低z。
通常,该算法提出通过强化信号r(t)来调节突触变化。例如,如果强化为负,则由于突触前脉冲之后突触后脉冲导致的z增强会导致突触效能w降低。
在持续负强化的情况下,该算法暗示了关联性脉冲时序依赖抑制和突触效能的非关联性增强。这种可塑性已经在电鱼的神经系统实验中被发现(Han, Grant, & Bell, 2000)。
2.2 A Neural Model for Bidirectional Associative Plasticity for Reinforcement Learning.
由于典型的实验观察到的STDP仅涉及关联可塑性,因此有趣的是,在这种情况下,基于OLPOMDP的强化学习算法将导致关联变化,该关联变化由pre-after-post脉冲对和post-after-pre脉冲对确定。事实证明,当突触前神经元稳态调整其发放阈值以保持突触后神经元的平均活动恒定时,就会发生这种情况。
看到这一点,让我们不仅考虑pi,还考虑突触前神经元 j 的发放概率pj取决于突触效能wij。我们将OLPOMDP强化学习算法应用于由神经元 i 和连接到 i 的所有突触前神经元 j 形成的智能体。与前面的情况一样,该策略由突触效能wij参数化。但是,该策略现在应该确定所有突触前神经元以及突触后神经元的发放概率。由于发放概率仅取决于神经元的电位和阈值,因此每个神经元都独立决定是否发放。因此,具有给定发放模式fi,{fj}的概率会分解为![]() ,其中
,其中![]() 是神经元 k 选择动作fk ∈ {0, 1}的概率。只有
是神经元 k 选择动作fk ∈ {0, 1}的概率。只有![]() 和
和![]() 取决于wij,因此:
取决于wij,因此:
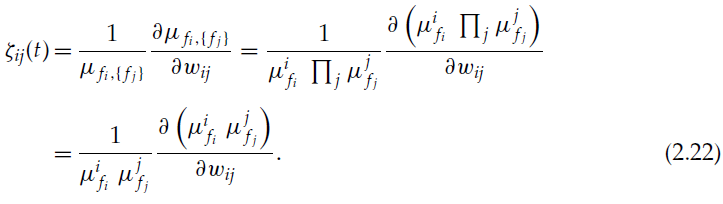
ζij的特定形式取决于神经元 i 和 j 采取动作的各种可能性:
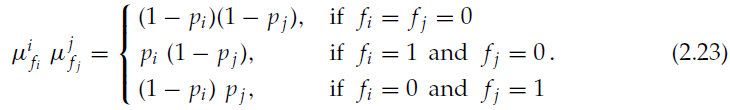
我们不考虑fi = fj = 1的情况,因为在很小的间隔δt内同时出现脉冲的可能性很小。在针对各种情况执行ζij的计算并考虑到δt → 0之后,通过类似于公式2.9和上一节的计算,我们得到:
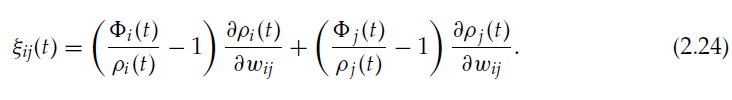
让我们考虑神经元 j 的发放阈值具有以下依赖性:
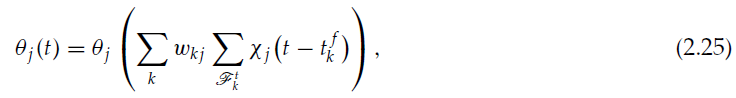
其中θj是任意连续的递增函数,第一个总和在神经元 j 投射到的所有突触后神经元上运行,第二个总和在突触后神经元 k 的 t 之前的所有脉冲上运行。χj是一个衰减核;例如,![]() ,这意味着θj取决于突触后神经元发放率的加权估计值,该估计值是使用具有时间常数
,这意味着θj取决于突触后神经元发放率的加权估计值,该估计值是使用具有时间常数![]() 的指数核计算的。
的指数核计算的。
所提出的突触前发放阈值的依赖性意味着,当突触后神经元的活动较高时,神经元 j 会提高其发放阈值,以减少对它们的发放的贡献并降低其活动。每个神经元 k 的活动都以突触效能wkj来衡量,因为发放阈值的增加和随后神经元 j 活性的降低将对与突触连接较强的突触后神经元产生更大的影响。这在生物学上是合理的,因为有许多神经机制可确保体内稳态(Turrigiano & Nelson, 2004)和内在兴奋性的可塑性(Daoudal & Debanne, 2003; Zhang & Linden, 2003),包括根据突触后活动调节突触前神经元兴奋性的机制(Nick & Ribera, 2000; Ganguly, Kiss, & Poo, 2000; Li, Lu, Wu, Duan, & Poo, 2004)。
神经元 j 的发放强度为![]() 。我们有:
。我们有:
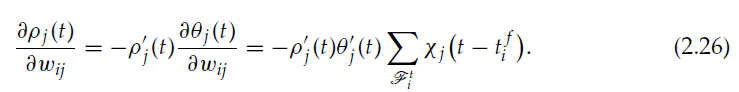
我们终于有:
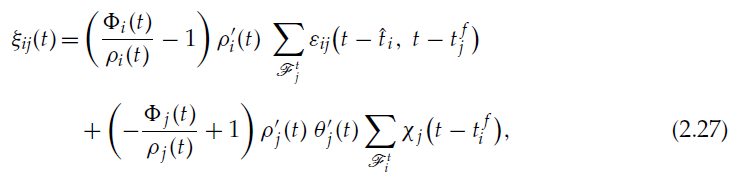
在这种情况下,它们与公式2.17和2.18一起定义了可塑性规则。
我们具有与以前的情况相同的 z 的关联脉冲时序依赖的增强,但是现在,我们还具有 z 的关联脉冲时序依赖的抑制。对应于![]() 的突触后脉冲之后
的突触后脉冲之后![]() 的突触前脉冲的抑制为:
的突触前脉冲的抑制为:
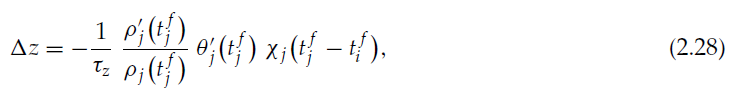
对相对脉冲时间的依赖性由χj给出。z 的变化为负,因为![]() 和
和![]() 为正,它们是递增函数的导数;ρj是正数,因为它是概率密度;而χj定义为正。
为正,它们是递增函数的导数;ρj是正数,因为它是概率密度;而χj定义为正。
因此,我们已经表明,双向关联的脉冲时间依赖的可塑性机制可以通过将强化学习算法应用于脉冲神经模型并通过对平均突触后活动进行稳态控制而得到。如前所述,突触变化通过全局强化信号r(t)进行调节。
与前面的情况一样,我们还具有 z 的非关联变化:每个突触前脉冲连续降低 z,而每个突触后脉冲连续增强 z。但是,根据参数,非关联性的变化可能会比脉冲时序依赖的变化小得多。例如,由突触前脉冲诱发的非关联性抑制的幅度由突触后发放强度的导数![]() (关于膜电位和放电阈值之间的差)来调节。当膜电位高时,这通常具有不可忽略的值(参见Gerstner & Kistler, 2002; Bohte, 2004的ρ函数形式),因此突触后脉冲很可能随之而来。发生这种情况时,z会增强,可以克服抑制的影响。
(关于膜电位和放电阈值之间的差)来调节。当膜电位高时,这通常具有不可忽略的值(参见Gerstner & Kistler, 2002; Bohte, 2004的ρ函数形式),因此突触后脉冲很可能随之而来。发生这种情况时,z会增强,可以克服抑制的影响。
2.3 Reinforcement Learning and Spike-Timing-Dependent Intrinsic Plasticity.
在本节中,我们认为突触后神经元的发放阈值θi也是一种有助于学习的适应性参数,例如wij参数。有足够的证据表明大脑就是这种情况(Daoudal & Debanne, 2003; Zhang & Linden, 2003)。发放阈值将根据:
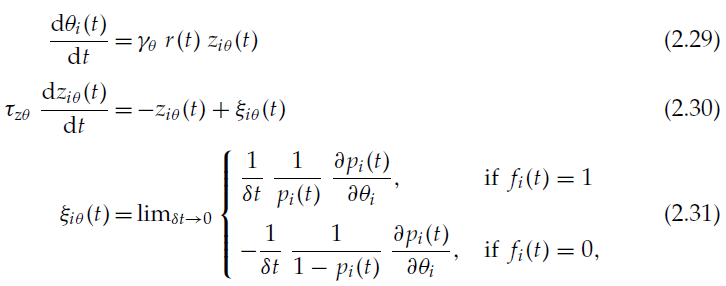
与公式2.17、2.18、2.9和2.19类似。由于![]()
![]() ,我们有:
,我们有:

因此,为了获得正奖励,神经元发出的脉冲会导致神经元发放阈值的降低(兴奋性的提高)。这与实验结果一致,实验结果表明神经兴奋性在爆发后会增加(Aizenman & Linden, 2000; Cudmore & Turrigiano, 2004; Daoudal & Debanne, 2003)。在脉冲之间,发放阈值连续增加(但是,当发放强度以及其相对于膜电位和发放阈值之差的导数较低时,发放阈值将非常缓慢)。
这种使用脉冲序列依赖的固有可塑性的强化学习算法与先前描述的其他两种算法互补,并且可以与它们中的任何一种同时使用。
2.4 Relationship to Other Reinforcement Learning Algorithms for Spiking Neural Networks.
可以证明,本文提出的算法与其他两种针对通用脉冲神经网络的现有强化学习算法具有共同的分析背景(Seung, 2003; Xie & Seung, 2004)。
Seung (2003)像我们所做的那样,通过考虑智能体是突触而不是神经元来应用OLPOMDP。智能体的动作是释放神经递质小泡,而不是神经元的脉冲,优化的参数是控制释放小泡而不是与神经元的突触连接的参数。结果是一种生物学合理的学习算法,但尚无实验证据。
Xie和Seung (2004)没有详细建模神经膜电位的整合特征,而是认为神经元通过改变其泊松脉冲序列的发放率来即时响应输入。他们的研究推导了一种类似于GPOMDP的回合式算法,并将其扩展为类似于OLPOMDP的在线算法,没有任何理由。调整符号后,确定在线学习的公式——Xie和Seung (2004)中的公式16和17——与此处的公式相同:方程式2.17、2.18和2.19。通过将Xie和Seung (2004)中的电流-放电函数 f 重新解释为发放强度ρ,并将突触电流hij解释为突触后核εij,我们可以看到Xie和Seung的算法在数学上等效于推导的算法,且更精确。但是,我们对数学框架的不同解释和实现允许与实验观察到的STDP更好地建立联系,并且可以直接将其推广和应用到模拟中常用的神经模型,而Xie和Seung算法由于对无记忆泊松神经模型的依赖性而不允许这样做。
所有这些算法的共同分析背景表明,它们的学习性能应该相似。
Pfister et al. (2006)开发了一种针对脉冲神经元的监督学习理论,该理论导致了STDP,并且可以在强化学习的背景下得到重新解释。他们仅详细研究了特定的回合式学习情景,而不研究我们在文章中探讨的一般在线案例。然而,分析的背景仍然是相同的,因为在他们的工作中,突触的变化取决于一个量(在他们的文章中为等式7),该量是ξij(t)(公式2.19)的学习回合的积分。因此,它们的某些结果与我们的结果相似也就不足为奇了:他们发现STDP函数的负偏移与我们的正奖励算法所建议的非关联性抑制相对应,并且他们推导出了与关联脉冲时序依赖抑制作为稳态机制的结果,就像我们在其他框架中所做的那样。
3 Modulation of STDP by Reward
前面几节中的推导表明,涉及奖励调节STDP的强化学习算法可以通过分析证明是正确的。我们先前还通过生物学启发实验在模拟中测试了其中一种衍生算法,以实际证明其有效性(Florian, 2005),但是,这些算法既涉及脉冲时序依赖的突触变化,也涉及非关联的突触变化,与之不同的是,标准的STDP (Bi & Poo 1998; Song et al., 2000),但与实验观察到的某些形式的STDP一致(Han et al., 2000)。此外,突触的特定动态取决于发放强度ρ的形式,该强度是一个没有实验证明的模型的函数。由于这些原因,我们选择在模拟中研究解析得出的算法的某些简化形式,以一种直接的方式扩展标准STDP模型。我们提出的学习规则可以应用于任何类型的脉冲神经模型。它们的适用性不仅限于概率模型或我们先前在分析推导中使用的SRM。
所提出的规则只是受分析得出的和实验观察到的规则的启发,并不直接遵循这些规则。在下面的内容中,我们放弃了可塑性对发放强度的依赖(这意味着学习机制也可以应用于模拟中常用的确定性神经模型),我们认为 z 的增强和抑制都是关联且脉冲时序依赖的(不考虑2.2节中介绍的稳态机制),我们使用可塑性对相对脉冲时间的指数依赖性,并且我们认为不同脉冲对的影响是可加的,如先前的研究(Song et al., 2000; Abbott & Nelson, 2000)。所得的学习规则由公式2.17和2.18确定,为方便起见,在下面重复进行讨论,并且考虑到这些简化,还针对ξ的动态公式进行了确定:

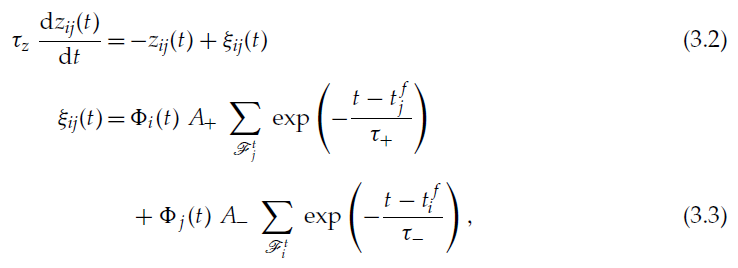
其中τ±和A±为常数参数。时间常数τ±确定了发生突触变化的突触间隔的范围。根据标准的非对称STDP模型,A+为正,A-为负。我们将由上述公式确定的学习规则称为带有资格迹的调节STDP(MSTDPET)。
通过删除资格迹,可以进一步简化学习规则。在这种情况下,我们可以通过标准STDP的奖励r(t)进行简单的调节:
![]()
其中ξij(t)由公式3.3给出。 我们称这种学习规则调节的STDP (MSTDP)。值得注意的是,用我们的符号法,标准STDP模型由下式表示:
![]()
对于所有这些学习规则,引入一个变量![]() 来跟踪突触前脉冲的影响和一个变量
来跟踪突触前脉冲的影响和一个变量![]() 来跟踪突触后脉冲的影响是有用的,而不是在计算机模拟中保留在内存中,过去的所有脉冲和反复总结其影响(Song et al., 2000)。这些变量可能在生物神经元中具有生化对应物。则ξ和P±的动态公式为:
来跟踪突触后脉冲的影响是有用的,而不是在计算机模拟中保留在内存中,过去的所有脉冲和反复总结其影响(Song et al., 2000)。这些变量可能在生物神经元中具有生化对应物。则ξ和P±的动态公式为:
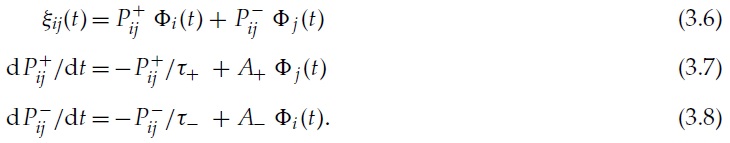
如果在所有突触中τ±和A±都相同(如我们的模拟情况),则![]() 不依赖于 i,
不依赖于 i,![]() 不依赖于 j,但是为了清楚起见,我们将保留两个索引。
不依赖于 j,但是为了清楚起见,我们将保留两个索引。
如果我们以时间步长δt在离散时间中模拟网络,则对于MSTDPET,公式2.7和2.8定义了突触的动态,对于MSTDP,通过以下公式定义了突触的动态:
![]()
并且:
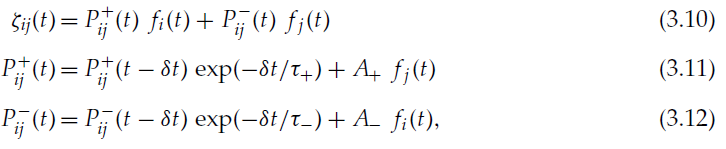
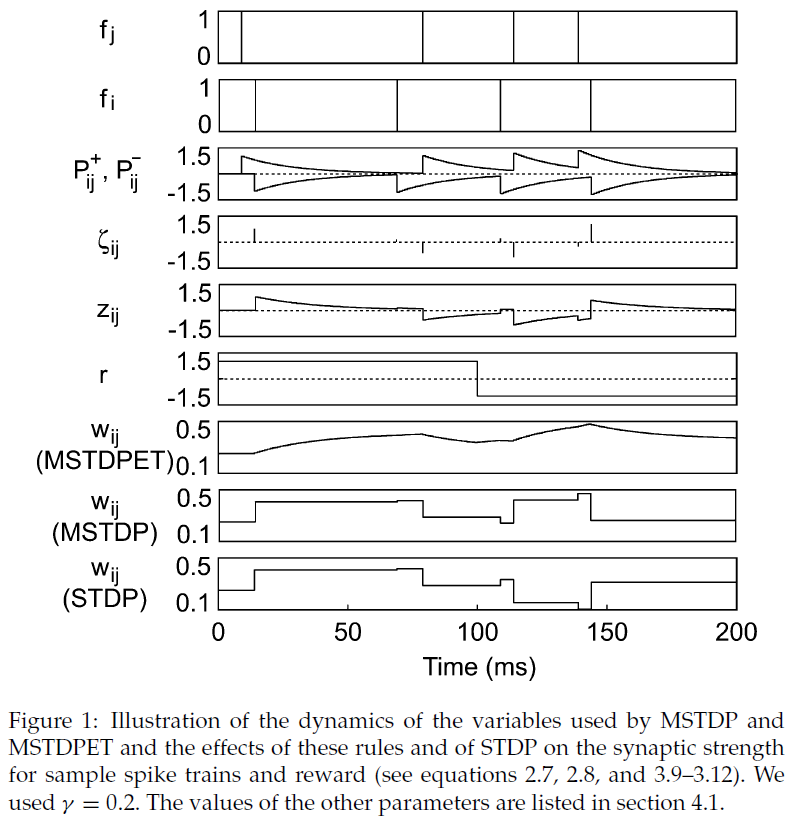
如果神经元 i 在时间步骤 t 发放,则fi(t)为1,否则为0。各种变量的动态如图1所示。
对于标准STDP模型,我们还将边界应用于突触,此外还应用于学习规则指定的动态。
4 Simulations
4.1 Methods.
在下面的模拟中,我们使用了由IF神经元组成的网络,其中静息电位ur = -70 mV,发放阈值θ = -54mV,复位电位等于静息电位,衰减时间常数τ = 20 ms (参数来自Gutig, Aharonov, Rotter, & Sompolinsky (2003),与Song et al. (2000)的研究相似)。网络动态在离散时间内以δt = 1ms的时间进行仿真。突触权重wij表示由单个突触前脉冲引起的突触后膜电位的总增加;这种增加被认为是在脉冲之后的时间步骤中发生的。因此,神经元膜电位的动态由下式给出:
 如果膜电位超过发放阈值θ,则将其重置为ur。轴突无延迟地传播脉冲。奖励调节STDP在生物学上似乎更合理的模拟在其他地方有所介绍(Florian, 2005);在此,我们打算使用极简设置展示所提出的学习规则的效果。我们使用τ+ = τ− = 20 ms;γ值因实验而异。除非另有说明,否则我们使用τz= 25 ms, A+ = 1和A- = -1。
如果膜电位超过发放阈值θ,则将其重置为ur。轴突无延迟地传播脉冲。奖励调节STDP在生物学上似乎更合理的模拟在其他地方有所介绍(Florian, 2005);在此,我们打算使用极简设置展示所提出的学习规则的效果。我们使用τ+ = τ− = 20 ms;γ值因实验而异。除非另有说明,否则我们使用τz= 25 ms, A+ = 1和A- = -1。
4.2 Solving the XOR Problem: Rate-Coded Input.
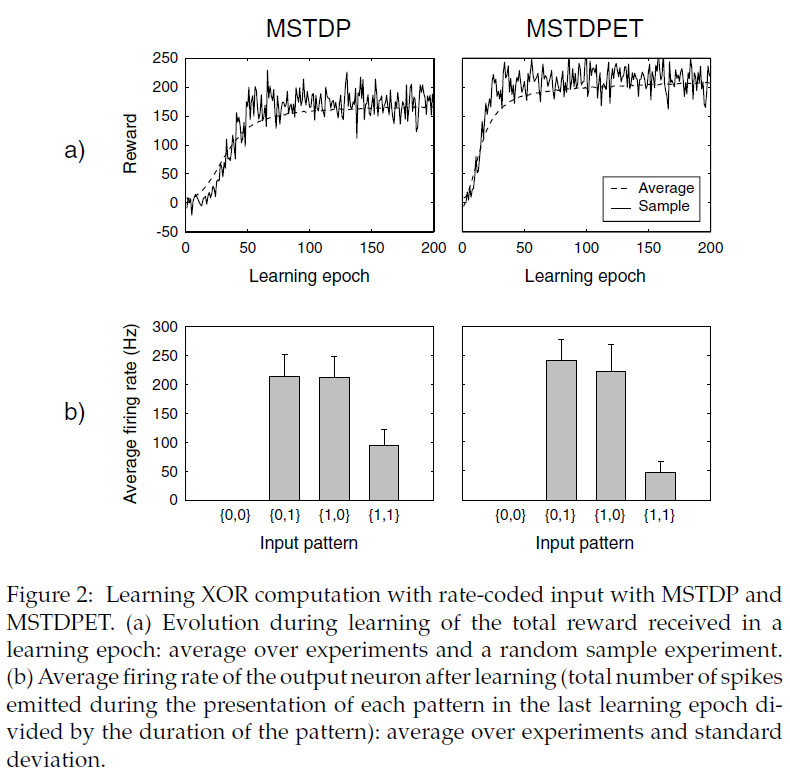
我们首先显示提出的规则用于学习XOR计算的功效。尽管这不是生物学相关的任务,但这是人工神经网络训练的经典基准问题。使用其他强化学习方法对通用脉冲神经网络也解决了这个问题(Seung, 2003; Xie & Seung, 2004)。XOR计算包括在两个二值输入和一个二值输出之间执行以下映射:{0, 0} → 0;{0, 1} → 1;{1, 0} → 1;{1, 1} → 0。
我们考虑了一种与Seung (2003)类似的设置。我们模拟了具有60个输入神经元,60个隐含神经元和1个输出神经元的前馈神经网络。每一层都全连接到下一层。二值输入和输出通过相应神经元的发放率进行编码。输入神经元的前半部分代表第一个输入,其余部分代表第二个输入。输入1由40 Hz的泊松脉冲序列表示,输入0由无脉冲表示。
根据输出神经元的活动,通过呈现输入然后对突触进行适当的奖励或惩罚来完成训练。在每个学习epoch中,四个输入模式以随机顺序分别显示500毫秒。在每种输入模式的表示过程中,如果正确的输出为1,则网络对于发出的每个输出脉冲将收到奖励r = 1,否则为0。这奖励了网络具有高输出发放率。如果正确的输出为0,则对于每个输出脉冲,网络将收到负奖励(惩罚)r = -1,否则为0。在输出脉冲之后的时间步骤中提供了相应的奖励。
编码其中任一输入的输入神经元中有50%具有抑制性;其余的都是兴奋的。突触权重wij在0至5 mV(对于兴奋性突触)或-5 mV至0(对于抑制性突触)之间进行硬约束。在指定范围内随机产生初始突触权重。如果在实验结束时输入模式{1, 1}的输出发放率低于模式{0, 1}或{1, 0}的输出发放率,我们认为网络学到了XOR函数(输入{0, 0}的输出发放率显然始终为0)。每个实验都有200个学习epoch(四个输入模式的表示),对应于400 s的模拟时间。我们调查了MSTDP(使用γ = 0.1 mV)和MSTDPET(使用γ = 0.625 mV)的学习情况。我们发现这两个规则对于学习XOR函数都是有效的(请参见图2)。通过最小化输入模式{1, 1}的输出神经元的发放率并最大化{0, 1}和{1, 0}的相同发放率,突触发生变化,从而增加了网络接收到的奖励。使用MSTDP,网络在1000个实验中的99.1%中学到了任务,而使用MSTDPET,在98.2%的实验中实现了学习。
学习后,如果消除了奖励信号并固定了突触,则XOR计算的性能将保持不变。
4.3 Solving the XOR Problem: Temporally Coded Input.
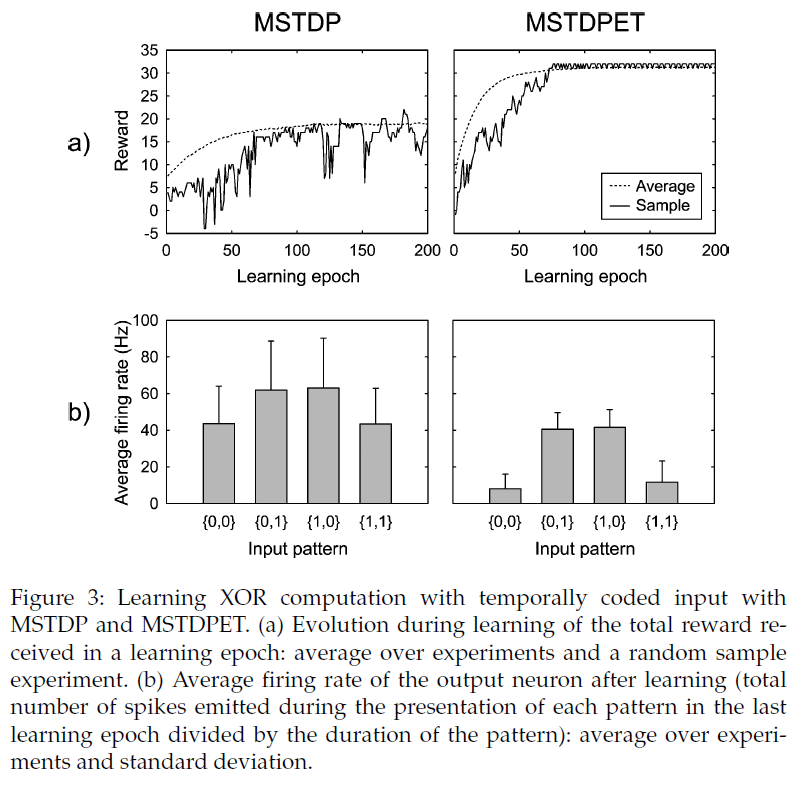
由于在提出的学习规则中突触的变化取决于脉冲精确时间,因此我们研究了如果输入是暂时编码的,是否还可以学习XOR问题。我们使用了一个具有2个输入神经元,20个隐含神经元和1个输出神经元的全连接前馈网络,其设置类似于Xie和Seung (2004)中的设置。输入信号0和1由长度为500 ms的两个不同的脉冲序列编码,这是在每个实验开始时通过在此间隔内均匀分布50个脉冲随机生成的。因此,为了强调频率编码的区别,所有输入均具有相同的100 Hz的平均发放率。
由于神经元的数量很少,因此我们没有将它们分为兴奋性神经元和抑制性神经元,而是让输入层和隐含层之间的突触权重同时采用了两种符号。这些权重的范围介于-10 mV和10 mV之间。隐含层和输出神经元之间的突触权重被限制在0到10 mV之间。和以前一样,每个实验都包含200个学习epoch,相当于400 s的模拟时间。对于MSTDP,我们使用γ = 0.01 mV,对于MSTDPET,我们使用γ = 0.25 mV。
使用MSTDP,网络在1000个实验中的89.7%处学习了XOR函数,而使用MSTDPET,在99.5%的实验中实现了学习(见图3)。网络学会了通过响应两个输入神经元的同步来解决任务。我们验证了学习后,网络不仅解决了学习期间使用的输入模式,而且还解决了类似生成的任意一对随机输入信号的任务。
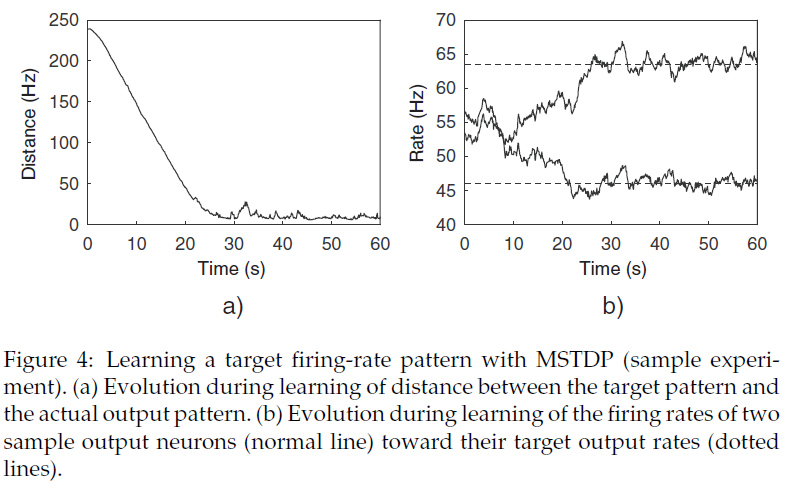
4.4 Learning a Target Firing-Rate Pattern.
我们还验证了所提出的学习规则的能力,以允许网络学习给定的输出模式,该模式由输出神经元的单个发放率进行编码。在学习过程中,当目标模式与实际模式之间的距离d减小时,网络获得奖励r = 1;而当距离增加时,网络获得惩罚r = -1,r(t + δt) = sign(d(t) - d(t - δt))。
我们使用了一个前馈网络,其中有100个输入神经元直接连接到100个输出神经元。每个输出神经元都从所有输入神经元接收轴突。突触权重限制在0和wmax = 1.25 mV之间。输入神经元以恒定随机的发放率发放泊松脉冲序列,对于每个神经元均匀地产生0至50 Hz。每个输出神经元的目标发放率![]() 也在每个实验开始时随机产生,均匀地在20到100 Hz之间。输出神经元的实际发放率νi使用时间常数τν = 2 s的泄漏积分器测量:
也在每个实验开始时随机产生,均匀地在20到100 Hz之间。输出神经元的实际发放率νi使用时间常数τν = 2 s的泄漏积分器测量:
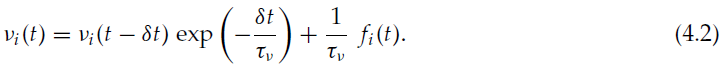
这等效于使用指数核对发放率进行加权估计。我们测量了当前输出发放模式与目标发放模式之间的总距离,即![]() 。在初始瞬态之后输出发放率稳定之后,学习就开始了。
。在初始瞬态之后输出发放率稳定之后,学习就开始了。
我们使用MSTDP (γ = 0.001 mV)和MSTDPET (γ = 0.05 mV)进行实验。两种学习规则均允许网络学习给定的输出模式,并获得非常相似的结果。在学习过程中,目标输出模式与实际输出模式之间的距离迅速减小(大约30 s),然后保持接近于0。图4说明了使用MSTDP进行学习。
4.5 Exploring the Learning Mechanism.
为了更详细地研究所提出的学习规则的性质,我们在改变定义规则的各种参数的同时,重复了上述目标发放率模式实验的学习。为了表征学习速度,我们认为,如果tc和tc + τc之间的 t 的实际输出与目标输出之间的距离d(t)不小于d(tc),则在时间tc处会收敛。2 s, 10 s或20 s,具体取决于实验。我们以e(t) = 1 - d(t)/d(t0)来衡量学习效果,其中d(t0)是学习开始时的距离;收敛时的学习效率为ec = e(tc)。最优学习效果可能是1,值为0表示没有学习。负值表示相对于突触具有随机值的情况,实际发放率模式与目标之间的距离增加了。
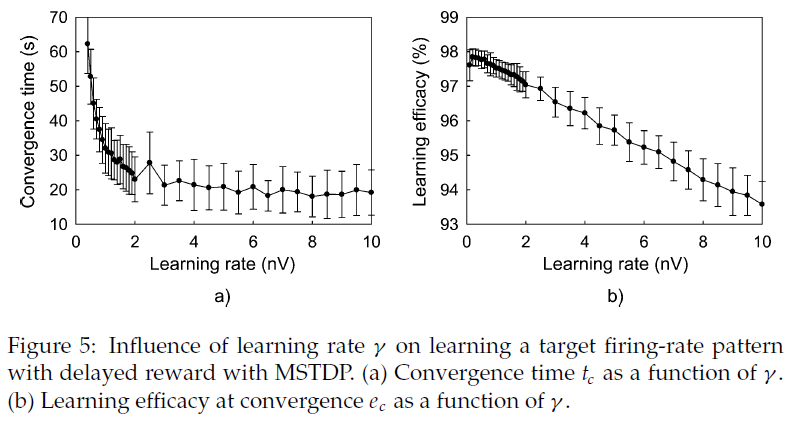
4.5.1 Learning Rate Influence.
增加学习速率γ会导致更快的收敛,但是随着γ的增加,它对学习速度的影响越来越不重要。收敛时的学习效率随着学习率的提高而线性下降。图5展示了对MSTDP的这些影响(τc = 10 s),但对于MSTDPET,其行为是相似的。
4.5.2 Nonantisymmetric STDP
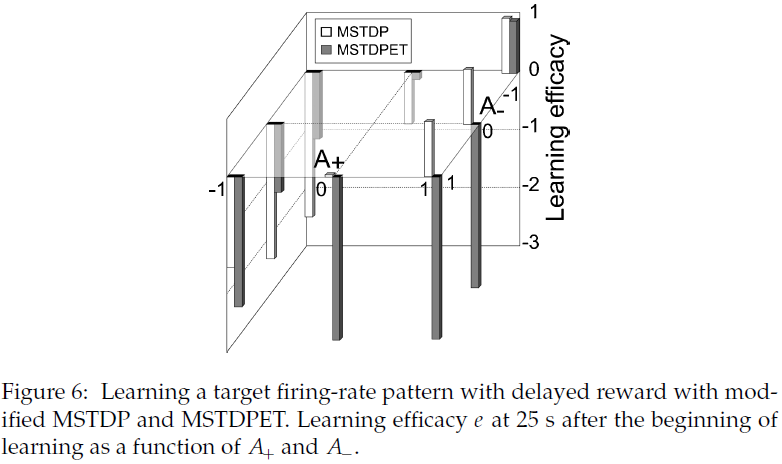
我们已经研究了通过改变A±参数的值来改变学习规则所使用的STDP窗口(函数)的形式对学习性能的影响。这样就可以评估对学习STDP窗口的两个部分的贡献(分别对应于突触前和突触后脉冲之间的正延迟和负延迟)。这也允许探索奖励调节对称STDP的特性。
我们已经重复学习了具有各种A±参数值的目标发放模式实验。图6展示了学习25秒后的学习效果。可以观察到,对于MSTDP,在所有情况下都可以进行强化学习,在这种情况下,当奖励为正时,突触前脉冲后的突触后脉冲会增强突触,而当奖励为负时会抑制突触,从而增强因果关系。当A+ = 1时,无论A-的值如何,MSTDP都会导致强化学习。对于MSTDPET,仅对标准反对称赫布STDP (A+ = 1,A- = -1)的调节才导致学习。A±参数的许多其他值使输出和目标模式之间的距离最大化(请参见图6),而不是使输出模式最小化,这是要学习的任务。这些结果表明,STDP的因果性质是所提出规则功效的重要因素。
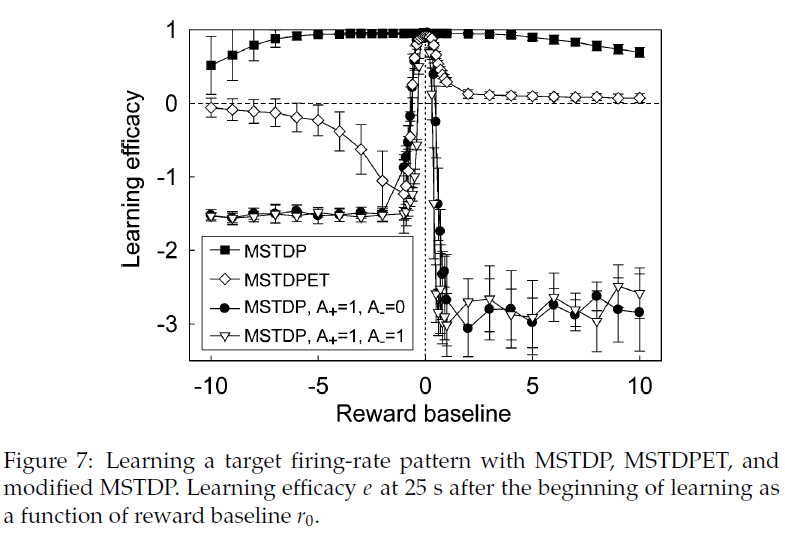
4.5.3 Reward Baseline.
在之前的实验中,奖励为1或-1,因此基准为0。我们重复了目标发放模式实验的学习,同时改变了奖励基准r0,得出奖励r(t + δt) = r0 + sign(d(t) - d(t - δt))。实验表明,零基准是最有效的。在相对较大的奖励基准间隔为0的情况下,MSTDP的效率变化不大。事实证明,MSTDPET的效率对基准为0更为敏感,但任何正基准仍会导致学习。这表明对于MSTDP和MSTDPET而言,强化学习都可以受益于标准STDP的无监督学习特性,当r为正时即可实现。确保r始终为正的正基准在生物学上也是相关的,因为尚未通过实验观察到STDP符号的变化,并且在大脑中可能是不可能的。
修改后的MSTDP (A−为0或1)已被证明可以学习0个基准,它对偏离该基准最敏感,轻微的偏差会导致学习效率变为负值(即距离最大化而不是距离最小化;请参见图7)。
修改后的MSTDP在正r0处的性能较差是由于所有突触都倾向于采用最大允许值。在r0为负值时,与正常MSTDP相比,修改后的MSTDP的突触分布偏向较小值。MSTDPET在负r0时相对较差的性能是由于突触的分布偏向大值。对于学习有效的情况,学习后的突触分布几乎是均匀的,其中MSTDP和修改后的MSTDP在允许间隔的末端也具有其他小的峰值。
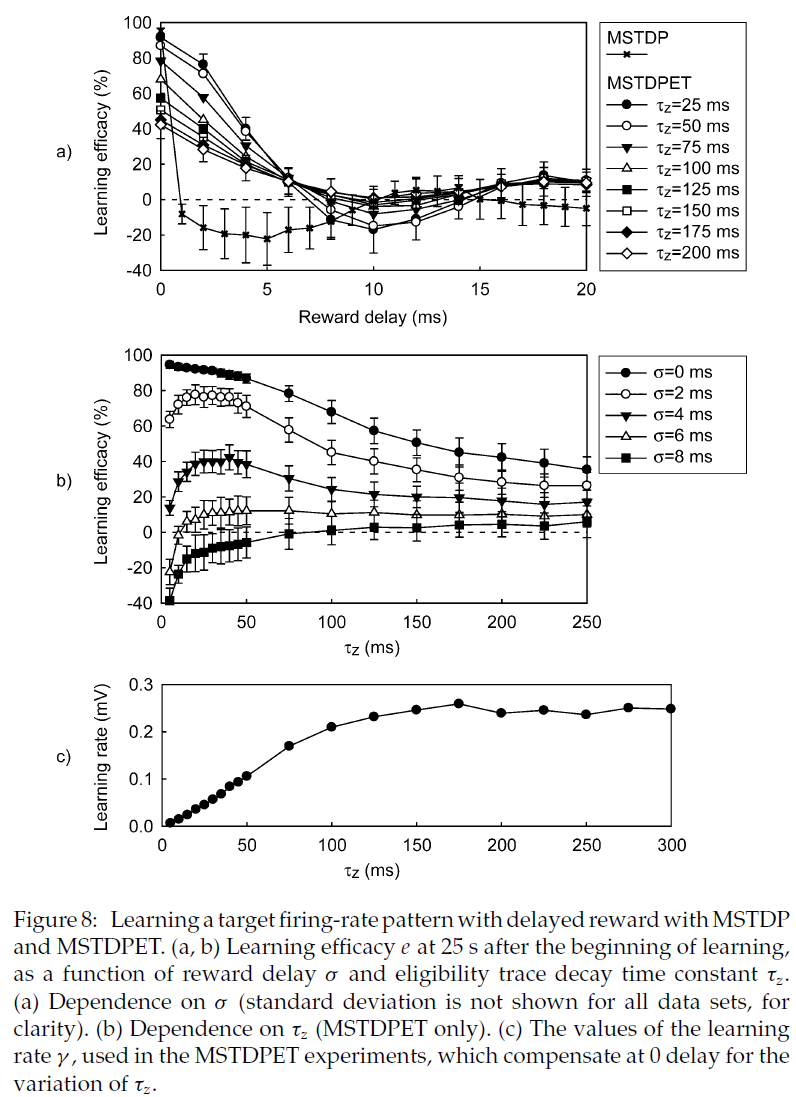
4.5.4 Delayed Reward.
对于迄今为止提出的任务,MSTDPET的性能可与MSTDP媲美或更差。当学习一项任务时,使用资格迹就会出现优势,在这种任务中,奖励是相对于导致该奖励的网络的状态或输出以一定的延迟σ传递到网络的。
为了正确研究奖励延迟对MSTDPET学习性能的影响,对于τz的各种值,我们必须考虑τz的变化的影响。较高的τz导致较小的突触变化,因为z衰减更慢,并且,如果奖励随时间步骤变化,并且正负奖励的概率近似相等,则它们对突触的影响(具有相反的符号)将几乎抵消掉。因此,τz的变化导致学习功效和收敛时间的变化,类似于先前描述的学习速率的变化。为了补偿这种影响,我们将学习率γ作为τz的函数进行了更改,以使MSTDPET的收敛时间是恒定的,在奖励延迟σ = 0时,对于γ = 0.001,它近似等于MSTDP的收敛时间,同样在σ = 0处。我们使用Ridder's方法(Press, Teukolsky, Vetterling, & Flannery, 1992)通过对公式![]() 进行数值求解来获得相应的γ值。为了确定收敛,我们使用τc = 2 s。所获得的γ值对τz的依赖性如图8c所示。
进行数值求解来获得相应的γ值。为了确定收敛,我们使用τc = 2 s。所获得的γ值对τz的依赖性如图8c所示。
MSTDPET继续允许网络学习,而MSTDP和修改后的MSTDP (A- ∈ {-1, 0, 1})在这种情况下即使延迟很小也无法解决任务。只有在奖励不延迟的情况下,MSTDP和修改后的MSTDP才能在我们的设置中进行学习。在这种情况下,ij突触强度的变化由乘积r(t + δt)ζij(t)决定,奖励r(t + δt)与网络在时间 t 的活动(突触后脉冲)相对应,变量ζij(t)仅当在同一时间步骤 t 内有突触前或突触后脉冲时非零。即使很小的奖励额外延迟σ = δt也会阻碍学习。图8a展示了两种学习规则的性能,作为学习目标发放模式的奖励延迟σ的函数。图8b显示了对于奖励延迟σ的几个值,MSTDPET的性能作为τz的函数。对于特定的延迟产生最优性能的τz值随该延迟单调且非常快地增加。对于零延迟或大于最优值的τz值,对于较高的τz,性能会下降。通过测量学习开始后25 s的学习效能e的均值(从100个实验中获得)来评估性能。
资格迹保留对最近的突触前和突触后脉冲之间的关系的递减记忆。因此可以理解的是,只要该延迟小于τz,MSTDPET甚至允许在延迟奖励的情况下进行学习。从图8可以看出,至少对于所研究的设置,即使延迟远小于τz,对于较大的延迟,学习效率也会显著降低,并且对于大于约7 ms的延迟,则没有明显的学习。对于其他设置,可能学习的最大延迟可能会更大。
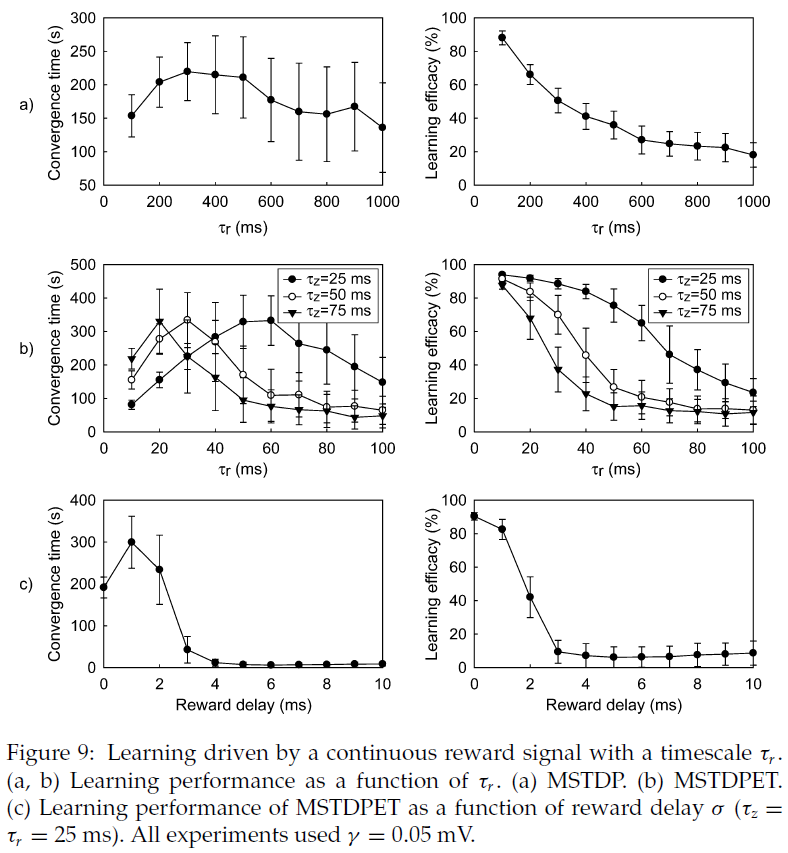
4.5.5 Continuous Reward.
在先前的实验中,奖励随时间步骤的变化而变化,时间尺度为δt = 1 ms。在动物中,内部奖励信号(例如神经调节剂)变化更慢。为了研究这种情况下的学习性能,我们使用了一个连续的奖励,该奖励随着时间尺度τr的变化而变化,其动态为:
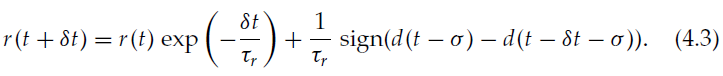
当奖励是连续且没有延迟时,MSTPD和MSTDPET都将继续工作。随着τr的增加,学习效率单调下降(见图9a和9b)。与离散奖励信号的情况一样,即使奖励延迟σ很小,MSTDPET仍允许学习(见图9c),而奖励延迟则MSTDP不会导致学习。

4.5.6 Scaling of Learning with Network Size.
为了探索所提出的学习机制的性能如何随网络规模扩展,我们系统地改变了输入和输出神经元的数量(分别为Ni和No)。为了使每个突触后神经元的平均输入在具有不同数量输入神经元的设置之间保持恒定,将最大突触效率设置为wmax = 1.25 · (Ni / 100) mV。
当No随着Ni常数而变化时,随着No的增加,收敛ec的学习效率降低,而随着No的增加,收敛时间tc随着No的增加而增加,这是因为任务的难度增加了。当Ni随着No常数而变化时,由于任务的难度保持恒定,收敛时间随着Ni的增加而减少,但是由于每个输出神经元传入突触的数量增加,因此可以解决任务的方式数量增加。但是,如果No不变,则Ni越高,学习效果就会越差。
当Ni和No同时变化时(Ni = No = N),对于较大的网络规模,收敛时间会略有减少(请参见图10a)。再次,较高的N会降低学习效果,这意味着无法使用此方法训练任意大小的网络(请参见图10b)。MSTDP和MSTDPET的行为都相似,但是对于MSTDPET,大型网络的学习效率下降更加明显。通过考虑ec对N的依赖关系对于N ≥ 600是线性的,并可以从可用数据中推算得出,结果是对于N > Nmax的网络,学习是不可能的![]() ,对于MSTDP,Nmax约为4690。MSTDPET为1560,用于此处考虑的设置和参数。对于某些参数配置,可以通过降低学习速率γ来提高学习效率,从而减少学习时间(如上所述;请参见图5)。
,对于MSTDP,Nmax约为4690。MSTDPET为1560,用于此处考虑的设置和参数。对于某些参数配置,可以通过降低学习速率γ来提高学习效率,从而减少学习时间(如上所述;请参见图5)。
4.5.7 Reward-Modulated Classical Hebbian Learning.
为了进一步研究因果性STDP作为所提出学习规则的组成部分的重要性,我们还研究了奖励(同时仍使用脉冲神经网络)调节的经典(与频率相关)赫布可塑性的特性。
在某些条件下(Xie & Seung, 2000),当可塑性窗口对称时,经典的赫布可塑性可以通过修改后的STDP进行近似,A+ = A- = 1。在这种情况下,根据Xie和Seung (2000)的表示,我们有β0 > 0和β1 = 0,因此可塑性(大约)取决于突触前和突触后发放率的乘积,而不是它们的时间导数。上面研究了具有A+ = A- = 1的奖励调节STDP。
遵循以下学习规则,可以更直接地将调节的频率依赖型赫布学习与脉冲神经元近似起来:

其中![]() 与MSTDP和MSTDPET相同,其中A+ = A- = 1。可以看出,该规则是经典赫布规则的奖励调节版本,因为
与MSTDP和MSTDPET相同,其中A+ = A- = 1。可以看出,该规则是经典赫布规则的奖励调节版本,因为![]() 是对突触前神经元 j 发放率的估计,而
是对突触前神经元 j 发放率的估计,而![]() 是对突触后神经元 i 发放率的估计(使用指数核)。奖励可以同时具有两个符号,因此该规则既可以增强突触,也可以抑制突触。像经典的赫布学习一样,没有必要使用额外的抑制机制来避免突触爆炸。我们使用此学习规则重复了上述实验。对于10−6至1 mV之间的γ值,我们无法使用此规则进行学习。
是对突触后神经元 i 发放率的估计(使用指数核)。奖励可以同时具有两个符号,因此该规则既可以增强突触,也可以抑制突触。像经典的赫布学习一样,没有必要使用额外的抑制机制来避免突触爆炸。我们使用此学习规则重复了上述实验。对于10−6至1 mV之间的γ值,我们无法使用此规则进行学习。
4.5.8 Sensitivity to Parameters.
相对于用于学习规则的参数,上面给出的模拟结果非常鲁棒。我们必须在实验之间调整的唯一参数是学习率γ,它决定了突触变化的幅度。学习速率太小并不能足够快地改变突触,以至于无法在给定的实验时间内观察到学习的效果,而学习速率太大会使突触趋向边界,从而限制了网络的行为。对于涉及突触可塑性的任何种类的学习规则,都需要调整学习速率。在没有延迟奖励的实验中,资格迹衰减的时间常数τz的大小不是必需的,尽管较大的值会降低学习性能(见图8b)。对于分别用于正负奖励的相对奖励幅度,我们使用了自然选择(将它们设置为相等),而不必像Xie和Seung (2004)那样调整这一点来实现学习。奖励和A±的绝对大小无关紧要,因为它们对突触的影响由γ缩放。
5 Discussion
通过将抽象的强化学习算法应用于脉冲神经元的脉冲响应模型,我们得出了用于脉冲神经网络的强化学习算法的几种版本。所产生的学习规则类似于动物实验中观察到的脉冲时序依赖的突触和内在可塑性机制,但是通过突触和兴奋性变化的奖励而涉及额外的调节。我们还在计算机模拟中研究了两种学习规则的性质,MSTDP和MSTDPET,它们保留了分析得出的规则的主要特征,同时更为简单,并且是STDP标准模型的扩展。我们已经表明,全局奖励信号对STDP的调节会导致强化学习。保留最近的脉冲对效应的衰变记忆的资格迹功能可以在奖励被延迟的情况下进行学习。STDP窗口的因果性质似乎是所提出的学习规则的学习性能的重要因素。
所提出的强化学习机制与实验观察到的STDP之间的连续性使其在生物学上似乎合理,并且还建立了强化学习与STDP的无监督学习能力之间的连续性。资格迹z的引入与当前对生物学STDP的了解并不矛盾,因为它仅暗示突触变化不是瞬时的,而是通过生成一组生化物质来实现的,而生化物质在生成后呈指数衰减。一个新的特征是奖励信号r的调节效应。 这可以通过神经调节剂在大脑中实现。例如,多巴胺携带一个短时的奖励信号,表明实际奖励与预测奖励之差(Schultz, 2002),非常适合我们基于连续奖励调节可塑性的学习模型。众所周知,多巴胺和乙酰胆碱可调节经典的(发放率依赖)突触的长期增强和抑制作用(Seamans & Yang, 2004; Huang, Simpson, Kellendonk, & Kandel, 2004; Thiel, Friston, & Dolan, 2002)。通过激活β-肾上腺素能受体,海马CA1锥体神经元的脉冲时序依赖的增强被放大,这支持了神经调节剂对STDP的调节(Lin, Min, Chiu, & Yang, 2003, 图6F)。正如之前推测的那样(Xie & Seung, 2004),可能是其他研究未能检测到神经调节剂对STDP的影响,因为在实验过程中奖励回路可能未起作用,并且奖励信号可能已固定为给定值。在这种情况下,根据所提出的学习规则,对于兴奋性突触,如果在实验过程中将奖励冻结为正值,则将导致赫布STDP,否则将导致反赫布STDP。
研究的学习规则可用于训练通用人工脉冲神经网络的应用程序,并建议对动物进行奖励调节STDP的存在的实验研究。


 浙公网安备 33010602011771号
浙公网安备 33010602011771号