文档检索之BM25
本篇介绍文档检索排序算法:TF-IDF、BM25及其扩展。
TF-IDF
TF-IDF 来源于一个最经典、也是最古老的信息检索模型,即“向量空间模型”(Vector Space Model)。向量空间模型就是希望把查询关键字和文档都表达成向量,然后利用向量之间的运算(点积或余弦相似度等)来进一步表达向量间的关系。
对于查询关键字,向量的长度是 V(词汇表的大小)。其中关键字的单词出现过的维度对应值是 1,其他维度值是 0。对于目标文档而言,关键词出现过的维度取值是 TF-IDF 的数值,而其他维度是 0。在这样的表达下,如果我们对两个文档进行“点积”操作,则得到的相关度打分(Scoring)就是 TF-IDF 作为相关度的打分结果。相当于word embedding常用的lookup table,查找对应的分数并相加。
TF-IDF定义:TF-IDF=TF×IDF
TF:关键词在文档中出现的频次;IDF:涵盖了这个单词的文档数量的倒数,用来“惩罚”那些出现在太多文档中的单词。
TF-IDF 算法变种
- TF上限的角度。
对 TF 进行log变换,是一个不让 TF 线性增长的技巧。 - TF 归一化(常用)“长文档”和“短文档”的区别。
对 TF 进行“标准化”(Normalization),如根据文档中的词汇量或者根据文档的最大 TF 值进行标准化,这是另外一个比较常用的技巧。 - 对 IDF 进行对数处理(常用)
使用 N+1 除以 DF 作为一个新的 DF 的倒数,并且再在这个基础上通过一个对数变化。这里的 N 是所有文档的总数。这样做的好处就是,第一,使用了文档总数来做标准化,很类似上面提到的标准化的思路;第二,利用对数来达到非线性增长的目的。 - IDF改为IWF
对IDF计算中的文档数量改为单词的词频,将评价重要度的粒度从doc数量细化到出现总次数。
如果要把 TF-IDF 应用到中文环境中,是否需要一些预处理的步骤?
中文首先要分词,分词后要解决多词一义,以及一词多义问题,这两个问题通过简单的tf-idf方法不能很好的解决,于是就有了后来的词嵌入方法,用向量来表征一个词。
BM25
BM25,全称是 Okapi BM25,是由英国一批信息检索领域的计算机科学家开发的排序算法,在 20 世纪 70 年代开始被提出。在信息检索和文本挖掘领域,具有理论基础,在工程实践中被广泛应用。这里的“BM”是“最佳匹配”(Best Match)的简称,BM25 是“非监督学习”排序算法中的一个典型代表。
BM25 其实是一个经验公式,这里面的每一个成分都是经过很多研究者的迭代而逐步发现的。很多研究在理论上对 BM25 进行了建模,从“概率相关模型”(Probabilistic Relevance Model)入手,推导出 BM25 其实是对某一类概率相关模型的逼近。
现代的 BM25 算法是用来计算某一个目标文档(Document)相对于一个查询关键字(Query)的“相关性”(Relevance)的流程。
BM25 分为三个部分:
- 单词和目标文档的相关性
- 单词和查询关键词的相关性
- 单词的权重部分
这三个部分的乘积组成某一个单词的分数。然后,整个文档相对于某个查询关键字的分数,就是所有查询关键字里所有单词分数的总和。
通常单词在文档中出现的频次TF越高往往越相关,而IDF可衡量单词对于文档的权重。BM25同样从TF-IDF的思路出发基于经验进行设计改进。TF-IDF 没有考虑词频上限的问题,因为标准实践中通常会移除高频停用词。BM25 最大的贡献之一就是挖掘出了词频和相关性之间的关系是非线性的,某一个单词对最后分数的贡献不会随着词频的增加而无限增加。
衡量文档匹配相似度的方法-BM25的公式如下:
由于对查询query中的所有单词进行加权求和,与单词数量相关,值域在[0, +无穷),没有上限。
其中IDF与普通的IDF计算方式无异,作为单词的权重。
单词与文档的相关性的定义为\(S(q_i, D) = \frac{(k_1+1)tf_{td}}{K+tf_{td}}= \frac{k_1+1}{{K\over tf_{td}}+1}\),\(K = k_1(1-b+b*\frac{L_d}{L_{ave}})\)
其中,\(tf_{td}\) 是单词t在文档d中的词频,Ld是文档d的长度,\(L_{ave}\)是所有文档的平均长度,用于长度归一化。
变量k1是一个正的参数,用来标准化文章词频的范围,当k1=0,就是一个二元模型(binary model)(没有词频),一个更大的值对应使用更原始的词频信息。这个参数控制着词频结果在词频饱和度中的上升速度。经验值为 1.2 。值越小饱和度变化越快,值越大饱和度变化越慢。
b是另一个可调参数(0<b<1),决定使用文档长度来表示信息量的范围:当b为1,是完全使用文档长度来权衡词的权重,当b为0表示不使用文档长度。b越大,文档长度的对相关性得分的影响越大,反之越小。而文档的相对长度越长,K值将越大,则相关性得分会越小。这可以理解为,当文档较长时,包含该单词的机会越大,因此,同等频率的情况下,长文档与qi的相关性应该比短文档与qi的相关性弱。经验值为 0.75 。
在相关性定义公式中\(k_1,b,L_d,L_{ave}\)都是固定的,只有\(tf_{td}\) 影响qi的相关性的相对大小,词频越大,分数也越大,呈非线性关系。这里TF的计算可以采用TF-IDF中常见的归一化后的TF计算方式。
单词与query的相关性计算方式与文档的方式相同,只不过由于query通常较短,不需要考虑长度对相关性得分的影响(将b置0,K=k1)。又因为query中出现的单词词频大多为1,所以\(S(q_i, Q)\)可直接取值1,从而忽略该项的计算。
BM25属于基于隐空间(latent space)的传统匹配方法,将query、doc映射到同一空间,对于query的表示采用的是布尔模型表达,也就是term出现为1,否则为0。计算框架示意图如下:
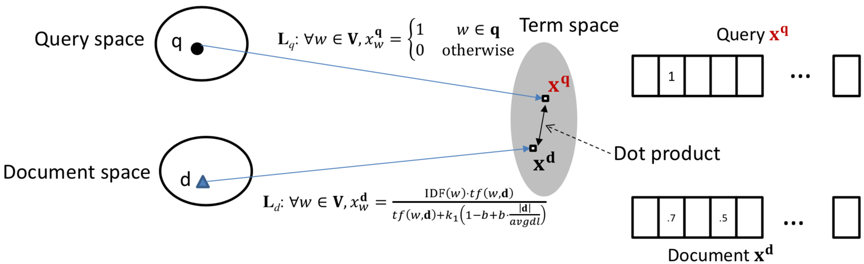
中文适配:在英文等按空格分词的语言中常采用IDF作为词的权重,而中文领域中的分词技术已经有了长足的发展,可以将简单的IDF替换成复杂的分词权重来做中文的检索匹配。
BM25扩展
代表性的扩展 BM25F,是在 BM25 的基础上再多个“域”(Field)文档上的计算。把每个域当做单独的文档,进行计算,然后集合每个域的值,进行加权平均得到最终分数。
参考:

 浙公网安备 33010602011771号
浙公网安备 33010602011771号
