[思考] 具身智能
人形机器人
此章节部分参考自新石器公园 - 具身智能关于机器人的科普视频。
基于动力学方法
波士顿动力早期方案 - 基于动力学的机器人控制方案:方法如图中4步所示,缺点是计算量大且不精确,对于环境严重过拟合。

盲人行走法
随着GPU仿真与强化学习训练平台的建设,参考nvidia与ETH 22年的论文,在仿真环境中训练机器人行走的方案逐渐成熟,如下图所示,以固定速度、根节点角度以及脚抬起时长等作为Reward给机器人一个初始速度让其“盲人行走”,再使用仿真器模拟各种摩擦力与地形的环境,使得机器习得走路技能。这种方式未使用传感器感知环境观测信息,无法应对复杂地形变换的场景。

传感器+世界模型
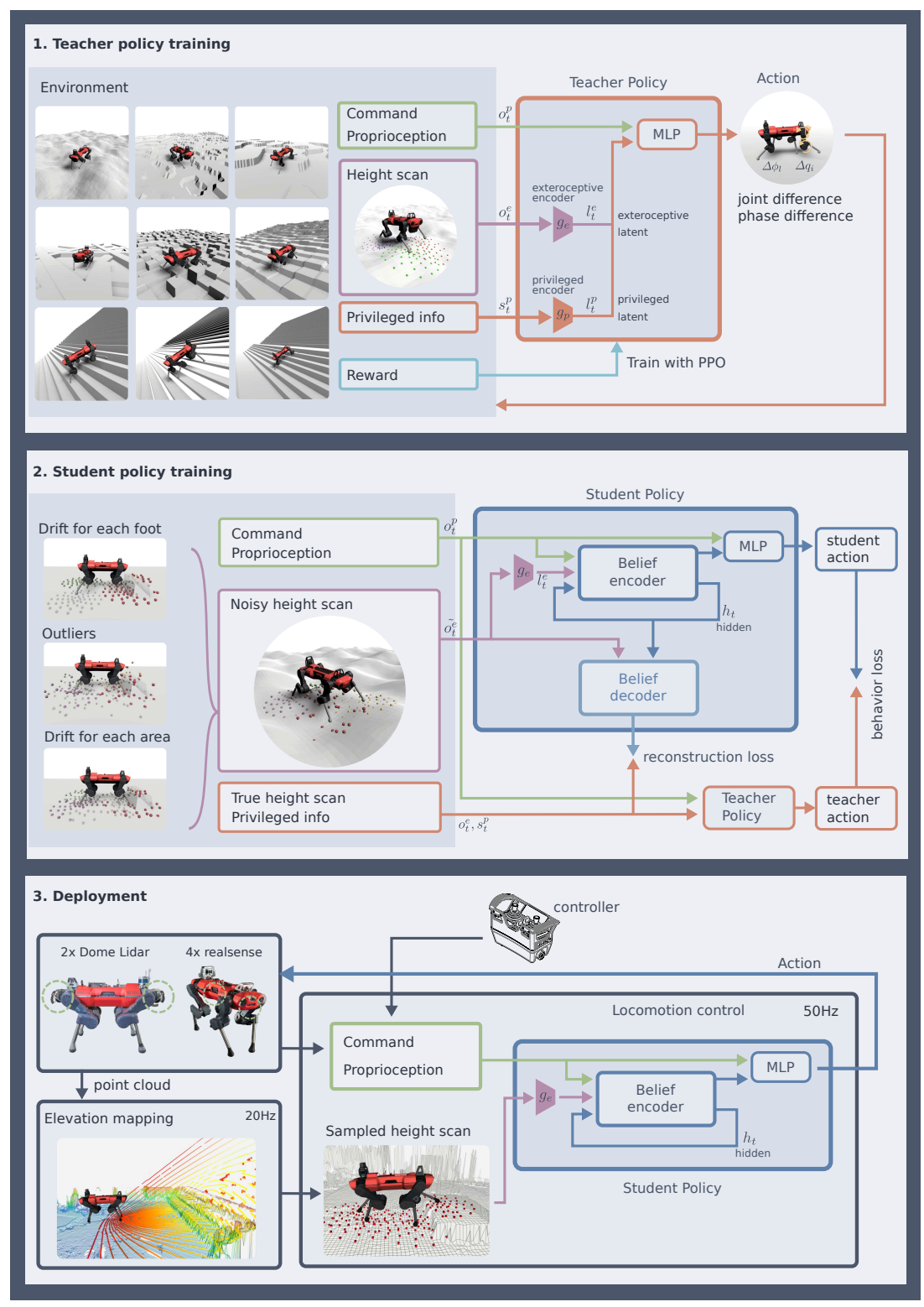
接近着比较容易想到的方法就是,在强化学习过程给机器人增加传感器(相机或者激光雷达)的观测信息,可以想像到对于简单地形变换确实可以提供较好的帮助。但对于雪地(激光Lidar失效)、草丛(机器人太矮完全遮挡视野)等复杂情况,机器人的行走能力会完全失效。此时依赖于世界模型给机器人提供先验来“脑补”被残缺部分的环境信息。其做法可参考ETH 2022年的工作Learning robust perceptive locomotion...,概括如下:
- 训练Teacher模型:利用建好图的模型作为“特权信息”提供给Teacher模型作为额外观测信息,使得Teacher模型在这种环境能够表现很好,并且Breif Encoder可以将“特权信息”编码为privileged latent;
- 给Teacher输入“特权信息”,而Student仅输入残缺的自身传感器观测信息,使用Teacher蒸馏Student的privileged latent并且Teacher的action policy蒸馏student的policy。如此,Student既学习到脑补完整建图的信息(也可理解为Student自己的世界模型),也可以有更准确的action policy。
- 部署时仅部署Student模型,研究人员发现在复杂地形上行走能力明显提升 (例如 在雪地场景传感器失效,就不相信感知与建图结果,直接退化为盲人行走模式)。
![image]()
更多动作的训练?
除了走路之外,还有很多动作,例如 快跑、慢跑、摔倒 后爬起来,为什么这些动作人形机器人的姿态与人类如此相似?答案在于:与人类具有仿生结构的人形机器,只有类似于跑步的动作,才能既快而能耗又比较低,基于能量低的Reward很多工作取得了很好的效果。

参考工作
提出能量Reward的参考工作
基于能量Reward机器狗跑酷的工作
更难动作的训练?
如何训练机器掌握新技能?例如,打篮球。答案是 通过模仿学习(mitation Learning),但需要解决sim2real的gap。原理参考nvidia与CMU 2025年的论文

具体方法如下图:
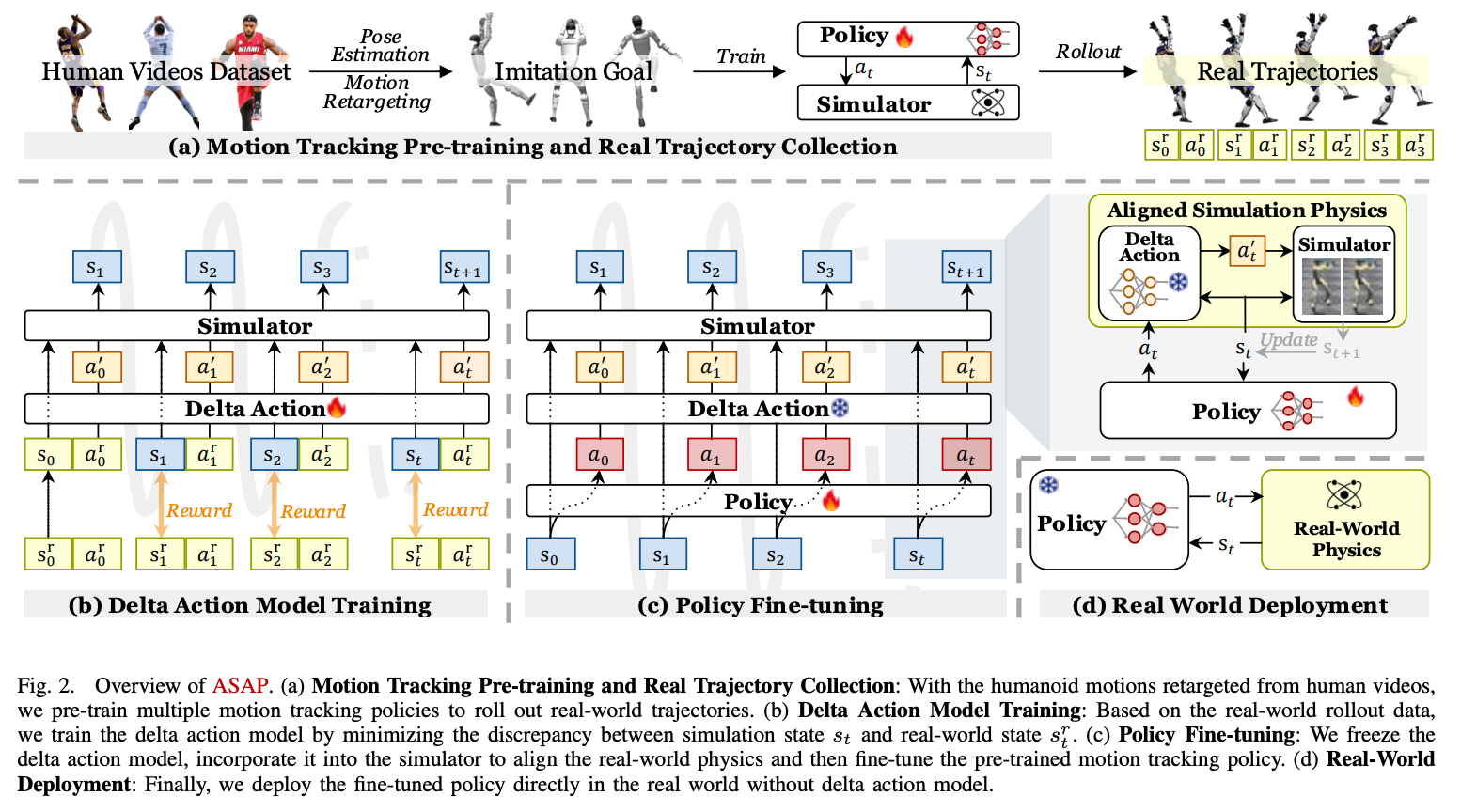
Figure 2a: 采集人类打篮球动作数据通过模仿学习在仿真环境中训练Policy,此时Policy在真实机器上效果还不好,存在sim2real gap。
Figure 2b: 将仿真轨迹\(a_t\)在真实机器人上的动作轨迹\(a'_t\),训练一个Delta Action Model数据表达为\(Δa_t = {\pi}^{\sigma}(s_t,a_t)\)。
Figure 2c: Action Delta Model来矫正仿真器状态数据表达为\(s_{t+1} = f^{sim}(s_{t}, a_{t} + Δa_{t})\),再使用矫正后仿真器Finetune训练Policy Model。
Figure 2d: 将Finetune训练后的Policy Model部署于真实环境效果很提升明显。
VLA模型
数据
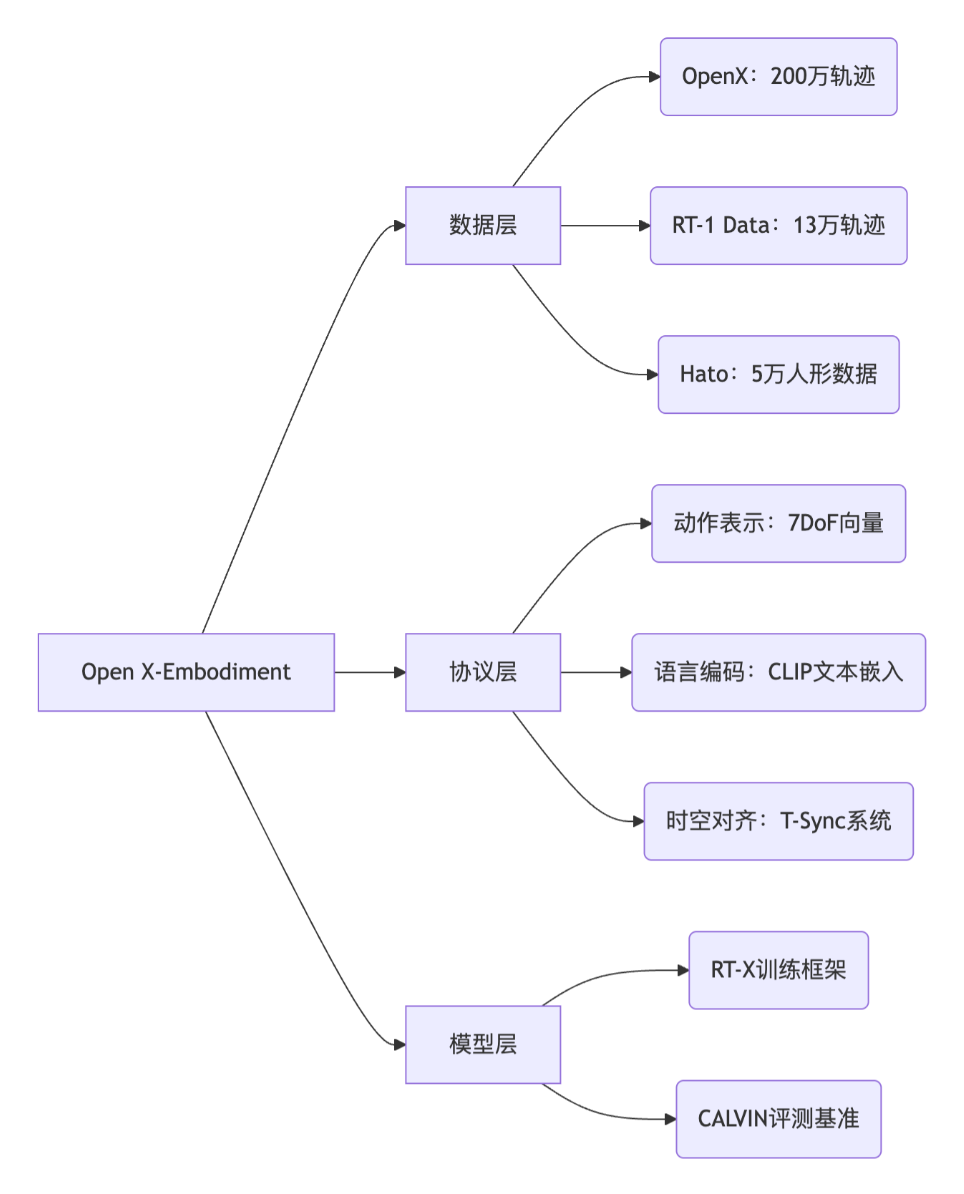
Open X-Embodiment (OXE)
OXE全称Open X-Embodiment,论文链接。它由Google DeepMind牵头,联合了全球超过20家顶尖高校和研究机构,共同将各自宝贵的机器人数据集贡献出来,并统一成标准格式。其影响力相当于ImageNet相对于早期的计算机视觉。
数据量
- OXE整合了来自22种不同机器人形态的数据。
- 包含了超过100万+条任务轨迹 (trajectory)。
- 覆盖了超过527种不同的技能 (skills)。
多样性
这是OXE名字中“X”的含义:
- 跨机器人形态 (Cross-Embodiment): 数据不仅来自常见的Franka Emika、UR5等七自由度机械臂,还包括Sawyer、KUKA臂、人形机器人手臂、甚至四足机器人等。
- 跨任务 (Cross-Task): 任务极其丰富,从简单的“拿起一个苹果”、“推开一个方块”,到复杂的“打开抽屉拿走杯子”、“将布丁倒入碗中”等。
- 跨环境 (Cross-Environment): 数据采集于全球不同的实验室,拥有不同的背景、光照、桌面和物体。
标准化的数据格式 (Robotics Library for Data Storage)
- 观测 (Observations): 机器人“看到”的,主要是RGB图像,有时也包括深度图、关节角度等本体感受信息。
- 动作 (Actions): 机器人“执行”的,即发送给机器人的控制指令(如末端执行器的位置、旋转、夹爪开合状态等)。
- 语言指令 (Language Instructions): 人类下达的任务指令,如“pick up the sponge”。
- 元数据 (Metadata): 描述任务的额外信息。
仿真环境数据集
虽然真实世界数据是黄金标准,但仿真环境因其低成本、高效率和绝对安全的特性,在数据收集中也扮演着重要角色。
代表工具:Isaac Gym, MuJoCo, SAPIEN
数据生成: 可以在仿真器中大规模、并行地生成各种任务的“专家”轨迹数据。
应用场景: 主要用于模型早期训练、算法验证和强化学习。
挑战: 核心挑战在于“Sim-to-Real Gap”(仿真到现实的鸿沟),在仿真中表现优异的模型,直接部署到真实机器人上时往往会“水土不服”。因此,当前的主流趋势是以真实数据为主,仿真数据为辅。
大规模人类视频数据集
为了让模型具备对物理世界更深层次的理解(即构建“世界模型”),有些研究者们会用海量的人类第一视角视频进行预训练。
代表项目:Ego4D, Something-Something V2, Epic Kitchens
数据内容: 这些数据集包含了数千小时的人类日常生活视频,覆盖了从烹饪、打扫到修理等各种活动。
核心思想: 模型通过观看这些视频,学习物体之间的交互关系、动作的先后顺序以及物理世界的动态变化规律,即使这些视频不包含任何机器人动作指令。
应用模型: GR-1和GR-2是该方法的典型代表。它们首先在Ego4D等数据集上进行生成式预训练(如预测下一帧视频),构建起强大的视觉动态预测能力,然后再用机器人数据集进行微调,将这种“世界理解”对齐到具体的机器人行动上。
评测
核心指标:任务成功率 (Success Rate, SR)
对于给定的语言指令,机器人在规定时间内完成任务即为“成功”,反之则为“失败”。这是一个二元(0或1)的评价。
计算方式: 成功次数 / 总尝试次数
评测场景:仿真 vs. 真实世界
仿真评测 (In-Sim Evaluation):
- 优点: 速度快、可大规模并行、成本低、无安全风险。非常适合进行模型迭代、超参数调优和消融实验。
- 缺点: 无法完全反映真实世界的复杂性(如光照变化、物理摩擦、物体形变等)。
真实世界评测 (Real-World Evaluation):
- 优点: 评测结果是检验模型实用性的“黄金标准”。
- 缺点: 速度慢、成本高、对硬件有损耗、存在安全风险。通常,只有在仿真中表现优异的模型才会被拿到真实机器人上进行最终验证。
泛化能力基准测试 (Generalization Benchmarks)
系统性地考察模型应对“未见过”场景的能力。
“见过”与“未见过” (Seen vs. Unseen)
- Seen: 在与训练数据完全相同的环境、物体和指令下进行测试,考察模型的记忆能力。
- Unseen: 在一个或多个维度上引入变化的测试,考察模型的泛化能力。
“未见过”的细分维度:
- 新颖物体 (Novel Objects): 指令模型操作一个在训练集中从未出现过的物体。例如,模型训练时只见过“拿起方块”,测试时要求它“拿起橡胶鸭”。
- 新颖任务/指令 (Novel Tasks/Instructions): 指令模型执行一个需要组合多种已知技能才能完成的新任务。例如,训练集中有“推开红色的碗”和“把积木放进蓝色的碗”,测试时要求“把积木放进红色的碗”。这考察了模型的组合泛化能力。
- 新颖环境 (Novel Environments): 在不同的背景、光照、桌面纹理下执行相同任务。这考察了模型的鲁棒性。
前置
VLA模型相对于VLM模型关键是额外预测了action,预测action可以多种方式,例如 MLP, AR, Diffusion, VAE, Flow Matching。
稍微介绍一下Flow Matching,学习初始分布与目标分布之间的 流场或流动路径,相对于Diffusion迭代次数更少。
- 噪声采样:从标准正态分布采样噪声ε∼N(0,I)
- 噪声动作构造:计算Aₜᵗ = τAₜ + (1-τ)ε
- 目标向量场:定义u(Aₜᵗ|Aₜ) = ε - Aₜ
- 网络训练:优化vθ(Aₜᵗ,oₜ)以匹配目标向量场
- 时间步采样:采用特殊设计的beta分布强调低τ值(高噪声水平)
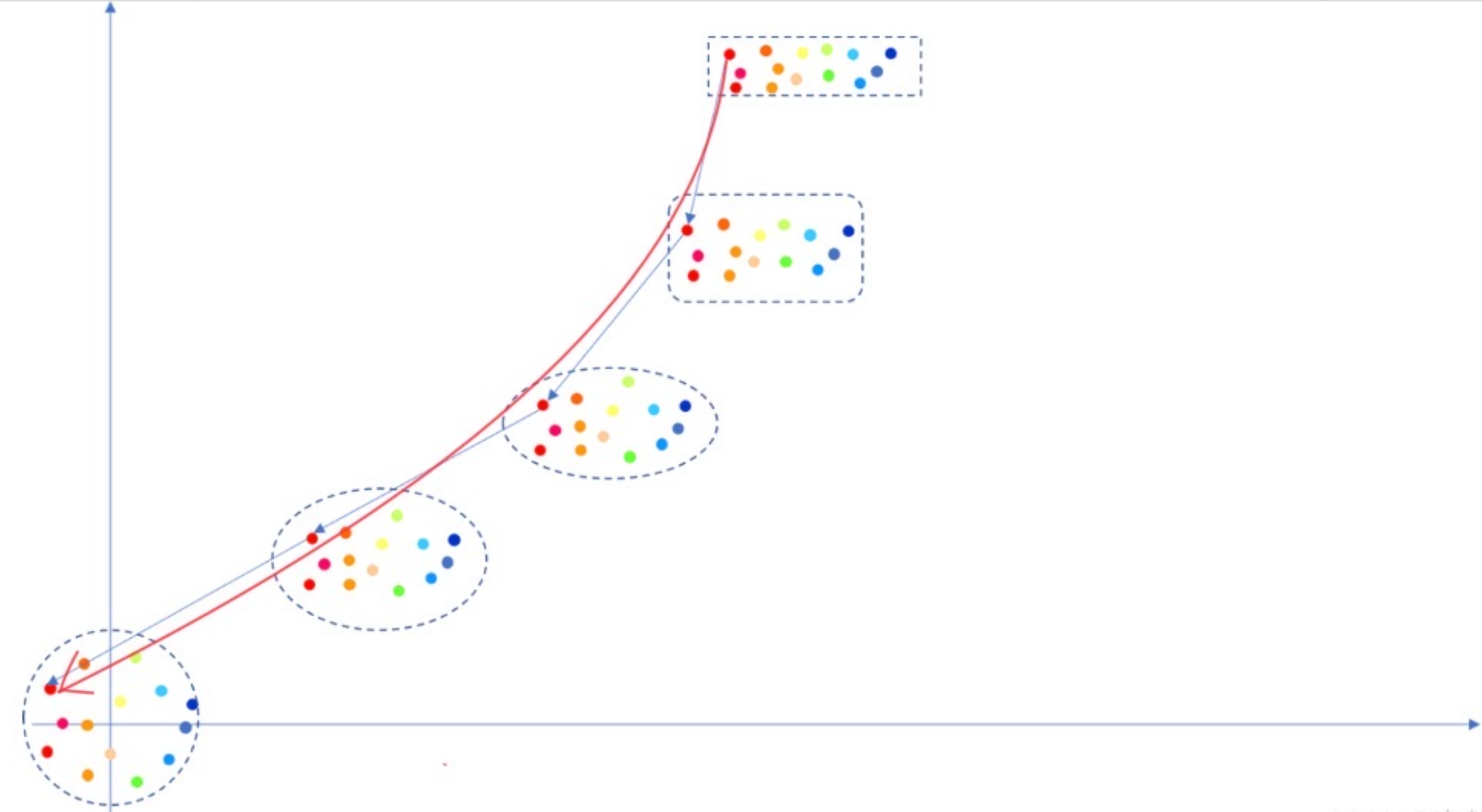
Flow Matching视角看Diffusion与Flow Matching
红色为Flow Matching的流动路径,浅色折线为Diffusion加噪过程的轨迹
更多信息参考:
SD3的采样上篇——Flow Matching - 上
SD3的采样上篇——Flow Matching - 下
https://zhuanlan.zhihu.com/p/704226398
| 特性 | cVAE | Diffusion Model | Flow Matching |
|---|---|---|---|
| 核心思想 | 编码-解码,压缩到隐空间再解压 | 迭代去噪,从纯噪声中恢复数据 | 学习向量场,沿直线路径从噪声流向数据 |
| 生成过程 | 单步前向传播 | 多步迭代(通常>100步) | 少步迭代(通常1-10步) |
| 采样速度 | 极快 (非常适合实时) | 极慢 (不适合高频控制) | 快 (速度与质量的极佳平衡) |
| 样本质量 | 一般 (可能模糊、过于平滑) | 极高 (细节丰富、非常自然) | 高 (媲美Diffusion) |
| 训练稳定性 | 稳定 | 非常稳定 | 非常稳定,且更直接 |
| 代表模型 | GR-2 | GR00T N1 | π0, π0.5 |
主流算法(关键里程碑)
| 时间 | 模型名称 | Paper | 机构/团队 | 简述 |
|---|---|---|---|---|
| 2022.12 | RT-1 | link | Google Robotics | 基于Transformer的机器人控制模型,利用真实数据+仿真数据,初步实现GPT-Like Robotics控制。 |
| 2023.07 | RT-2 | link | Google DeepMind | RT-1的演进,引入互联网络WebData与真实数据CoFinetune更大55B VLM模型,提升Zero-shot泛化能力。 |
| 2023.12 | GR-1 | link | Bytedance | 提出视频生成辅助训练任务,输入语言+图像序列,输出动作+未来图像序列。 |
| 2024.06 | OpenVLA | link | Stanford, UC Berkeley | 开源VLA模型,基于LLaMA-2和SigCLIP对齐视觉特征,RT-2的开源平替。 |
| 2024.10 | GR-2 | link | Bytedance | GR1的扩展,增加更多视频预训练数据,MLP升级为cVAE action预测。 |
| 2024.10 | π0 | link | Physical Intelligence | VLM预测模型 + 真实数据Finetune,action使用Expert + Flow Matching生成。 |
| 2025.02 | Helix | link | Figure AI | 较早在人形机器上提出双系统架构(S1快系统 + S2慢系统),专注于人形机器人控制。 |
| 2025.03 | GR00T N1 | link | Nvidia | 也是双系统模型,开源的通用人形机器人基座模型,使用WebData、仿真数据及真实机器人数据三类混合训练,Diffusion生成action。 |
| 2025.04 | π0.5 | link | Physical Intelligence | π0的改进版,优化预训练数据量与训练方式,后训练增加low level action过度,实验证明长程及灵巧操作泛化性提升。 |
架构图
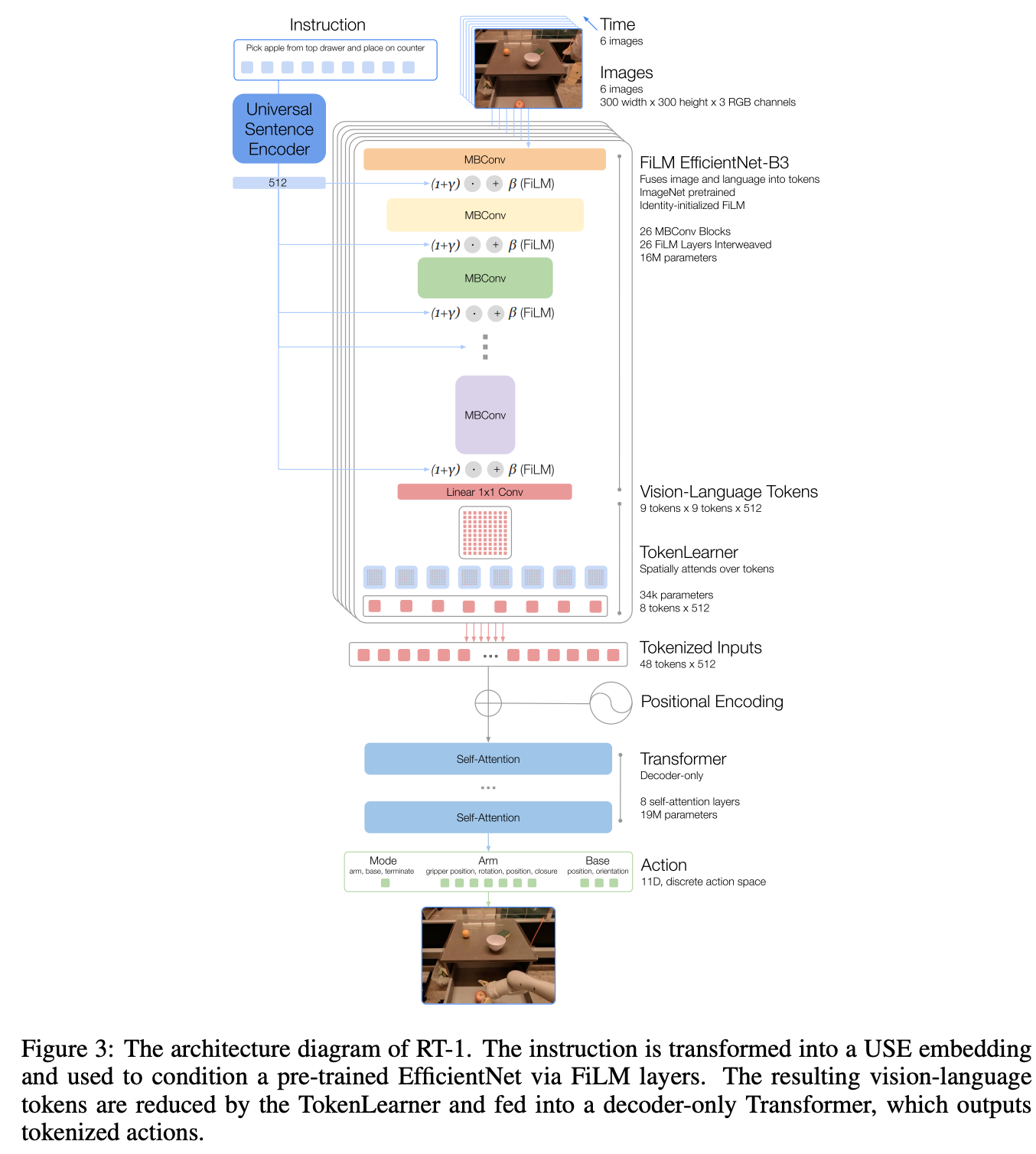
RT-1
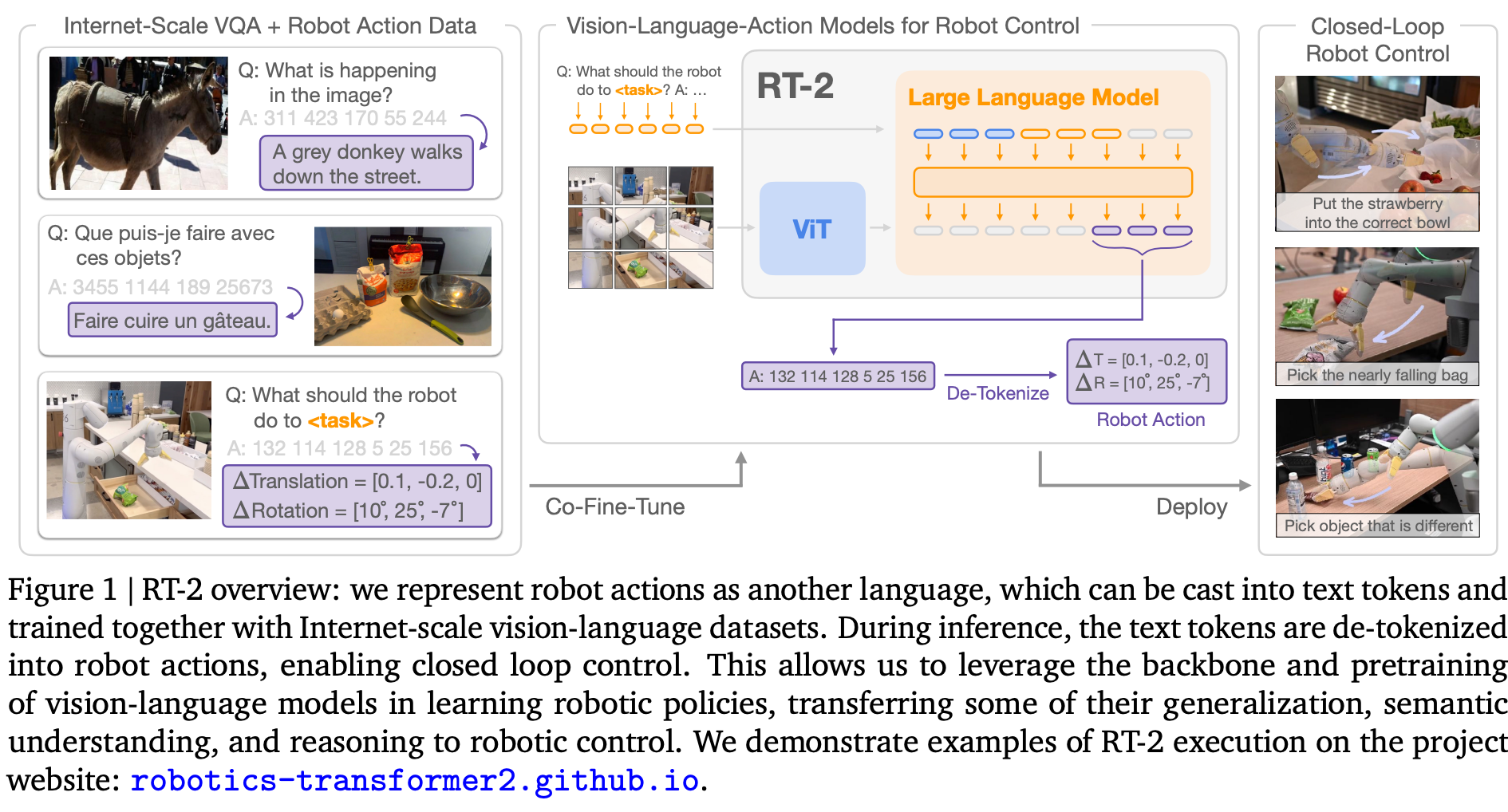
RT-2
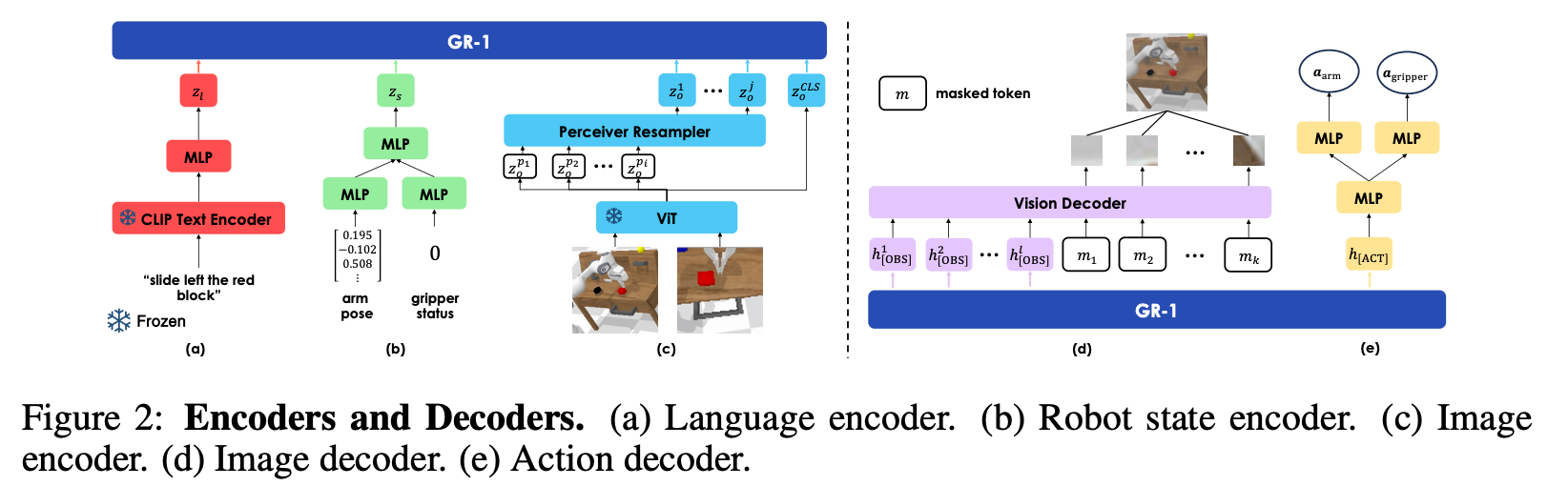
RG-1
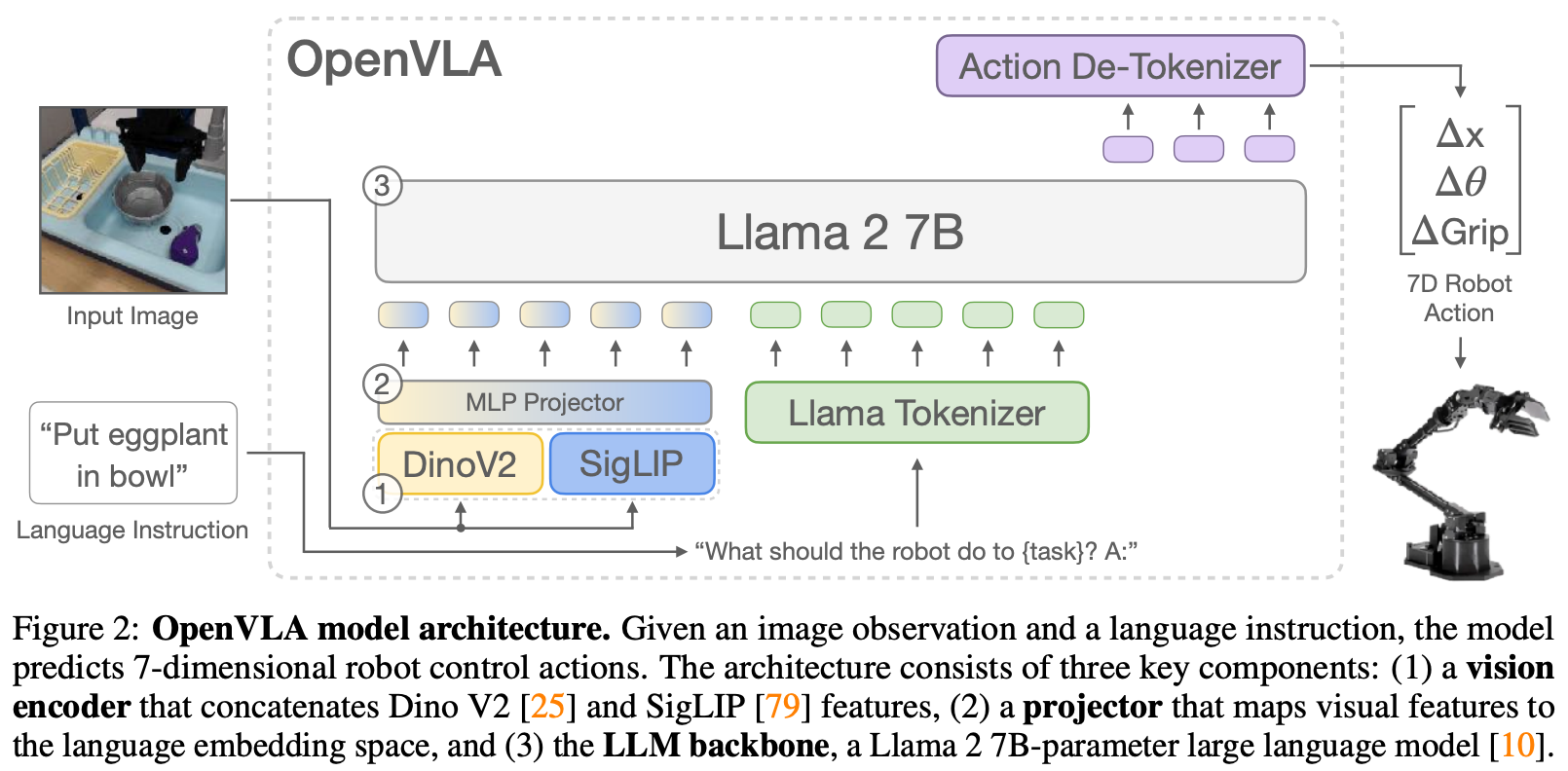
OpenVLA
GR-2

π0
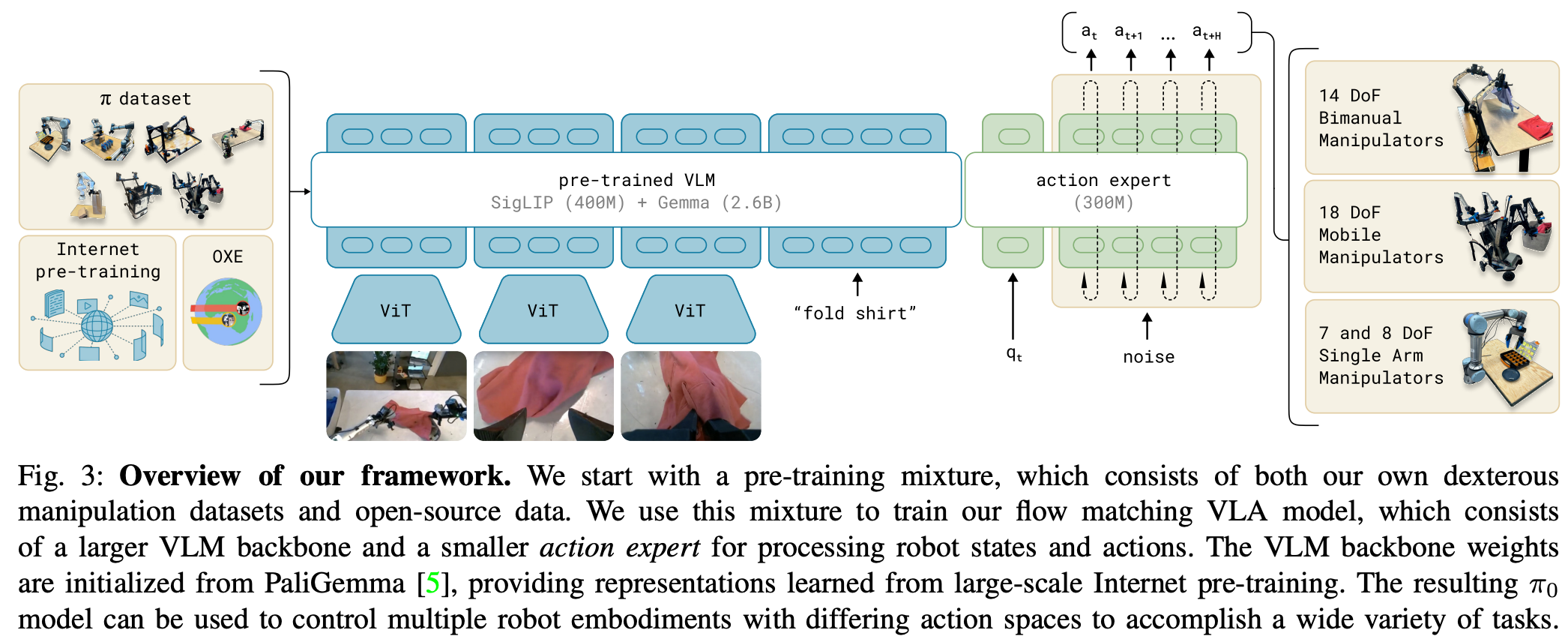
Helix
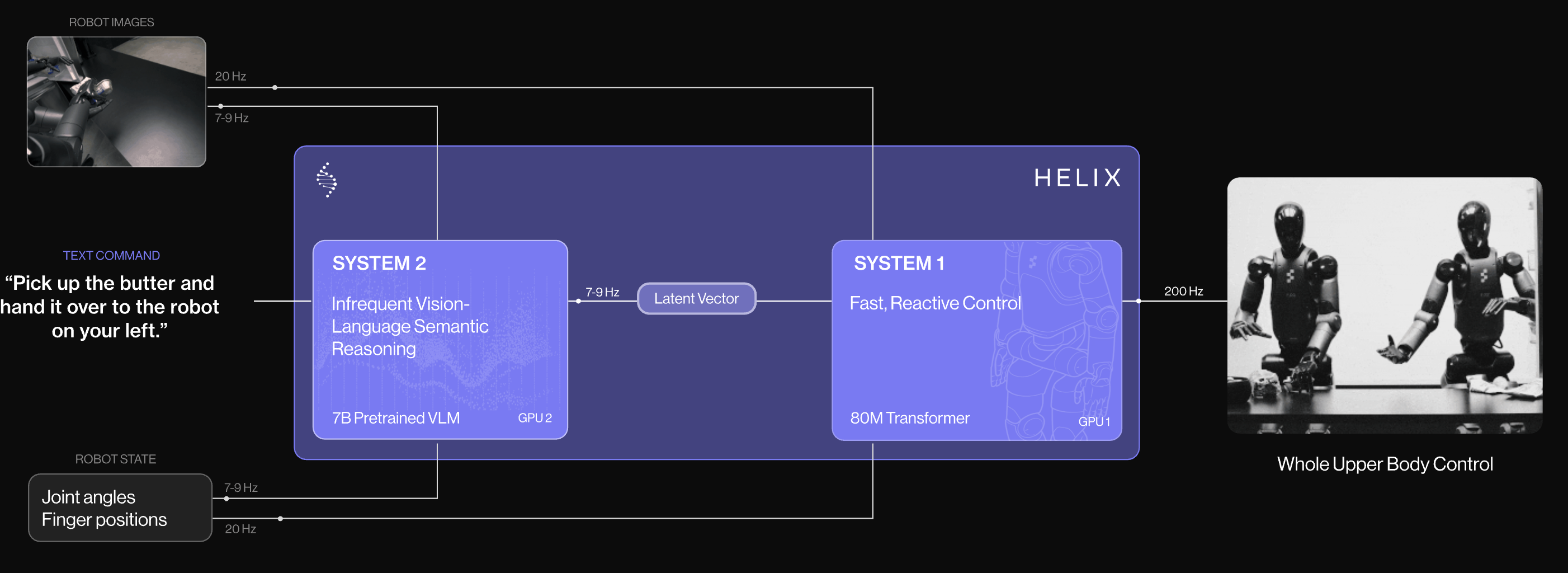
GR00TN1
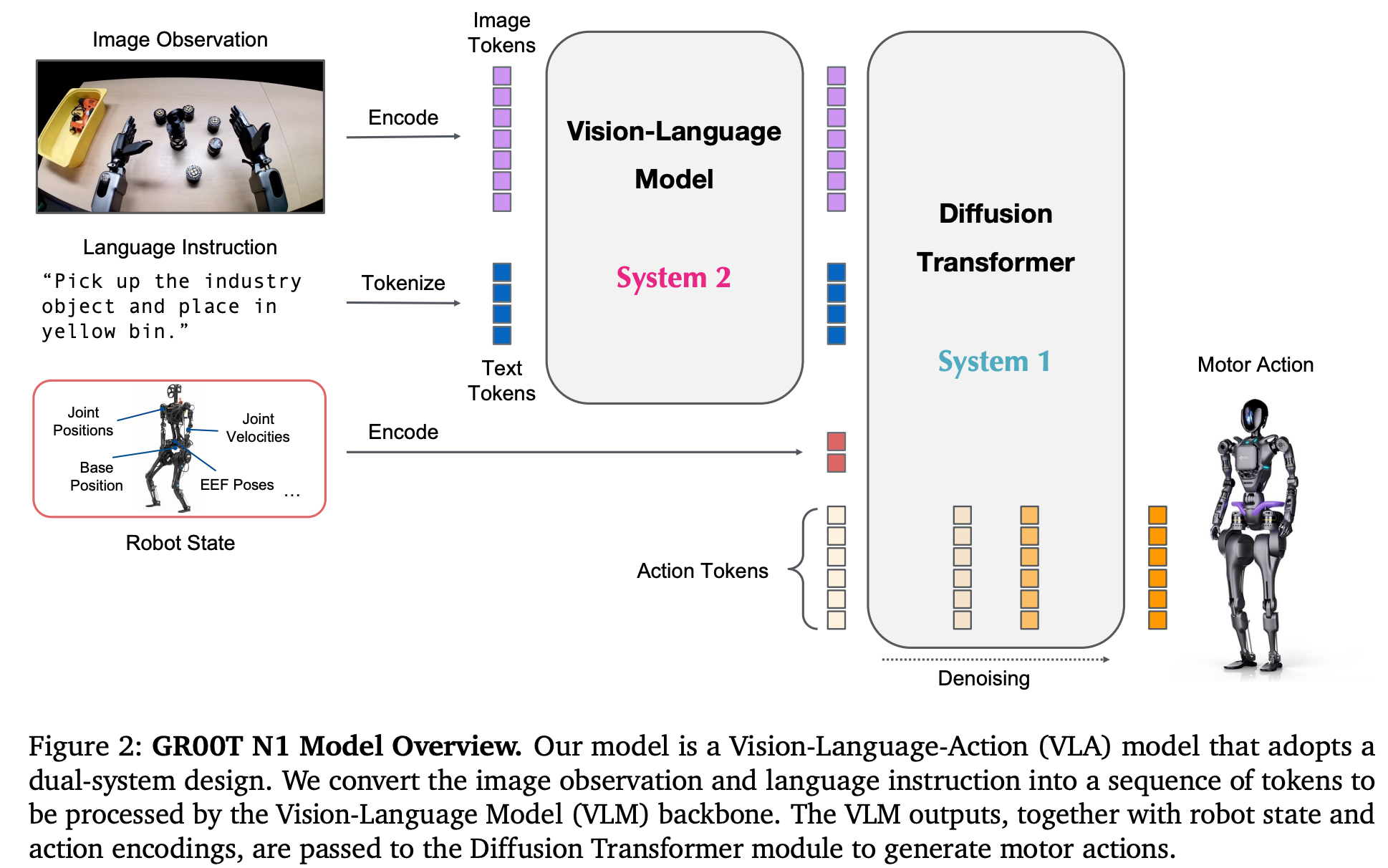
π0.5
不同系列的本质差异
| 维度 | RT系列/OpenVLA | GR系列 | π系列 | Helix | GR00T-N1 |
|---|---|---|---|---|---|
| 核心架构 | GPT-Like | 视频生成辅助任务 | VLM + Flow Matching | 快慢双系统 | 快慢双系统 |
| 动作预测 | AR生成action离散化bins token | MLP/cVAE生成动作序列(+未来帧生成) | 概率流匹配生成动作序列 | 200hz快系统MLP预测当前帧 | Diffusion生成动作序列 |
| 训练数据 | 大规模遥操机器人轨迹 | 视频数据集(如Ego4D)+ 机器人数据 | 遥操机器人轨迹 + 开放场景数据 | 互联网数据 + 遥操机器人轨迹 | 互联网数据 + 仿真数据 + 遥操机器人轨迹 |
| 本质差异 | 知识迁移驱动:利用Web知识提升泛化。 | 世界模型:视频预测作为动作基础。 | 利用多模态能力提升泛化性 | 快慢系统分工提升泛化性 | 快慢系统分工提升泛化性 |
相关链接
本文来自博客园,作者:fariver,转载请注明原文链接:https://www.cnblogs.com/fariver/p/19034605

 浙公网安备 33010602011771号
浙公网安备 33010602011771号