[PaperReading] π0: A Vision-Language-Action Flow Model for General Robot Control
π0: A Vision-Language-Action Flow Model for General Robot Control
link
时间:24.10
单位:Physical Intelligence
相关领域:Robotics
作者相关工作:https://www.physicalintelligence.company/
被引次数:8
项目主页:https://www.physicalintelligence.company/research/knowledge_insulation
TL;DR
本工作提出一种flow matching架构,该方法以大量互联网VLM预训练模型为基座,并在大量丰富的多种机器人数据进行Finetune,测试结果显存其在叠衣服、擦桌子以及折箱子等任务上都有较好的表现。
Method
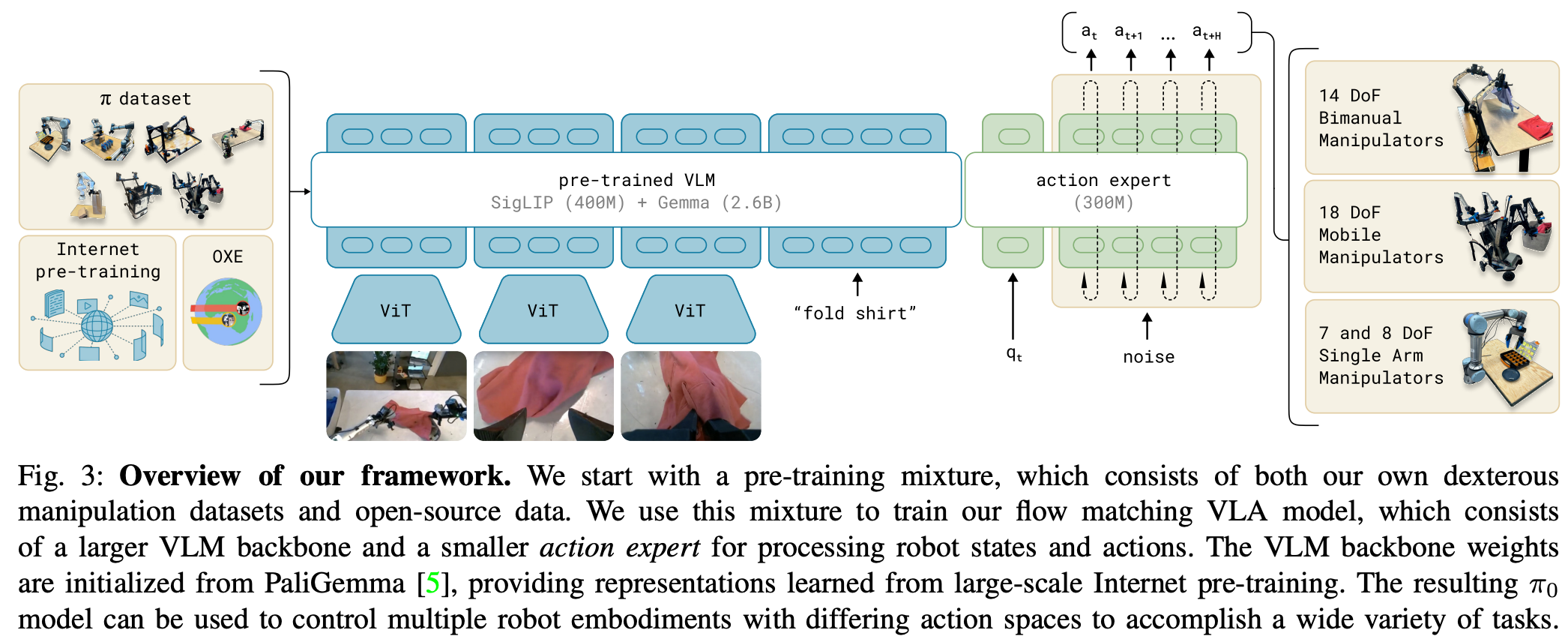
PaliGemma VLM基座模型
PaliGemma是π₀采用的视觉语言模型基础:
- 参数规模:30亿参数的开源VLM,在大小和性能间取得平衡
- 架构特点:采用标准late-fusion VLM设计,图像编码器将视觉观察嵌入到与语言token相同的嵌入空间
- 扩展性:π₀在PaliGemma基础上增加了3亿参数的action expert,总参数达33亿
- 灵活性:虽然π₀使用PaliGemma,但框架兼容任何预训练的VLM骨干
VLA多模态的对齐机制
π₀采用late-fusion VLM方案实现视觉语言对齐:
- 统一嵌入空间:图像Iₜⁱ和状态qₜ通过编码器投影到与语言token相同的嵌入空间
The images \(I_t\) and state \(q_t\) are encoded via corresponding encoders and then projected via a linear projection layer into the same embedding space as the language tokens.
- 双向注意力:视觉和语言token通过transformer的自注意力机制交互
- 机器人扩展:在PaliGemma VLM基础上增加了机器人专用的状态和动作token处理通路
与Transfusion的联系
π₀的架构设计受到Transfusion的启发,但进行了重要改进:
- 多目标训练:类似Transfusion使用单个transformer处理连续(flow matching)和离散(交叉熵)输出
- 权重分离:π₀为机器人专用token(动作和状态)使用独立的权重集,形成类似混合专家的结构
- 性能提升:相比Transfusion,这种分离设计带来了性能提升
- 应用领域:Transfusion主要用于图像生成,而π₀将其概念扩展到机器人动作生成
Flow Matching生成如何在本文所介绍的VLA模型中应用的?
训练过程细节
- 噪声采样:从标准正态分布采样噪声ε∼N(0,I)
- 噪声动作构造:计算Aₜᵗ = τAₜ + (1-τ)ε
- 目标向量场:定义u(Aₜᵗ|Aₜ) = ε - Aₜ
- 网络训练:优化vθ(Aₜᵗ,oₜ)以匹配目标向量场
- 时间步采样:采用特殊设计的beta分布强调低τ值(高噪声水平)
推理流程
- π₀的推理过程采用高效的前向欧拉积分:
- 初始化:从Aₜ⁰∼N(0,I)开始
- 迭代更新:Atτ+δ=Atτ+δvθ(Atτ,ot)
- 步长控制:使用δ=0.1,共10个整合步骤
- 缓存优化:缓存观察token的键值,仅更新动作token
与模型架构的集成
π₀将Flow Matching与VLM骨干网络通过以下方式深度整合:
- 专用权重:为动作token使用独立的"action expert"权重
- 注意力机制:动作token间使用全双向注意力
- 时间步融合:通过MLP将τ时间步信息注入网络
- 多模态输入:视觉、语言和本体状态共同条件化动作生成
DATA COLLECTION AND TRAINING RECIPE

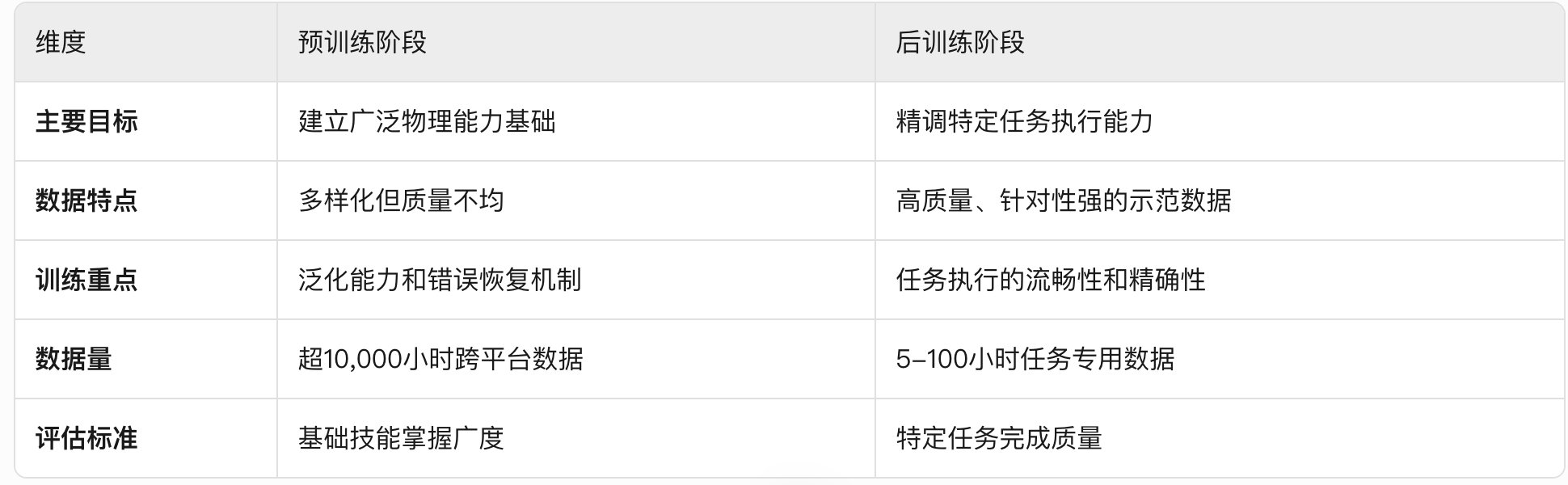
pre-train与post-train阶段目标与数据有什么区别?
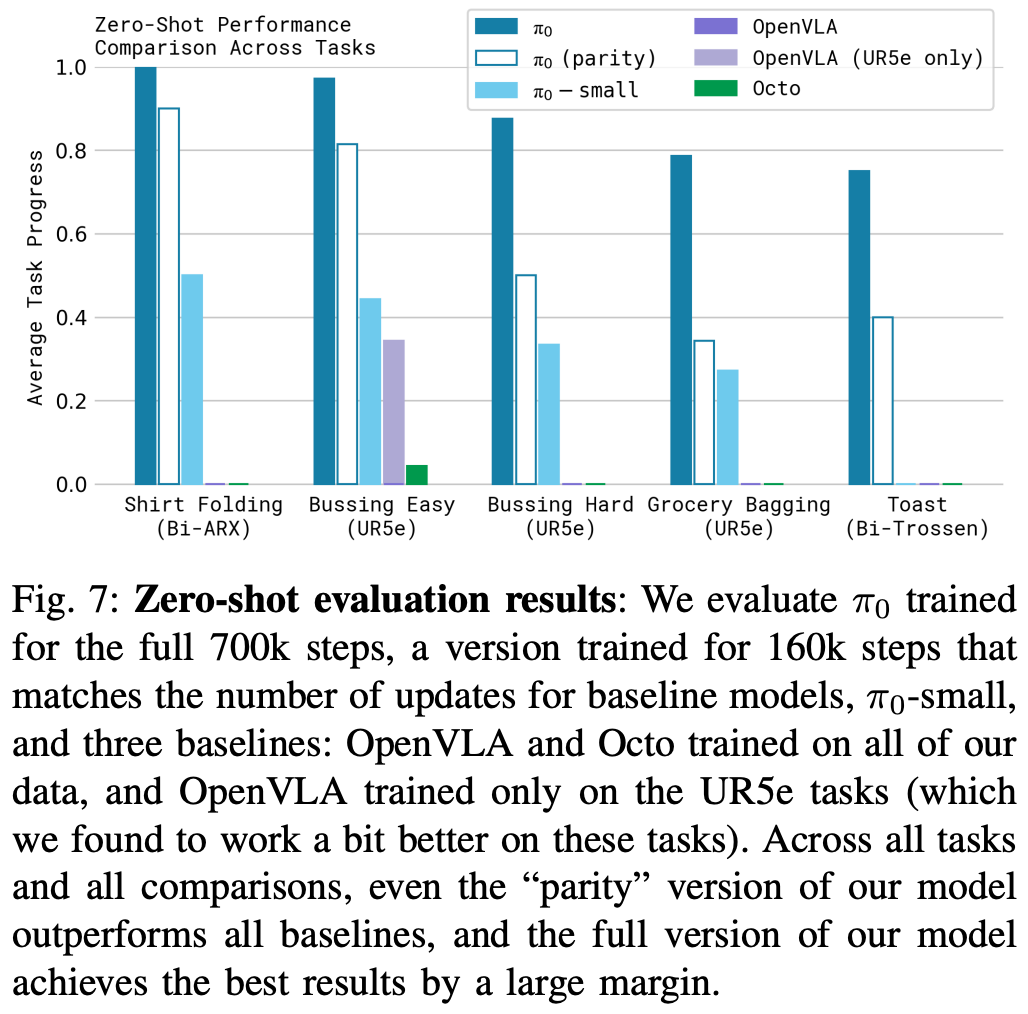
Experiment
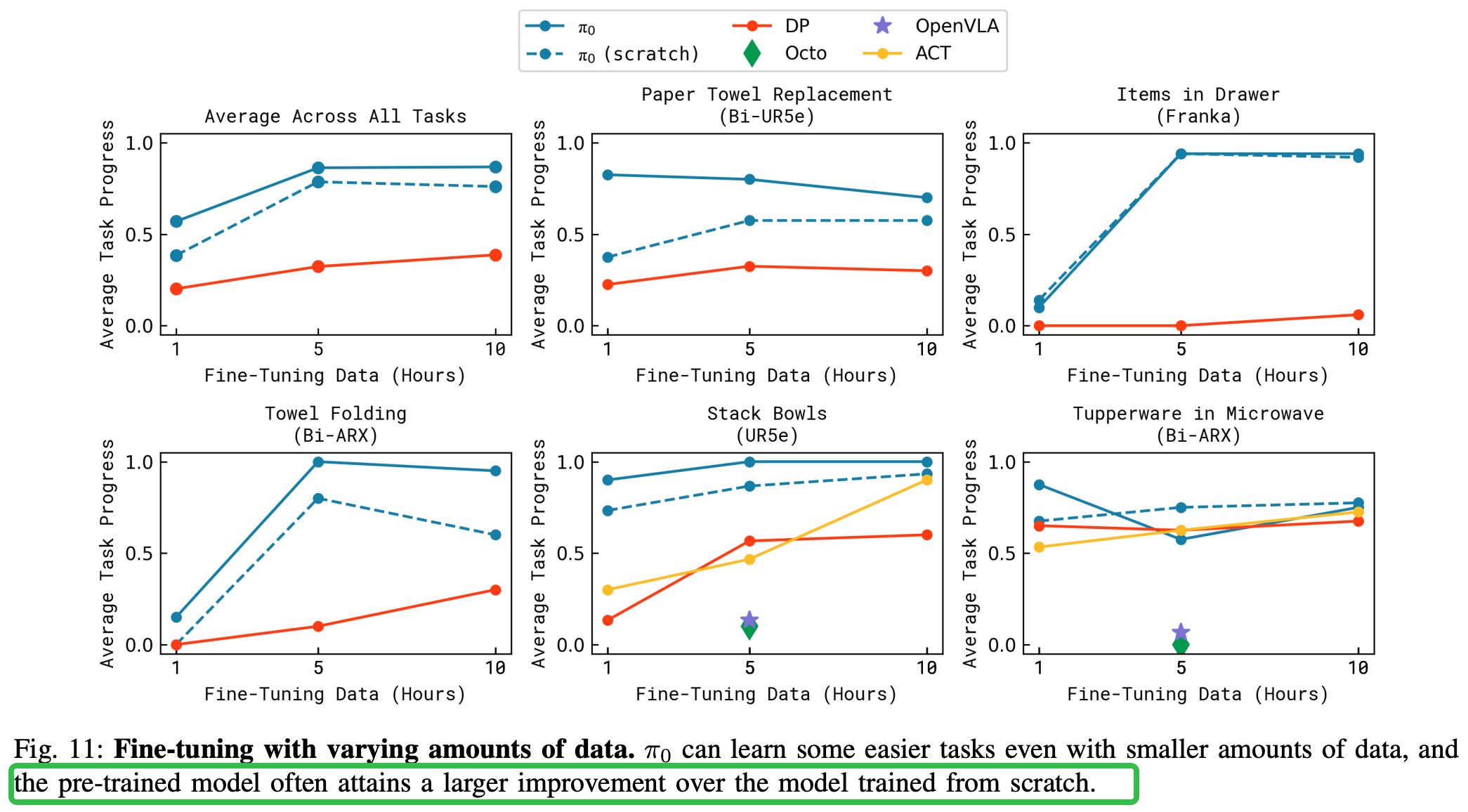
效果可视化

总结与思考
无
相关链接
https://zhuanlan.zhihu.com/p/5150857138
资料查询
Flow Matching与Diffusion的总体比较
Flow Matching和Diffusion同属于生成模型家族,但在实现原理和应用特性上有显著差异:

本文来自博客园,作者:fariver,转载请注明原文链接:https://www.cnblogs.com/fariver/p/19029275

 浙公网安备 33010602011771号
浙公网安备 33010602011771号