[PaperReading] π0.5: a Vision-Language-Action Model with Open-World Generalization
目录
π0.5: a Vision-Language-Action Model with Open-World Generalization
link
时间:25.04
单位:Google
相关领域:Robotics、Multimodal
项目主页:
https://www.pi.website/blog/pi05
TL;DR
相对于\(\pi_0\)主要提升数据丰富性,包括 多种机器人、高级语义预测、互联网数据。同时使用co-training的方式将图像、语言指标、目标检测与分割等多种任务组合在一起,提升泛化性。实验证明\(\pi_{0.5}\)具有好的长程及灵巧操作泛化性。
Method
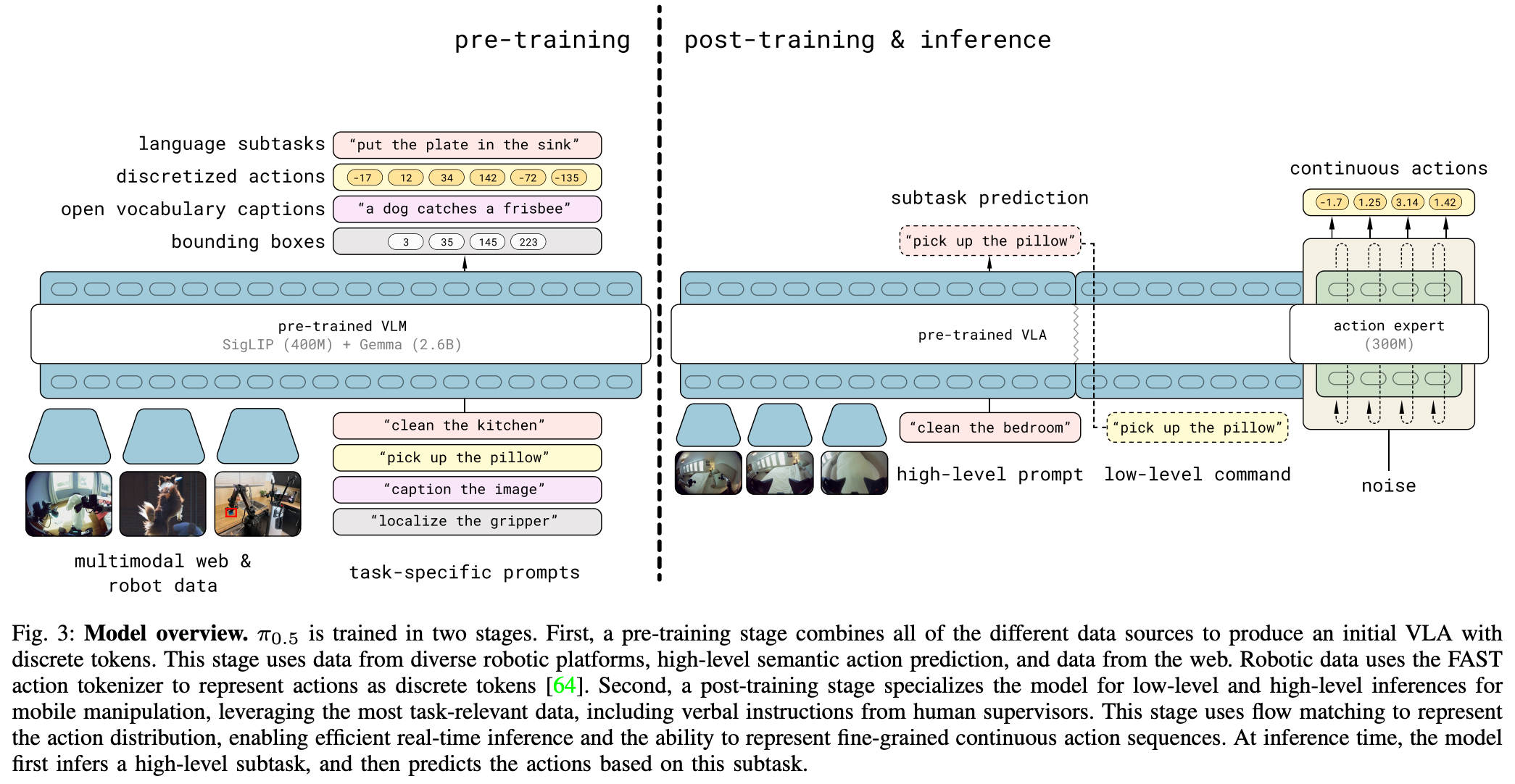
模型通过统一架构同时支持动作块分布和文本输出,其概率分布可表示为:
![]()
先推理出 高层任务类型\(\hat{l}\)(如"拿起盘子"),再根据 高层任务类型以及观测信息 使用action expert的flow matching推理出具体的控制信号序列
- \(o_t\):多摄像头图像+机器人关节状态
- \(l\):用户任务指令(如"收拾餐具")
- \(\hat{l}\):模型输出的语义子任务类型(如"拿起盘子")
Training Recipe
预训练:使用离散令牌(discrete tokens)方式预测动作,训练更高效
后训练:使用流匹配(discrete tokens)方式预测动作,提高控制精度
Data
Pretraining数据混合策略:
- 移动操作数据(MM, Mobile Manipulator):400小时家庭环境任务数据
- 多环境静态机器人(ME, Multi-Environment):轻量机械臂采集的多样化场景数据
- 实验室跨本体数据(CE, Cross-Embodiment):包含OXE数据集的双臂/移动平台数据
- 高级子任务标注(HL, High-Level):人工标注的语义步骤(如"调整毯子")
- 网络多模态数据(WD, Web Data):图像描述/问答/物体定位数据

硬件配置
- 四摄像头系统(腕部/前后视角)
- 自由度分布如下
![image]()


Experiment
相对于\(\pi_0\)还是提升了不少
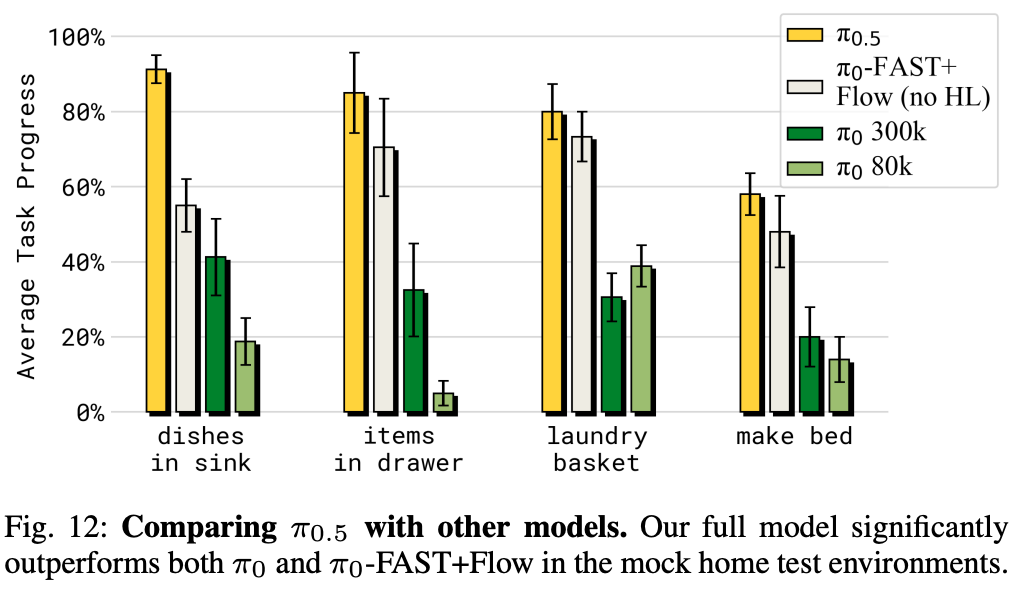
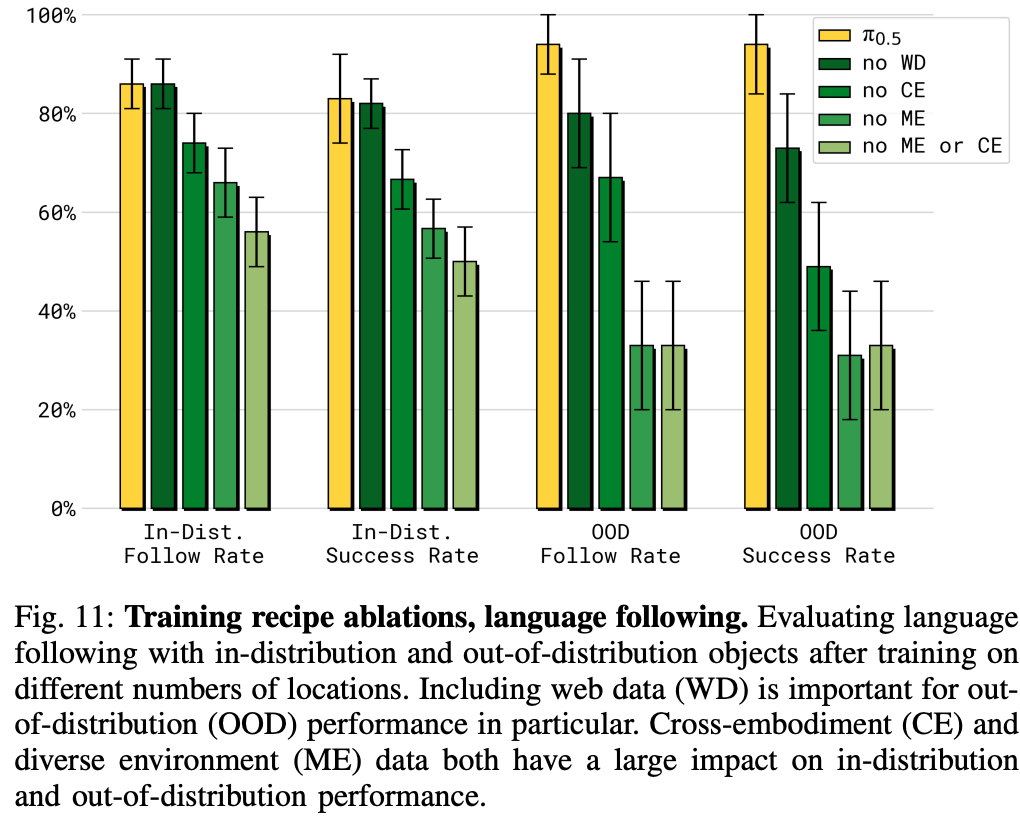
效果可视化
https://website.pi-asset.com/pi0_5/PiV9_320.mp4
总结与思考
无
相关链接
与\(\pi0\)的差异 以及关键问题,参考
cool paper: https://papers.cool/arxiv/2504.16054
本文来自博客园,作者:fariver,转载请注明原文链接:https://www.cnblogs.com/fariver/p/19042372

 浙公网安备 33010602011771号
浙公网安备 33010602011771号