[PaperReading] GR00T N1: An Open Foundation Model for Generalist Humanoid Robots
GR00T N1: An Open Foundation Model for Generalist Humanoid Robots
link
时间:25.03
单位:NVIDIA
相关领域:Robots
被引次数:6
项目主页:
https://github.com/NVIDIA/Isaac-GR00T
TL;DR
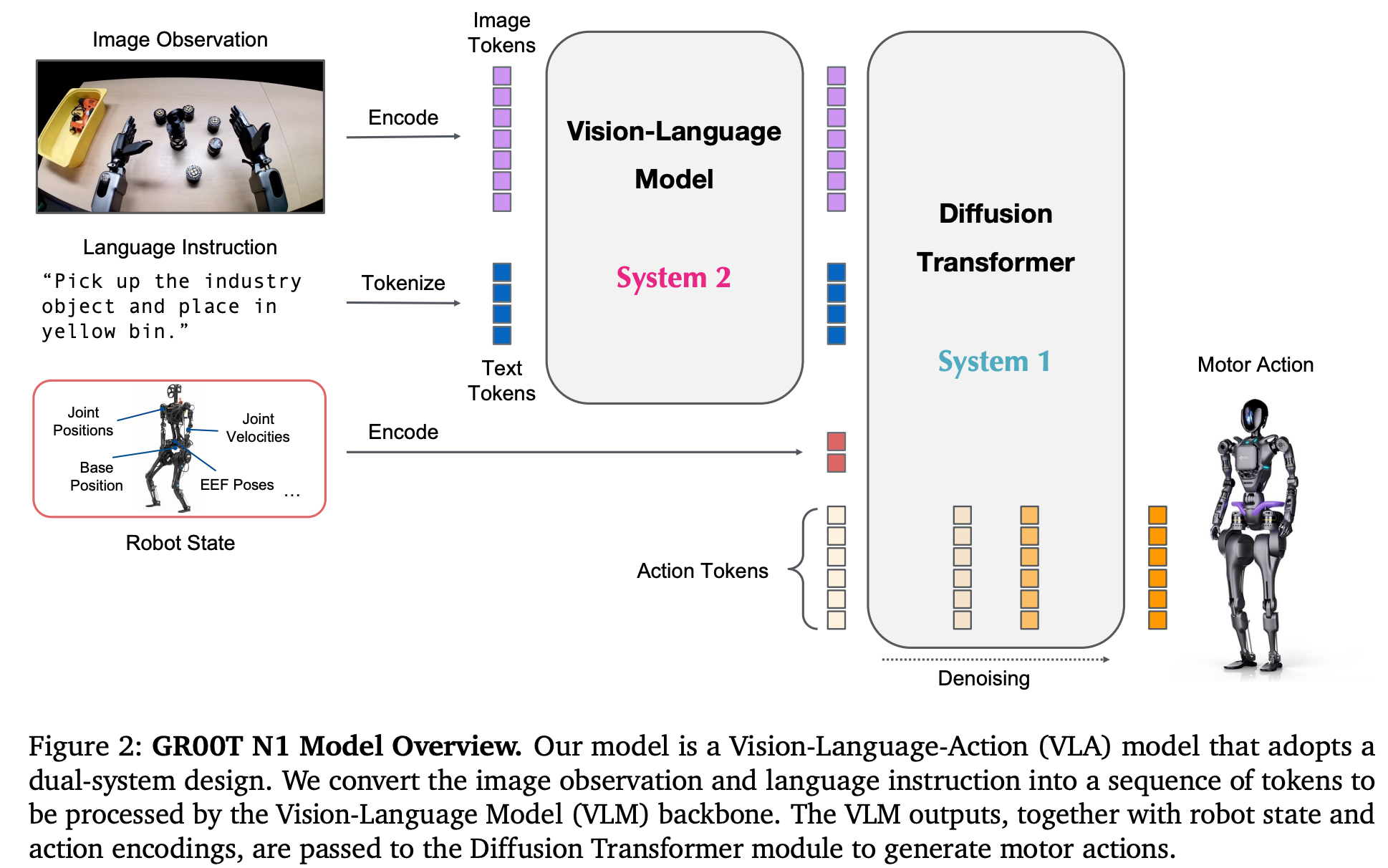
提出一个名为GR00T N1的双系统Fundation Model,Vision Language模块(System2)理解环境中的视频与语言指令,diffusion transformer模块(System1)实时生成action控制信号。模型是端到端在机器人轨迹数据、人类视频 以及 生成数据上训练而来。该模型在仿真测试集上被证明超过多个机器人本体,同时在Fourier GR-1实体机器人的双手操作任务上也被证明有很好的效果。
Method
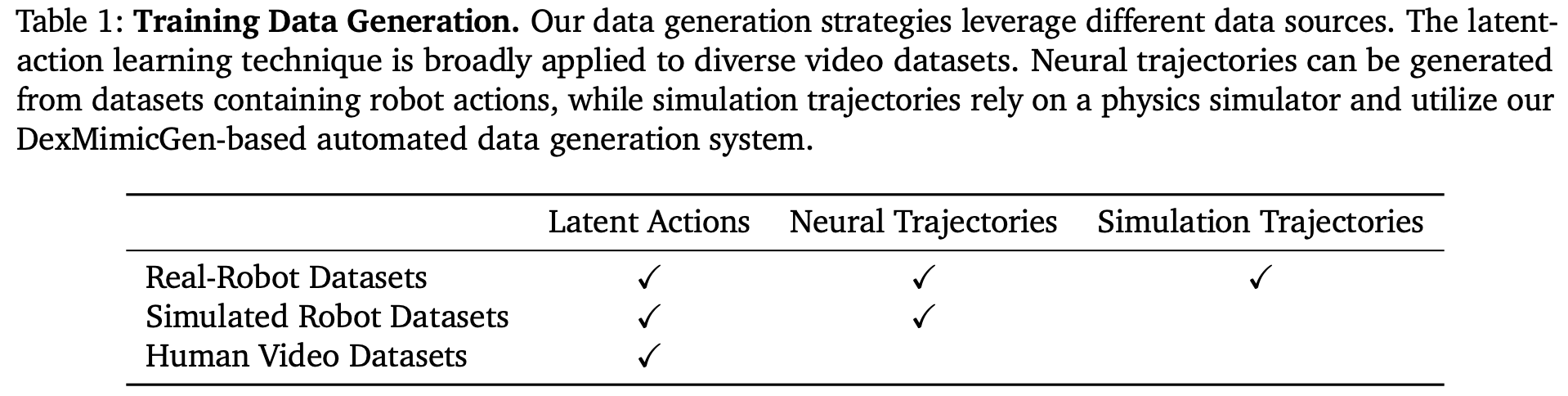
pretraining: 使用三类数据预训练 human videos, simulation and neuralgenerated data, and real robot demonstrations
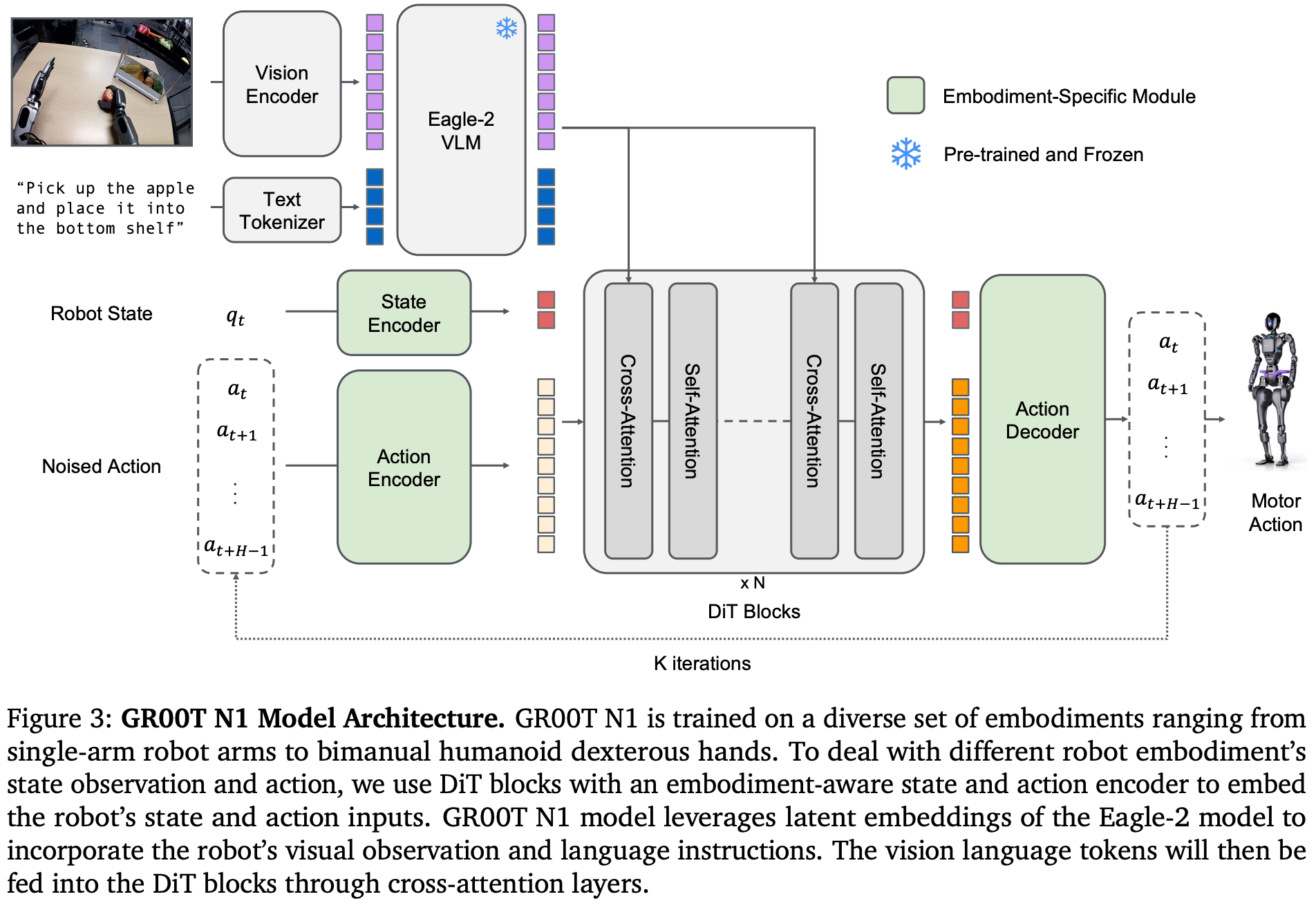
模型Size: GR00T-N1-2B Fundation模型有2.2B参数量,其中NVIDIA Eagle-2 VLM多模态模型有1.34B参数量,剩余0.86B参数量在System1。
System2
10Hz运行
System1
120hz运行
使用Flow-Matching的方式预测action,类似于Diffusion只不过加噪与去噪模型不同。
训练:
噪声注入:\(Aₜᵏ = τAₜ + (1-τ)ε\), 其中\(ε∼N(0,I)\)
损失函数:\(ℒ_fn(θ)=E_τ[‖V_θ(φₜ,Aₜᵏ,qₜ)-(ε-Aₜ)‖²]\)
时间步分布:\(p(τ)=Beta((s-τ)/s;1.5,1), s=0.999\)
推理:
4步去噪:采用Aₜᵏ⁺¹ᴷ = Aₜᵏ + (1/K)V_θ(...)的欧拉积分
跨注意力机制:DiT块交替使用:
自注意力:处理噪声动作和状态嵌入
跨注意力:融合VLM的φₜ特征
Training Setting
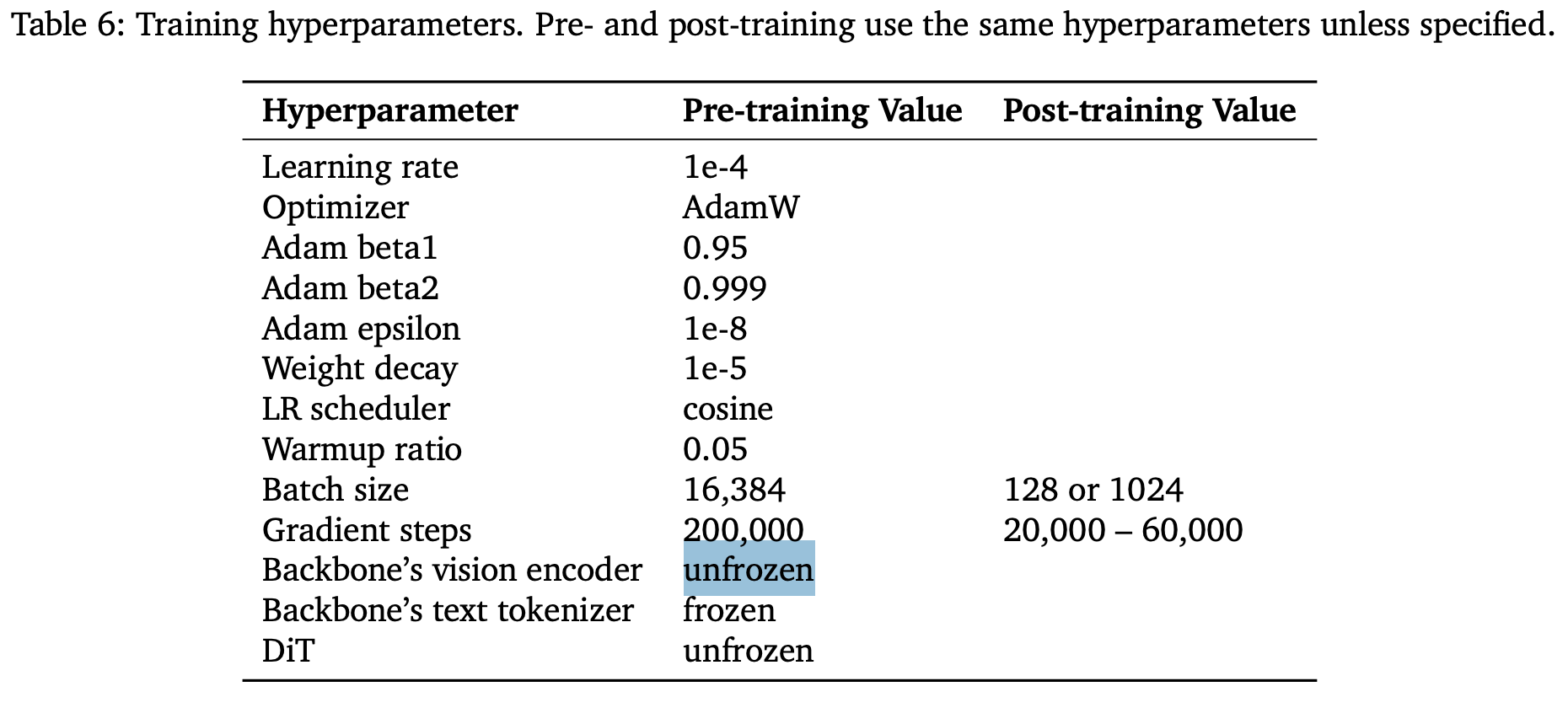
无论Pretrain还是Posttrain,都是Freeze Text Encoder,其余参数放开训练。
Data
数据金字塔

human video数据pretrain方法
LADA: Latent Action Dynamics Alignment
IDM: Inverse Dynamics Model -> 从latent feature生成伪动作
编码器设计:
输入:当前帧xₜ和未来帧\(x_{t+H}\)组成的图像对
输出:连续潜在向量zₜ ∈ ℝᵈ
解码器设计:
输入:潜在动作zₜ和当前帧xₜ
输出:重建的未来帧\(x_{t+H}\)
使用这些latent action作为flow-matching的action target
神经轨迹生成流程
模型微调:
基于WAN2.1-I2V-14B视频生成模型
使用LoRA适配器在81帧480P机器人数据上微调
生成控制:
输入:初始帧 + 语言指令(如"pick up the red apple")
输出:合成视频轨迹
仿真轨迹生成方法
在物理引擎中(如DexMimicGen系统)通过算法自动生成的机器人运动
输入:少量人类演示(数十个)
处理流程:
- 分割演示为对象中心的子任务段
- 根据新场景中的物体位置自适应调整轨迹
- 通过插值确保运动连续性
规模扩展:
- 自动生成54种源-目标容器组合
- 每种组合生成10,000条演示
- 总计540,000条仿真轨迹(≈6,500小时)
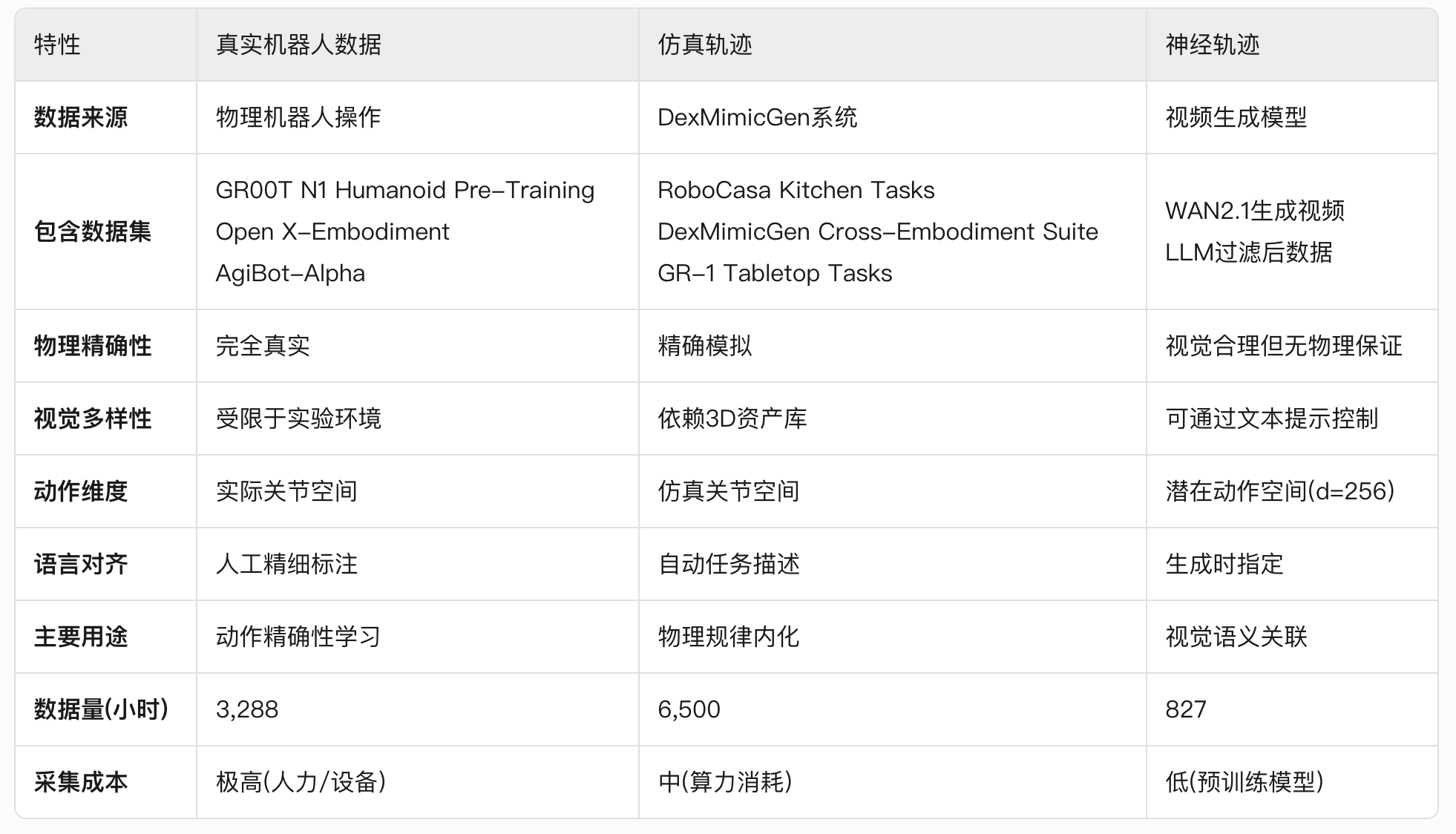
部分训练数据可视化

Experiment
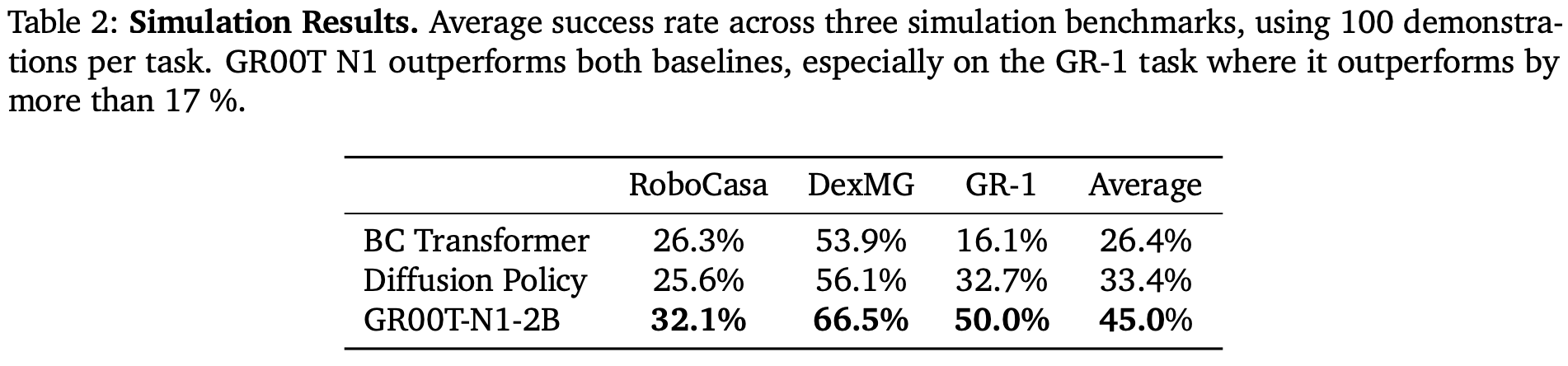
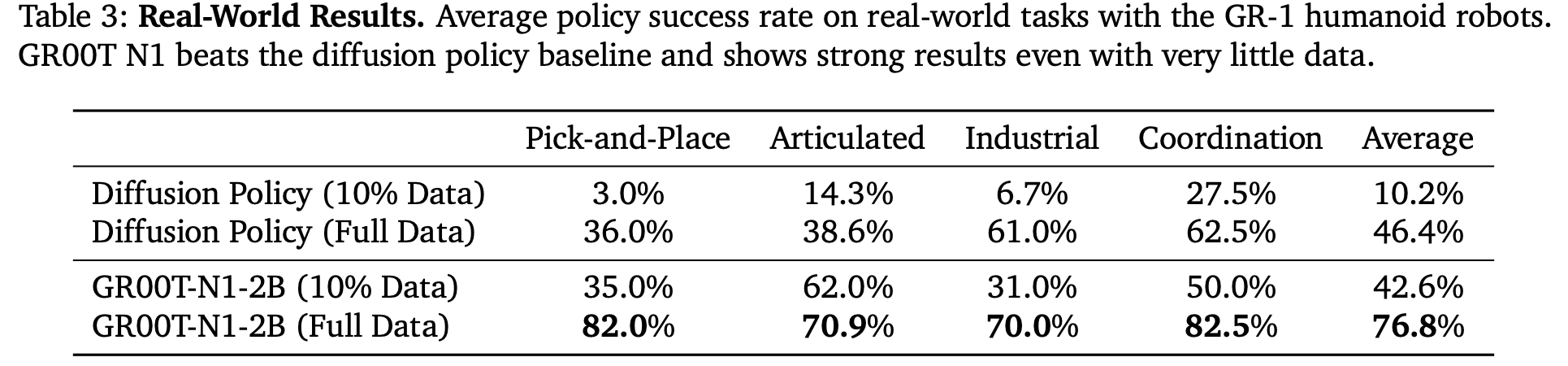
LADA: Latent Action Dynamics Alignment
IDM: Inverse Dynamics Model -> 从latent feature生成伪动作
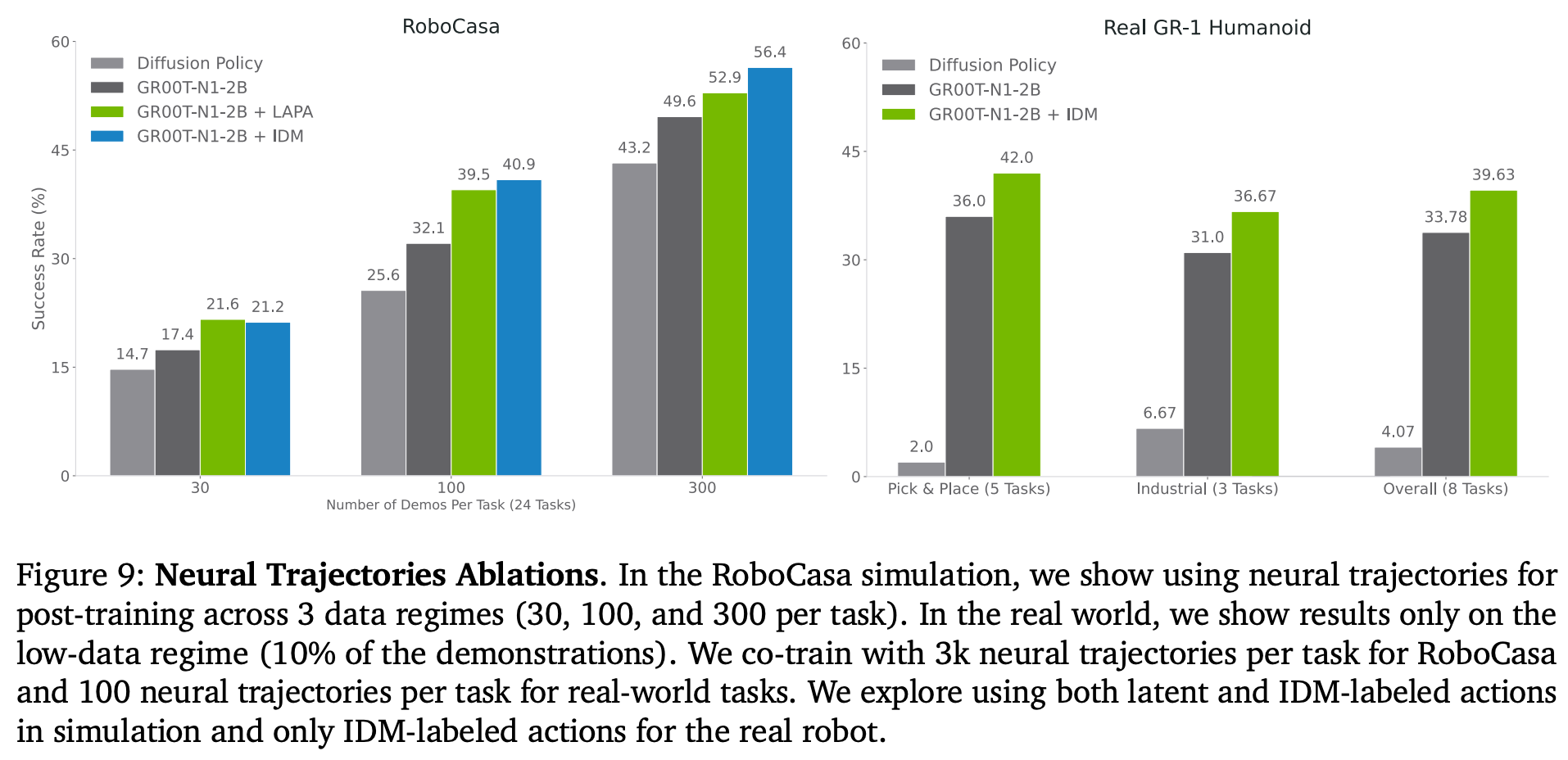
效果可视化

总结与思考
暂无
相关链接
cool paper链接:https://papers.cool/
https://zhuanlan.zhihu.com/p/1915178980568446515
nvidia官方在B站的宣讲视频
本文来自博客园,作者:fariver,转载请注明原文链接:https://www.cnblogs.com/fariver/p/19038674

 浙公网安备 33010602011771号
浙公网安备 33010602011771号