[PaperReading] GR-1: UNLEASHING LARGE-SCALE VIDEO GENERATIVE PRE-TRAINING FOR VISUAL ROBOT MANIPULATION
目录
UNLEASHING LARGE-SCALE VIDEO GENERATIVE PRE-TRAINING FOR VISUAL ROBOT MANIPULATION
link
时间:23.12
单位:Bytedance
相关领域:Robotics
作者相关工作:https://scholar.google.com/citations?user=7u0TYgIAAAAJ&hl=en&oi=sra
被引次数:132
项目主页:https://gr1-manipulation.github.io/
TL;DR
首先将GPT的范示应用于机器人操控,输入:语言指令、观测图片序列、机器人状态序列,输出:机器动作、未来图片序列。在CALVIN benchmark上,成功率从88.9%提升至94.9%。泛化性方面,在未见过场景上,成功率53.3%提升至85.4%。
Method
整体Framework
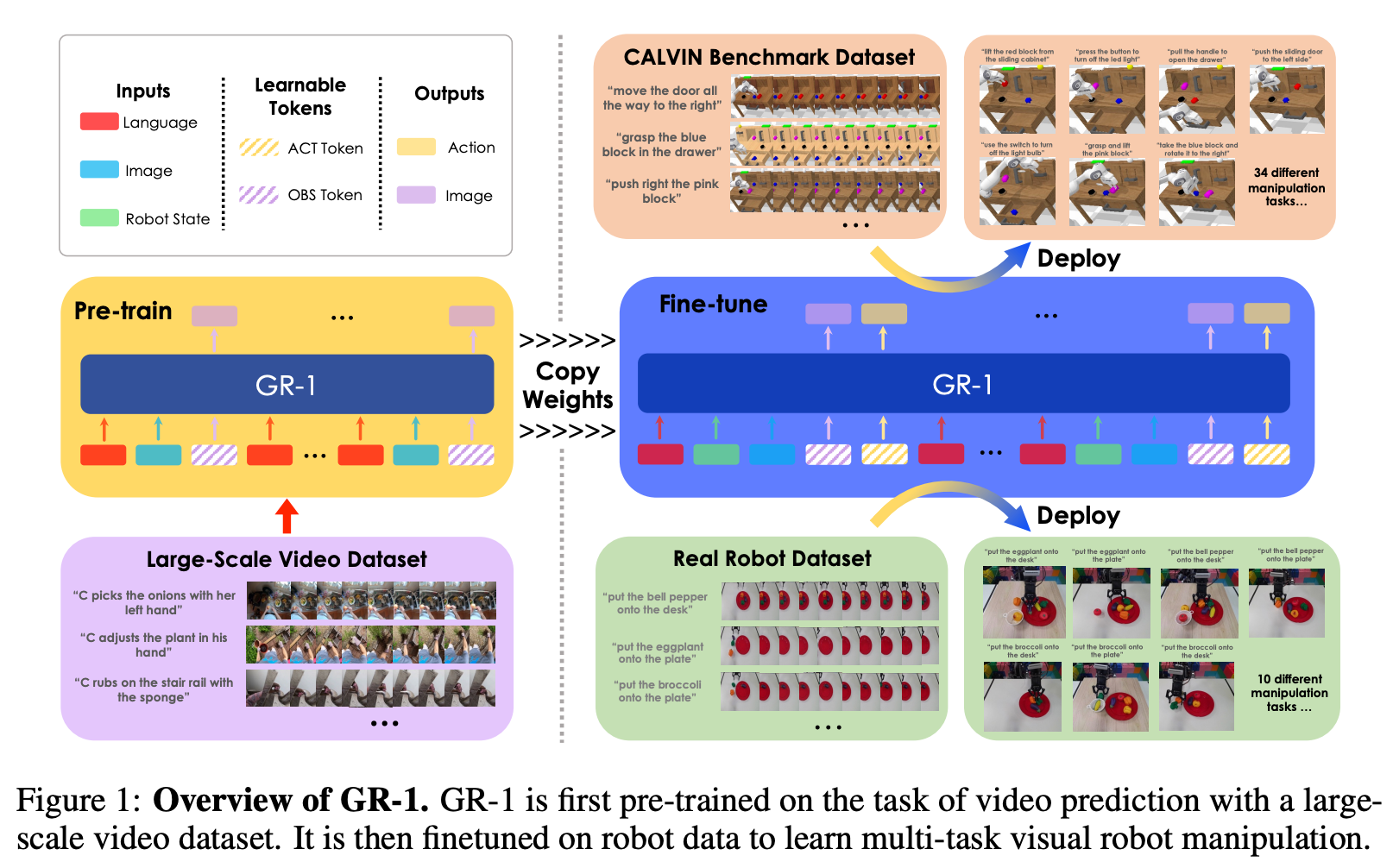
模型Framework
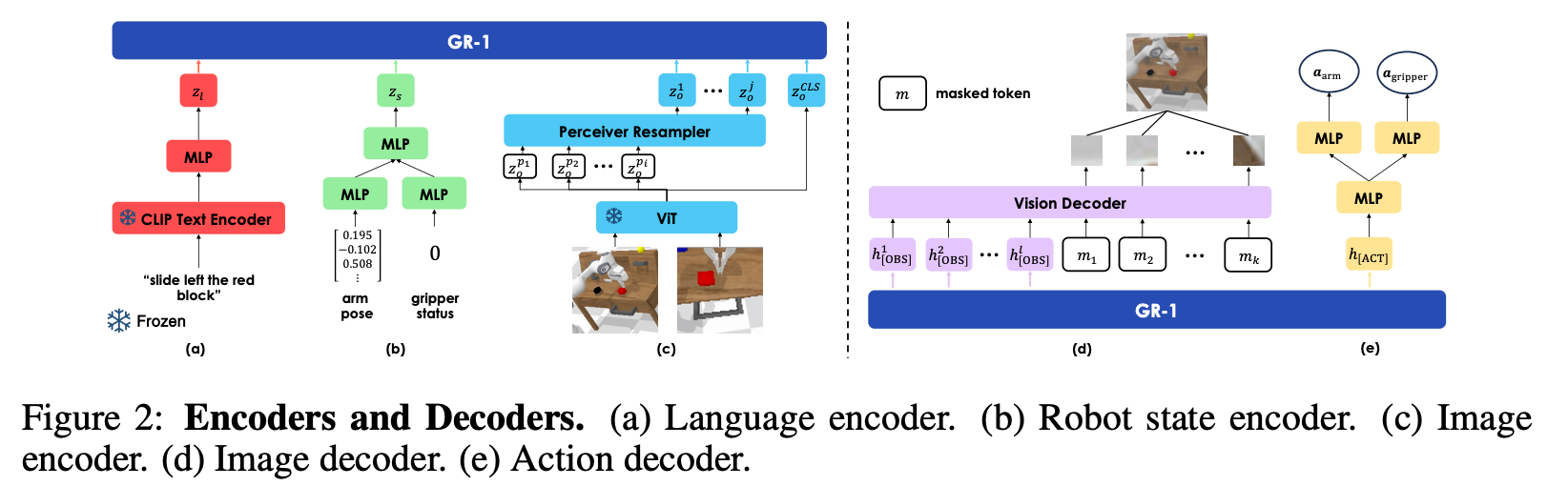
Pretrain
一个Video Prediction的任务,ViT Encoder与Clip Text Encoder被冻结,在Ego4D Dataset上训练,该数据集有3,500 hours的第一人称视频数据,每个clip有对应的文字描述。
Robot Data Finetuning
加入action的输入输出分支:输入由多个MLP编码融入GR1模型,输出由GR1模型能过多个MLP直接预测action。
![]()
使用了195M的一个Transformer GPT模型 (参考Appendix)。
训练集:The training dataset contains over 20k expert trajectories paired with language instruction labels
Experiment
在真实数据上有效性、泛化性?
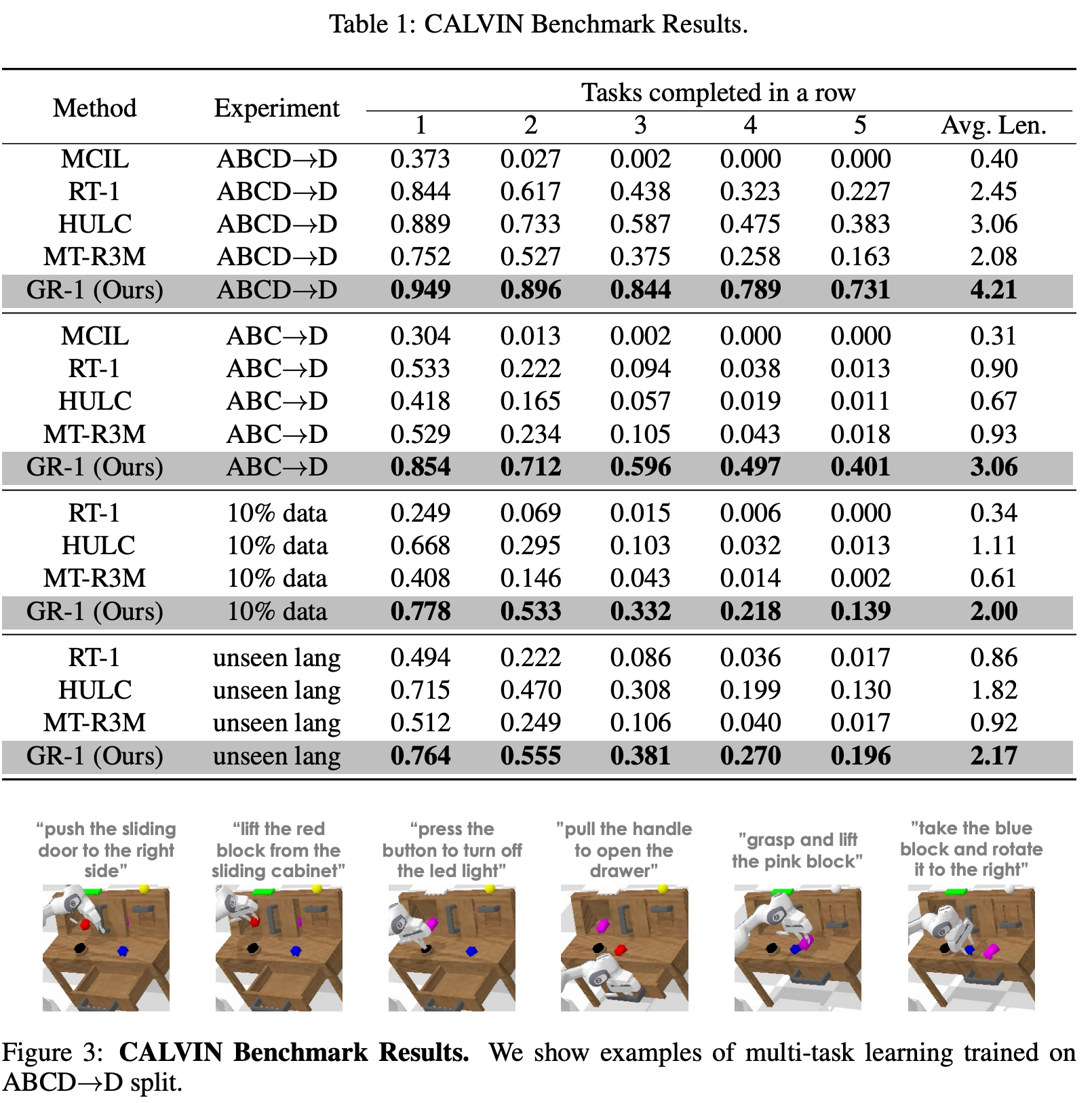
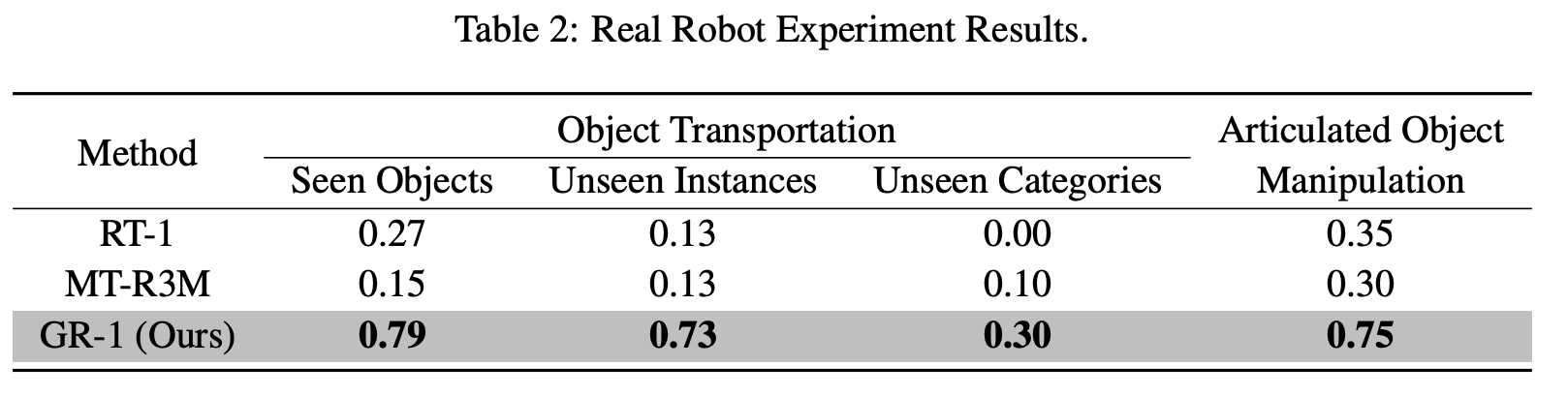
总结与思考
无
相关链接
无
本文来自博客园,作者:fariver,转载请注明原文链接:https://www.cnblogs.com/fariver/p/19027562

 浙公网安备 33010602011771号
浙公网安备 33010602011771号