[PaperReading] OpenVLA: An Open-Source Vision-Language-Action Model
OpenVLA: An Open-Source Vision-Language-Action Model
link
时间:24.06
单位:Stanford University, UC Berkeley, Toyota Research Institute, Google Deepmind, Physical Intelligence, MIT
相关领域:Robot
被引次数:695
项目主页:https://openvla.github.io/
TL;DR
开源7B VLA模型及970k段训练集,基于llama2语言模型外加Dinov2使用SigCLIP来对齐视觉特征,效果上相对于RT-2-X (55B)提升16.5%的任务成功率。同时在多个新环境上finetune该模型效果比模仿学习(eg. Diffusion Policy)提升20.4%。同时,该模型在消费级显卡上可以轻松LoRA Finetune。
Method
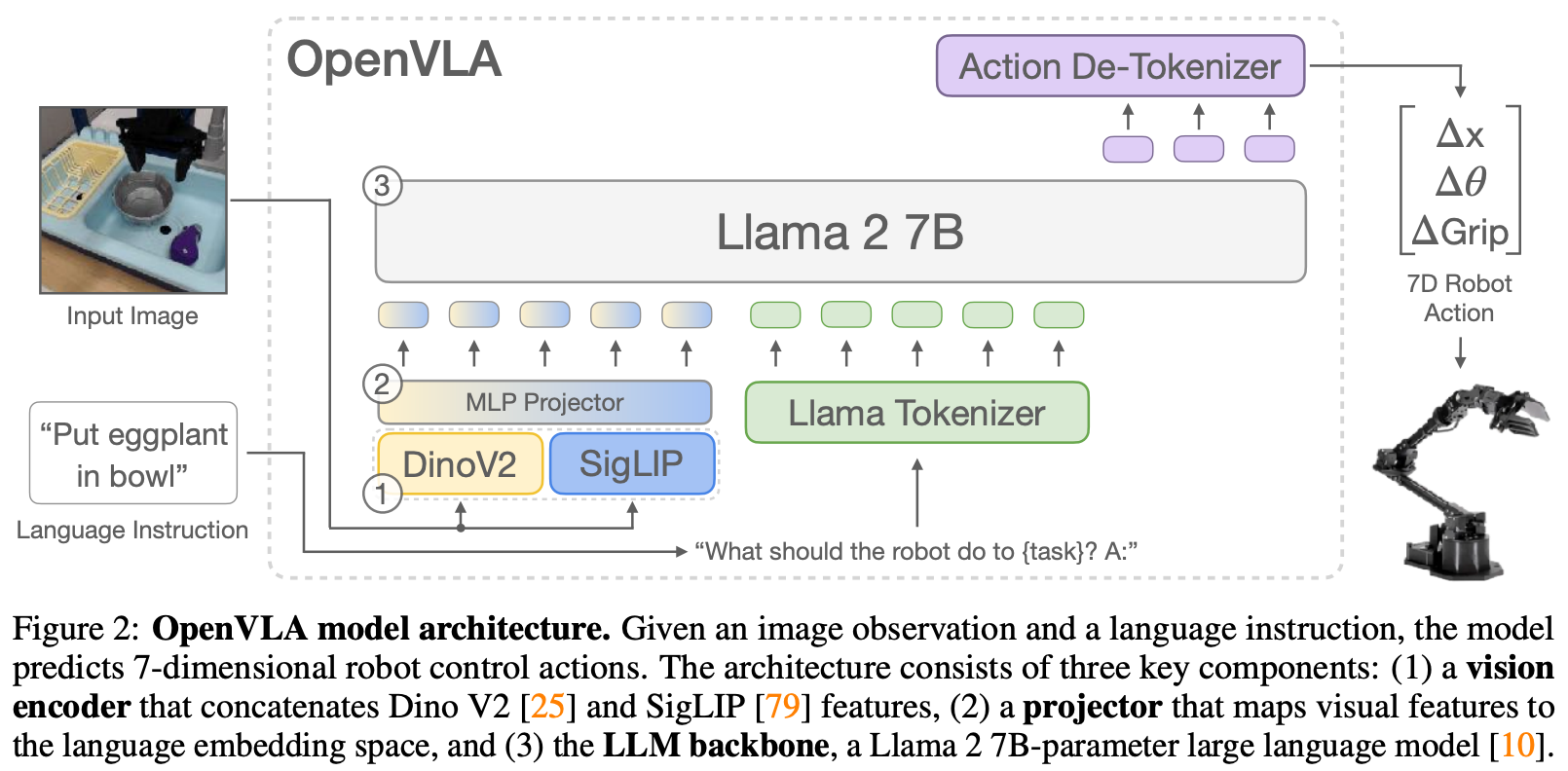
action表示
将action每个自由度的数值范围划分为 256个“箱子”(bins)。每个箱子可以被看作是词汇表中的一个“单词”或“词元(token)”。问题在于LLM仅预留了100个未占用的特殊token,而这里需要256个特殊token,本文的作法是覆盖256个使用频率最低的token。
Training Data
以OpenX作为基础数据(包含70+种机器本体及2百万运动轨迹),主要通过筛选与归类构建新数据集。主要考虑两个问题:
- 输入空间的相干性 与 输出空间的相干性。
输入空间相干性 需要保障每组数据至少包含一个第三视角的相机;输出空间的相干性要求action自由度控制类型相同。
- 本体多样性、任务多样性 以及 场景多样性,使用过滤及up-weights等处理方法保障三者的配比均衡。

Implementation
以下经验在一个小数据集BridgeData V2上验证得出:
Vision Encoder: FT要比Freeze好;Prismatic7B要比llava好;
图像分辨率:384x384与224x224效果接近,反而训练更慢;
Training Epochs: 在27Epoch之前都有提升,27Epoch达到95%的准确率;
Infrastructure
训练:64 A100 GPUs for 14 days
推理:6Hz on one NVIDIA RTX 4090 GPU,需要15GB显存
Experiment
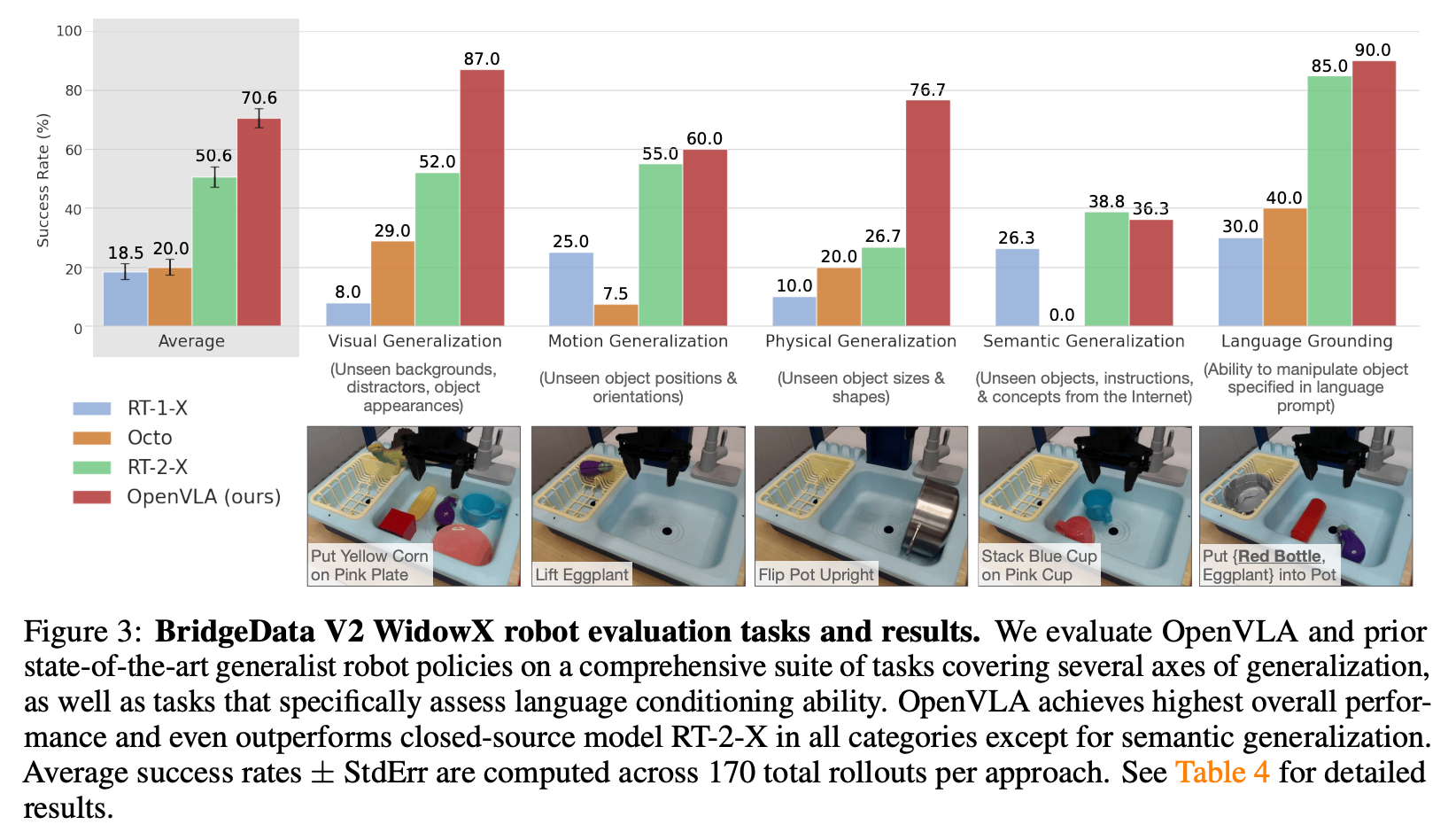
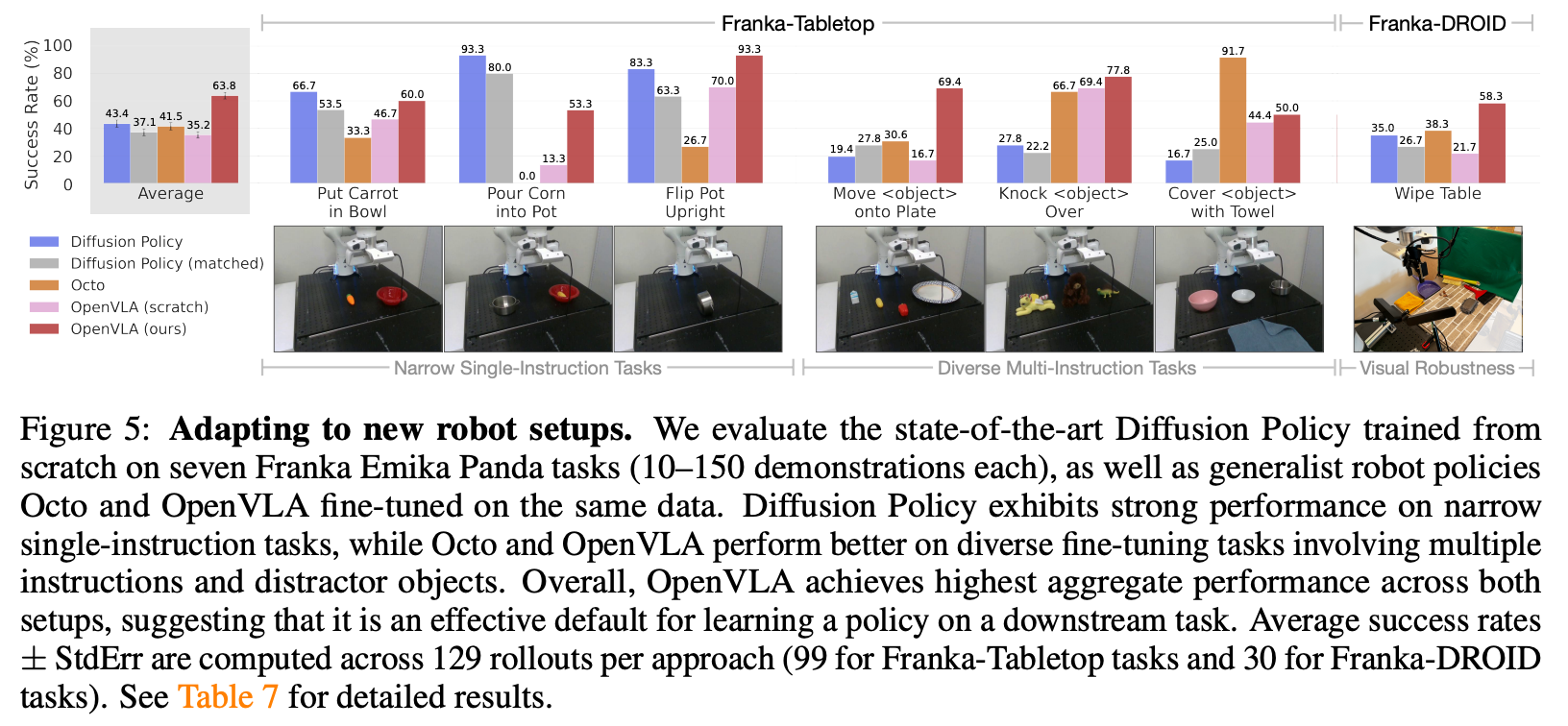
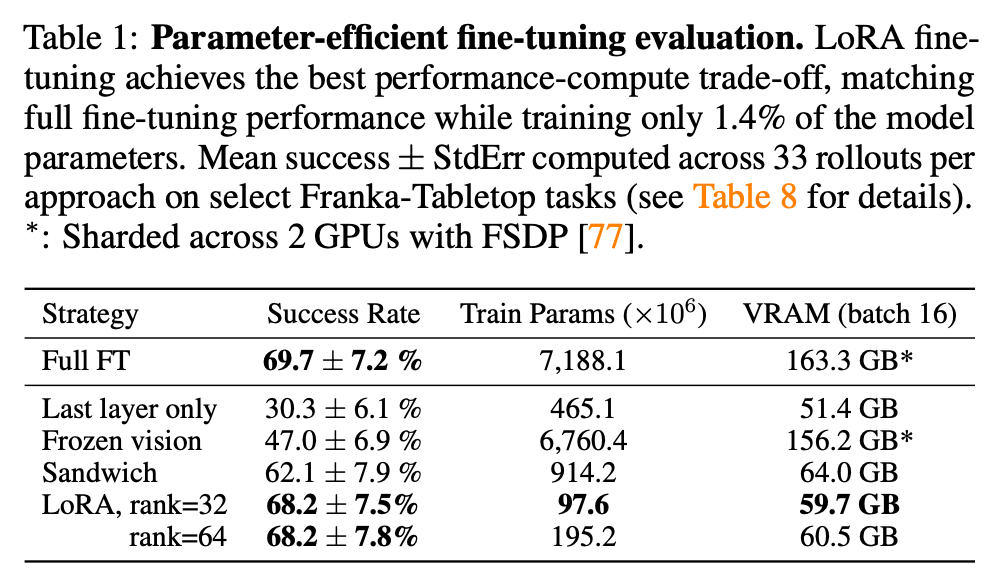
效果可视化
总结与思考
无
相关链接
https://zhuanlan.zhihu.com/p/1925499475973116151
Related works中值得深挖的工作
资料查询
OpenVLA/RT1/RT2与Diffusion Policy之间的差异
概念层次与定位差异 Diffusion Policy与RT-1、RT-2以及OpenVLA并不完全属于同一层次的概念,它们代表了机器人学习领域不同的技术路线和架构选择。RT系列与OpenVLA:端到端的VLAs(Vision-Language-Action模型)
RT-1、RT-2和OpenVLA都属于Vision-Language-Action (VLA)模型,这类模型具有以下共同特征:
架构基础:建立在大型视觉-语言模型(VLMs)基础上,通过直接微调生成机器人动作
训练范式:利用互联网规模的视觉-语言预训练+大规模机器人演示数据微调
输入输出:接受图像和语言指令作为输入,直接输出机器人动作
参数规模:通常为十亿参数级别的大型模型(RT-1: 35M; RT-2: 55B; OpenVLA: 7B)
Diffusion Policy:基于扩散模型的模仿学习框架
Diffusion Policy则代表了一种不同的技术路线:
架构基础:建立在扩散模型(Diffusion Models)上,专门为机器人控制设计
训练范式:纯粹从机器人演示数据中学习(无互联网规模预训练)
输入输出:接受图像/状态观测序列,输出动作序列
参数规模:通常为百万参数级别(远小于VLAs)
核心创新:提出了"动作分块"(action chunking)和时态平滑机制
本文来自博客园,作者:fariver,转载请注明原文链接:https://www.cnblogs.com/fariver/p/19027344

 浙公网安备 33010602011771号
浙公网安备 33010602011771号