[PaperReading] RT-1: ROBOTICS TRANSFORMER FOR REAL-WORLD CONTROL AT SCALE
RT-1: ROBOTICS TRANSFORMER FOR REAL-WORLD CONTROL AT SCALE
link
时间:22.12
单位:Google
相关领域:Robtics
被引次数:1387
项目主页:https://robotics-transformer1.github.io/
TL;DR
大规模预训练结合zero-shot与小规模Finetune已在NLP/CV任务上验证效果,本文主张机器人场景下通过丰富的任务无关的预训练也有可能做出通用机器人。本文针对不同数据量、不同模型尺寸以及不同丰富度的数据上进行了大量实验验证该结论。


Method
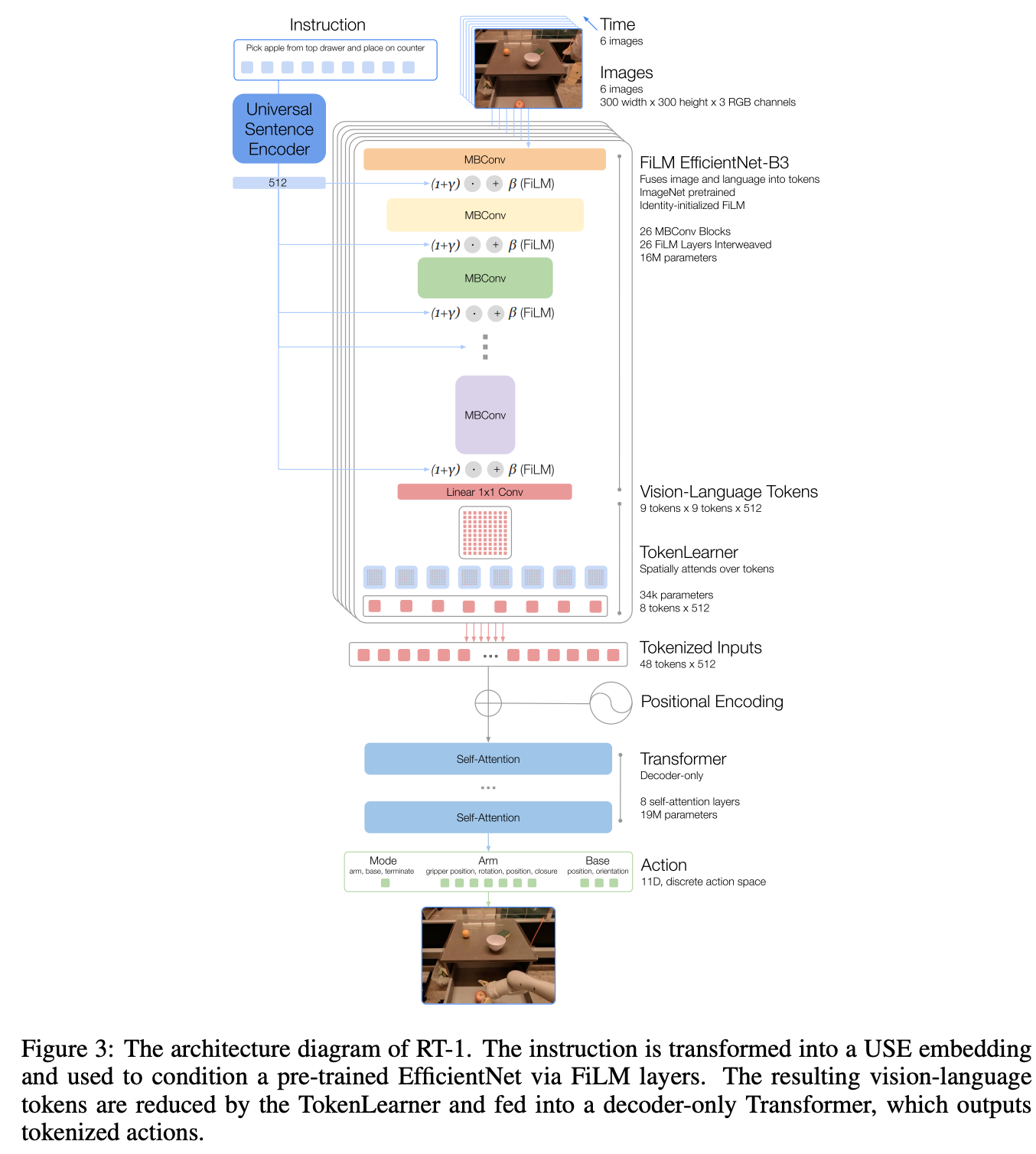
instructions与images模态特征处理
- image: an ImageNet pretrained EfficientNet,每次同时输入6帧
- instruction: 通过a pretrained Universal Sentence Encoder来抽取embedding特征
- 特征融合:通过FiLM Layer将text特征融入视觉特征中
- 输出action:每个自由度被划分为256bins
- arm movement:x, y, z, roll, pitch, yaw, opening of the gripper
- base movement: x, y, yaw
- a discrete dimension to switch between three modes: controlling the arm, the base, or terminating the episode
FiLM Layer是如何将text特征融入视觉特征的?
FiLM Layer的基本原理 FiLM Layer是一种特征级别的条件调节机制,最早由Perez等人在2018年提出。它的核心思想是通过对神经网络中间特征进行仿射变换(affine transformation)来实现条件调节。具体来说,FiLM层会为每个特征通道生成一个缩放因子(scale)和偏移量(shift),对原始特征进行线性变换: $$FiLM(x) = γ * x + β$$ 其中: - x是输入特征 - γ(scale)和β(shift)是由条件信息(如文本嵌入)生成的调制参数 - 在RT-1中,FiLM层被插入到预训练的EfficientNet-B3模型中,用于将语言指令的语义信息注入到视觉特征提取过程中。TokenLearner
用来对token序列进行压缩提升推理速度,例如可以将81个visual tokens压缩为8个token,再输入一个19M的Decoder-only的Transformer中预测action tokens。
Action预测
GR-1使用MLP动作头,每次预测的是未来一小段的动作序列(Action Sequence or Action Chunk),而不是仅仅预测下一个时刻的单个动作。
机器人并不会盲目地执行完整个预测出的N帧动作。它通常采用一种类似模型预测控制(MPC)或滚动时域控制(Receding Horizon Control)的方式:
- 预测 (Predict): 模型在当前时刻 t,预测出从 t 到 t+N-1 的整个动作序列。
- 执行 (Execute): 机器人只执行这个序列中的第一步或前几步动作(比如只执行 action_t)。
- 重复 (Repeat): 在下一个控制时刻 t+1,机器人获取新的观测,然后重新运行整个模型,再次预测一个新的、从 t+1 到 t+N 的动作序列。然后再次只执行其中的第一步。
Data
人类采集的13W段示例轨迹,每段对应一条指令任务,总共700多种指令。
Experiment
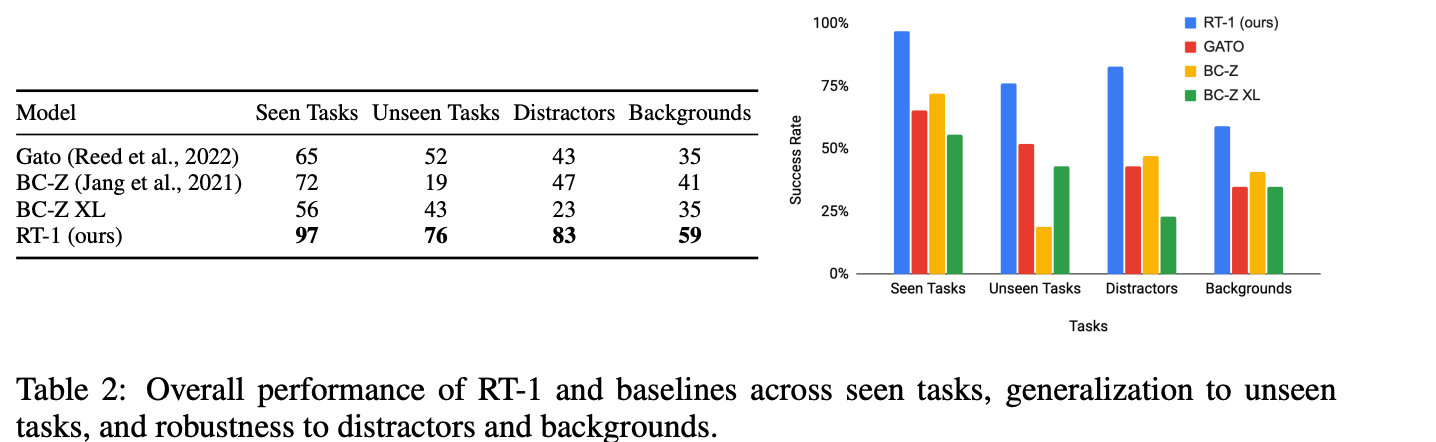
在新任务上Zero-shot泛化能力
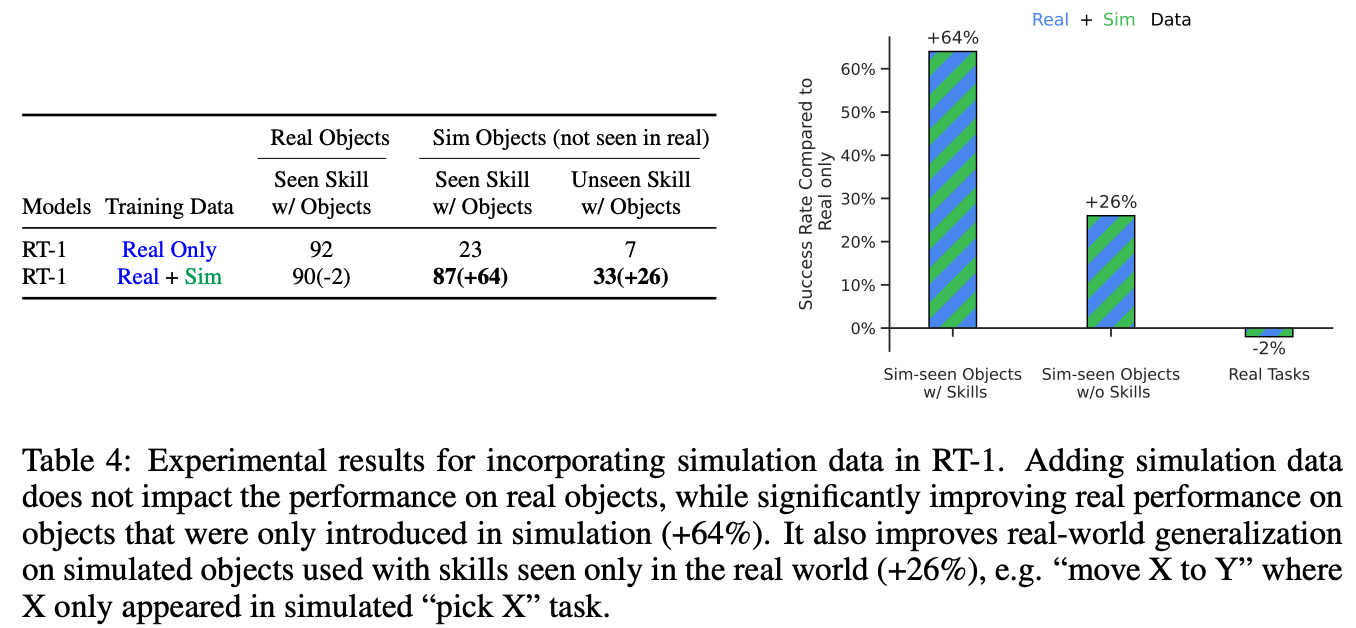
仿真数据对于泛化性的提升
作者实验证明增加仿真数据不影响真实数据表现,并能够提升仿真数据类别在真实世界的表现
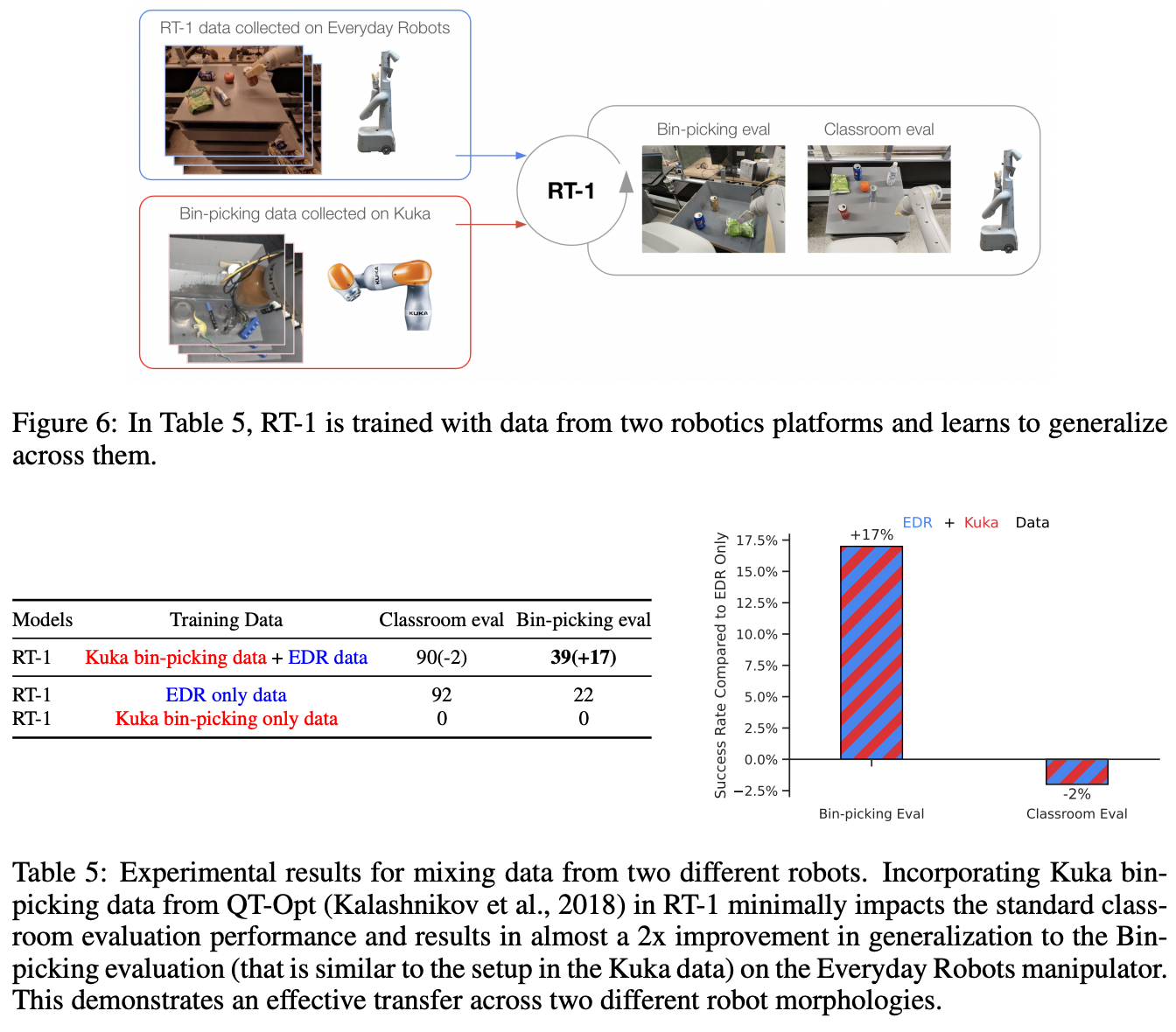
跨本体数据的迁移能力
Table 5和Figure 6共同展示了RT-1模型在跨机器人数据融合方面的突破性能力。这项实验验证了RT-1能够吸收来自不同机器人平台(Kuka IIWA和Everyday Robots)的数据,并实现跨平台的技能迁移。核心发现包括:
- 性能保持:加入Kuka数据后,原始任务性能仅下降2%(从92%到90%)
- 技能迁移:在类似Kuka设置的"Bin-picking"任务上,性能提升17%(从22%到39%)
![image]()
数据量与数据丰富度对于效果与泛化性的影响
数据丰富度对于效果影响更大一些
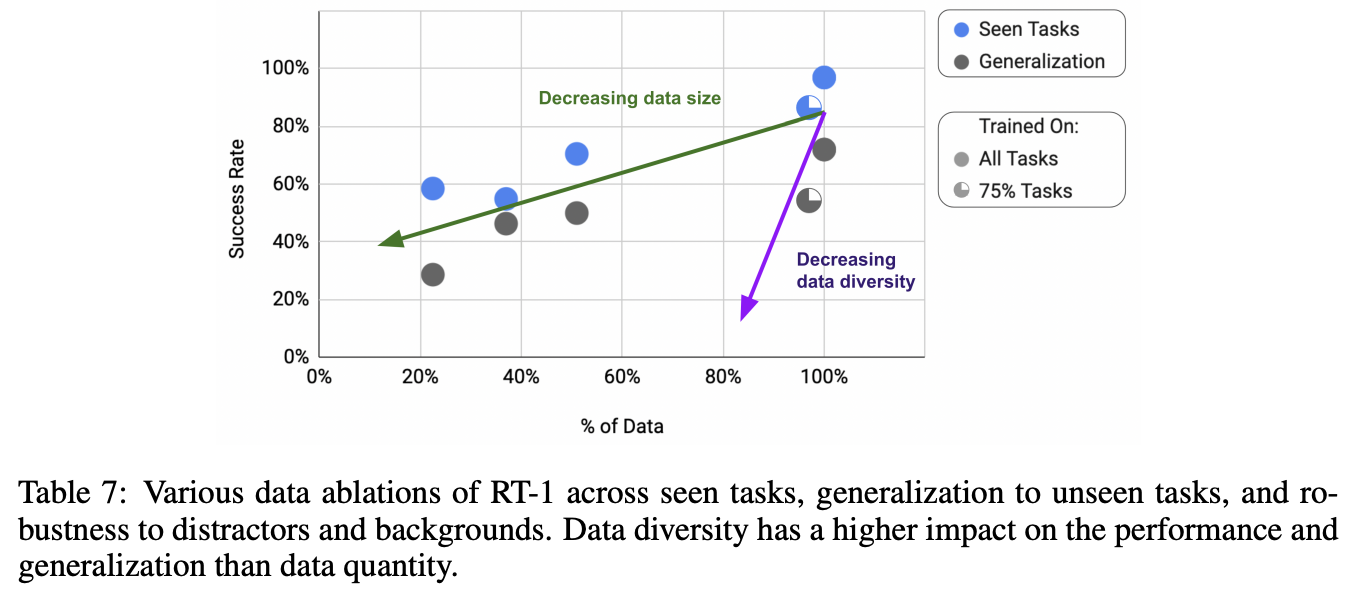
效果可视化
总结与思考
- 目前了解到的最早的通用机器人工作,实验扎实,构建数据也花费不少资源
- 没有使用非常大的模型尺寸,多模型融合方法也比较简单(FiLM),但做出基本效果
相关链接
https://zhuanlan.zhihu.com/p/12410988322
https://zhuanlan.zhihu.com/p/675317460
本文来自博客园,作者:fariver,转载请注明原文链接:https://www.cnblogs.com/fariver/p/19034602

 浙公网安备 33010602011771号
浙公网安备 33010602011771号