[PaperReading] GR-2: A Generative Video-Language-Action Model with Web-Scale Knowledge for Robot Manipulation
GR-2: A Generative Video-Language-Action Model with Web-Scale Knowledge for Robot Manipulation
link
时间:24.10
单位:Bytedance
相关领域:Robotics
被引次数:99
项目主页:
https://gr2-manipulation.github.io/
TL;DR
GR-2在38M video clips与6B tokens的大规模数据集上预训练,并提出一种新架构可无缝从pretrain阶段迁移知识,在超过100个任务的测试集上达到97.7%的成功率。
Method
两阶段训练:video generation pre-training and robot data fine-tuning
模型架构
pretrain与finetune尽可能复用架构:GR-2采用GPT-style的Transformer架构,在预训练和微调阶段保持一致的模型结构。预训练:GPT-style的视频token生成任务;Finetune阶段:使用机器人数据训练,生成动作轨迹 与 未来视频tokens。
We develop a novel model architecture that allows the knowledge gathered from pre-training to seamlessly
transfer to downstream fine-tuning in a lossless way.
多模态统一表示:
- 通过VQGAN将图像和视频统一编码为离散token序列,与文本token采用相同的处理方式;
- VQGAN是提前训练好的,不随pretrain与finetune阶段训练。
条件VAE设计:动作预测采用条件变分自编码器(cVAE),与视频生成任务共享底层表示,确保动力学知识可以跨任务迁移。
关于机器人硬件配置:a static head camera provides an overview of the workspace; another camera, which is
mounted on the end-effector, offers a close-up view of interactions between the gripper and the environment.
关于cVAE
文中用来生成action序列,但未详细描述,查询了一些资料如下:
GR-2的cVAE模块采用分层条件编码结构:
- 多模态条件输入:
- 语言指令通过冻结的CLIP文本编码器处理
- 视觉观察序列经VQ-GAN编码为离散token
- 机器人状态(末端位姿+夹持器状态)用可训练线性层编码
- 三者融合后形成条件向量\(z_{cond}\)
- 概率建模机制:
其中\(z\)为潜在变量,\(\theta\)为解码器参数,\(\phi\)为编码器参数
- 轨迹级输出:
不同于单步动作预测,cVAE直接生成\(k\)步动作轨迹(文档2.1节关键设计),配合WBC算法实现200Hz实时控制:
Dataset
Pre-train Dataset
38M video clips(等效于6B tokens)的大规模数据集

Robotic Dataset
通过遥操采集,105 table-top tasks,包含8种类型的技能 i.e., picking, placing, uncapping, capping, opening, closing, pressing, and pouring。共4W段示例轨迹。

Experiment
泛化性测试场景

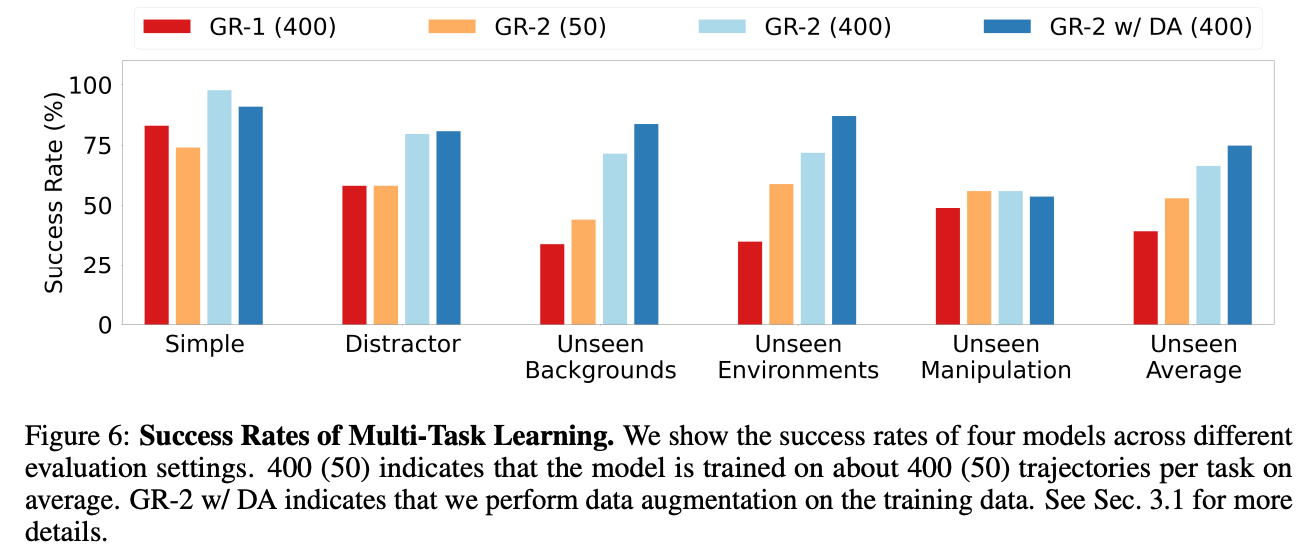
成功率测试 (相对于GR1以及不同训练数据量的GR2)
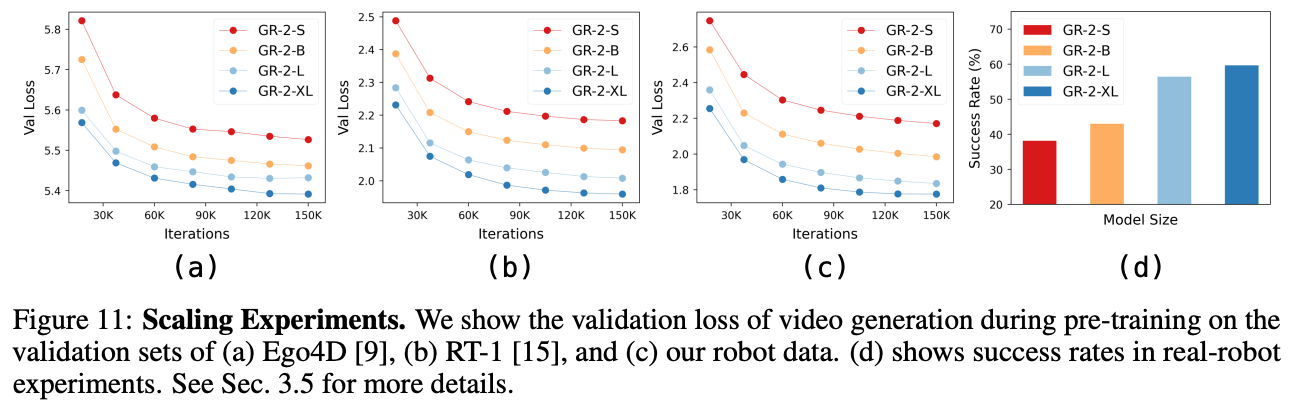
不同模型Size对应的成功率变化;预训练过程Val Loss的变化;
总结与思考
与GR-1有什么区别?主要是数据量变大了,action的生成方式变为cVAE,原来GR-1是直接MLP预测。
相关链接
本文来自博客园,作者:fariver,转载请注明原文链接:https://www.cnblogs.com/fariver/p/19029921

 浙公网安备 33010602011771号
浙公网安备 33010602011771号