[思考] LLM训练工程优化
背景
大语言模型(LLM)参数量已突破万亿,单次训练计算量达千亿亿次浮点运算(ExaFLOPs)。单卡GPU显存上限仅80GB(A100),算力峰值312 TFLOPS,显存墙与通信墙成为千卡/万卡分布式训练的核心瓶颈。
前置知识
1. DDP训练过程
数据切片:全局Batch拆分为子Batch分发到各GPU
独立前向/反向:每卡计算本地梯度
梯度同步:AllReduce操作聚合全局梯度(如NCCL)
参数更新:各卡独立更新相同权重副本
瓶颈:显存冗余(每卡存全量参数/优化器状态),仅适用于中小模型。
2. Transformer Attention机制
- 计算式:
\(\text{Attention}(Q,K,V) = \text{softmax}\left(\frac{QK^T}{\sqrt{d_k}}\right)V\) - 显存复杂度:\(O(L^2 \cdot d)\)
- \(QK^T\)矩阵尺寸为\(L \times L\),占用\(O(L^2)\)显存
- 后续与\(V \in \mathbb{R}^{L \times d}\)相乘,总显存\(O(L^2 \cdot d)\)。
显存优化
假设模型参数量为\(X\),则FP16训练模型相关显存占用如下:
| 组件 | 计算公式 |
|---|---|
| 模型参数 | 2 X |
| 梯度 | 2 X |
| 优化器状态 | 12 X = model + momentum + variance |
备注:除此之外,还有激活值、剩余内存 占用,推理时还有KV Cache的显存占用。
优化手段与通信开销分析
显存优化需权衡通信开销(并行策略)、计算延迟(重计算)、精度损失(量化)。
1. ZeRO(零冗余优化器)
| 阶段 | 显存削减 | 通信开销 | 适用场景 |
|---|---|---|---|
| ZeRO-1 | 4倍 | AllGather优化器状态(带宽敏感) | 中小规模多机训练 |
| ZeRO-2 | 8倍 | ReduceScatter梯度(延迟敏感) | 中等规模集群 |
| ZeRO-3 | Nd倍 | 权重AllGather + 梯度ReduceScatter | 万卡级超大模型 |
备注:
- Nd指是GPU Device的数量
- ZeRO又称ZeEO-DP,本质上计算流程类似于Data-Parallel
2. 并行策略
| 并行类型 | 显存优化 | 通信开销 | 典型框架 |
|---|---|---|---|
| 数据并行(DDP) | 无参数冗余优化 | 梯度聚合Ring-AllReduce(O(2N)) | PyTorch DDP |
| 张量并行(TP) | 完整激活,参数沿列切片 | 两次AllGather | Megatron |
| 流水线并行(PP) | 单卡仅存部分层 | O(layers) | DeepSpeed |
| 序列并行(SP) | 切分序列维度,降低激活值 | AllGather序列块(O(L * d)) | Megatron |
| 专家并行(MoE) | 仅激活当前专家 | All-to-All路由(O(experts)) | DeepSpeed-MoE |
3. Activation Recomputation(重计算)
- 原理:丢弃部分激活值,反向传播时临时重算
- Megatron: 证明使用Selective Activation Recomputation相对于暴力Recomputation节省90%重计算
- DeepSeek优化:动态规划选择最低成本重计算节点
4. Gradient Accumulation(梯度累积)
PyTorch中的梯度累积(Gradient Accumulation)机制通过减少反向传播时的显存峰值占用来降低显存需求,其核心原理是将大批次(batch)的计算拆分为多个小批次累加梯度,从而避免一次性处理大批次数据时的显存爆炸。
model.zero_grad() # 初始化梯度缓冲区
accum_steps = 4 # 累积步数k
for i, (inputs, labels) in enumerate(dataloader):
outputs = model(inputs) # 前向传播(小批次M)
loss = criterion(outputs, labels) # 计算损失
loss = loss / accum_steps # 损失按k平均(可选,用于数值稳定性)
loss.backward() # 反向传播,梯度累积到缓冲区
if (i + 1) % accum_steps == 0: # 每k步更新一次参数
optimizer.step() # 参数更新
model.zero_grad() # 清空梯度缓冲区
备注:
- 梯度缓冲区(gradient buffer)的显存占用与累积批次数k无关,梯度累加是通过就地求和(in-place summation)实现
for param in model.parameters():
param.grad += current_minibatch_grad # 就地加法,显存不变
- batch_size仅与激活的显存有关,而与梯度及优化器的显存无关
- 学习率调整:累积梯度等效于大批次,通常需要按比例增大学习率(如lr *= k)。
- BatchNorm影响:如果模型包含BatchNorm层,小批次M的统计量可能不准确,需谨慎处理(如使用torch.nn.SyncBatchNorm或冻结统计量)。
- (Gradient Accumulation)与直接使用LargeBatch训练在理论上是等价的,但实际效果可能因实现细节和超参数调整而略有差异
5. PageAttention(vLLM)
- 虚拟显存化:KV Cache分页存储,支持非连续物理块
- 通信开销:零额外通信,但需维护Block Table映射表
- 吞吐量:提升2-4倍
6. 量化技术
(1) AWQ(激活感知权重量化)
- 核心思想:分析激活分布识别1%关键权重通道,通过数学等效缩放(非混合精度)保护其量化
- 实现:量化标定时,识别1%重要通道保持FP16,其余通道INT4,部署时持续使用这种量化关系。
- 效果:相比FP16加速3-4倍,首次支持70B模型在移动GPU部署
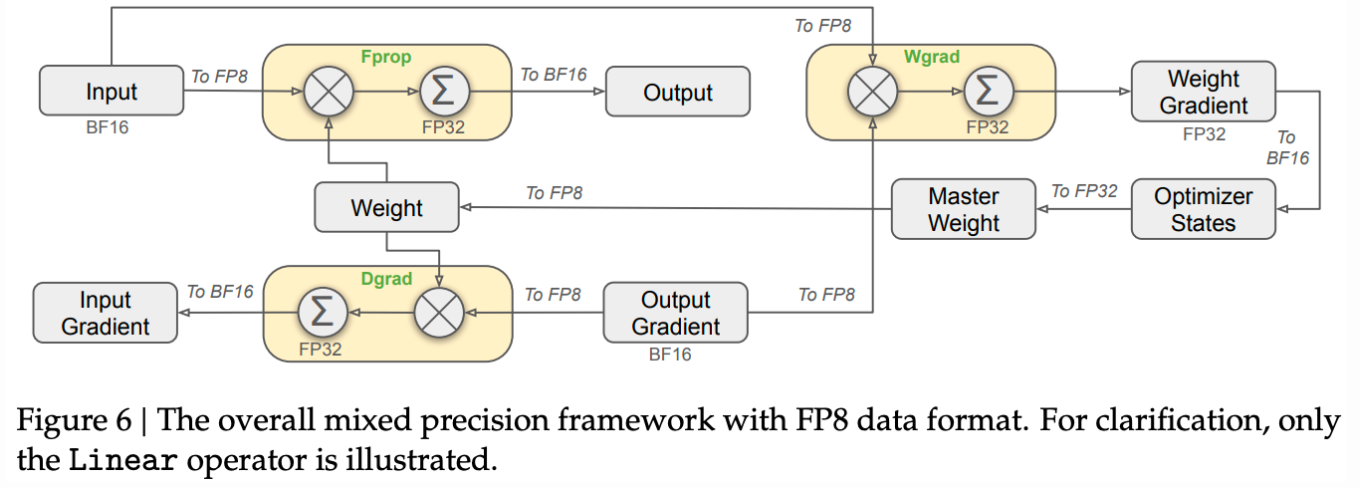
(2) FP8训练(DeepSeek-V3方案)
- 混合精度策略:
![image]()
速度优化
1. FlashAttention
- 核心原理:通过GPU Tiling将Attention算子融合,减少GPU HBM与片上内存的读写次数
- 性能提升:提升推理速度(GPT2上加速2.2倍,更长context情况下加速2.4倍)
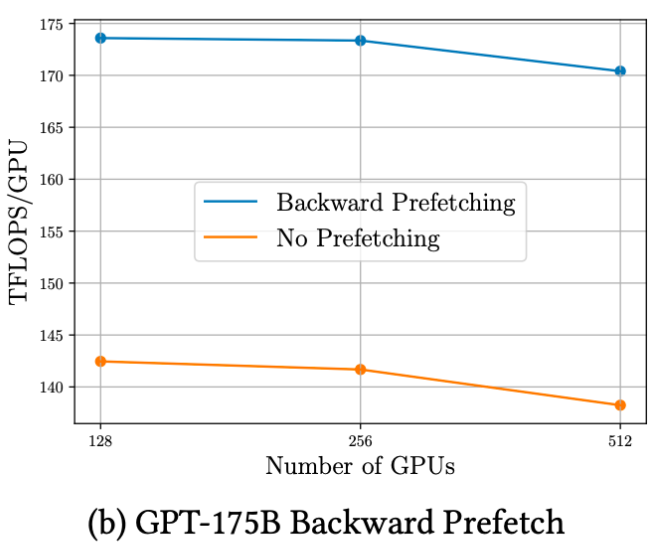
2. 计算与通信重叠
FSDP中证明使用Prefetching将Forward与Backward中All-Gather通信重叠后,GPU计算吞吐量有明显提升。
关键问题解答
Q: Flash Attention中softmax计算为什么与全局一次性计算等价?
本文来自博客园,作者:fariver,转载请注明原文链接:https://www.cnblogs.com/fariver/p/18957656

 浙公网安备 33010602011771号
浙公网安备 33010602011771号