[PaperReading] AWQ: ACTIVATION-AWARE WEIGHT QUANTIZATION FOR ON-DEVICE LLM COMPRESSION AND ACCELERATION
AWQ: ACTIVATION-AWARE WEIGHT QUANTIZATION FOR ON-DEVICE LLM COMPRESSION AND ACCELERATION
link
时间:23.06
单位:mit-han-lab
相关领域:MLSys 2024 Best Paper Award
作者相关工作:
Ji Lin: VLM, 3D感知,模型裁剪
song han: squeezeNet, deepCompression
被引次数:1047
主页:
https://github.com/mit-han-lab/llm-awq
TL;DR
端侧部署LLM能够很好保护用户隐私,但LLMs参数量巨大(如175B参数),难以在端侧运行。现有量化方案QAT需要额外的训练时间与资源,PTQ量化精度损失严重。本文提出AWQ量化方法,通过分析激活分布识别1%关键权重通道,通过数学等效缩放(非混合精度)保护其量化。最终实现4-bit量化LLM推理,相比FP16加速3-4倍,首次支持70B模型在移动GPU部署。
Method
Story
直接量化为INT3精度损失严重 -> 发现仅将weights中1% channels改为FP16量化精度提升明显 -> AWQ使用per-channel scaling技术降低量化损失。
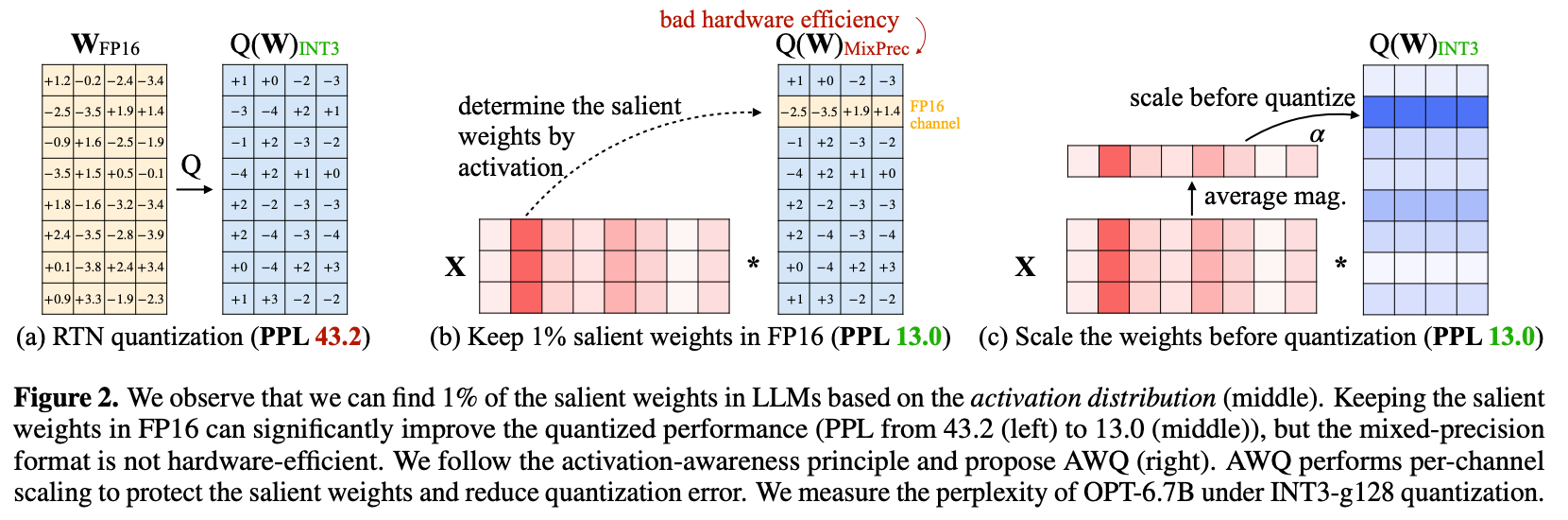
为什么用weights quantized-only的方案?
generation(token生成)阶段相对于context(prompt处理)阶段耗时更大 -> generation阶段速度是memory bound类型 -> LLM中基本操作Attention与FFN中weights loading耗时明显大于实际计算时间

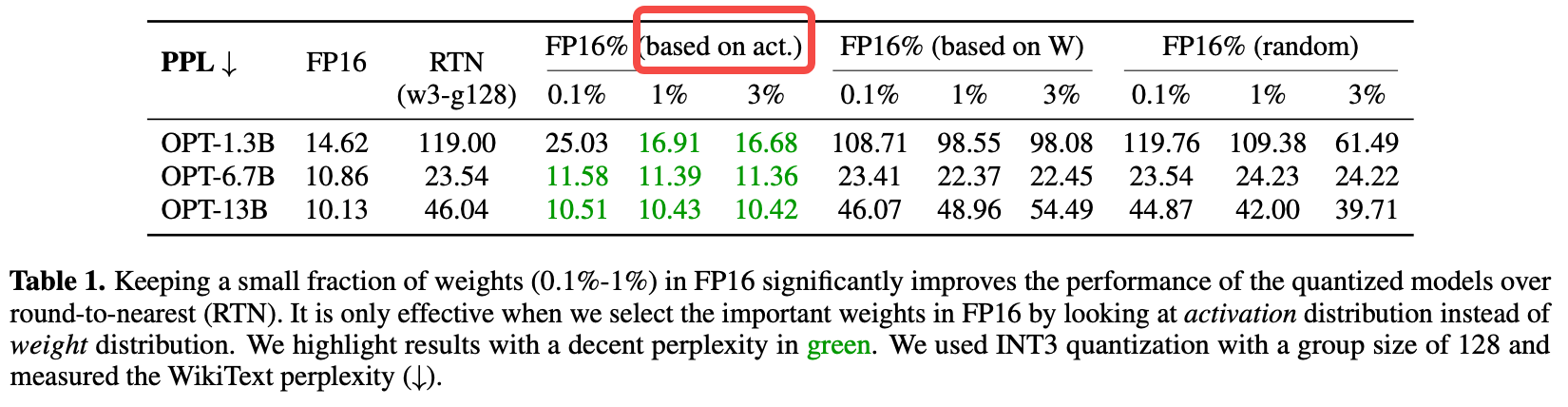
如何挑选import weights?
基于activation分布挑选 > 基于weights分布挑选 > 随机挑选
理论
由于W4A16的量化,想高特定channel量化精度,可以通过以下公式,将W的数值范围放缩到合适范围,多余scale转移给X即可(X是16bit不用担心量化损失)。
Implementation
- 离线统计激活幅值分布
- 网格搜索最优缩放系数α(公式5)
- 应用逐通道缩放并量化所有权重
weights的1%重要通道标定
校准阶段固化:一旦模型完成校准(使用小规模校准集统计激活分布),重要通道及其缩放因子\(s_i\)即被固定,后续推理过程不再变化。依据如下:
- 实验支持:表1显示,使用固定校准集选择的1%重要通道能使OPT-6.7B的PPL从23.54→11.39,说明通道重要性具有稳定性。
- 泛化性保障:论文强调AWQ不依赖在线学习或动态调整(第3.2节),因此重要通道在模型部署后是静态的。
Experiment
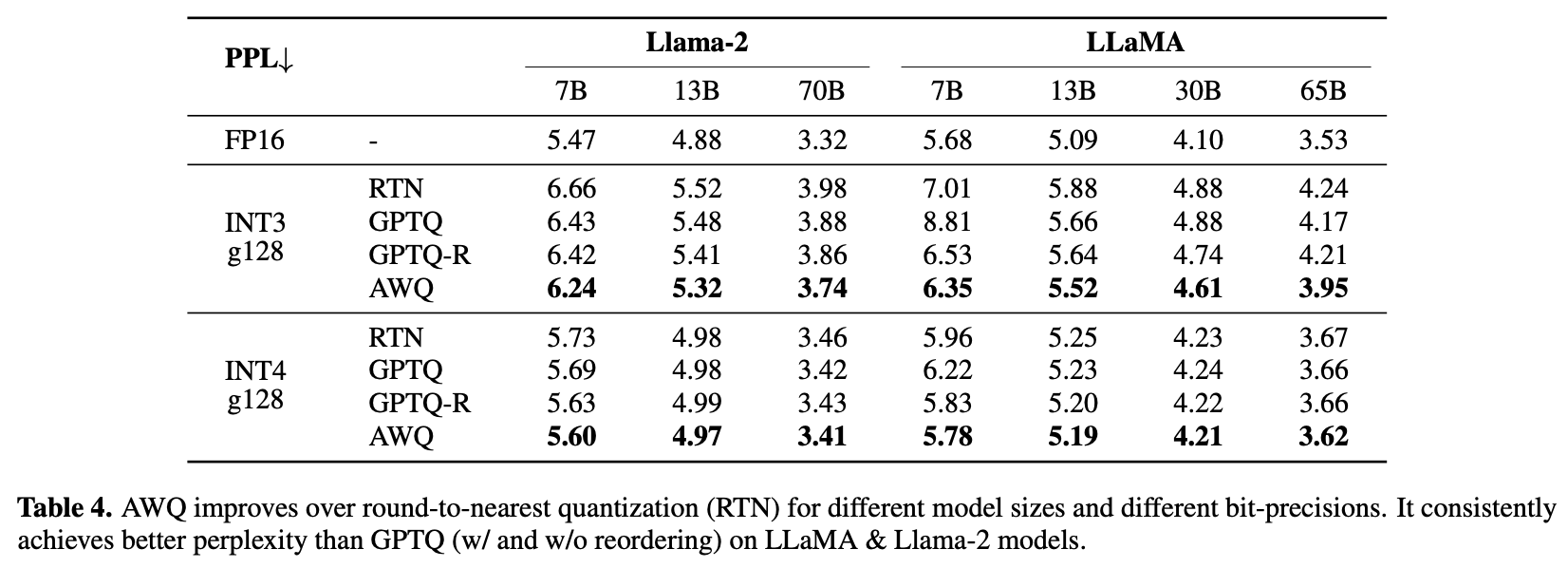
对比其它weights量化方法,精度损失最小,但相对于FP16仍有差距
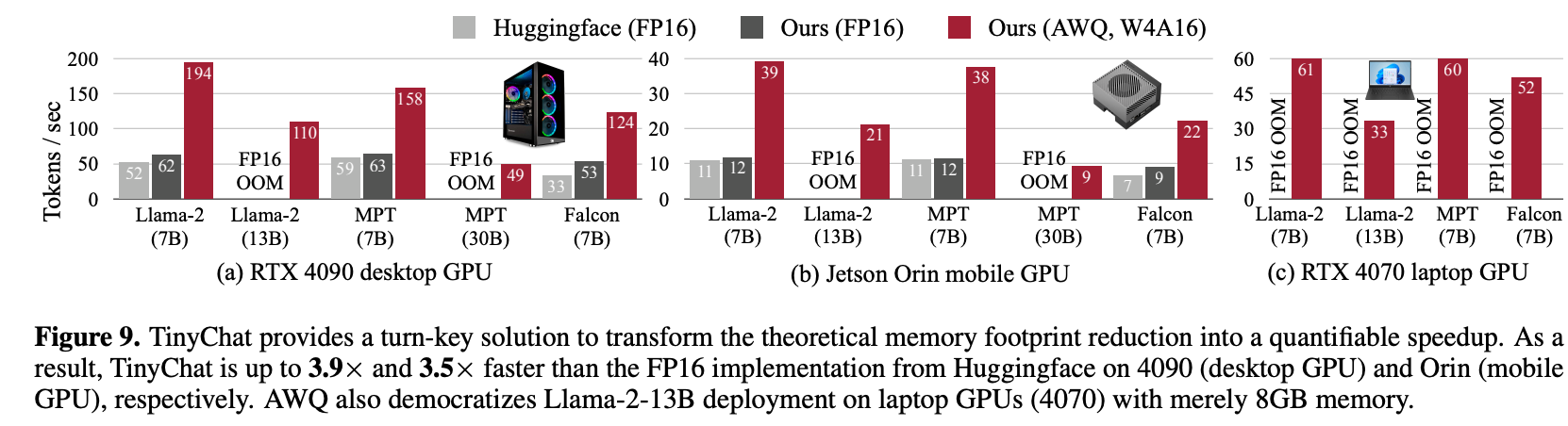
速度上相对于FP16有3.5x(on 4090)/3.9x(on Orin)提升
效果可视化
总结与思考
方法简单,故事线比较好,很有insight
相关链接
这篇写得比较通俗易懂,其中“篇章四”优劣势部分可作为本文补充。
Related works中值得深挖的工作
资料查询
折叠Title
FromChatGPT(提示词:XXX)本文来自博客园,作者:fariver,转载请注明原文链接:https://www.cnblogs.com/fariver/p/18940358

 浙公网安备 33010602011771号
浙公网安备 33010602011771号