[PaperReading] Efficient Memory Management for Large Language Model Serving with PagedAttention
Efficient Memory Management for Large Language Model Serving with PagedAttention
link
时间:23.09
单位:UC Berkeley, Stanford, UCSD
作者相关工作:
一作:https://scholar.google.com/citations?user=_AT3eUcAAAAJ&hl=en&oi=sra
被引次数:2201
主页:
github
slides
TL;DR
针对大模型部署过程中KV Cache内存浪费进行优化,参考计算操作系统内存管理的虚拟内存与页表管理机制。搭建一个vLLM的serving系统,优势是:a.几乎零内存浪费;b.可以跨requests来做批量化加速,进一步减少内存浪费。实验测试,latency相对于之前方法提升2-4x倍。
Motivation
现状:GPU显存是瓶颈
- 以一个13B LLM为例子,一个token的KV Cache占用800KB内存,如果生成长度限定在2048tokens,那么将占用1.6GB,再加上不同requests同时请求,KV Cache将占用很大存储。
- 新型GPU的算力在增长,但显存却在80G止步不前。
具体浪费情况
现有系统(如FasterTransformer和Orca)采用连续内存分配策略,导致三种内存浪费:
- 预留浪费:为未来token预留但尚未使用的空间 (类比vector中用户实际resize大小; 与LLM生成tokens长度上限有关)
- 内部碎片:因预分配最大可能长度而过度分配的空间 (类比vector中capcity)
- 外部碎片:内存分配器(如伙伴分配器)产生的不可用空间 (零散的小内块)
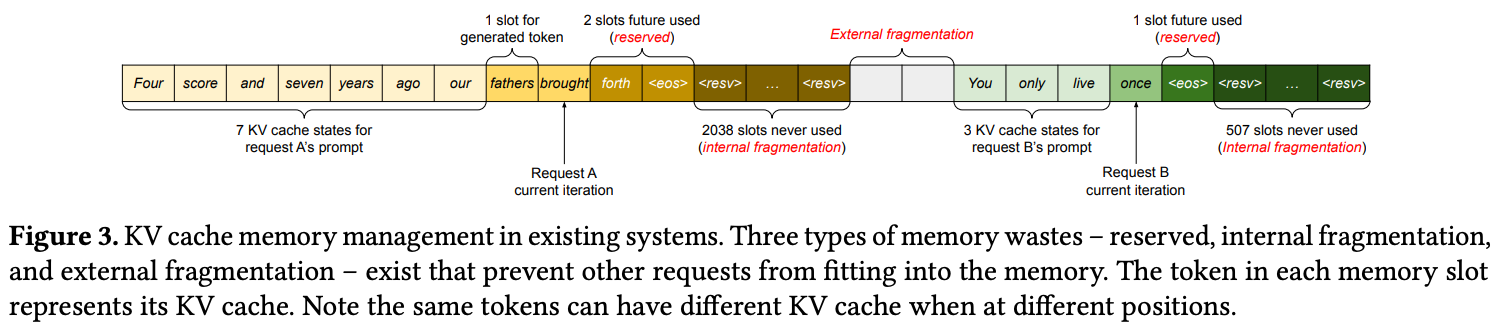
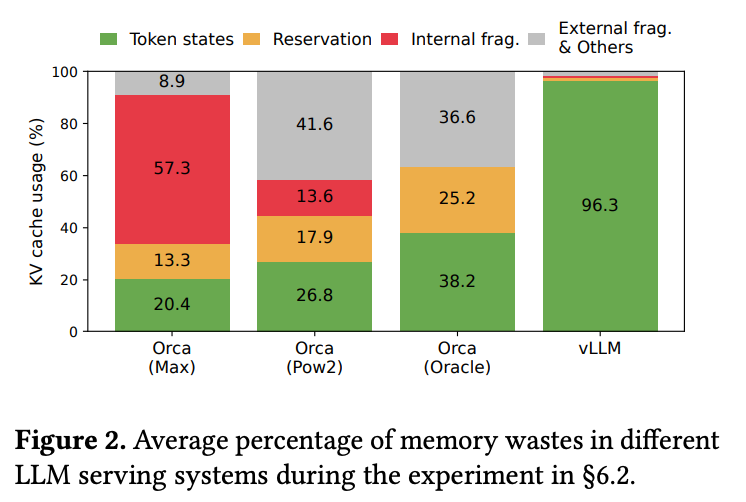
实验数据显示,现有系统中实际用于存储token状态的有效内存仅占20.4%-38.2%,大部分内存被浪费
Method
本章解决Motivation中问题,核心思想参考计算机操作系统中内存管理中的虚拟内存与页表机制启发。
vLLM Framework
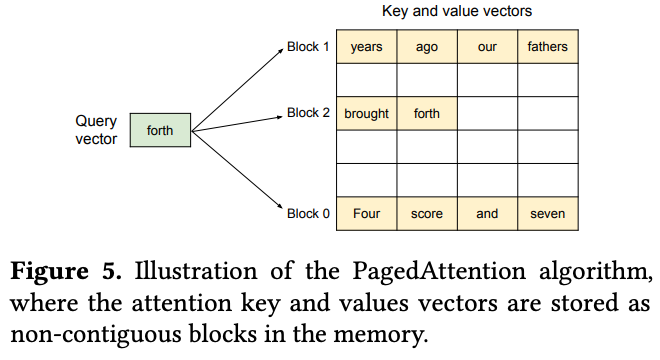
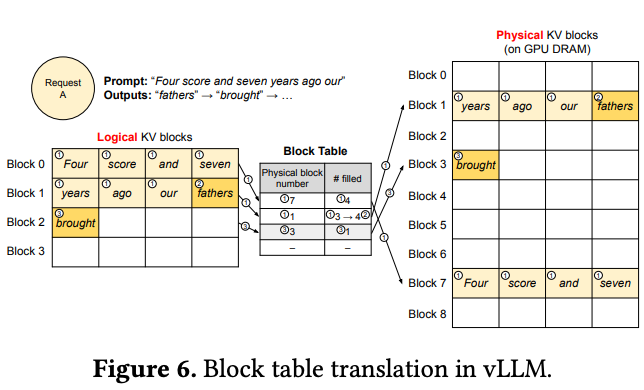
- KV块划分:将序列的KV缓存划分为固定大小的块(每块包含固定数量token的key和value向量)
- 逻辑块与物理块分离:维护逻辑块到物理块的映射表,虚拟页之间内存非连续存储
- 通过Block Table建立虚拟块与物理块之间的索引关系
![]()
![]()
![]()
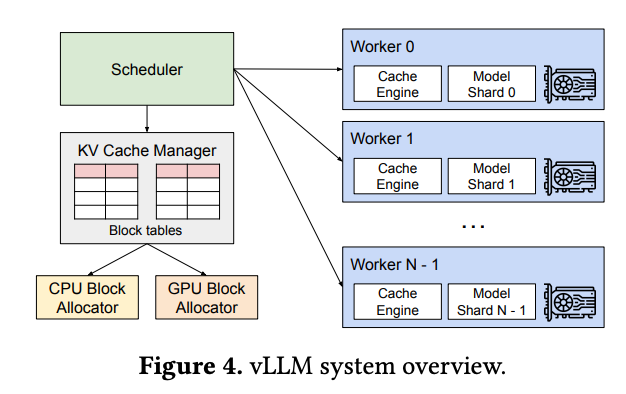
调度与抢占
vLLM采用以下策略处理内存不足情况:
- FCFS调度:先到先服务,防止饥饿
- 全有或全无换出:整组序列一起换出
- 恢复机制:将KV块换出到CPU内存 或者 重新计算KV缓存
其它Trick
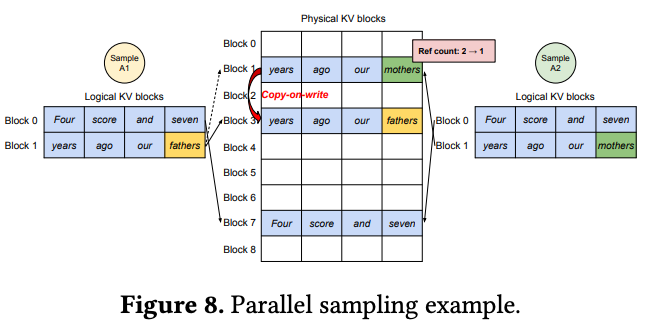
如果两组requests对应的tokens的KV Cache刚好完全相同,可使用它们虚拟页表指向同一个物理块,减少重复存储。
Experiment
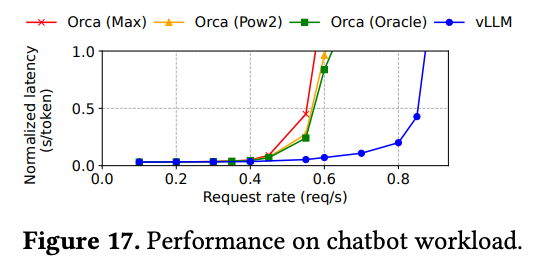
与其它竞品的延迟对比
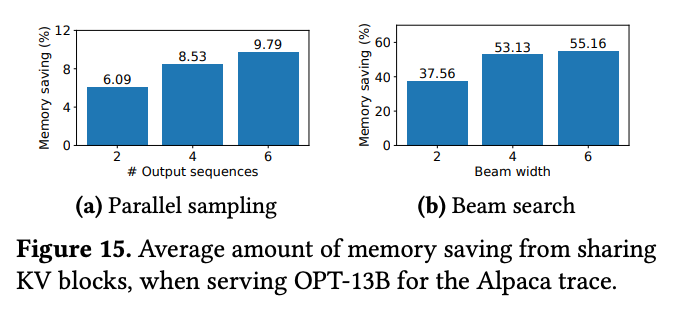
内存节省状态
总结与思考
暂无
相关链接
https://zhuanlan.zhihu.com/p/715958346
https://zhuanlan.zhihu.com/p/31620134167
Related works中值得深挖的工作
资料查询
折叠Title
FromChatGPT(提示词:XXX)本文来自博客园,作者:fariver,转载请注明原文链接:https://www.cnblogs.com/fariver/p/18922503

 浙公网安备 33010602011771号
浙公网安备 33010602011771号