[PaperReading] ZeRO Memory Optimizations Toward Training Trillion Parameter Models
名称
link
时间:19.10
单位:microsoft
作者相关工作:https://i.cnblogs.com/posts/edit;postId=18916963
deepspeed, zero-infinity, deepspeed-moe, deepspeed fastgen, deepspeed-drive
被引次数:1647
TL;DR
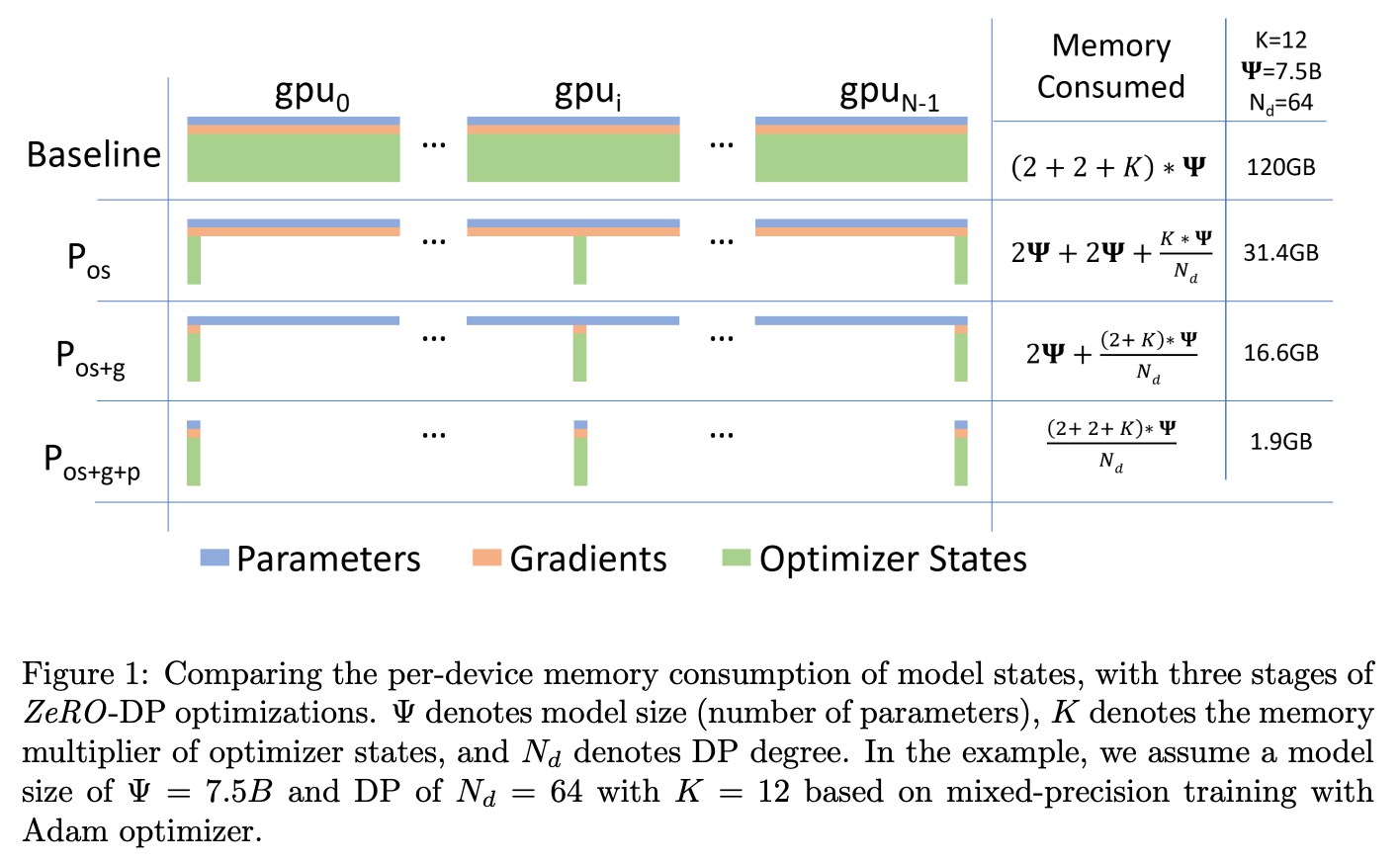
ZeRO全称Zero Redundancy Optimizer,译为 零冗余优化。针对于DP与MP的冗余问题进行优化:DP(数据并行)在每张卡都会保存完整model state,有显存上的冗余;MP(模型并行,将不同Layer切到不同GPU上),不同模型切片有前后同步的依赖关系,有通信与计算上的冗余。为了优化上述冗余,本文提出ZeRO-DP,三阶段优化普通DP中模型状态冗余(优化器状态\(P_os\) -> 梯度\(P_{os + g}\)->参数\(P_{os+g+p}\))。除此之外,本文还提出ZeRO-R,针对非模型状态的剩余内存优化,方法包括:\(P_a\)(Partitioned Activation), \(C_B\)(Constant Size Buffers), \(M_D\)(Memory Defragmentation)
Method
ZeRO-DP
三个阶段model state切分方式
| 切分对象 | 切分维度 | 分区方式 |
|---|---|---|
| 优化器状态 (Pos) | 按数据并行组 (DP Group) | 垂直切分:每个GPU仅存储自己负责的优化器状态(如动量/方差)。 |
| 梯度 (Pg) | 按参数张量维度 | 水平切分:每个GPU存储完整参数的梯度子集(如参数行)。 |
| 参数 (Pp) | 按参数张量维度 | 水平切分:每个GPU仅存储完整参数的子集(如参数矩阵行),其他部分按需广播。 |
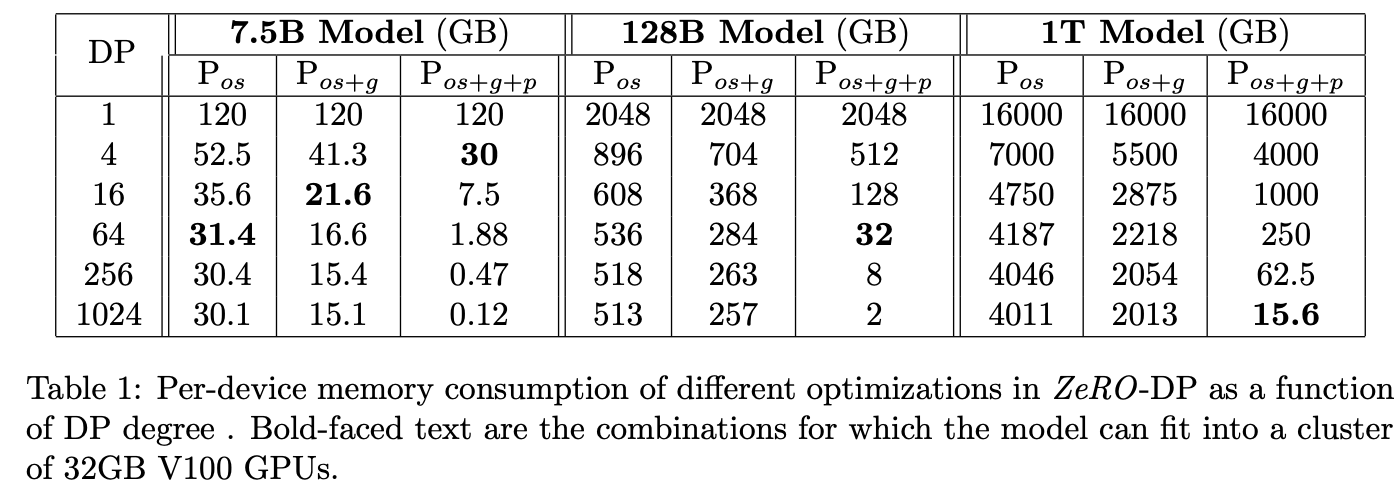
协同工作示例(以7.5B模型+64-way DP为例)
- 前向传播:
- 参数通过All-Gather临时重建完整矩阵(通信3Ψ)。
- 计算后丢弃非本地参数,仅保留本地激活分区(ZeRO-R的Pa)。
- 反向传播:
- 再次All-Gather参数计算梯度,生成分区梯度(Pg)。
- 通过All-Reduce聚合梯度(通信2Ψ)。
- 优化器更新:
- 每个GPU仅更新本地优化器状态(Pos),无需通信。
效果
从Figure1来看,\(P_os\)降低显存效果最明显,其次是\(P_g\)与\(P_p\)。
ZeRO-R
背景
在模型训练中,除模型状态(参数、梯度、优化器状态)外,还有三类主要内存开销:
| 类型 | 描述 | 典型值(1.5B参数模型) |
|---|---|---|
| 激活值(Activations) | 前向传播中每层的输出(需保存以供反向传播) | 60GB(GPT-2类模型) |
| 临时缓冲区(Temporary Buffers) | 用于存储计算中间结果(如梯度聚合、损失计算) | 6GB |
| 内存碎片(Memory Fragmentation) | 频繁内存分配/释放导致的不连续空间浪费 | 占用可用内存的30% |
优化策略
激活分区(Pa, Partitioned Activations)
原理:每个GPU仅存储activation的部分切片,反传时使用All-gather获得完整激活。
节省效果:激活内存从 \(O(N·L)\) 降至 \(O(N·L / P)\)(P=分区数)。
示例:4-way MP下,60GB激活→15GB。
通信代价:反向传播时需通过all-gather重建完整激活,增加约10%通信量。
固定缓冲区(CB, Constant Size Buffers)
问题:临时缓冲区(如梯度聚合区)默认随模型参数量增长。
解决:预定义固定大小的缓冲区(如1GB),通过分块处理大张量。
示例:梯度聚合时,分多次处理1GB数据块,而非一次性分配6GB。
优势:避免缓冲区占用失控(尤其对万亿参数模型)。
内存整理(MD, Memory Defragmentation)
问题:频繁内存分配/释放导致碎片化(类似磁盘碎片)。
解决:
- 预分配连续内存池:训练前统一分配大块内存,避免运行时动态分配
- 主动合并空闲块:定期整理碎片化内存
效果:可用内存提升30%,减少OOM概率。
小结
| 概念 | 作用对象 | 优化目标 | 关键区别 |
|---|---|---|---|
| ZeRO-DP | 模型状态 | 消除DP的内存冗余 | 分区模型状态,动态通信调度 |
| ZeRO-R | 剩余内存 | 优化激活/缓冲区/碎片 | 与MP协同减少激活内存 |
| Pos | 优化器状态 | 首阶段内存节省(4x) | 仅分区优化器状态,不影响通信 |
| Pos+g | 优化器状态+梯度 | 中阶段内存节省(8x) | 增加梯度分区,保持通信效率 |
| Pos+g+p | 全模型状态 | 终极内存节省(Ndx) | 参数分区,通信量略增(1.5x) |
| CB | 临时缓冲区 | 平衡内存与计算效率 | 固定大小,避免大模型缓冲区爆炸 |
| MD | 内存碎片 | 提高内存利用率 | 主动整理碎片,减少OOM概率 |
Experiment
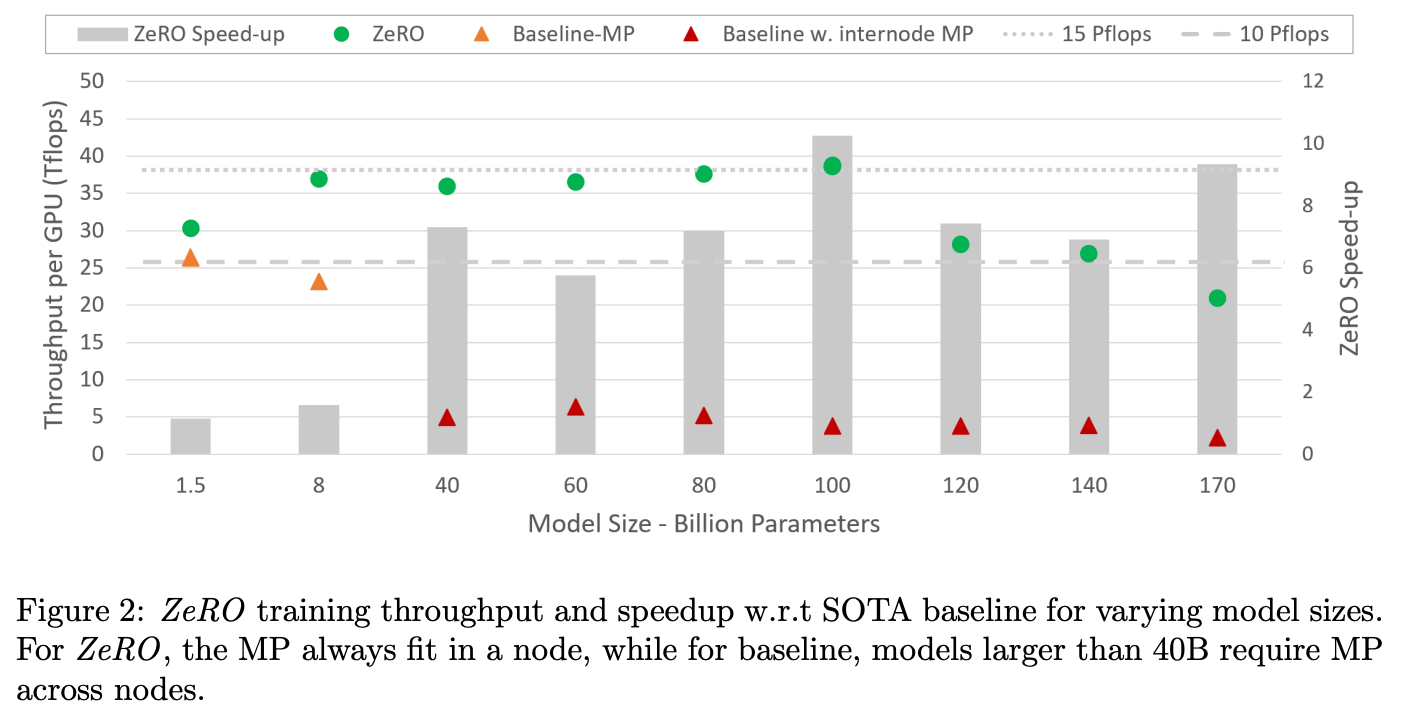
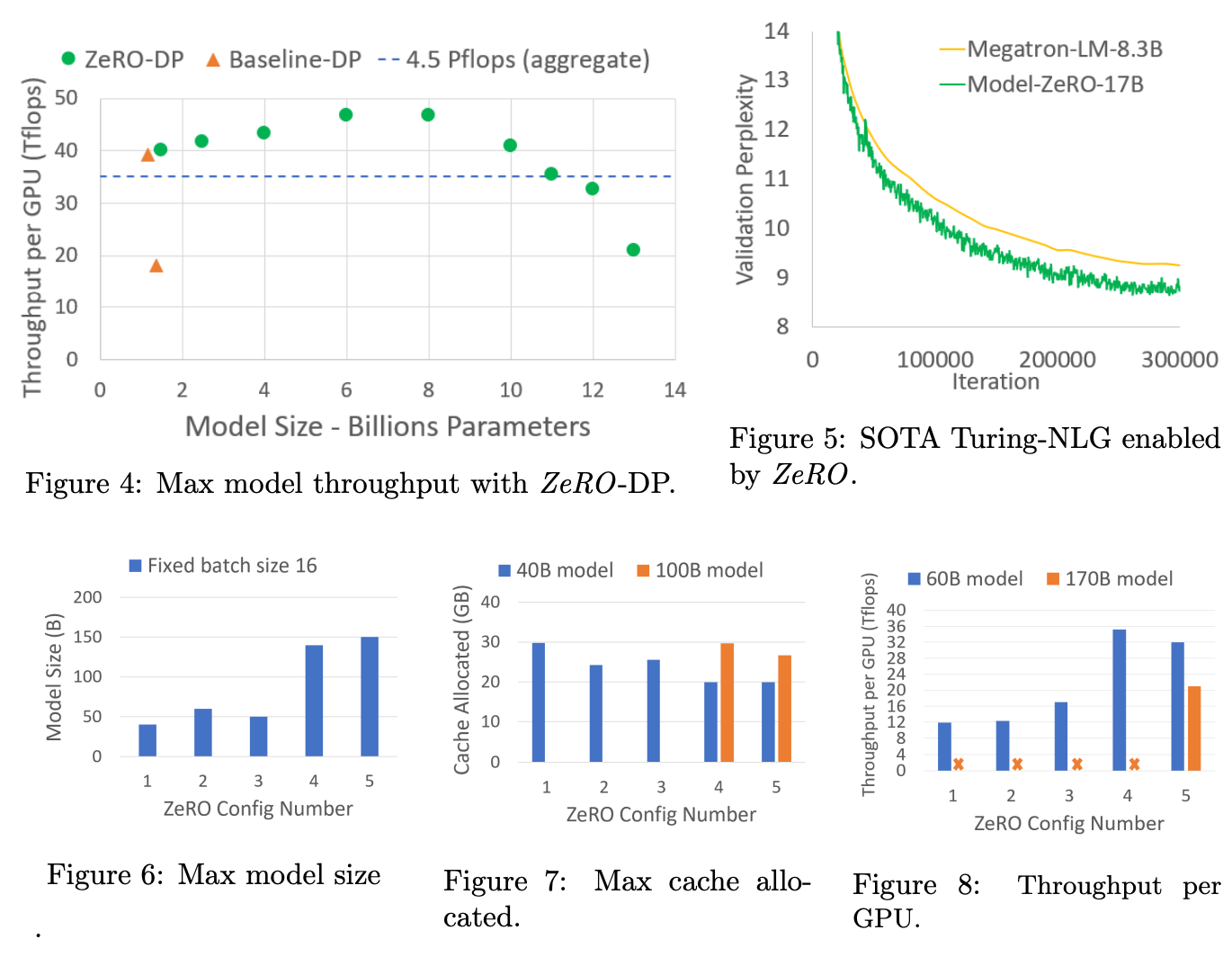
效果可视化
无
总结与思考
无
相关链接
fariver DeepSpeed blog
deepspeed官方:https://github.com/deepspeedai/DeepSpeed
https://zhuanlan.zhihu.com/p/1903086549580620372
https://zhuanlan.zhihu.com/p/30490173978
本文来自博客园,作者:fariver,转载请注明原文链接:https://www.cnblogs.com/fariver/p/18916963

 浙公网安备 33010602011771号
浙公网安备 33010602011771号