[PaperReading] FlashAttention: Fast and Memory-Efficient Exact Attention with IO-Awareness
FlashAttention: Fast and Memory-Efficient Exact Attention with IO-Awareness
link
时间:22.06
单位:Stanford
作者相关工作:Mamba
被引次数:2337
主页:https://github.com/Dao-AILab/flash-attention
TL;DR
提出IO-aware的FlashAttention算法通过减少GPU HBM与片上内存的读写次数,提升推理速度(GPT2上加速2.2倍,更长context情况下加速2.4倍)。同时,提出block-sparse FlashAttention,是一种Attention近似算法,速度优于现有的其它Attention近似算法。FlashAttention对于更长上下文建模有速度与效果上的优势。
Method
如Figure1左图所示,HBM读写速度为1.5TB/s,SRAM读写速度为19TB/s远大于HBM。本工作基于此观察,设计Tiling机制:将Attention计算分成若干Block,每个Block Size刚好匹配SM的SRAM大小,每个Block将Attention的所有操作合并完成再写回HMB。backward时利用recomputation重新计算梯度反传所需要结果。
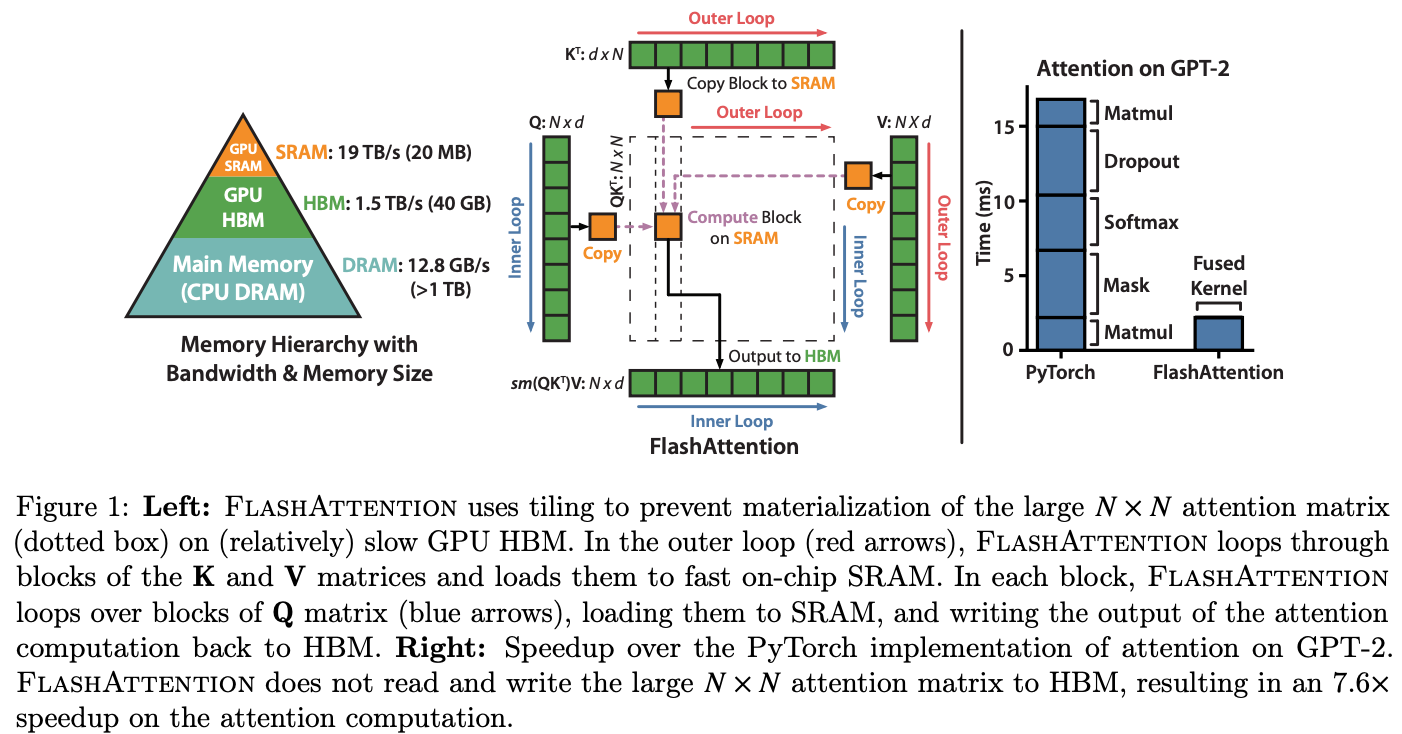
FlashAttention算法详解


Attention算法核心计算过程如Algorithm0所示,除了softmax需要矩阵K列的维度全局统计指数和之外,其它计算都可拆成小块进行。
FlashAttention:
- 将Q/K/V按行拆成若干小矩阵,分别计算目标矩阵\(O\)的子矩阵\(O_i\) (每个子矩阵的列数为d是特征dim)
- 指数和的解决办法:在每个block计算完之后都会统计出当前指数和\(l_i\),并根据\(l_i\)修正本次计算出来的整个\(O_i\),当内层for循环过完之后,\(O_i\)也会修正为所求解的正确值。
- 伪代码表面上是for循环,实际上是不同SM在并发执行
- 为了防止指数数值溢出,参考已有工作将softmax进行变形所以伪代码看起来复杂一些。
![]()
![]()
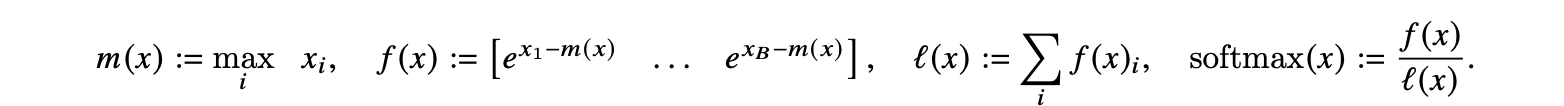

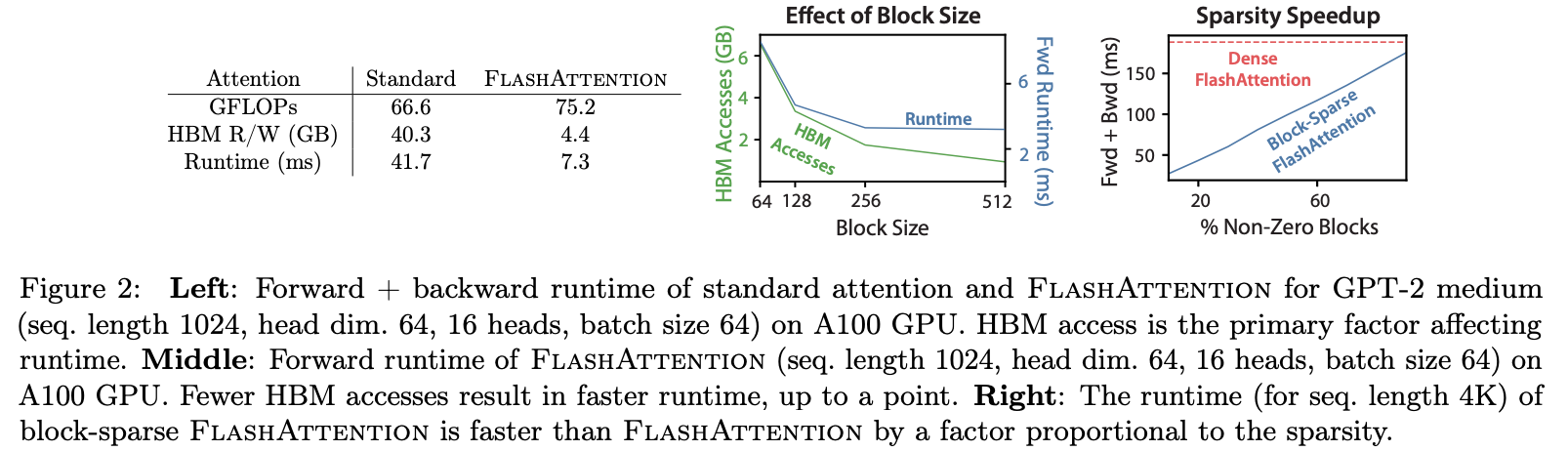
Sparse FlashAttention
其中mask(稀疏注意力掩码)的来源可以是用户自定义的输入参数,也可以通过特定算法(例如Butterfly)自动生成。

Experiment
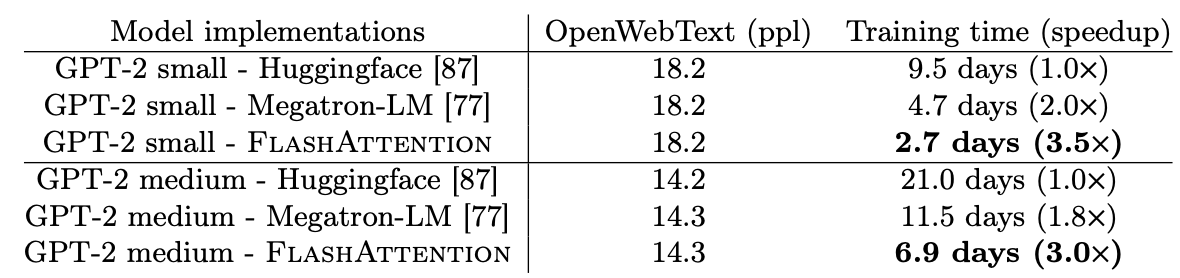
对比Huggingface与Megatron-LM的训练速度
相对于FlashAttention相对于普通Transformer、Spase FlashAttention与其它近似Attention之间的效果与速度对比。

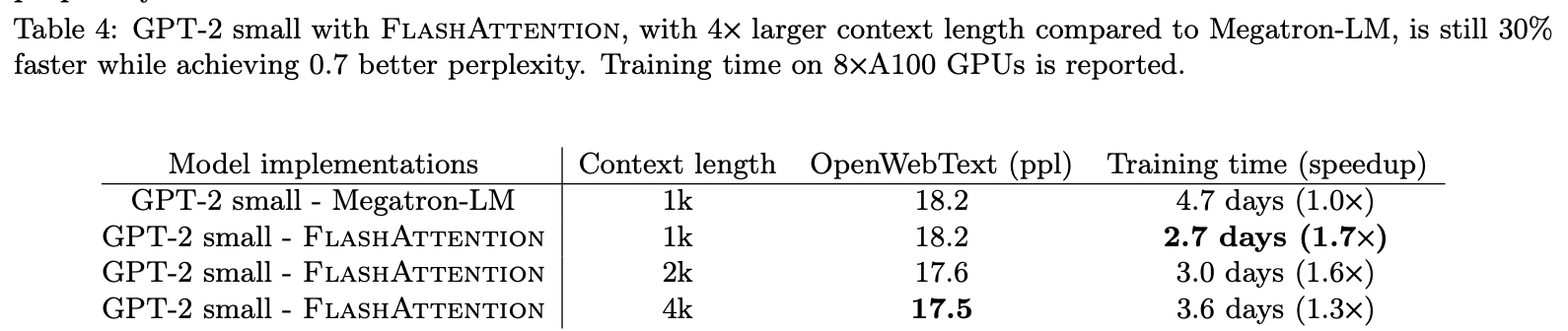
FlashAttention在Larger context length的提升
Q&A
Q: 为什么FlashAttention能够提升long context的效果?
A: FlashAttention在提升模型效果方面的能力并非来自算法本身的创新性优化,而是Attention计算过程占用显存更小,通过解锁传统注意力无法实现的长序列建模能力和更高效的训练动态间接实现的。
- 传统注意力:由于内存消耗为 \(O(N^2)\),序列长度N通常被限制在1K-2K(如BERT的512)。
- FlashAttention:内存降至\(O(N)\),允许训练N=64K甚至更长的序列。
总结与思考
暂无
相关链接
https://zhuanlan.zhihu.com/p/714881594
https://www.zhihu.com/question/611236756/answer/3132304304
https://zhuanlan.zhihu.com/p/2132459108
本文来自博客园,作者:fariver,转载请注明原文链接:https://www.cnblogs.com/fariver/p/18912911

 浙公网安备 33010602011771号
浙公网安备 33010602011771号