
[PaperReading] PyTorch FSDP: Experiences on Scaling Fully Sharded Data Parallel
PyTorch FSDP: Experiences on Scaling Fully Sharded Data Parallel
link
时间:23.04
单位:Meta
被引次数:363
主页:
https://docs.pytorch.org/docs/stable/fsdp.html
https://engineering.fb.com/2021/07/15/open-source/fsdp/
TL;DR
Pytorch官方提供的大模型训练训练推理接口,垂直方向将不同Layer划分为不同unit组,水平方向将weights分到不同device,Forward与Backward时All-gather回来进行计算。
Method
模型整体拆法如Fitgure1所示,FSDP的sharding主要指得是水平方向将weights切分到不同device存储,垂直方向仅仅是逻辑上的分组,方便sharding的分组管理。
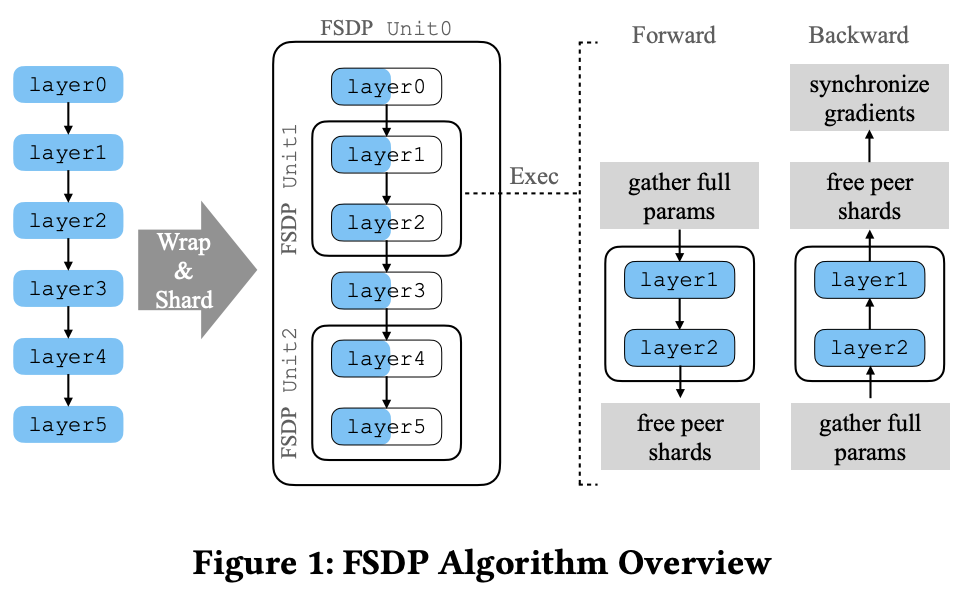
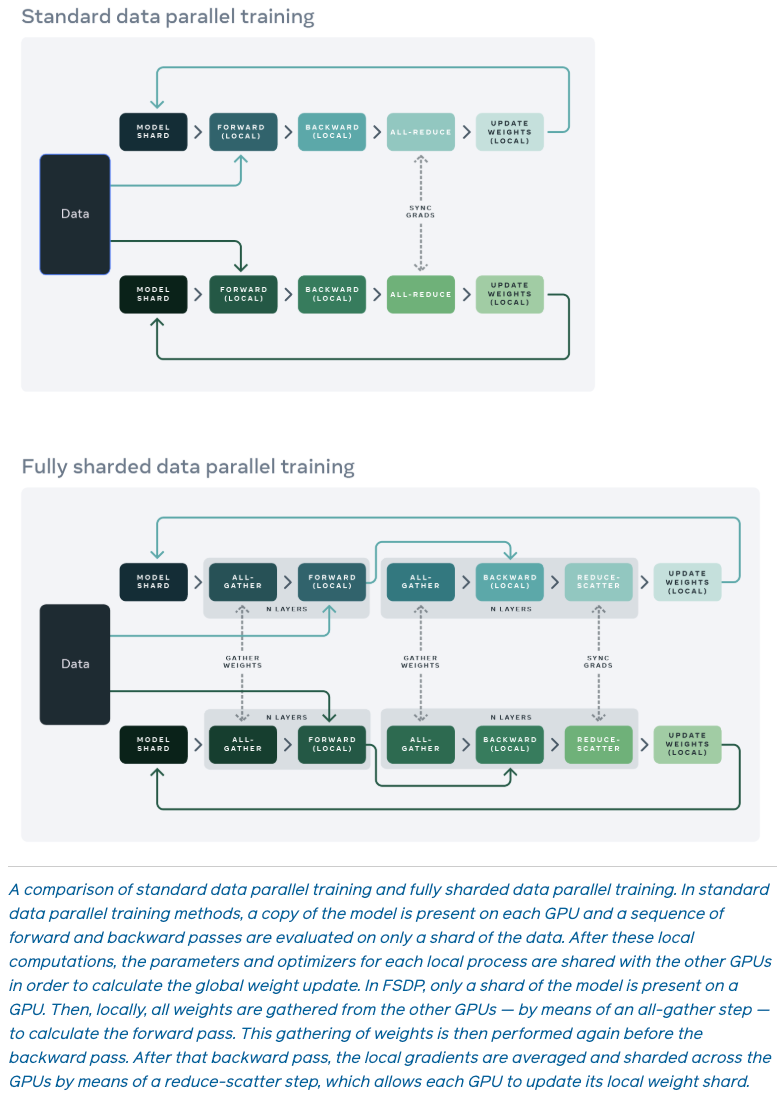
水平拆分参考官方blog里面的介绍图。相比与传统Data Parallel,FSDP每个device仅持有\(1/N\) unit组模型的参数切片,在Forward与Backward之前,需要先All-gather拿到该unit组的完整模型,计算完成将peer devices的参数扔掉。
System Design
Model Initialization
核心问题
- 挑战1:传统PyTorch要求模型参数在初始化时全量驻留GPU内存,无法直接初始化超大模型(如参数>单卡显存)。
- 挑战2:用户自定义的初始化逻辑(如参数依赖其他模块的参数)需在分片后保持正确性。
解决方案:Deferred Initialization(延迟初始化)
- 假设备(Fake Device):在初始化阶段,参数存储在虚拟设备(如meta设备)上,仅记录形状和初始化操作(如nn.init.kaiming_normal_),不分配实际存储,不做任何初始化动作。优势:避免OOM,支持任意规模模型的初始化。
- 按需分片初始化:将模型分解为多个FSDP单元(unit),逐个单元移动到真实GPU,执行记录的初始化操作后立即分片。
- 处理依赖:若单元A依赖单元B的参数,FSDP临时恢复B的完整参数,初始化完成后再次分片。
以下是 PyTorch FSDP 论文第三章《SYSTEM DESIGN》各小节的详细解析,结合算法原理、设计动机和实现细节进行说明:
Sharding Strategies(分片策略)
Full Sharding(完全分片)
- 机制:参数沿(num_params / world_size)均匀分片,每卡仅保留局部分片。计算前通过AllGather恢复完整参数,计算后立即释放非本地分片(ReduceScatter聚合梯度)。
- 问题:直接分片单个参数导致通信效率低(小张量过多)。
- 方案:将多个参数拼接为连续的FlatParameter,分片后每卡获得等大的连续块。填充对齐:确保FlatParameter总长度可被world_size整除,最小化填充开销。优势:减少通信次数,提升带宽利用率(见图2实验)。
FlatParameter示意图
![]()
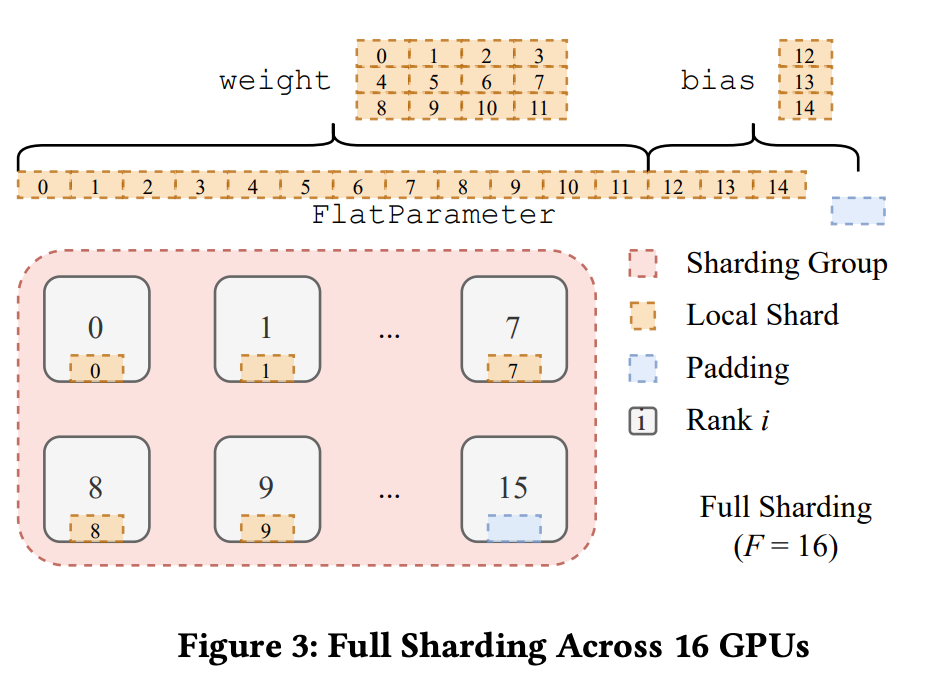
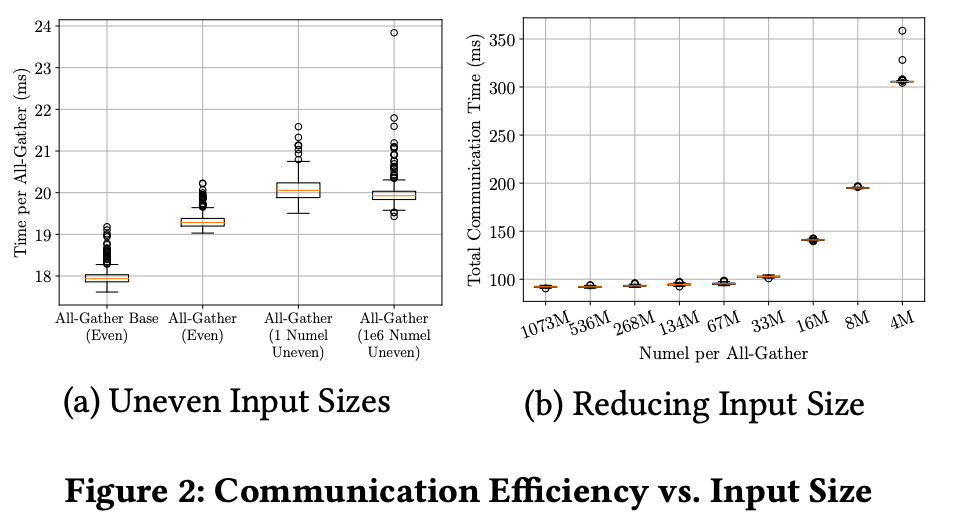
图2表明:a.切片参数越均匀,通信成本越小;b.通信总数据量相同情况下,数据块越大通信成本越低;
Hybrid Sharding(混合分片)
- 应用场景:模型略大于单卡显存,但Full Sharding通信开销又太大。
- 设计:将设备分为多个分片组(Sharding Group)和复制组(Replication Group)。
- 分片组内:参数分片存储,组内AllGather/ReduceScatter。
- 复制组间:组间AllReduce同步梯度。
优势: - 减少跨节点通信(如分片组限制在同一节点内)。
- 支持灵活调整分片因子(sharding_factor),平衡内存与吞吐。
Communication Optimizations(通信优化)
Overlapping Communication and Computation (通信与计算时间重叠)
- 问题:AllGather在通信过程会阻塞计算。
- 方案:a.使用独立CUDA流发起通信,与计算流并行;b.同步机制:通过work.wait()确保计算依赖的通信完成;
Backward/Forward Prefetching
我们知道FSDP在Forward与Backward前有All-Gather操作会引发通信延迟,Prefetching机制使得该通信操作提前进行,使得通信与计算时间重叠。有空Backward Prefetching的对比参考Figure6 b实验。
Gradient Accumulation(梯度累积)
- 带通信:多步累积后ReduceScatter,内存友好。
- 无通信:保留完整梯度(更高内存),减少通信次数。
Memory Management(内存管理)
- 问题:CUDA缓存分配器:频繁分配/释放导致内存碎片,尤其在多流场景下。FSDP痛点:AllGather流(生产者)与计算流(消费者)竞争内存块,可能触发阻塞式cudaMalloc重试。
- 解决方案:Rate Limiter(速率限制器)
- 限制最大在途AllGather数量(默认2),避免生产者过快耗尽内存。
- 通过torch.cuda.memory_stats()监控num_alloc_retries,动态调整限制。
效果:减少碎片化,提升吞吐(见图6c实验对比)。
Code && Implementation
暂无
Experiment
Figure6 b实验说明在2.8B及以下模型尺寸实验上,使用FSDP与DDP的性能接近。
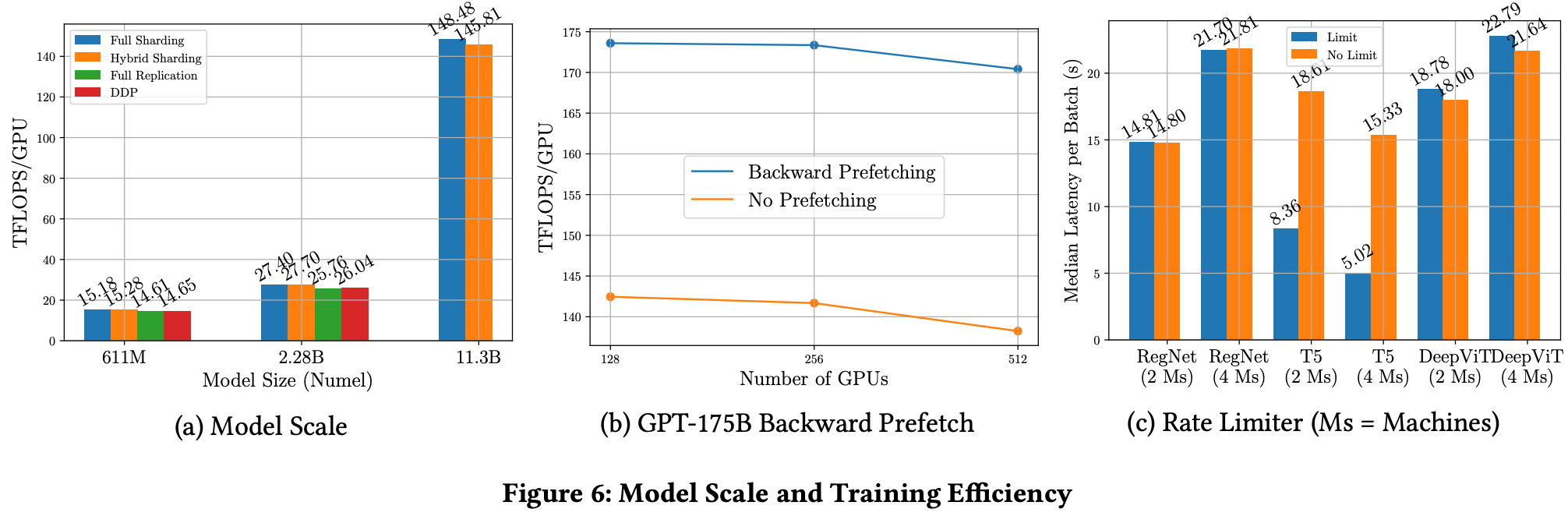
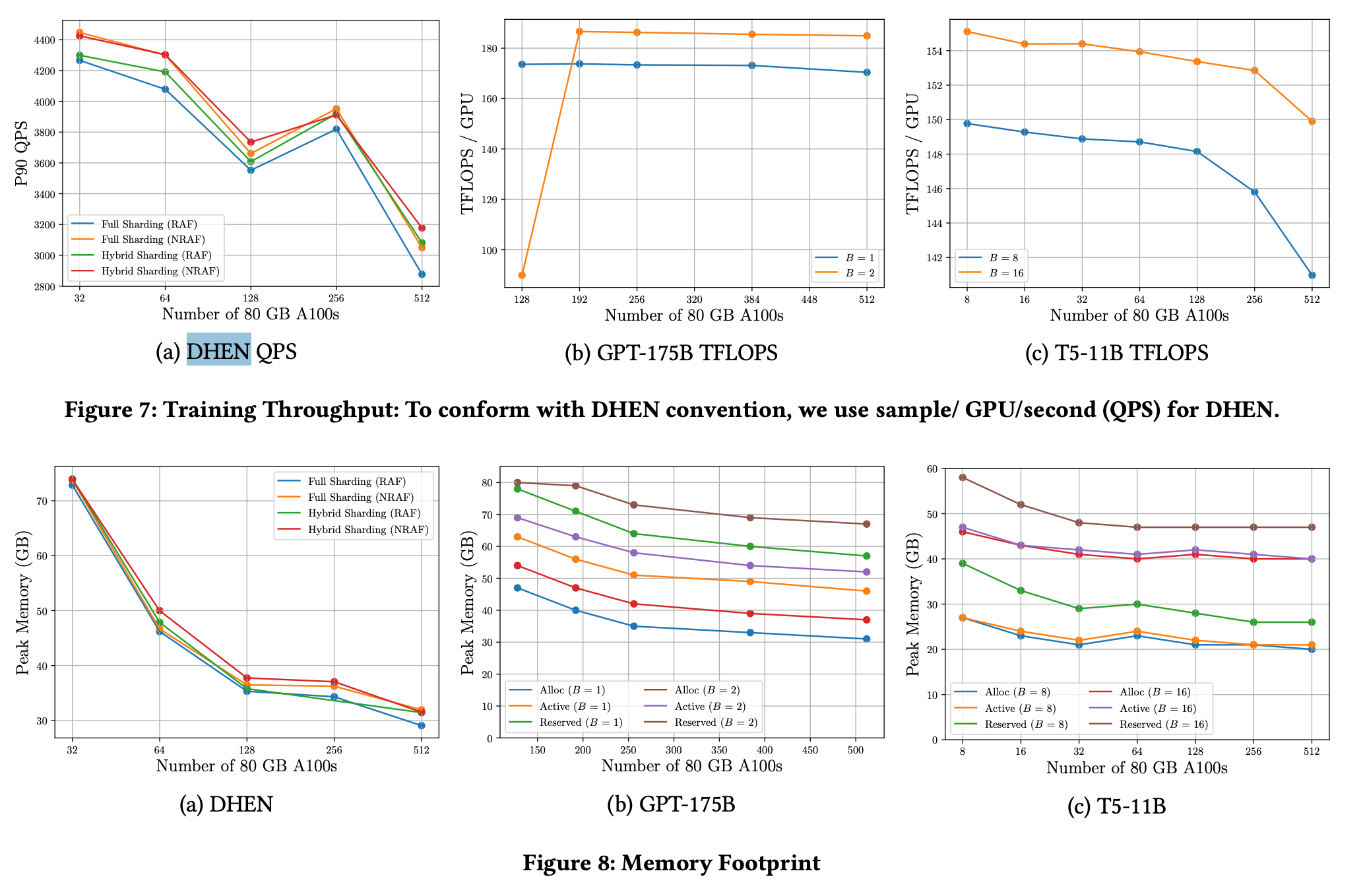
- Figure7c看出当GPU达到512时,平均每张卡的吞吐量会下降7%,说明此时的通信与计算开销已经不能很好的重叠了。
- Figure7b的单卡吞吐量明显较低,这是因为在128GPUs外加GPT175B的情况下,反传过程更容易触发CUDA内存整理。
![]()
Q&A
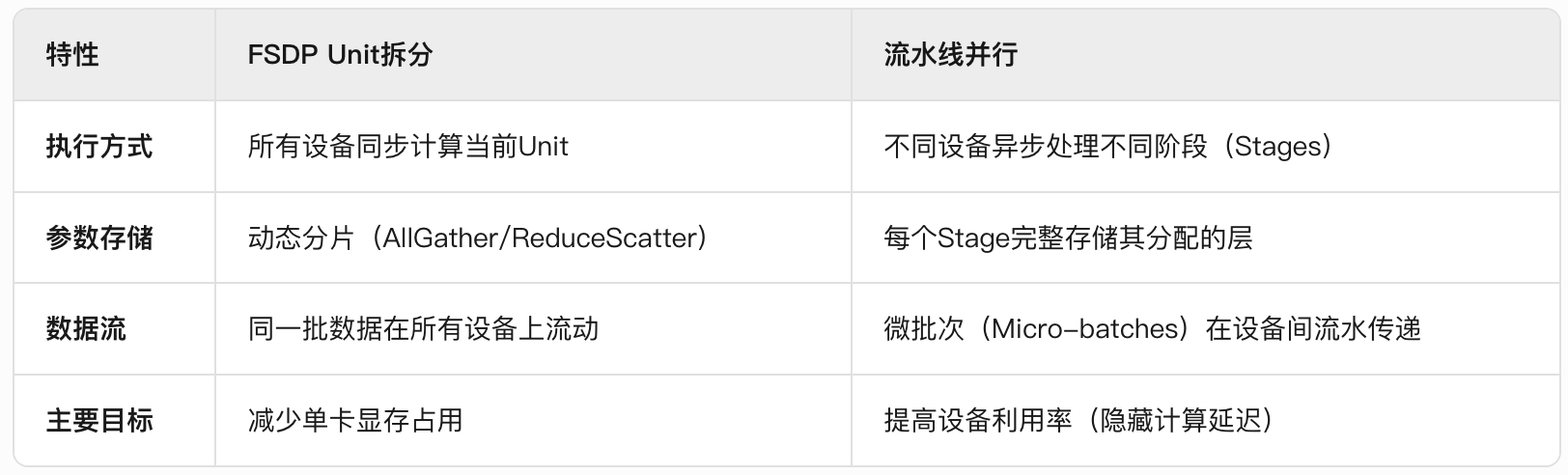
Q: FSDP的垂直方向分组与Pipeline Parallelism有什么区别?
A: FSDP中的水平Unit拆分(如将模型按层分组)本质上是为了更灵活地控制参数分片(Sharding)的粒度,而非将不同Unit分配到不同设备组上串行执行。 这与流水线并行(Pipeline Parallelism)的物理阶段划分有根本区别。
总结与思考
- FSDP仍然属于数据并行,因为计算的时候还是All-Gather原始的全部参数来计算的,而不是像tensor parallel那样只拿weight的分片计算。
相关链接
https://zhuanlan.zhihu.com/p/694288870
https://docs.pytorch.org/docs/stable/fsdp.html
https://engineering.fb.com/2021/07/15/open-source/fsdp/
Related works中值得深挖的工作
本工作受Zero-DP启发,可以对比来看两个工作。
本文来自博客园,作者:fariver,转载请注明原文链接:https://www.cnblogs.com/fariver/p/18916961

 浙公网安备 33010602011771号
浙公网安备 33010602011771号