[PaperReading] Megatron: Reducing Activation Recomputation in Large Transformer Models
Megatron: Reducing Activation Recomputation in Large Transformer Models
link
时间:22.05
单位:NVIDIA
相关领域:MLSys(Machine Learning and Systems) 是一个专注于机器学习与系统交叉领域的顶级国际学术会议,旨在推动机器学习算法与底层计算系统的协同设计与优化。
作者相关工作:https://scholar.google.com/citations?user=iwWl6AwAAAAJ&hl=en&oi=sra
被引次数:281
开源版本:https://github.com/NVIDIA/Megatron-LM
官方维护版本:https://developer.nvidia.com/nvidia-nemo
TL;DR
本文提出两种大模型训练系统性能优化:Sequence Parallelism与Selective Activation Recomputation。相对于Naive训练方案显存节约5倍,相对于Activation Recompuation节省了90%的激活重复计算。MFU(Model Flops Utilization)从42.1%提升至54.2%。
Method
SP(Sequence Parallelism、序列并行)
张量并行对于Attention、MLP这类操作比较容易并行,但对于LayerNorm这种依赖全局统计量的操作,之前的做法是各卡维护全部token计算,重复计算量较大。本文使用对LayerNorm,通过序列并行将token sequence沿着sequence的维度拆分,不同卡单独的统计量mean与variance,再通过All-Reduce mean来得到全局统计量(仅mean与variance的同步量,通信成本较低)。获取全局统计量后,各卡单独进行归一化操作。

Selective Recomputation
Transformer Layer的显存计算公式如下,通常情况下\(5as/h>34\),如果将贡献\(5as/h\)部分的显存使用Recomputation的方法来获取Activation,那么将节省大部分显存。例如,针对GPT-3模型架构\(5as/h= 80\),将这部分Recomputation则可以节省70%的显存。

Code && Implementation
Waiting For Update
Experiment
显存节省参考Figure7的黄色,虽然不及完全Activation Recomputation(绿色),但也比较接近。同时,前传+反传 速度也衰退不明显,由19ms降至20.3ms衰退仅4%。
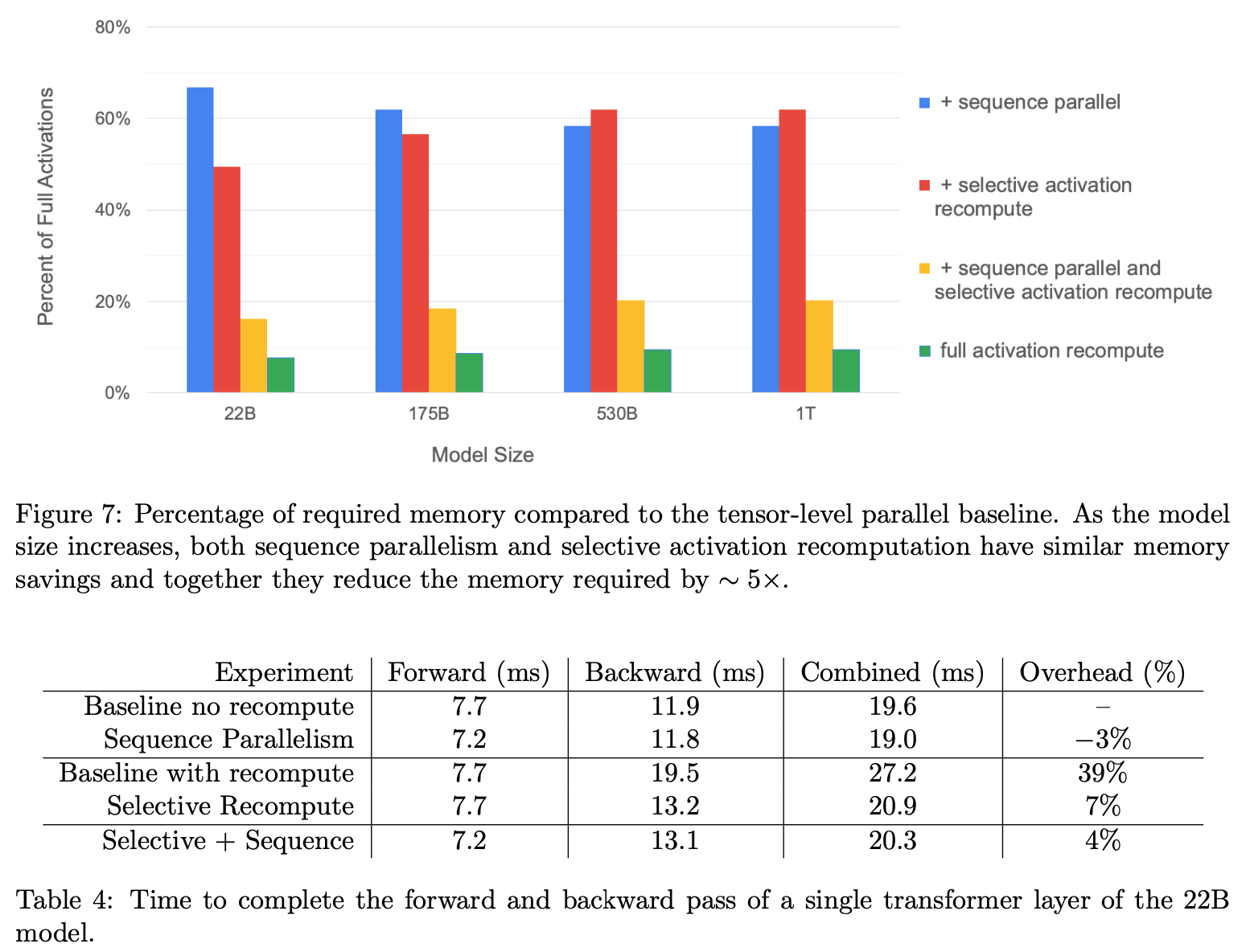
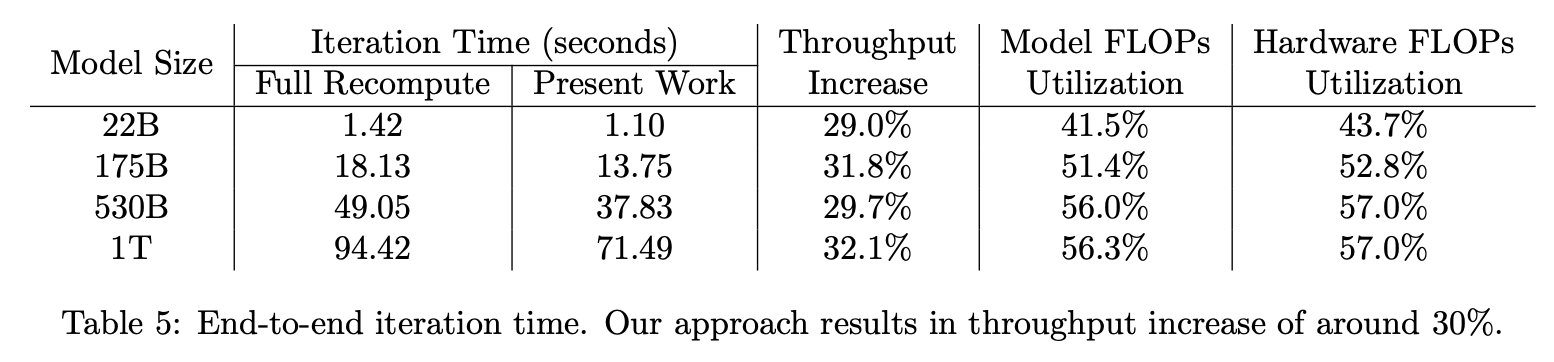
MFU达到56.3%
总结与思考
暂无
相关链接
本文来自博客园,作者:fariver,转载请注明原文链接:https://www.cnblogs.com/fariver/p/18901293

 浙公网安备 33010602011771号
浙公网安备 33010602011771号