
摘要:  作为`结构化推理`的坚定支持者,我一度对MCP感到困惑:Agent和工具调用的概念早已普及,为何还需要MCP这样的额外设计呢?本文就来深入探讨MCP,看看它究竟解决了什么问题。我们将分几章解析MCP:本章理清基础概念和逻辑,后面我们直接以一个Agent为例演示全MCP接入的实现方案。 阅读全文
作为`结构化推理`的坚定支持者,我一度对MCP感到困惑:Agent和工具调用的概念早已普及,为何还需要MCP这样的额外设计呢?本文就来深入探讨MCP,看看它究竟解决了什么问题。我们将分几章解析MCP:本章理清基础概念和逻辑,后面我们直接以一个Agent为例演示全MCP接入的实现方案。 阅读全文
作为`结构化推理`的坚定支持者,我一度对MCP感到困惑:Agent和工具调用的概念早已普及,为何还需要MCP这样的额外设计呢?本文就来深入探讨MCP,看看它究竟解决了什么问题。我们将分几章解析MCP:本章理清基础概念和逻辑,后面我们直接以一个Agent为例演示全MCP接入的实现方案。 阅读全文
posted @ 2025-08-06 07:30
风雨中的小七
阅读(743)
评论(2)
推荐(0)
 承接上篇对Context Engineering的探讨,本文将聚焦多智能体框架中的上下文管理实践。我们将深入剖析两个代表性框架:字节跳动开源的基于预定义角色与Supervisor-Worker模式的 Deer-Flow ,以及在其基础上引入动态智能体构建能力的清华CoorAgent。通过对它们设计思路和实现细节的拆解,提炼出多智能体协作中高效管理上下文的关键策略。
承接上篇对Context Engineering的探讨,本文将聚焦多智能体框架中的上下文管理实践。我们将深入剖析两个代表性框架:字节跳动开源的基于预定义角色与Supervisor-Worker模式的 Deer-Flow ,以及在其基础上引入动态智能体构建能力的清华CoorAgent。通过对它们设计思路和实现细节的拆解,提炼出多智能体协作中高效管理上下文的关键策略。  无论智能体是1个还是多个,是编排驱动还是自主决策,是静态预定义还是动态生成,Context上下文的管理机制始终是设计的核心命脉。它决定了:每个节点使用哪些信息?分别更新或修改哪些信息?多步骤间如何传递?智能体间是否共享、如何共享?后续篇章我们将剖析多个热门开源项目,一探它们如何驾驭Context。
无论智能体是1个还是多个,是编排驱动还是自主决策,是静态预定义还是动态生成,Context上下文的管理机制始终是设计的核心命脉。它决定了:每个节点使用哪些信息?分别更新或修改哪些信息?多步骤间如何传递?智能体间是否共享、如何共享?后续篇章我们将剖析多个热门开源项目,一探它们如何驾驭Context。  在大模型驱动的时代,向量模型、索引抽取模型、文本切分模型(chunking)的迭代速度令人目不暇接,几乎每几个月就要升级一次。随之而来的,是Elasticsearch索引结构的频繁变更需求。然而,ES有个众所周知的‘硬伤’:一旦字段的mapping设定,就无法直接修改!
在大模型驱动的时代,向量模型、索引抽取模型、文本切分模型(chunking)的迭代速度令人目不暇接,几乎每几个月就要升级一次。随之而来的,是Elasticsearch索引结构的频繁变更需求。然而,ES有个众所周知的‘硬伤’:一旦字段的mapping设定,就无法直接修改!  记忆存储是构建智能个性化、越用越懂你的Agent的核心挑战。上期我们探讨了模型方案实现长记忆存储,本期将聚焦工程实现层面。
- What:记忆内容(手动管理 vs 自动识别)
- How:记忆处理(压缩/抽取 vs 直接存储)
- Where:存储介质(内存/向量库/图数据库)
- Length:记忆长度管理(截断 vs 无限扩展)
- Format:上下文构建方式
- Retrieve:记忆检索机制
记忆存储是构建智能个性化、越用越懂你的Agent的核心挑战。上期我们探讨了模型方案实现长记忆存储,本期将聚焦工程实现层面。
- What:记忆内容(手动管理 vs 自动识别)
- How:记忆处理(压缩/抽取 vs 直接存储)
- Where:存储介质(内存/向量库/图数据库)
- Length:记忆长度管理(截断 vs 无限扩展)
- Format:上下文构建方式
- Retrieve:记忆检索机制  Context Cache的使用几乎已经是行业共识,目标是优化大模型首Token的推理延时,在多轮对话,超长System Prompt,超长结构化JSON和Few-shot等应用场景,是不可或缺的。这一章我们主要从原理、一些论文提出的优化项和VLLM开源项目入手,分析下context Cache的实现和适合场景。
Context Cache的使用几乎已经是行业共识,目标是优化大模型首Token的推理延时,在多轮对话,超长System Prompt,超长结构化JSON和Few-shot等应用场景,是不可或缺的。这一章我们主要从原理、一些论文提出的优化项和VLLM开源项目入手,分析下context Cache的实现和适合场景。  本章主要覆盖以下
多Query向量查询的各种方案:Script,Knn(mesearch)
KNN查询IOUtil过高问题排查
如何使用Filter查询更高效
本章主要覆盖以下
多Query向量查询的各种方案:Script,Knn(mesearch)
KNN查询IOUtil过高问题排查
如何使用Filter查询更高效 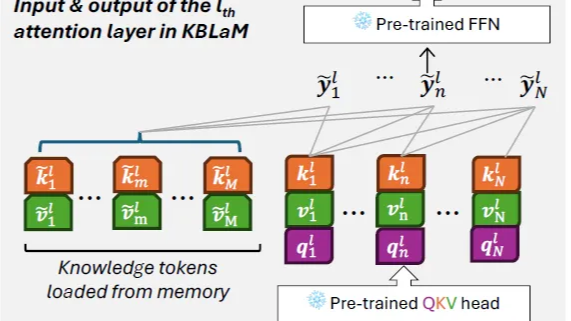 上一章畅想里面我们重点提及了大模型的记忆模块,包括模型能否持续更新记忆模块,模型能否把持续对记忆模块进行压缩更新在有限的参数中存储更高密度的知识信息,从而解决有限context和无限知识之间的矛盾。这一章我们分别介绍两种方案,一种是基于模型结构的Google提出的Titan模型结构,另一种是基于外挂知识库表征对齐的Kbalm
上一章畅想里面我们重点提及了大模型的记忆模块,包括模型能否持续更新记忆模块,模型能否把持续对记忆模块进行压缩更新在有限的参数中存储更高密度的知识信息,从而解决有限context和无限知识之间的矛盾。这一章我们分别介绍两种方案,一种是基于模型结构的Google提出的Titan模型结构,另一种是基于外挂知识库表征对齐的Kbalm  在DeepSeek-R1的开源狂欢之后,感觉不少朋友都陷入了**技术舒适区**,但其实当前的大模型技术只是跨进了应用阶段,可以探索的领域还有不少,所以这一章咱不聊论文了,偶尔不脚踏实地,单纯仰望天空,聊聊还有什么有趣值得探索的领域,哈哈有可能单纯是最近科幻小说看太多的产物~
在DeepSeek-R1的开源狂欢之后,感觉不少朋友都陷入了**技术舒适区**,但其实当前的大模型技术只是跨进了应用阶段,可以探索的领域还有不少,所以这一章咱不聊论文了,偶尔不脚踏实地,单纯仰望天空,聊聊还有什么有趣值得探索的领域,哈哈有可能单纯是最近科幻小说看太多的产物~ 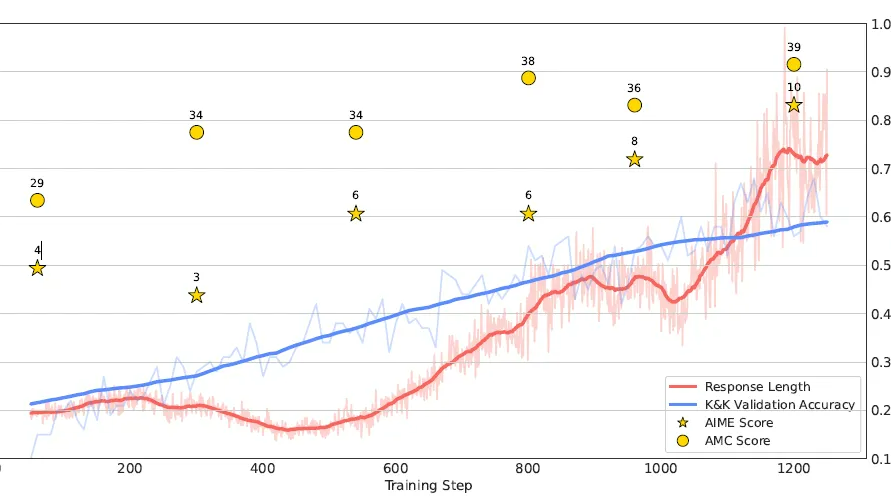 DeepSeek R1出来后业界都在争相复现R1的效果,这一章我们介绍两个复现项目SimpleRL和LogicRL,还有研究模型推理能力的Cognitive Behaviour,项目在复现R1的同时还针对R1训练策略中的几个关键点进行了讨论和消融实验,包括
DeepSeek R1出来后业界都在争相复现R1的效果,这一章我们介绍两个复现项目SimpleRL和LogicRL,还有研究模型推理能力的Cognitive Behaviour,项目在复现R1的同时还针对R1训练策略中的几个关键点进行了讨论和消融实验,包括  浙公网安备 33010602011771号
浙公网安备 33010602011771号