摘要:  这一章我们聊聊这两年注意力架构的技术演化路线
- KV Cache 压缩类:MQA → GQA → MLA(每个 token 的 KV 变细)
- 推理效率优化类:Flash Attention、Paged Attention(让 GPU 跑得更满)
- 长文本优化类:NSA → DSA → CSA + HCA(需要 attend 的 token 变少) 阅读全文
这一章我们聊聊这两年注意力架构的技术演化路线
- KV Cache 压缩类:MQA → GQA → MLA(每个 token 的 KV 变细)
- 推理效率优化类:Flash Attention、Paged Attention(让 GPU 跑得更满)
- 长文本优化类:NSA → DSA → CSA + HCA(需要 attend 的 token 变少) 阅读全文
这一章我们聊聊这两年注意力架构的技术演化路线
- KV Cache 压缩类:MQA → GQA → MLA(每个 token 的 KV 变细)
- 推理效率优化类:Flash Attention、Paged Attention(让 GPU 跑得更满)
- 长文本优化类:NSA → DSA → CSA + HCA(需要 attend 的 token 变少) 阅读全文
posted @ 2026-07-02 07:31
风雨中的小七
阅读(100)
评论(0)
推荐(0)
 有一阵没做游戏了,咱接着回来做中医游戏,这期咱们聊聊怎么给游戏NPC装个"智能大脑",顺便看看开发过程中Hook这个老朋友的新玩法。项目代码在这里[tcm_odyssey]
有一阵没做游戏了,咱接着回来做中医游戏,这期咱们聊聊怎么给游戏NPC装个"智能大脑",顺便看看开发过程中Hook这个老朋友的新玩法。项目代码在这里[tcm_odyssey]  本章我们尝试复现“图像文字元素编辑”功能,代码已经上传到Github。AI 生图配合文字元素编辑,确实能解决很多场景上AI生图无法直接落得的业务问题,感兴趣的朋友可以clone直接使用。
本章我们尝试复现“图像文字元素编辑”功能,代码已经上传到Github。AI 生图配合文字元素编辑,确实能解决很多场景上AI生图无法直接落得的业务问题,感兴趣的朋友可以clone直接使用。  话接上文,咱接着做中医小游戏。这一章我们会聊到:
- 开发流程中的核心实践:重构、版本控制、进度管理
- 技能进阶:创建技能、测试技能、提高技能引用率
- Claude Design 使用体验
话接上文,咱接着做中医小游戏。这一章我们会聊到:
- 开发流程中的核心实践:重构、版本控制、进度管理
- 技能进阶:创建技能、测试技能、提高技能引用率
- Claude Design 使用体验  话接上回,咱继续做中医小游戏,正所谓关关难过关关过,踩完这坑踩那坑。咱一边用Claude code构建我心中的“药灵山谷”,一边聊聊开发过程中碰到的好用的技能!
话接上回,咱继续做中医小游戏,正所谓关关难过关关过,踩完这坑踩那坑。咱一边用Claude code构建我心中的“药灵山谷”,一边聊聊开发过程中碰到的好用的技能!  这一章我们会解锁 Claude 的 teammate 模式,尝试开发一款 AI-oriented + 中医学习小游戏。在遍地都是“成功学”的今天,第一版游戏更像是大型事故现场>_<
这一章我们会解锁 Claude 的 teammate 模式,尝试开发一款 AI-oriented + 中医学习小游戏。在遍地都是“成功学”的今天,第一版游戏更像是大型事故现场>_<  这一章我们演示用龙虾制作我的专属技能-“中医方剂卡片”的全过程,同时轻度解密龙虾的几个核心设计,看看龙虾为何俘获了这么多人的心~
这一章我们演示用龙虾制作我的专属技能-“中医方剂卡片”的全过程,同时轻度解密龙虾的几个核心设计,看看龙虾为何俘获了这么多人的心~  本文不输出权威指南,只是一位一线算法工程师和AI不算peace的合作场景还原。系列第一篇,我们将从最基础的“磨合期”开始聊起。
技术标签:#opencode,#browser-use,#单智能体,#Agents.md
本文不输出权威指南,只是一位一线算法工程师和AI不算peace的合作场景还原。系列第一篇,我们将从最基础的“磨合期”开始聊起。
技术标签:#opencode,#browser-use,#单智能体,#Agents.md  在 LLM 发展的上半场,我们执着于不断拉长 Context Window,从 8K 到 128K 甚至百万级别。但在下半场我们围绕Coding这个核心视角来寻找一些新的上下文管理的思路
在 LLM 发展的上半场,我们执着于不断拉长 Context Window,从 8K 到 128K 甚至百万级别。但在下半场我们围绕Coding这个核心视角来寻找一些新的上下文管理的思路 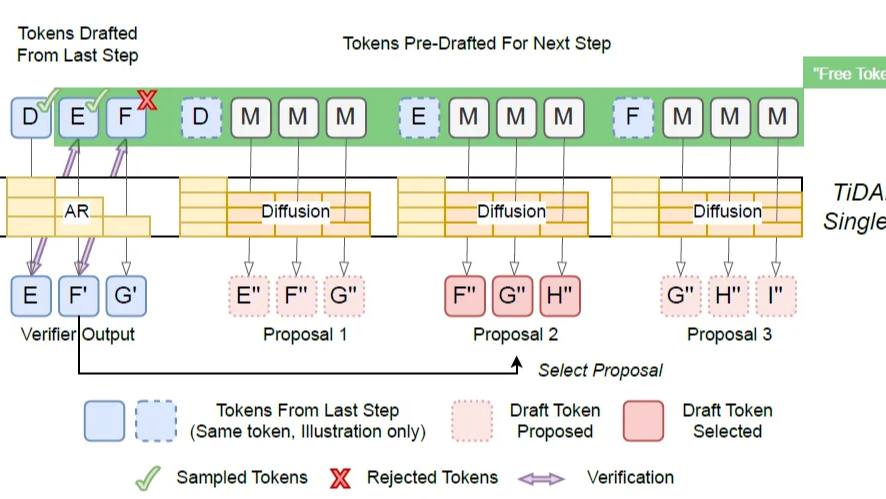 慢思考的本质依然是通过生成更多的显性 Token 来换取计算时间。为了想得深,必须说得多。这一章的四篇论文都在尝试:能否在不输出废话的情况下,让模型在内部“空转”思考? 甚至打破自回归全局规划?
慢思考的本质依然是通过生成更多的显性 Token 来换取计算时间。为了想得深,必须说得多。这一章的四篇论文都在尝试:能否在不输出废话的情况下,让模型在内部“空转”思考? 甚至打破自回归全局规划?  浙公网安备 33010602011771号
浙公网安备 33010602011771号