

随笔分类 - 深度学习
摘要:在我们已经训练好BERT后,BERT就可以对输入的每一个词元返回抽取了上下文信息的特征向量(也就是对于任意一个词元,将这个词元当做查询,所有词元当做键值对) 一些任务如下 这里将<cls>的特征向量传递给全连接层的原因就是因为<cls>本来就是用来分类的,所以肯定传这个。当然也可以传其他的,反正我们
阅读全文
摘要:想想吴恩达讲的CV里面,复用其他网络的结构,只在最后一层加入一个全连接层,对这个全连接层进行微调,也就是如下过程 那么CV里面可以这么用,NLP里面当然也可以这么用,如下 我们只需要调整这个新增加的简单输出层即可 BERT说白了,就是只有编码器的Transformer 他有两个版本,见下 block
阅读全文
摘要: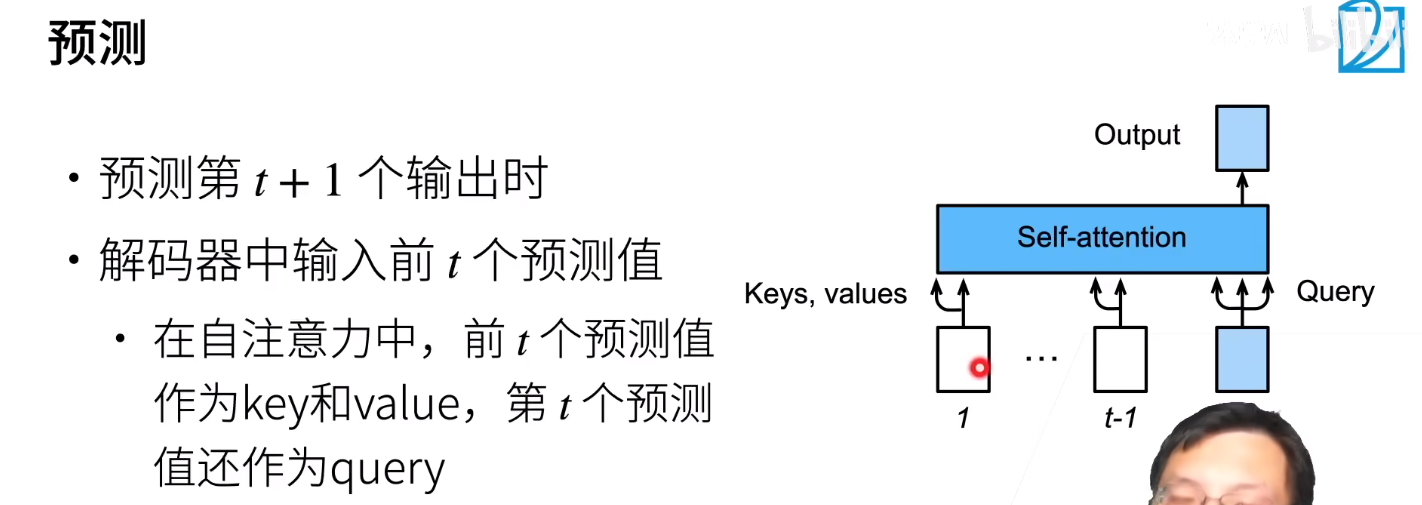
阅读全文
摘要:注意,我们这里必须要将输入的前两维(batch_size和num_steps)结合起来,而不能将后两维(num_steps和dimension)结合起来,因为这里num_steps是变化的(num_steps是我们指定的超参数,指定之后编码器-解码器的确只能处理固定长度的序列,因为有truncate
阅读全文
摘要:CNN怎么做序列?实际上之前已经接触过了,就是把序列当成没有高只有宽的图片而已 将书上讲的复杂度汇总如下 CNN 计算复杂度:进行一次卷积计算,由于卷积层大小为\(k\),输入有\(d\)个通道,所以复杂度为\(O(kd)\);由于序列长为\(n\),所以计算完输出的一个通道的时间复杂度为\(O(k
阅读全文
摘要:最后一段话各个句子的意思: ELMo将来自预训练的双向长短期记忆网络的所有中间层表示组合为输出表示:ELMo(Embeddings from Language Models)通过双向长短期记忆网络(BiLSTM)生成上下文敏感的词表示,其核心思想是结合双向LSTM所有层的中间表示,形成动态的词向量。
阅读全文
摘要:最后一段最后一句话的含义及示例说明: 核心问题:交叉熵损失在处理大型语料库中的罕见共现事件时,会赋予它们过高的权重,导致模型过度关注这些不常见的情况,从而影响整体性能。 具体解释 在跳元模型中,损失函数为: \[-\sum_{i \in V} \sum_{j \in V} x_{ij} \log q
阅读全文
摘要:跳元模型的似然函数选择为: \[\prod_{t=1}^T \prod_{-m \leq j \leq m, \, j \neq 0} P(w^{(t+j)} \mid w^{(t)}) \]而非其他形式,主要基于以下核心原因: 1. 模型目标的直接对应 跳元模型的核心目标是最大化给定中心词生成其上
阅读全文
摘要:' '.join(list(token))是将token中的每个元素用空格给连接起来。比如' '.join(['f', 'a', 's', 't', '_']) → 'f a s t _' split()函数的默认行为是按照任意空白字符(包括空格、制表符、换行符等)进行分割,并且会自动处理连续的空格
阅读全文
摘要:
阅读全文
摘要:首先来看看二元交叉熵的损失公式 然后再来看看nn.functional.binary_cross_entropy_with_logits的用法 然后来讲一下\(0.9352\)是怎么得出的(\(1.8462\)同理) 每个样本没有归一化的输出为[1.1, -2.2, 3.3, -4.4],标签分别为
阅读全文
摘要:一些本人的理解如下: 事件\(D|w_c,w_o\)的意思是以\(w_c\)作为中心词,\(w_o\)是否来自其上下文,若\(D=1\)则表示来自,否则表示不来自 式\((14.17)\)也比较好理解,两个词向量的内积可以衡量两个的相似程度(长度以及夹角) 文中“正样本的事件”指的是\(D=1\);
阅读全文
摘要:书上对残差网络的理解讲的有一点不清楚,解释一下。实际上,残差网络真正想干的事是通过在原网络上加入层/块(这就让原网络变得更深),而不改变原来的网络能够学习到的函数,以图\(7-8\)为例(这个图\(7-8\)画的是VGG的架构,与其下面的代码是相符合的,当然还有其他各种各样的残差块) 这两张图片中的
阅读全文
摘要:当网络很深的时候会出现下面的问题 梯度消失是一般情况,所以上面讨论的是梯度消失的情况(每一层的梯度都很小,很多个很小的数相乘就会导致底部的层梯度比上面的层的梯度小);梯度爆炸是另外一回事 之所以会导致上面这种情况是因为不同层之间数据分布是有差别的。所以一个简单的想法就是我给数据的分布固定住 之所以不
阅读全文
摘要:白色的\(1\times 1\)卷积层是用来降低通道数的,蓝色的卷积层是用来学习特征的 大致解释一下这些数字是怎么分配的。现在我们的通道数是\(192\),于是我们假设最后输出的通道数是\(256\);考虑这些通道如何分配:我们知道\(3\times 3\)的卷积层性质很好(参数不算太多,学习能力也
阅读全文
摘要:本质和主要改进见下 因为模型更大了,所以要用丢弃法做正则;\(\text{ReLu}\)则比\(\text{Sigmoid}\)更能支撑更深的网络(解决了梯度消失);最大汇聚层则让输出更大,梯度更大,训练更容易 还有一些主要区别如下 步长也很大的原因也是当时的算力其实不是很够 池化层更大了就允许像素
阅读全文
摘要:这里为什么要用bmm:看NWKernelRegression定义的过程,我们是将查询数定义为了批量,attention_weights在第1维度展开就可以提取每一个查询,将所有加了权的键变成行向量;values在最后一个维度展开,就将所有值变成了一个列向量;此时两者相乘就是预测值
阅读全文
摘要:我觉得这个问题的核心在于理解为什么在实际应用中,尽管 RNN 可以动态处理不同长度的序列,我们还是需要截断和填充。RNN 本身确实可以通过循环结构处理任意长度的序列,但实际应用中,我们通常需要批量处理数据,而批量数据的形状需要固定。如果每个序列的长度不同,GPU 无法高效地进行并行计算,因为每次循环
阅读全文
摘要:在TransformerEncoder中,要将嵌入表示先乘以嵌入维度的平方根的原因我觉得是让位置编码和特征维度的数值大小匹配,因为嵌入矩阵通常通过均匀分布初始化,例如在 PyTorch 的 nn.Embedding 中,默认使用均匀分布\([-\sqrt{\frac{3}{d}},\sqrt{\fr
阅读全文
摘要:这个nn.LayerNorm有点搞笑我觉得,有个参数normalized_shape,输入想要归一化张量的最后几个维度,然后就将最后几个维度的元素看做一个整体进行归一化,如下 import torch import torch.nn as nn # 定义输入张量 (batch_size, seque
阅读全文
 浙公网安备 33010602011771号
浙公网安备 33010602011771号