

15.7.3 微调BERT
在我们已经训练好BERT后,BERT就可以对输入的每一个词元返回抽取了上下文信息的特征向量(也就是对于任意一个词元,将这个词元当做查询,所有词元当做键值对)
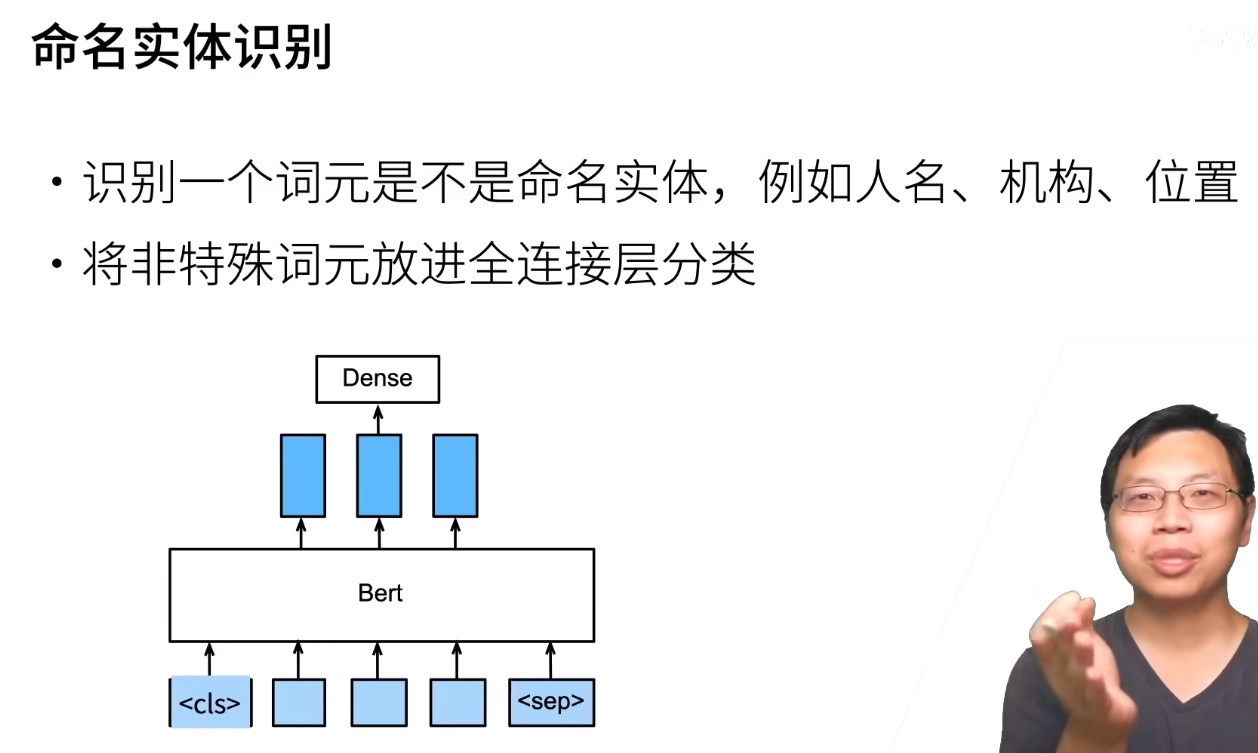
一些任务如下
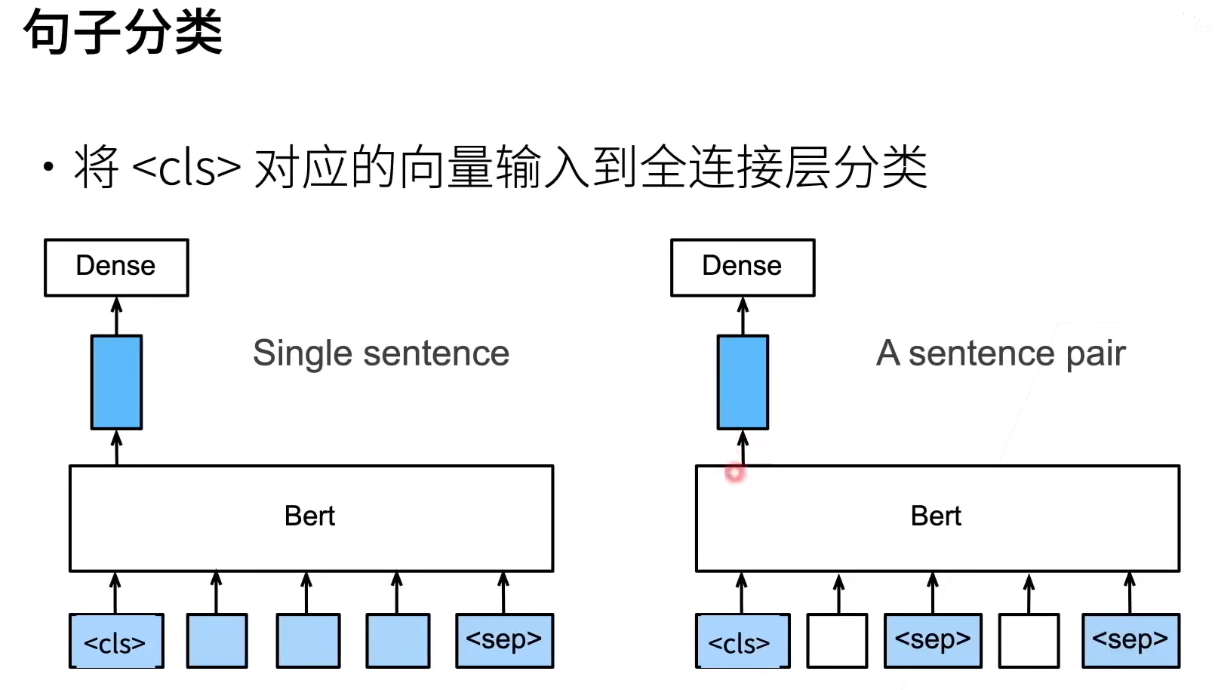
这里将<cls>的特征向量传递给全连接层的原因就是因为<cls>本来就是用来分类的,所以肯定传这个。当然也可以传其他的,反正我们的全连接层都是用来微调的
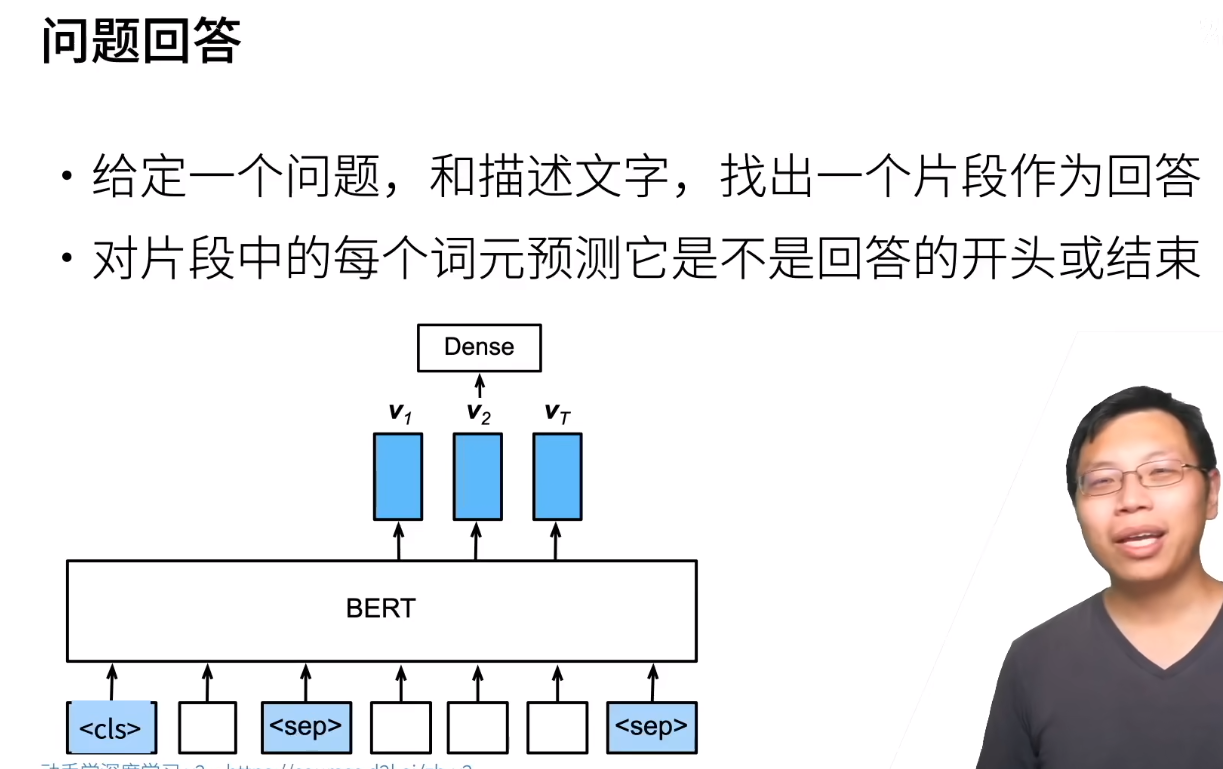
注意这个任务中的描述和问题都是我们给的,相当于让模型做阅读理解。模型的目的是将我们给的描述进行三分类:回答的开头,回答的结尾以及其他的

这里输入的表示和使用BERT的特征就是上面说的拿什么词放到BERT里面,以及全连接层最后输出的是什么
书上的说法感觉有点错,陈旧梯度指的不是MaskLM和NextSentencePred的梯度,这两个部分的梯度根本没有被包含进BERTClassifer;陈旧梯度实际上指的就是所有梯度
在微调场景中,“陈旧梯度”指的是所有参与参数更新的部分的梯度,包括 net.encoder 和 net.hidden 的梯度,而不仅仅是 net.output 的梯度。设置 ignore_stale_grad=True 的原因和参数默认值如下:
1. 陈旧梯度的定义与来源
-
陈旧梯度:指在分布式训练或多GPU场景中,某些参数的梯度基于旧参数值计算的情况。例如:
- 当某个GPU正在计算梯度时,其他GPU可能已更新了参数(如
net.encoder和net.hidden),导致当前梯度与最新参数状态不一致。 - 在微调中,
net.encoder和net.hidden的参数会逐步调整,而net.output的参数需要从头学习,二者的梯度更新频率或策略可能不同。
- 当某个GPU正在计算梯度时,其他GPU可能已更新了参数(如
-
与预训练任务无关:
MaskLM和NextSentencePred是预训练任务的模块,在微调阶段已被移除。陈旧梯度问题仅存在于当前训练任务涉及的参数(即net.encoder、net.hidden和net.output),与预训练任务无关。
2. 为何需要设置 ignore_stale_grad=True?
-
梯度同步问题:
在多GPU或分布式训练中,不同设备上的参数可能异步更新。例如:net.encoder和net.hidden的参数可能在一个GPU上已更新,而另一个GPU仍在基于旧参数计算梯度。net.output的参数更新可能与其他层不同步。
-
参数更新策略差异:
net.encoder和net.hidden通常使用较小的学习率(微调),而net.output可能使用较大的学习率(从头学习),导致梯度计算时机不一致。ignore_stale_grad=True允许优化器接受这种不一致的梯度状态,避免因梯度过时报错。
3. ignore_stale_grad 的默认值
在 MXNet 框架中,trainer.step() 的 ignore_stale_grad 参数默认值为 False。
但在用户提供的代码中,该参数被显式设置为 True(硬编码在 train_batch_ch13 函数内):
trainer.step(labels.shape[0], ignore_stale_grad=True) # 强制忽略陈旧梯度
这是框架使用者针对特定场景(如BERT微调)的主动配置,并非 MXNet 的默认行为。
总结
- 陈旧梯度来源:
所有参与微调的参数(net.encoder、net.hidden和net.output)都可能产生陈旧梯度,尤其是在多设备训练中。 - 参数设置目的:
避免因梯度状态不一致导致训练中断,提升微调过程的稳定性。 - 默认值:
MXNet 中ignore_stale_grad默认关闭(False),但代码中主动启用(True)以适配复杂训练场景。
另外还要注意,书上给的训练代码没有显式设置,看电子书,是有显示设置的
再提一嘴,其实微调是说encoder和hidden的学习率低,output的学习率高,但是代码中没有体现,可能是为了方便演示

 浙公网安备 33010602011771号
浙公网安备 33010602011771号