摘要:
看一遍就懂-大模型架构及encoder-decoder详细训练和推理计算过程 一、特殊Token的意思 不同模型架构的特殊token体系 BERT(Encoder-only,用于理解任务): <CLS>:放在句首,用于分类任务,其输出向量代表整句语义 <SEP>:分隔符,用于句对任务(如问答、文本蕴 阅读全文
posted @ 2026-01-25 18:21
石头开会
阅读(836)
评论(0)
推荐(0)
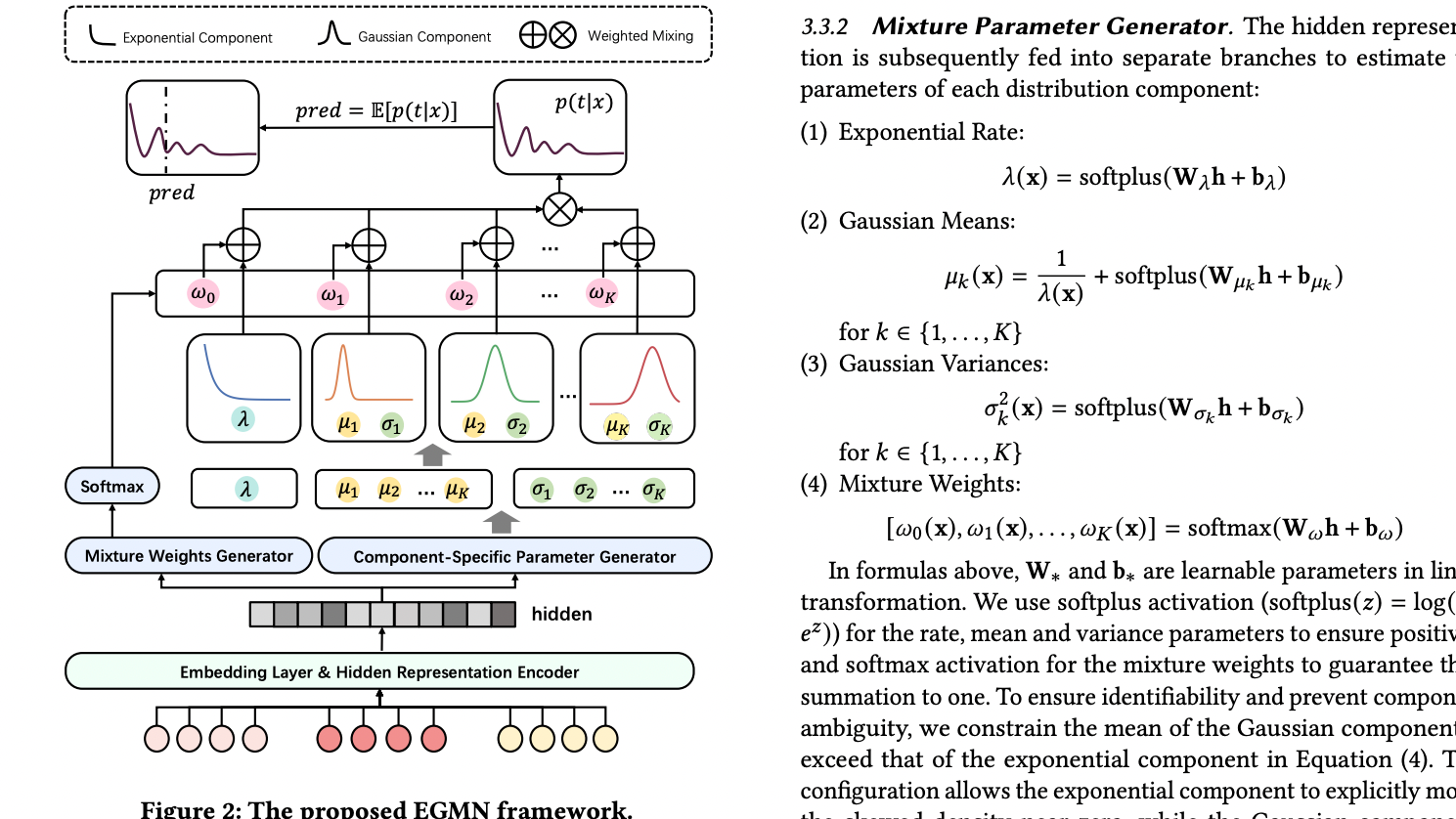 从点预测到分布建模:小红书-EGMN在视频观看时长预测中的方法与实践 原文:https://arxiv.org/pdf/2508.12665 一、引言:问题背景与研究动机 在短视频推荐系统中,观看时长(Watch Time)被广泛视为衡量用户满意度与内容质量的核心信号之一。与点击、点赞等离散反馈不同 阅读全文
从点预测到分布建模:小红书-EGMN在视频观看时长预测中的方法与实践 原文:https://arxiv.org/pdf/2508.12665 一、引言:问题背景与研究动机 在短视频推荐系统中,观看时长(Watch Time)被广泛视为衡量用户满意度与内容质量的核心信号之一。与点击、点赞等离散反馈不同 阅读全文
 注意力机制:从核心原理到前沿应用 如果你关注人工智能,无论是惊艳世人的GPT-4,还是精准洞察你购物偏好的推荐引擎,它们的背后都有一个共同的技术基石——注意力机制 (Attention Mechanism)。 然而,随着技术飞速发展,Attention的“家族”也日益庞大:Self-Attentio 阅读全文
注意力机制:从核心原理到前沿应用 如果你关注人工智能,无论是惊艳世人的GPT-4,还是精准洞察你购物偏好的推荐引擎,它们的背后都有一个共同的技术基石——注意力机制 (Attention Mechanism)。 然而,随着技术飞速发展,Attention的“家族”也日益庞大:Self-Attentio 阅读全文
 AUC 与 GAUC:从全局排序到用户内排序的理解 一、为什么需要 AUC 评估一个推荐模型,最直觉的想法是看准确率——预测对了多少条。但准确率有一个致命缺陷:它高度依赖正负样本的比例。在推荐场景中,用户点击的内容往往只占曝光内容的百分之几,样本极度不平衡,一个把所有样本都预测为"不点击"的模型,准 阅读全文
AUC 与 GAUC:从全局排序到用户内排序的理解 一、为什么需要 AUC 评估一个推荐模型,最直觉的想法是看准确率——预测对了多少条。但准确率有一个致命缺陷:它高度依赖正负样本的比例。在推荐场景中,用户点击的内容往往只占曝光内容的百分之几,样本极度不平衡,一个把所有样本都预测为"不点击"的模型,准 阅读全文
 推荐系统中 Q 值的设计:从训练目标到推理信号 一、为什么要聊这个话题 做推荐系统的人,每天都在和 Q 值打交道。粗排要输出 Q 值,精排要融合多个 Q 值,线上打分公式里全是 Q 值。但如果你问"这个 Q 值到底代表什么,为什么可以用它来排序",很多人的回答是"模型输出的分数呗"——这个回答没有错 阅读全文
推荐系统中 Q 值的设计:从训练目标到推理信号 一、为什么要聊这个话题 做推荐系统的人,每天都在和 Q 值打交道。粗排要输出 Q 值,精排要融合多个 Q 值,线上打分公式里全是 Q 值。但如果你问"这个 Q 值到底代表什么,为什么可以用它来排序",很多人的回答是"模型输出的分数呗"——这个回答没有错 阅读全文
 浙公网安备 33010602011771号
浙公网安备 33010602011771号