

注意力机制:从核心原理到前沿应用
注意力机制:从核心原理到前沿应用
如果你关注人工智能,无论是惊艳世人的GPT-4,还是精准洞察你购物偏好的推荐引擎,它们的背后都有一个共同的技术基石——注意力机制 (Attention Mechanism)。
然而,随着技术飞速发展,Attention的“家族”也日益庞大:Self-Attention, Cross-Attention, Multi-Head, Additive Attention... 这些术语常常被混在一起,让许多初学者甚至从业者都感到困惑,难以形成一个清晰的体系。
这篇技术博客的目的,就是化繁为简。我们将抛弃扁平化的罗列,采用一个正交的三维框架来彻底解构Attention,让你一次性看透其本质。这个框架包含三个维度:
- 核心计算范式:Attention最底层的数学实现。
- 信息交互模式:决定了Attention处理的是何种信息流。
- 结构与功能变体:增强Attention性能的关键“插件”。
读完本文,你将能清晰地识别和组合这些核心组件,并理解它们在大模型和推荐算法中的关键作用。
第一章:Attention的基石——两大核心计算范式
一切复杂的机制都源于简单的起点。Attention的核心是为输入序列中的每个元素分配一个权重,这个权重的计算方式,就是它的计算范式。
1.1 加性注意力 (Additive Attention): 历史的起点
这是最早被提出的注意力形式,由Bahdanau等人在2014年用于改进神经机器翻译。它的核心思想是:使用一个小型的前馈神经网络来学习Query和Key之间的相似度分数。
-
核心逻辑:
\[score(\mathbf{q}, \mathbf{k}) = \mathbf{v}^T \tanh(\mathbf{W}_q\mathbf{q} + \mathbf{W}_k\mathbf{k}) \]其中,\(\mathbf{W}_q\), \(\mathbf{W}_k\), 和 \(\mathbf{v}\) 都是可学习的参数矩阵。
-
特点与场景:
- 优点: 理论上,由于引入了非线性激活函数
tanh,它的表达能力更强,并且可以处理Query和Key维度不匹配的情况。 - 缺点: 计算涉及多个矩阵乘法和激活函数,相比点积注意力,计算成本更高,难以高效并行。
- 定位: 作为Attention机制的开山之作,它成功解决了早期Seq2Seq模型的瓶颈。虽然在当今的大模型中已不常用,但理解它是追溯技术演进的重要一环。
- 优点: 理论上,由于引入了非线性激活函数
1.2 缩放点积注意力 (Scaled Dot-Product Attention): 现代的标准
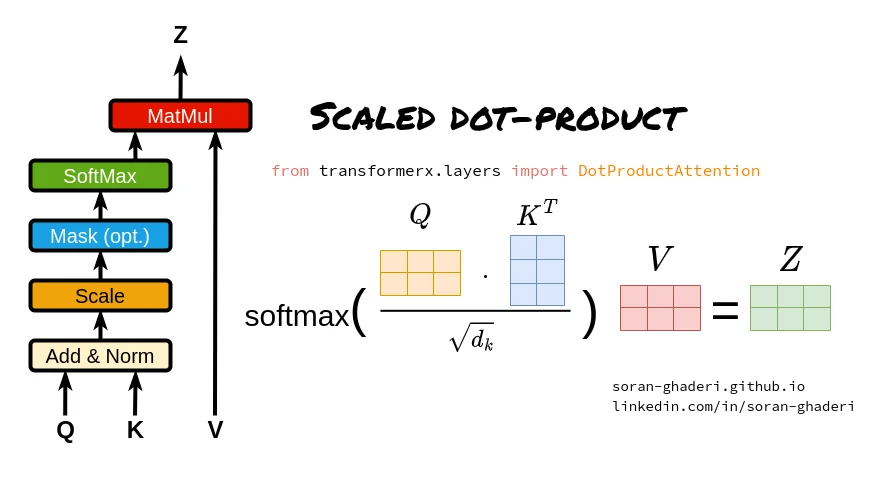
2017年,"Attention Is All You Need" 论文提出了Transformer架构,其核心就是缩放点积注意力。它摒弃了复杂的神经网络,回归到更简洁、更高效的向量运算。
-
核心逻辑: 通过计算Query和Key向量的点积来直接衡量相似度,并除以一个缩放因子来稳定梯度。
\[\text{Attention}(Q, K, V) = \text{softmax}\left(\frac{QK^T}{\sqrt{d_k}}\right)V \] -
特点与场景:
- 优点: 计算效率极高。它本质上是一系列矩阵乘法,完美适配现代GPU的并行计算架构,速度远超加性注意力。
- 关键点: 缩放因子 \(\sqrt{d_k}\) (\(d_k\)是Key向量的维度)至关重要。当维度 \(d_k\) 较大时,点积结果的方差会增大,可能将softmax函数推向梯度极小的区域,导致训练困难。除以\(\sqrt{d_k}\)可以缓解这个问题。
- 定位: 现代AI模型的默认标准。从GPT系列到各类视觉、推荐大模型,几乎都构建在这一高效的计算范式之上。
第二章:信息的流动——两大信息交互模式
确定了如何计算权重后,下一个核心问题是:Query, Key, Value从哪里来? 这决定了Attention是在处理序列内部关系,还是在连接不同的信息源。
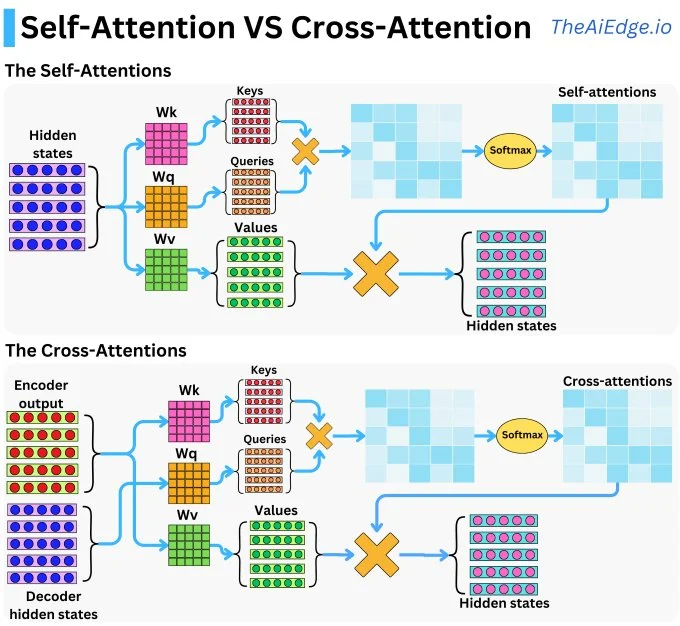
2.1 自注意力 (Self-Attention): 序列内部的深度对话
顾名思义,自注意力的信息来源是序列自身。
-
核心逻辑: Query, Key, Value三个向量均来自同一个输入序列。序列中的每一个Token都会生成自己的Q、K、V,然后用自己的Q去和序列中所有Token的K计算相似度,从而得到一个加权的V作为自己的新表示。这好比序列中的每个词都在审视全局上下文,进行一场“内部深度对话”来更新自己。
-
特点与场景:
- 特点:
- 并行计算: 对序列中所有位置的计算可以完全并行,突破了RNN的序列依赖瓶颈。
- 捕捉长距离依赖: 任意两个位置之间都可以直接交互,路径长度为O(1),非常擅长捕捉长距离的语法或语义依赖。
- 应用:
- 大语言模型: GPT、BERT等模型的基础,用于理解句子或文档的内部结构和上下文。
- 序列推荐: 在SASRec等模型中,用于捕捉用户历史行为序列中的动态兴趣演化。
- 特点:
2.2 交叉注意力 (Cross-Attention): 连接不同信息源的桥梁
当信息需要跨越不同来源时,交叉注意力就登场了。
-
核心逻辑: Query来自一个序列,而Key和Value来自另一个完全不同的序列。这就像用一把“钥匙”(Query),去另一个信息“仓库”(Key-Value源)中精准地提取所需信息。
-
特点与场景:
- 特点: 实现信息的非对称融合与对齐,将一个序列的信息“注入”或“对齐”到另一个序列上。
- 应用:
- Encoder-Decoder架构: 在机器翻译、文本摘要中,Decoder(生成译文)在每一步都会用自己的状态作为Query,去查询Encoder(编码原文)的全部输出,以决定当前翻译哪个词。
- 多模态模型: 在文生图模型中,文本的Embedding作为Query,去查询图像特征,实现文本对图像生成的指导。
- 推荐系统: 它的一个精妙应用将在下一章详述。
2.3 各种场景下的注意力利用
| 场景 | 使用的注意力 | Q 的来源 | K, V 的来源 | 目的与作用 |
|---|---|---|---|---|
| 机器翻译 (Encoder) | 自注意力 | 源语言句子 | 源语言句子 | 理解源语言句子的内部结构和上下文。 |
| 机器翻译 (Decoder) | 掩码自注意力 | 已生成的目标语言序列 | 已生成的目标语言序列 | 确保生成句子的流畅性和语法正确性。 |
| 机器翻译 (Decoder) | 交叉注意力 | 目标语言序列(来自自注意力层) | 源语言句子(来自编码器) | 将源语言的信息对齐并融入到目标语言的生成中。 |
| 图像描述生成 | 交叉注意力 | 正在生成的文本序列 | 图像的特征网格 | 在生成每个单词时,关注图像中最相关的区域。 |
| 视觉问答 (VQA) | 交叉注意力 | 问题的文本表示 | 图像的特征网格 | 根据问题,在图像中寻找答案的线索。 |
| 文本摘要 (Seq2Seq) | 交叉注意力 | 正在生成的摘要 | 原始长文本 | 从原文中提取关键信息来构建摘要。 |
| 多模态情感分析 | 交叉注意力 | 文本特征 | 视频/音频特征 | 让文本表示能够感知视频或音频中的情感线索。 |
2.4 总结
- 自注意力是“向内看”:专注于理解一个序列内部成员之间的关系,是构建高质量上下文表示的基础。
- 交叉注意力是“向外看”:专注于连接两个不同的序列,实现信息查询、对齐和融合,是多模态或条件生成任务的桥梁。
第三章:性能倍增器——三大关键结构与功能变体
有了底层的计算范式和宏观的交互模式,我们还需要一些关键的“插件”来让Attention的威力倍增,并适应更复杂的任务需求。
3.1 多头注意力 (Multi-Head Attention): 从不同子空间并行洞察
如果只用一组Q, K, V进行注意力计算,模型可能会陷入单一的关注模式。多头机制解决了这个问题。
-
核心逻辑: 与其进行一次高维度的注意力计算,不如将Query, Key, Value通过不同的线性变换投影到多个低维的“子空间”(即“头”),在每个头中并行地计算注意力,最后将所有头的结果拼接起来。这好比让多个专家从不同角度独立分析问题,再汇总意见得出最终结论。
-
特点与场景:
- 特点: 极大地增强了模型的表达能力,允许模型在不同表示子空间中同时关注不同方面的信息(例如,一个头可能关注语法结构,另一个头关注语义关联)。
- 定位: 现代Transformer架构的标配,它不是一种新的Attention类型,而是一种必不可少的增强结构。
3.2 掩码注意力 (Masked Attention): 实现精准的信息控制
在很多任务中,我们不希望模型“看到”所有信息。掩码机制通过给Attention Score矩阵加上一个掩码,强制模型忽略特定位置。
-
子类型一:因果掩码 (Causal Masking)
- 核心逻辑: 在计算一个位置的注意力时,遮蔽掉所有“未来”的位置。通常是在Attention Score矩阵的上三角部分加上一个极大的负数(如
-inf),这样在softmax后,未来位置的权重就变成了0。 - 应用: 所有自回归生成模型(如GPT)的根本。它确保了在生成第
t个词时,模型只依赖于1到t-1的已知信息,避免了信息泄露。
- 核心逻辑: 在计算一个位置的注意力时,遮蔽掉所有“未来”的位置。通常是在Attention Score矩阵的上三角部分加上一个极大的负数(如
-
子类型二:填充掩码 (Padding Masking)
- 核心逻辑: 在处理一个batch的变长序列时,我们通常会用特殊字符(Padding Token)将短序列补齐到与最长序列相同的长度。填充掩码的作用就是在计算注意力时,忽略这些无意义的Padding Token。
- 应用: 处理变长序列输入的标准操作,几乎所有需要处理文本的深度学习模型都会用到。
3.3 目标感知注意力 (Target-Aware Attention): 推荐系统的“读心术”
这是交叉注意力在推荐领域登峰造极的应用,完美诠释了如何让技术与业务场景深度结合。
-
核心逻辑: 传统的用户兴趣模型会为用户生成一个固定的兴趣向量。而目标感知注意力的巧妙之处在于,它用“候选商品”(Target)作为Query,去“查询”用户的历史行为序列(作为Key和Value)。
-
特点与场景:
- 特点: 用户的兴趣表示不再是静态的,而是根据当前要预测的候选商品动态生成的。如果候选商品是键盘,模型会重点关注用户历史上的3C行为;如果候选商品是口红,模型则会聚焦于美妆行为。
- 应用: 这是提升推荐精准度的关键技术,其代表作就是阿里的DIN (Deep Interest Network),在工业界CTR预估等任务中取得了巨大成功。
第四章:总结与展望
现在,让我们用这个三维框架来审视一个典型的现代AI模块——GPT的Decoder模块。它究竟是什么?
- 它是一个多头 (Multi-Head) 的、应用了因果掩码 (Causal Masking) 的自注意力 (Self-Attention) 模块,其核心计算基于缩放点积 (Scaled Dot-Product)。
看,通过这个框架,一个复杂的概念被清晰地分解为了几个核心组件的组合。
未来趋势:
- 效率优化:
O(n^2)的计算复杂度仍然是Attention处理超长序列的瓶颈。Sparse Attention, Linear Attention等旨在降低复杂度的研究方向方兴未艾。 - 架构融合: Attention与卷积(CNN)、图网络(GNN)等其他结构的融合正在催生更多强大的新模型。
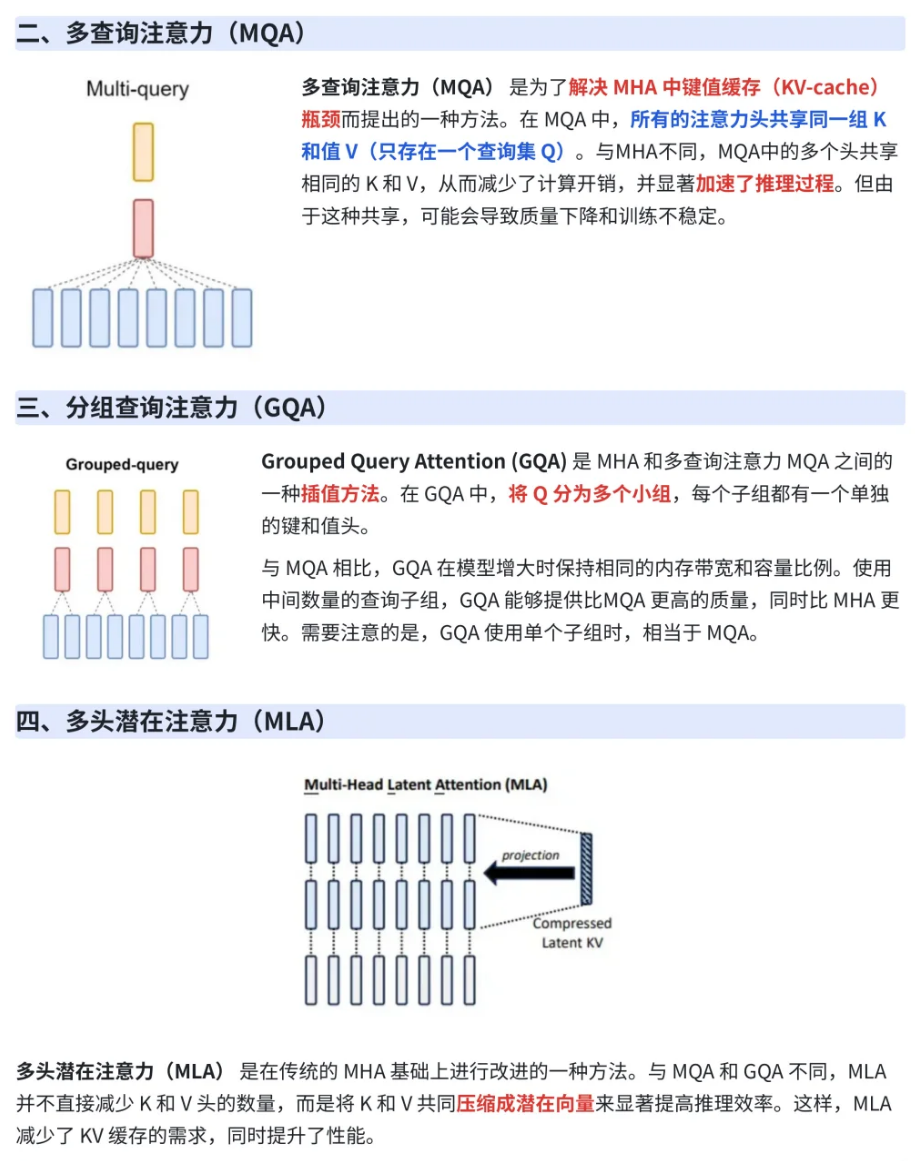
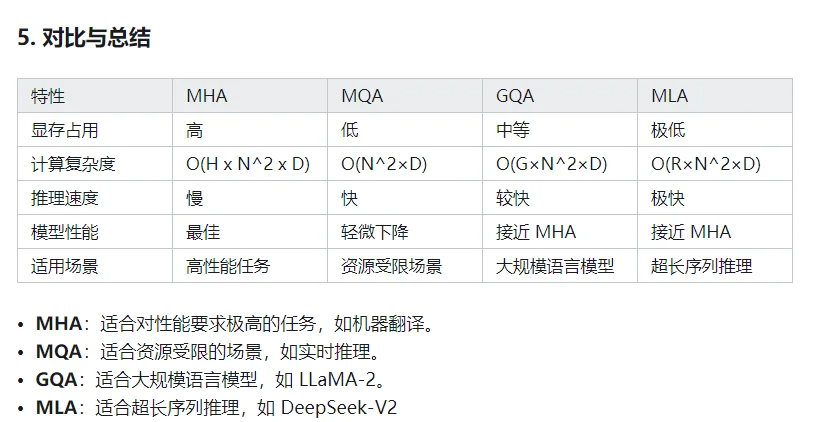
- 相关变种:多查询注意力MQA、多分组查询注意力GQA、多头潜在注意力MLA
![image]()
![image]()
总而言之,Attention机制的简洁、强大和灵活性,使其当之无愧地成为了现代AI的基石。掌握我们今天讨论的三维框架,你就能在面对未来层出不穷的新模型时,拨开云雾,直击其核心。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号