
【原创】xenomai UDD介绍与UDD用户态驱动示例
 本文介绍linux实时操作系统xenomai UDD原理和相关代码,并给出一个基于UDD的用户态操作GPIO的示例,以及xenomai RTNet协议栈收发网络包与UDD用户态驱动操作网卡收发包的CPU耗时对比。
本文介绍linux实时操作系统xenomai UDD原理和相关代码,并给出一个基于UDD的用户态操作GPIO的示例,以及xenomai RTNet协议栈收发网络包与UDD用户态驱动操作网卡收发包的CPU耗时对比。
xenomai UDD与用户态驱动示例
本文介绍xenomai UDD原理和相关代码,并给出一个基于UDD的用户态操作GPIO的示例,以及内核收发网络包与用户态操作网卡收发包的CPU耗时对比。
一、UDD介绍
大家可能在看xenomai源码的时候注意到,driver目录下有个不起眼的目录udd,里面仅一个.c文件,无任何示例,可能也不不知道它是干什么的,下面开始介绍它。
UDD全称User-space Device Driver framework ,即用户态设备驱动框架,即为用户态设备驱动提供的一种机制,用户态驱动是什么,有什么用呢?
我们都知道,在Linux开发中,要操作一个硬件设备,比如一个GPIO、serial等,通常需要在内核开发对应的driver,然后再通过操作系统提供接口来实现对该硬件的访问,这样的好处是,操作系统屏蔽了底层实现,统一了与硬件设备的交互接口,方便我们的程序的可移植性。
但是,在一些嵌入式应用场合(我们的主题是xenomai,先以实时应用这个场景来分析~),我们每次访问操作硬件,比如我要操作一个GPIO口输出高低电平,都需要先切换到内核态,然后内核经过一系列子系统最终调用GPIO驱动实现高低电平输出,从整个流程来看有哪些问题:
- 用户态内核态切换,CPU执行操作系统代码需要占用CPU资源,路径显得过于繁琐
- 路径长意味着不确定性增加,进而影响信号输出的实时性
- 内核态用户态之间数据需要拷贝
- 用户态内核态频繁切换cache、TLB抖动
这时候我们会想,“要是能不通过操作系统内核,应用可以直接操作硬件进行输出多好!” 为了能够实现该想法,xenomai为我们提供了UDD,只需要我们在内核态通过UDD实现很少一部分,然后在用户态实现GPIO相关驱动,达到用户态应用程序直接操作硬件的目的。
UDD是xenomai特有的吗?不是,在Linux中,这是2006年就存在的东西,叫UIO(Userspace I/O)即,运行在用户空间的I/O技术,且应用广泛。
举个UIO应用例子,互联网行业中,经典的 C10K 和 C1000K 问题不断解决(C10K 就是单机同时处理 1 万个请求(并发连接 1 万)的问题,而 C1000K 也就是单机支持处理 100 万个请求(并发连接 100 万)的问题)。人们对于性能的要求是无止境的,网速一直在提升,网卡从1G到100G的发展,对应单机的网络IO能力必须跟上时代的发展。
所以有没有可能在单机中,同时处理 1000 万的请求呢?即 C10M 问题。在 C10M 问题中,各种软件、硬件的优化很可能都已经做到头了。假设,我们要跑满10GE网卡,每个包64字节,这就需要2000万PPS(注:以太网万兆网卡速度上限是1488万PPS,因为最小帧大小为84B《Bandwidth, Packets Per Second, and Other Network Performance Metrics》),100G是2亿PPS,即每个包的处理耗时不能超过50纳秒。而一次Cache Miss,不管是TLB、数据Cache、指令Cache发生Miss,回内存读取大约65纳秒,NUMA体系下跨Node通讯大约40纳秒,所以,即使不加上业务逻辑,即使纯收发包都如此艰难。我们要控制Cache的命中率,我们要了解计算机体系结构,不能发生跨Node通讯。所以当升级完硬件(比如足够多的内存、带宽足够大的网卡、更多的网络功能卸载等)后,你可能会发现,无论你怎么优化应用程序和内核中的各种网络参数,想实现 1000 万请求的并发,都是极其困难的。
- 传统的收发报文方式都必须采用硬中断来做通讯,每次硬中断大约消耗100微秒,这还不算因为终止上下文所带来的Cache Miss。
- 数据必须从内核态用户态之间切换拷贝带来大量CPU消耗,全局锁竞争。
- 收发包都有系统调用的开销。
- 内核工作在多核上,为可全局一致,即使采用Lock Free,也避免不了锁总线、内存屏障带来的性能损耗。
- 从网卡到业务进程,经过的路径太长,有些其实未必要的,例如netfilter框架,这些都带来一定的消耗,而且容易Cache Miss。
究其根本,是 Linux 内核协议栈做了太多太繁重的工作。从网卡中断带来的硬中断处理程序开始,到软中断中的各层网络协议处理,最后再到应用程序,这个路径实在是太长了,就导致网络包的处理优化到了一定程度后,就无法更进一步了。
内核是导致瓶颈的原因,要解决这个问题,最重要就是绕过内核协议栈的冗长路径,绕过内核直接在用户态收发包来解决内核的瓶颈。这里有多种旁路机制PACKET_MMAP、Snabbswitch、Netmap、PF_RING™ZC、DPDK、XDP等(注:只有Snabbswitch、DPDK 和 netmap 会接管整个网卡,不允许网卡的任何流量经过内核),目前最常用的两种机制是DPDK 和 XDP,其中的DPDK应用就是UIO技术,它跳过内核协议栈,利用UIO将硬件操作映射到用户空间,在用户态实现网卡驱动直接操作硬件,用户态进程通过轮询的方式,来处理网络接收。这样减少了频繁的内核态用户态上下文切换和数据拷贝,可以极大提高数据处理性能和吞吐量。
注:DPDK不仅可以通过轮询的方式来处理网络接收,也可以通过中断的方式来接收。
对于我们实时应用场合,虽然出发点不同(我们关注实时性,即确定性),但优化方式是一致的,我们希望,在响应某个实时事件后能跳过内核,直接操作硬件进行结果的输出,降低输出路径上的不确定性,同时节省内核路径所需的CPU资源。既然UIO可以实现,所以2014年发布的xenomai3中引入了适合xenomai RTDM的UIO机制,称为UDD。大家可以看到,xenomai官方源码里并没有任何UDD示例驱动,大家可能不知道怎么用,这也是为什么写本文的原因。
我们介绍完UDD和UIO(UDD和UIO原理一致,使用上基本一致,后文没有特殊说明均指UDD),接下来会分析UDD原理和相关代码,最后给出一个基于UDD的用户态操作GPIO的示例,以及对比用户态操作网卡收发包的CPU耗时。
二、UDD原理及框架
1. 内存映射
首先我们要思考如何实现在用户态实现直接操作硬件?
以GPIO为例,回想MCU裸机点灯的时候,我们操作GPIO输出高低电平是通过写指定寄存器来完成的,这些寄存器位于MCU物理寻址范围的固定地址处。回到我们Linux应用,由于操作系统和MMU的存在,每个进程读写的是虚拟地址,如果需要访问指定的物理内存地址,就需要操作系统为该进程添加物理内存到进程虚拟内存之间的映射表,同时设置该片内存的访问权限和一些标识。
所以要在用户态实现硬件的直接操作,UDD需要提供一个机制将硬件所在物理地址映射到进程地址空间,实现用户态对这些物理地址的读写操作。
对嵌入式linux开发稍有经验的朋友可能都知道,将物理内存到进程虚拟内存的映射可以通过对设备节点/dev/mem使用O_SYNC标识打开,进行mmap()函数操作就能做到,那还要UDD干嘛?是的如果我们只是访问物理内存,比如通过GPMC进行外部ram数据读写,并没有用到UDD或UIO就可完成。其实是因为这些外设没有涉及设备中断,UDD存在的主要目的是提供中断通知处理机制,接下来我们看看中断。
2. 中断处理
基本所有的外设(网卡、SPI、MMC...)都需要中断来通知CPU处理。通常,OS运行在CPU的高特权级,中断产生后的处理也是在高特权级,linux应用程序运行在CPU低特权级的用户态,所以用户态的驱动无法直接处理产生的中断,这就需要内核态辅助实现中断的控制处理,这是UDD的一个重要机制。
前几个月,记得在哪里看到过有开发者往upstream推用户态中断处理机制的代码,最近找不到了。
UDD与UIO的区别
中断响应时间是RTOS实时性的重要指标 ,对于一个实时外设设备,如果我们在用户态空间来驱动它,那它产生中断如何快速响应(响应时间确定)?如果使用linux UIO,前面文章说过,linux的中断响应时间不是确定的,那就无实时性可言了,不能使用linux UIO。
这就是xenomai UDD存在的原因,UDD保证了实时设备中断响应的实时性,UDD与UIO主要区别在于中断的处理和通知机制,UDD基于RTDM和xenomai调度,全路径为实时上下文。
需要说明的是:如果你的实时设备仅作为输出,比如驱动GPIO输出一个电平,并无中断需求,那么使用UDD还是UIO或/dev/mem无任何区别。
另外,有朋友问我,一些驱动不开源的PCI控制卡/采集卡/数字输出卡,xenomai能不能用?通常我们使用一个外设作为实时设备时,需要专门的为这个设备编写xenomai实时驱动程序。但是,一般这些驱动不开源的PCI控制卡,它的驱动大部分在用户态实现,以库的方式提供,内核部分仅做一些io映射(这部分开源,与UIO原理一致), 这类板卡如果对中断处理依赖不高,或者你的应用用不到它中断相关的部分,那么是可以在xenomai上创建实时任务直接调用它的库来使用的。
3. linux UIO与xenomai UDD框架对比
3.1 UIO机制
linux UIO框架如下:
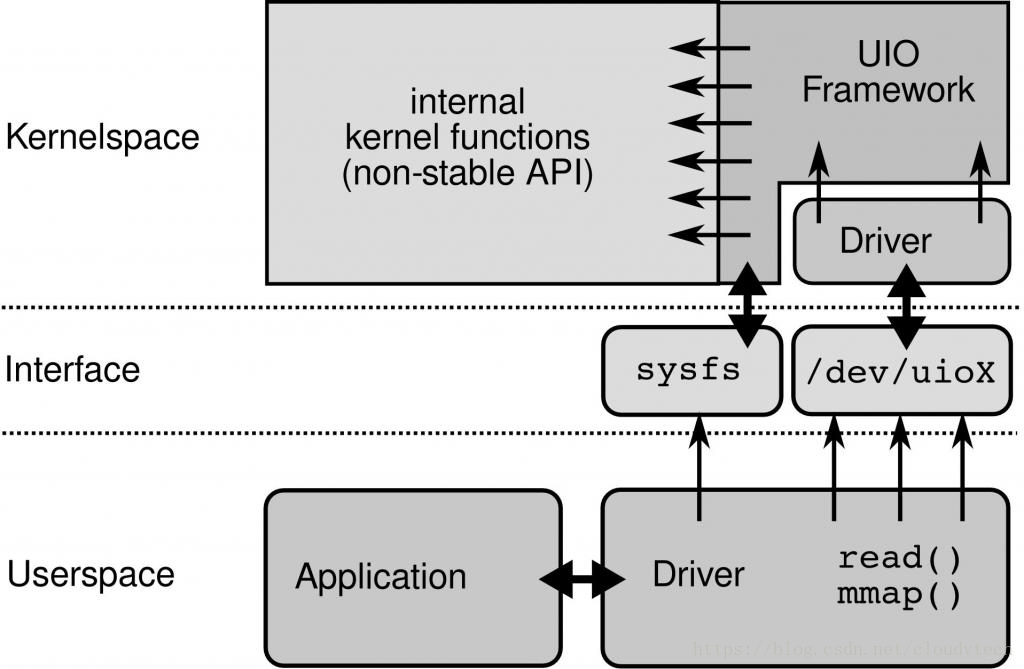
内核态UIO Framework为UIO 设备Driver提供机制和稳定接口,
- 用户态驱动通过
mmap函数实现对/dev/uioX驱动中mmap方法完成物理地址到进程地址空间的映射。 - 异步IO
poll/epoll()或select()完成内核态中断到用户的通知,结合read()等待和处理。
更多UIO介绍及使用说明详见内核官方文档https://www.kernel.org/doc/html/latest/driver-api/uio-howto.html.
3.2 UDD机制
linux UIO框架如下:
内核态UIO Framework为UIO 设备Driver提供机制和稳定接口,
- 用户态驱动通过
mmap函数实现对/dev/rtdm/mmapX驱动中mmap方法完成物理地址到进程地址空间的映射。 - xenomai支持
select()的方式来等待中断和处理,结合read()进行中断应答;或为中断注册信号使用sigtimedwait来响应中断。
三、UDD应用示例
1. UDD GPIO操作
以ti am335x为例实现用户态GPIO操作。内核模块代码如下:
#include <linux/module.h>
#include <linux/types.h>
#include <linux/interrupt.h>
#include <linux/gpio.h>
#include <rtdm/driver.h>
#include <rtdm/udd.h>
#include <linux/platform_device.h>
#define OMAP_MAX_GPIO 192
#define AM33XX_GPIO0_BASE 0x44E07000 /*gpio0 物理起始地址*/
#define AM33XX_GPIO1_BASE 0x4804C000 /*gpio1 物理起始地址*/
#define AM33XX_GPIO2_BASE 0x481AC000 /*gpio2 物理起始地址*/
#define AM33XX_GPIO3_BASE 0x481AE000 /*gpio3 物理起始地址*/
#define RTDM_SUBCLASS_OMAP_GPIO 0
#define DEVICE_NAME "udd_gpio"
MODULE_DESCRIPTION("UDD driver for OMAP3 GPIO");
MODULE_LICENSE("GPL");
MODULE_AUTHOR("wsg1100");
static struct udd_device device = {
.device_name = DEVICE_NAME,
.device_flags = RTDM_NAMED_DEVICE|RTDM_EXCLUSIVE,
.device_subclass = RTDM_SUBCLASS_OMAP_GPIO,
.mem_regions[0].name = "gpio0_addr",
.mem_regions[0].addr = AM33XX_GPIO0_BASE,
.mem_regions[0].len = 4096,
.mem_regions[0].type = UDD_MEM_PHYS,
.mem_regions[1].name = "gpio1_addr",
.mem_regions[1].addr = AM33XX_GPIO1_BASE,
.mem_regions[1].len = 4096,
.mem_regions[1].type = UDD_MEM_PHYS,
.mem_regions[2].name = "gpio2_addr",
.mem_regions[2].addr = AM33XX_GPIO2_BASE,
.mem_regions[2].len = 4096,
.mem_regions[2].type = UDD_MEM_PHYS,
.mem_regions[3].name = "gpio3_addr",
.mem_regions[3].addr = AM33XX_GPIO3_BASE,
.mem_regions[3].len = 4096,
.mem_regions[3].type = UDD_MEM_PHYS,
};
static int udd_gpio_probe(struct platform_device *pdev)
{
dev_info(&pdev->dev, "mem region len: %d\n",device.mem_regions[0].len);
dev_info(&pdev->dev, "mem region addr: 0x%08lx\n",device.mem_regions[0].addr);
dev_info(&pdev->dev, "mem region len: %d\n",device.mem_regions[1].len);
dev_info(&pdev->dev, "mem region addr: 0x%08lx\n",device.mem_regions[1].addr);
dev_info(&pdev->dev, "mem region len: %d\n",device.mem_regions[2].len);
dev_info(&pdev->dev, "mem region addr: 0x%08lx\n",device.mem_regions[2].addr);
dev_info(&pdev->dev, "mem region len: %d\n",device.mem_regions[3].len);
dev_info(&pdev->dev, "mem region addr: 0x%08lx\n",device.mem_regions[3].addr);
return udd_register_device (&device);
}
static int udd_gpio_remove(struct platform_device *pdev)
{
udd_unregister_device (&device);
return 0;
}
static const struct of_device_id udd_gpio_ids[] = {
{ .compatible = "ti,omap3-udd-gpio" },
{},
};
MODULE_DEVICE_TABLE(of, udd_gpio_ids);
static struct platform_driver udd_gpio_platform_driver = {
.driver = {
.name = DEVICE_NAME,
.of_match_table = udd_gpio_ids,
},
.probe = udd_gpio_probe,
.remove = udd_gpio_remove,
};
int __init omap_gpio_init(void)
{
return platform_driver_register(&udd_gpio_platform_driver);
}
void __exit omap_gpio_exit(void)
{
return platform_driver_unregister(&udd_gpio_platform_driver);
}
module_init(omap_gpio_init);
module_exit(omap_gpio_exit);
用户态代码详见gitee:https://gitee.com/wsg1100/xenomai-udd-example
注意: 由于中断级联,对于每个bank GPIO控制器下的每个GPIO来说,它们产生中断后,不能直接通知GIC,而是先通知GPIO中断控制器,然后gpio控制器再通过SPI通知GIC,然后GIC会通过irq或者firq触发某个CPU中断。每个UDD设备驱动只能注册处理一个中断处理,如果为每个gpio都注册中断,处理将很麻烦,所以这里将全部gpio通过一个UDD设备注册,没有通过UDD注册中断,所以只作为输入输出,没有中断事件的处理。
2. UDD vs. RTnet网络包收发
实时工业以太网应用广发,通常实时工业以太网基于实时操作系统来实现。实时操作系统在操作系统调度层面保证了事件响应的实时性,但事件的响应结果输出,依赖操作系统以太网的实时性,这涉及操作系统以太网硬件驱动具体实现、操作系统网络协议栈等。
以EtherCAT工业以太网(二层网络)为例,高档的数控系统为获得更高的加工精度,需要很短的插补周期(比如500us、125us、62.5us),即系统调度-插补运算-协议栈处理-网络输出-帧传输延时四者所需总时间需要在一个插补周期内完成,这需要系统各部分具有很强的实时性,其中帧传输延时是确定的,与以太网络速率相关;系统调度与操作系统实时性相关;网络输出是重要的一环,不仅要求输出时间确定,且网络输出CPU占用尽可能小,这样能留出更多的CPU时间用于插补控制运算。
最直接的方案是通过操作系统提供的原始套接字(Raw Socket)接口进行链路层以太网帧的收发,但是存在文章开头说的问题(RTNet协议栈相比Linux网络协议栈已经足够简单,执行路径足够确定,仍存在上下文切换等开销,间后文测试)。
这里我们使用UDD来编写用户态网卡驱动,直接驱动硬件进行EtherCAT数据收发,下面是做的简单对比测试。
实时任务定时发帧间隔为250us,总次数为10万次,EtherCAT数据帧长度约1200字节,其内容为重复的0x130报文(第一个报文M位为1),以下为收发CPU耗时统计,其中发送时间包括协议栈组帧-拷贝-发送,接收时间包括接收-协议栈解析,其中,接收时协议栈只处理第一个报文,可简单认为处理时间恒定,在此基础上我们来看耗时对比。
UDD 时间分布分布如下:
# 00:00:00 (recv, priority 79)
# ---- min| ---- avg| ---- max|
# 0.603| 0.757| 4.035|
0 1
0.5 95841
1.5 2909
2.5 1234
3.5 19
4.5 2
5 1
# 00:00:00 (send, priority 79)
# ---- min| ---- avg| ---- max|
# 0.096| 0.433| 3.476|
0 1
0.5 97127
1.5 2786
2.5 88
3.5 4
4 1
RTNET PF_PACKET时间分布分布如下:
# 00:00:00 (recv, priority 79)
# ---- min| ---- avg| ---- max|
# 1.356| 1.607| 6.248|
1 1
1.5 96610
2.5 1374
3.5 1743
4.5 258
5.5 19
6.5 2
7 1
# 00:00:00 (send, priority 79)
# ---- min| ---- avg| ---- max|
# 1.053| 1.460| 4.755|
1 1
1.5 97318
2.5 2408
3.5 269
4.5 10
5 1
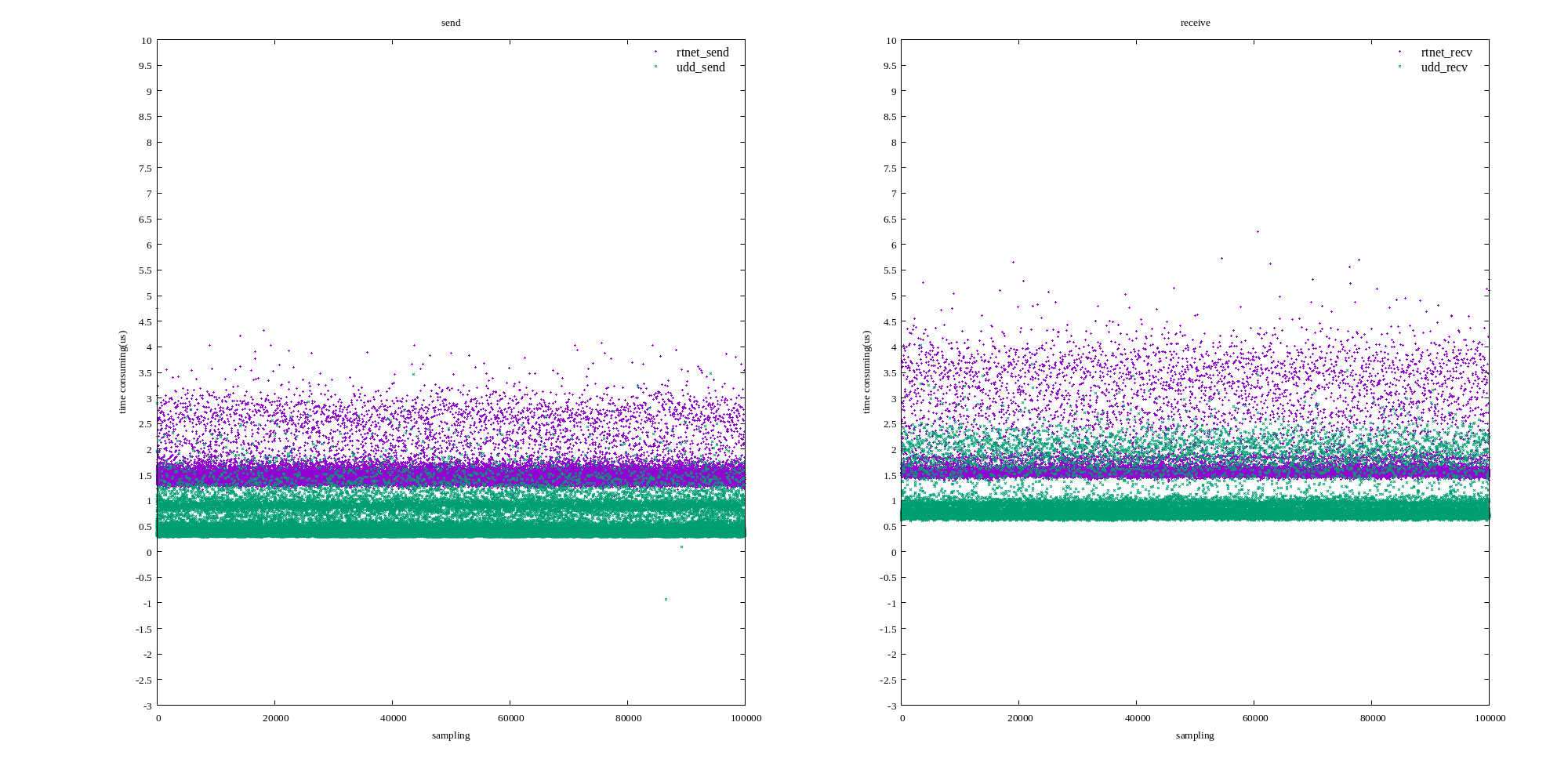
X86 UIO vs. PREEMPT-RT PACKET_MMAP 网络包收发
表1:发送测试对比
| 指标 | 最小(us) | 平均(us) | 最大(us) | 抖动(us) |
|---|---|---|---|---|
| uio_send | 0.603 | 0.757 | 4.035 | 3.432 |
| socket_send | 1.150 | 1.745 | 13.518 | 12.368 |
表2:接收测试对比
| 指标 | 最小(us) | 平均(us) | 最大(us) | 抖动(us) |
|---|---|---|---|---|
| uio_recv | 0.096 | 0.433 | 3.476 | 3.380 |
| socket_recv | 0.315 | 1.849 | 15.635 | 15.320 |
X86 UIO vs. Xenomai RTnet 实时网络包收发
表1:发送测试对比
| 指标 | 最小(us) | 平均(us) | 最大(us) | 抖动(us) |
|---|---|---|---|---|
| uio_send | 0.603 | 0.757 | 4.035 | 3.432 |
| rtnet_send | 1.053 | 1.460 | 4.755 | 3.702 |
表2:接收测试对比
| 指标 | 最小(us) | 平均(us) | 最大(us) | 抖动(us) |
|---|---|---|---|---|
| uio_recv | 0.096 | 0.433 | 3.476 | 3.380 |
| rtnet_recv | 1.356 | 1.607 | 6.248 | 4.892 |
X86 DPDK vs. PREEMPT-RT PACKET_MMAP 网络包收发
平均提升对比:DPDK 平均 15us,PACKET_MMAP 平均 22us
A40I UIO vs. PREEMPT PACKET_MMAP 网络包收发
表1:发送测试对比
| 指标 | 最小(us) | 平均(us) | 最大(us) | 抖动(us) |
|---|---|---|---|---|
| uio_send | 4.916 | 5.556 | 21.709 | 16.793 |
| socket_send | 15.541 | 32.796 | 127.917 | 112.376 |
表2:接收测试对比
| 指标 | 最小(us) | 平均(us) | 最大(us) | 抖动(us) |
|---|---|---|---|---|
| uio_recv | 0.707 | 8.318 | 24.834 | 24.127 |
| socket_recv | 4.459 | 5.434 | 25.375 | 20.916 |
| 需要注意的是,这里主要测试需要的CPU时间差异,我们认为函数执行完毕即为网络包已发送到网线上,但是你需要清楚,raw packet一般受操作内核和网络协议栈机制的影响,函数执行完不一定代表已操作硬件发送(这里使用的是xenomai rtnet,不存在该问题)。另外,就算用户态驱动直接操作了网卡硬件,但是数据的传输还是受DMA不确定性的影响,实际网络包出现在网线上也会有偏差。本人没有硬件时间戳抓包器,否则可以对比他们实际到网线上的差异,那才是实时性的真实体现。 | ||||
| 当然,你也可以使用串口实时性测试类似的方法来测试网络收发的实时性。 |
3. UIO vs. linux PACKET_MMAP网络包收发
既然xenomai UDD与linux UIO原理一致,笔者一低端ARM平台上,使用PREEPMT-RT下,同样以以太网包收发为例,使用UIO与linux 内核PACKET_MMAP收发对比如下(其中rt_表示UIO),仅供参考。
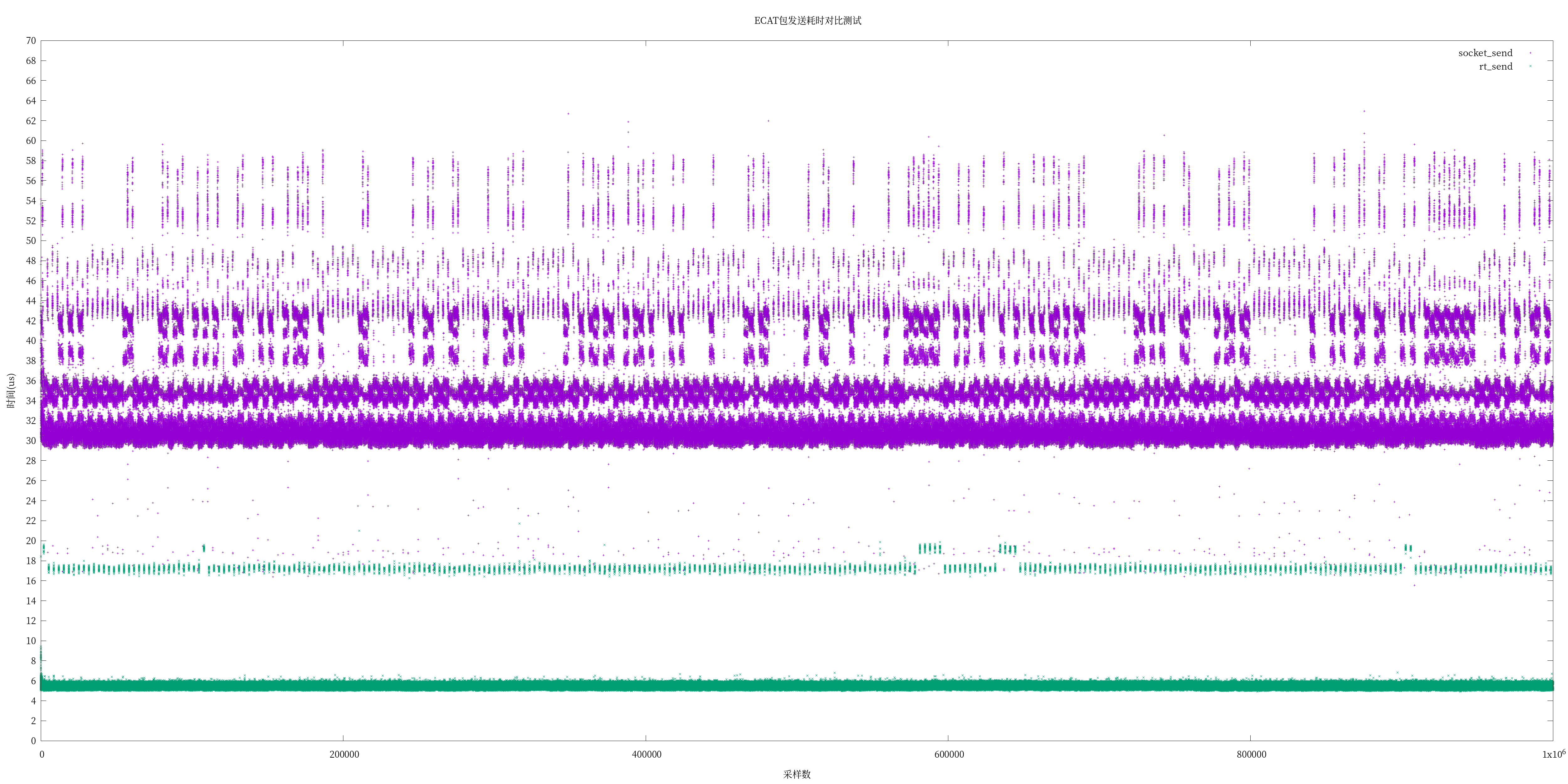
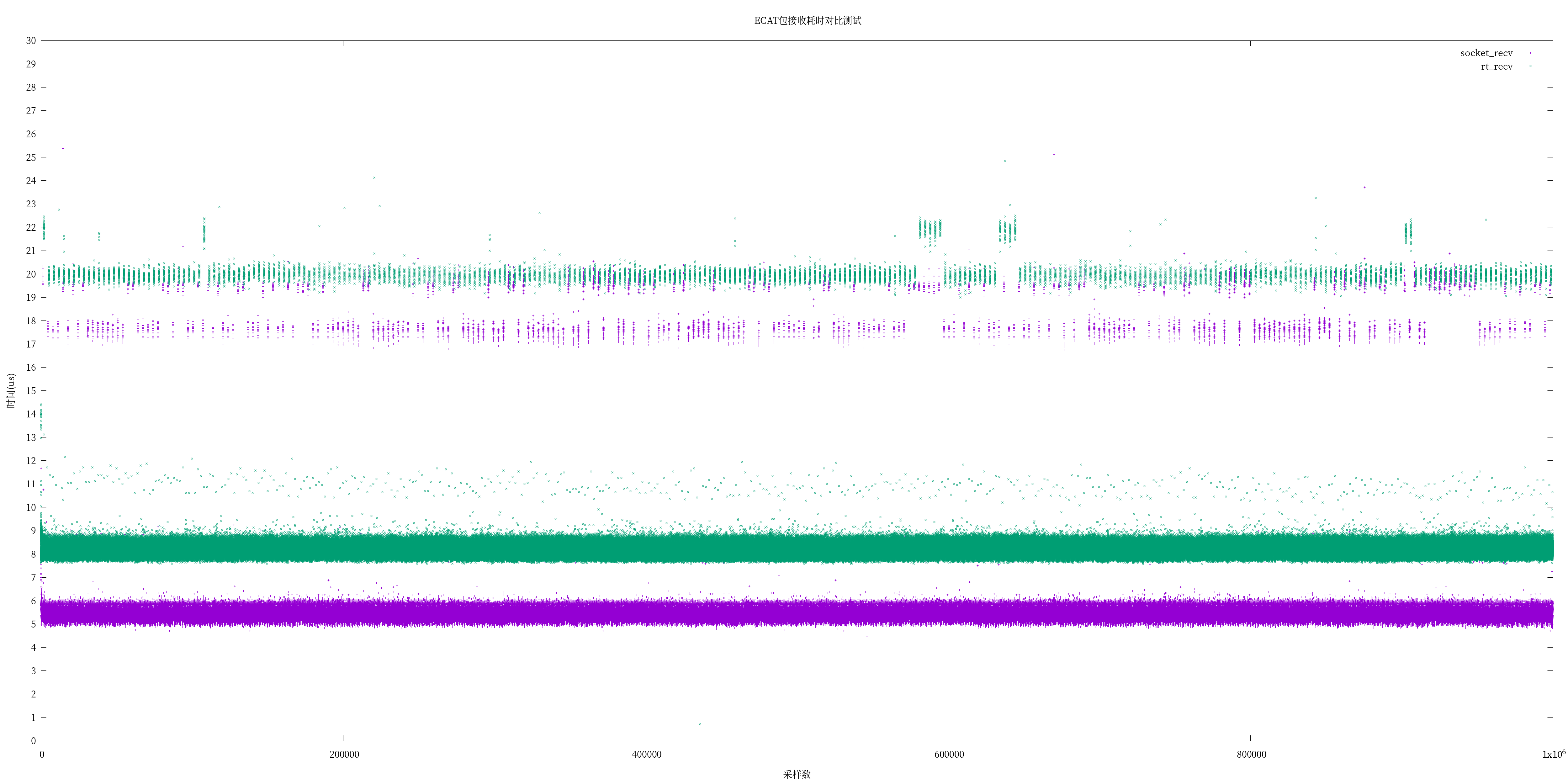
简单说明一下为什么接收时,UIO花的时间比PACKET_MMAP多,是因为UIO使用的是interrupt less,需要我们轮询处理,时间是完整的操作网卡接收所需的时间。而内核PACKET_MMAP因为网卡驱动通过中断接收,内核早已将网络包接收,所以从应用测量的接收时间只是我们从内核拿数据的时间。
四 总结
1. 作用
将硬件操作映射到用户空间,用户态直接操作硬件,减少用户态与内核态之间的数据拷贝与交互。
2. 优点
实时性方面,由于直接在用户态操作硬件,减少了系统调用路径中的不确定性。
性能方面,减少内核页表切换开销、cache换入换出等,释放部分CPU资源,提高CPU性能,同时降低抖动延迟。
调试方面,解决内核态容易造成系统崩溃死机等问题。
3. 注意事项
- 适用重输出场景,中断少的场景,如网卡发包、IO输出。
- UDD用户态驱动中断的处理比内核态驱动中断处理路径长,需要权衡内核态与用户态的收益进行选择。
- 无中断情况下,UDD与UIO一致,xenomai可直接使用基于UIO的linux用户态驱动。
- 不要过度优化,要考虑投入产出比,从X86平台网络收发包测试可以看到,虽然有提升,但是这点提升是你的主要性能瓶颈吗?还是把精力放到更需要优化的地方去吧!!!
linux有多重网络包收发的方式,后续从实时的角度写一篇文章看看一下这些方式,敬请关注。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号