


网络通讯中粘包的处理
在网络通讯中,不仅仅是TCP通讯,也包括串口通讯中,我们经常会遇到数据包粘连的问题,本文详细介绍粘包问题产生的原因和解决办法。
一、粘包定义
TCP 传输中,客户端发送数据,实际是把数据写入到了 TCP 的缓存中,由于传输的过程为数据流,经过TCP传输后,多条数据被合并成了一条,这就是数据粘包了。图示如下:
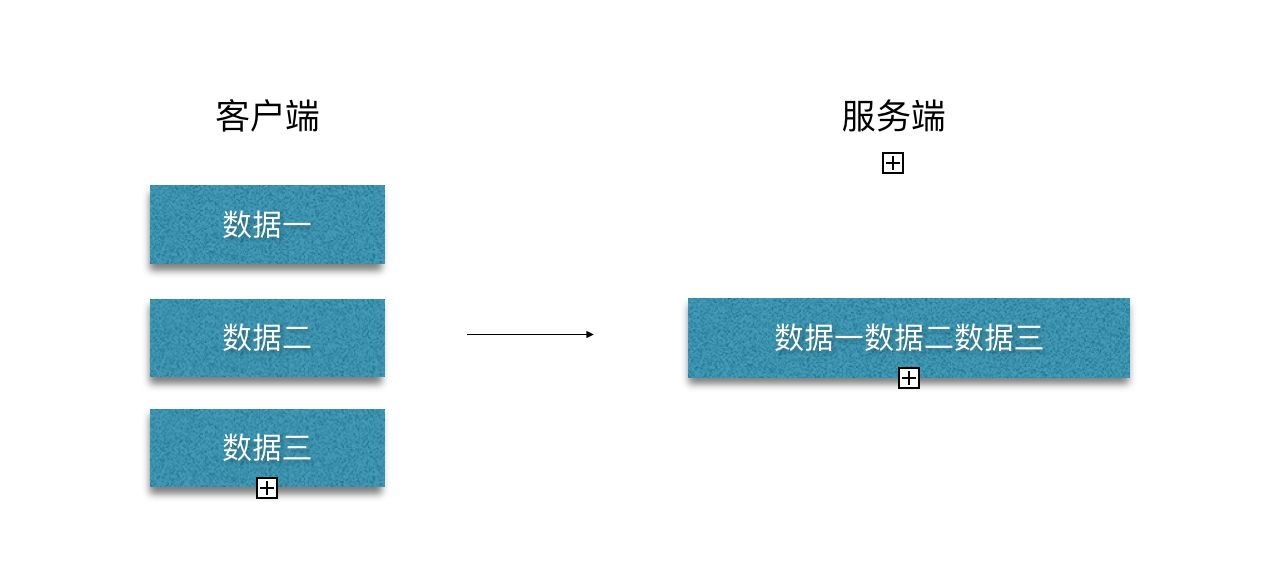
二、产生原因
其实从上面的定义,我们就可以大概知道产生的原因了。
粘包的主要原因:
- 发送方每次写入数据 < 套接字(Socket)缓冲区大小
- 接收方读取套接字(Socket)缓冲区数据不够及时
半包的主要原因:
- 发送方每次写入数据 > 套接字(Socket)缓冲区大小
- 发送的数据大于协议的 MTU (Maximum Transmission Unit,最大传输单元),因此必须拆包
其实我们可以换个角度看待问题:
- 从收发的角度看,便是一个发送可能被多次接收,多个发送可能被一次接收。
- 从传输的角度看,便是一个发送可能占用多个传输包,多个发送可能共用一个传输包。
根本原因,其实是
TCP 是流式协议,消息无边界。
(PS : UDP 虽然也可以一次传输多个包或者多次传输一个包,但每个消息都是有边界的,因此不会有粘包和半包问题。)
三、解决方法
就像上面说的,UDP 之所以不会产生粘包和半包问题,主要是因为消息有边界,因此,我们也可以采取类似的思路。
1. 改成短连接
将 TCP 连接改成短连接,一个请求一个短连接。这样的话,建立连接到释放连接之间的消息即为传输的信息,消息也就产生了边界。
这样的方法就是十分简单,不需要在我们的应用中做过多修改。但缺点也就很明显了,效率低下,TCP 连接和断开都会涉及三次握手以及四次握手,每个消息都会涉及这些过程,十分浪费性能。
因此,并不推介这种方式。
2. 固定长度
这种方式下,消息边界也就是固定长度即可。
优点就是实现很简单,缺点就是空间有极大的浪费,如果传递的消息中大部分都比较短,这样就会有很多空间是浪费的。
因此,这种方式一般也是不推介的。
3. 分隔符
这种方式下,消息边界也就是分隔符本身。
优点是空间不再浪费,实现也比较简单。缺点是当内容本身出现分割符时需要转义,所以无论是发送还是接受,都需要进行整个内容的扫描。
因此,这种方式效率也不是很高,但可以尝试使用。
4. 专门的 length 字段
这种方式,就有点类似 Http 请求中的 Content-Length,有一个专门的字段存储消息的长度。作为服务端,接受消息时,先解析固定长度的字段(length字段)获取消息总长度,然后读取后续内容。
优点是精确定位用户数据,内容也不用转义。缺点是长度理论上有限制,需要提前限制可能的最大长度从而定义长度占用字节数。
因此,十分推介用这种方式。
5. 其他方式
其他方式就各不相同了,比如 JSON 可以看成是使用{}是否成对。这些优缺点就需要大家在各自的场景中进行衡量了。
四、举例
Netty 中的实现:使用了固定长(FixedLengthFrameDecoder)、分隔符(DelimiterBasedFrameDecoder)、专门的length字段(LengthFieldBasedFrameDecoder)三种方案;
CMPP协议中:协议头有Length字段定义包的长度,接收方按长度进行拆分即可。(主要是接收SubmitResp、Deliver包需要特别注意粘包的处理)
SIGP协议、SMGP协议与CMPP协议类似,协议中都定义了包的长度Length字段。
对于单个数据缓冲区可能接收到半包的问题,可以设计一个滚动的长缓存区负责接收存放数据,这样多个半包可以重新组合成一个完整包,然后另起解析线程异步对包进行拆解处理。
下面代码片段显示了实现:
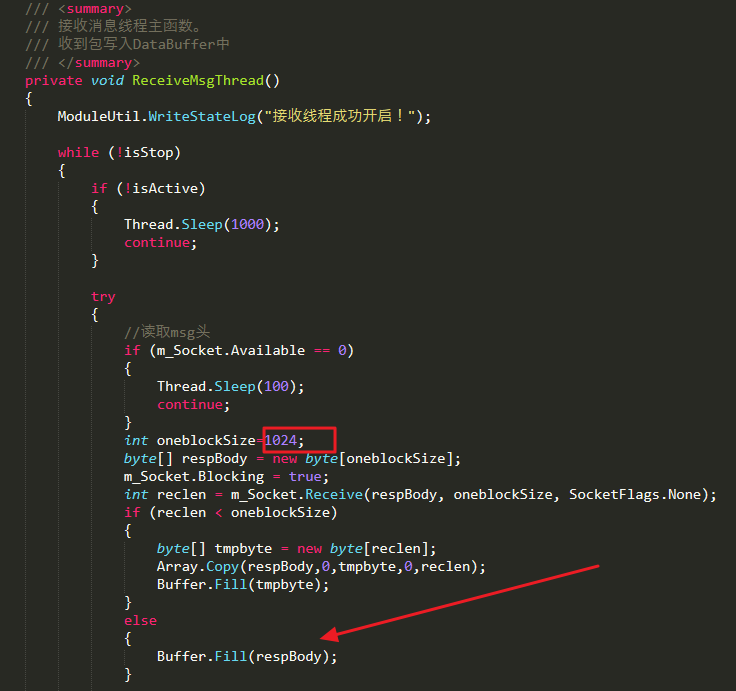
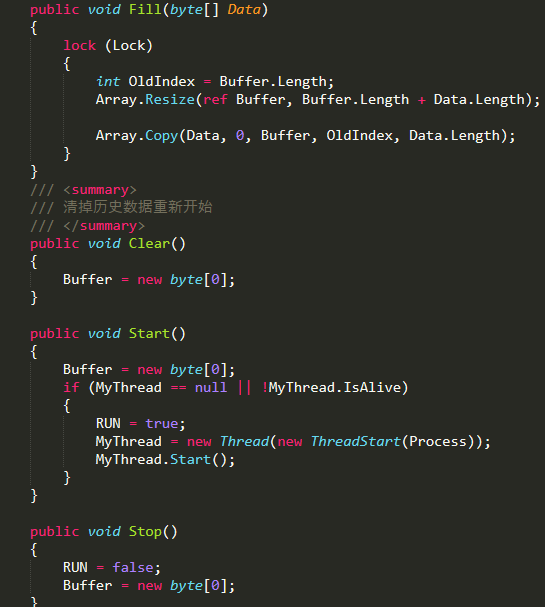
这里接收数据的线程(发送线程不存在粘连包的问题),只负责接收并往Buffer里插入数据,Buffer里再去按协议包格式长度进行拆包。这里虽然临时接收缓存为1024个字节,但并不用担心数据包会截断,因为所有数据包最终都会组合到一个长缓存区进行拆解。Buffer类的代码片段:

 浙公网安备 33010602011771号
浙公网安备 33010602011771号