机器学习课程笔记 4
上一篇 -> 机器学习课程笔记 3。
0. 前情提要
0.1 Attention
- 注意力机制
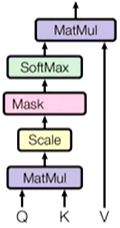
0.2 Self-Attention
- Q、K、V 同源
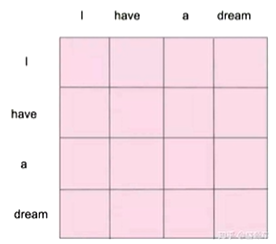
0.3 Masked Self-Attention
- 为了弥补Self-Attention的缺点
前一序列输入并未得知后续有什么,所以为了更贴近实际,将后续的信息遮挡起来,只计算已知的信息的关联性。

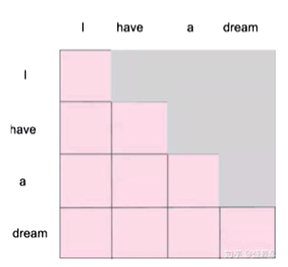
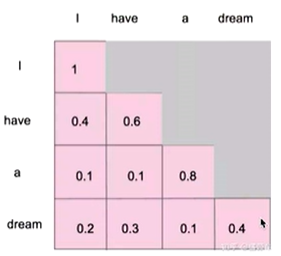
- 逐一生成,逐一计算,最后给出。
1. Transformer
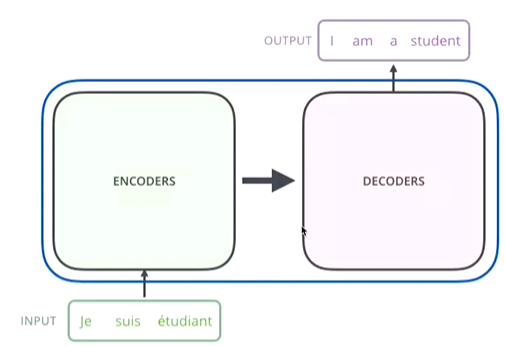
- Encoder-Decoder框架(seq2seq)
- 简化来看
- 粒度再细点
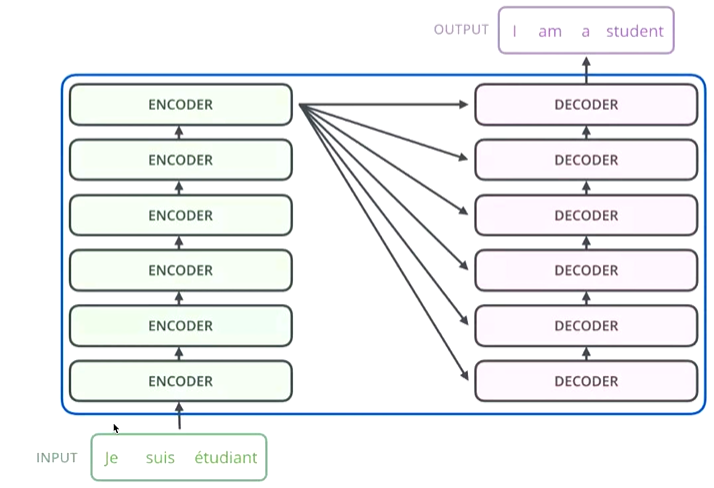
- 粒度再细点
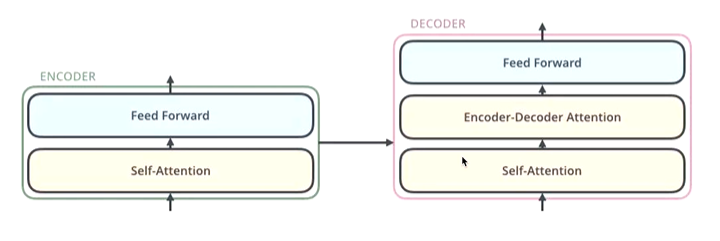
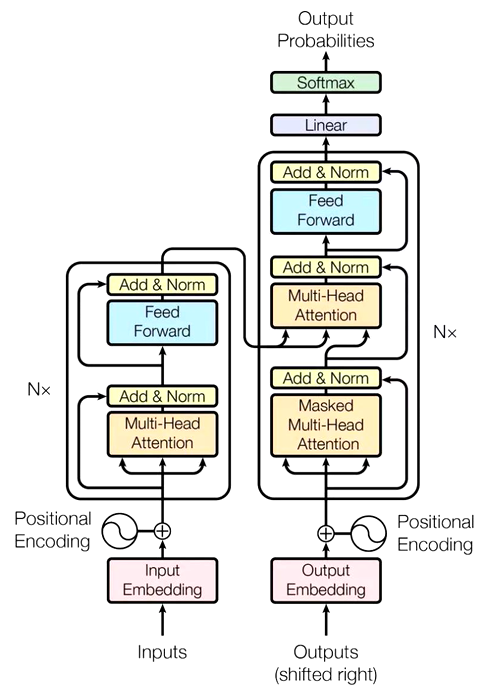
1.1 Encoder 编码器
- 简单理解
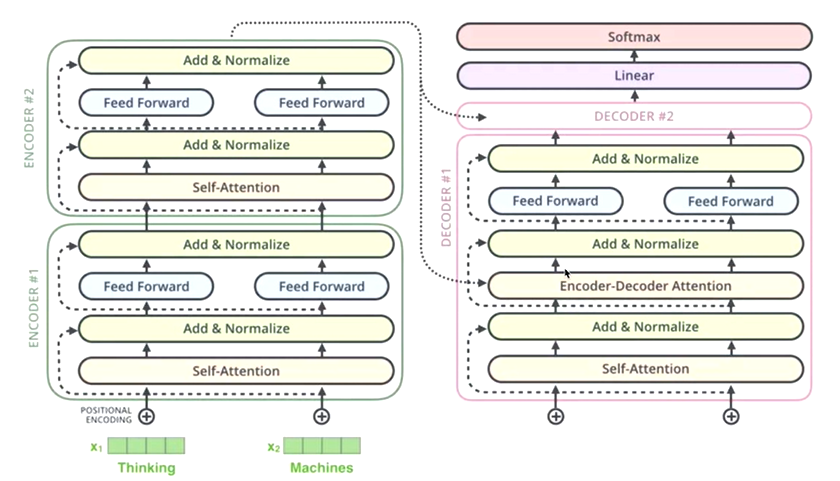
从输入中抓取有用的信息,将其组合成解码器可以处理的信息。 - Encoder 由小 Encoder 叠加(transformer 有 N 个), 逐步加强对信息的抓取和组合。
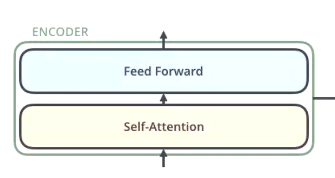
- Self-Attention
- Feed Forward
- 每个子层都还有一个 残差网络 + 归一化
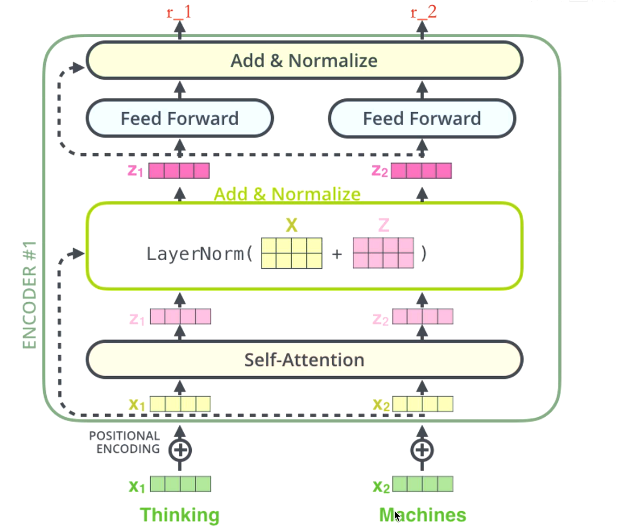
- 以\(z_1\)为例
- 总体来说就是让数据的表征更加优秀。
1.2 Decoder 解码器
- 简单理解
从编码器信息中抓取有用的信息,结合输入的目标生成可用结果。 - Decoder 由小 Decoder 叠加(transformer 有 N 个),逐步加强对信息的抓取和生成。
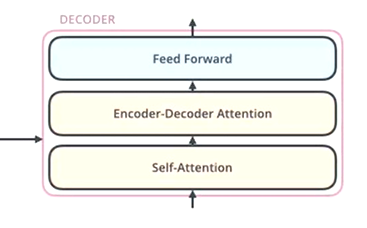
- Self-Attention
此处的加入了 Mask,为什么?原因?- 简单比喻,“你知道卷子所有的题目”和“你考试时一道道知晓”,哪个更符合测验的本质?
- 肯定是第二种,所以训练时按照测试时的思路去让机器学习,Mask 遮挡后续数据,“一道道”处理。
- Feed Forward
- Encoder-Decoder Attention
这里Attention名称变了,说明 Q、K、V 的来源变了。- 即 K、V 来自于 Encoder,Q 来自于 Decoder 。
- 回顾注意力机制的本质,提取重要信息,所以这里 Q 是解码的目标表征,而 K、V 是要解码的数据表征, 利用目标 Q 结合数据 K 得出重要信息权重,后结合数据 V 进一步把真正解码的信息求出。

- 每个子层都还有一个 残差网络 + 归一化。
- 最后全连接和softmax层的作用
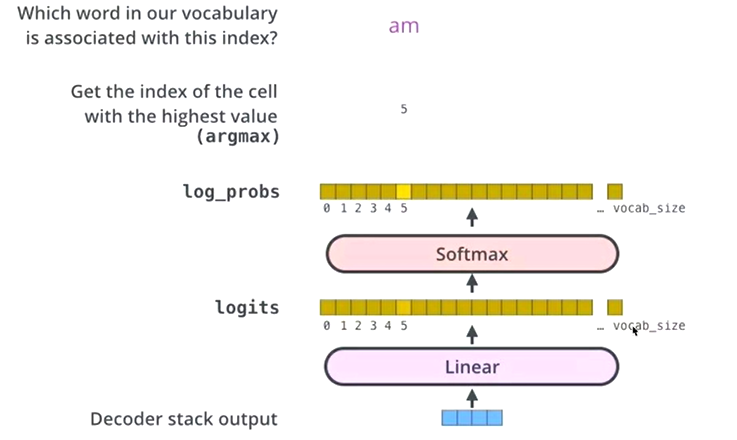
- 根据softmax最大概率,确定此位置的单词。
1.3 原本的seq2seq框架问题
- 原本是两个 LSTM,一个为 Encoder,一个为 Decoder;
- 导致每次生成的词都是利用 Encoder 的到的全部信息去生成(很多对生成新词并无太大意义),Transformer 解决了这个问题。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号