机器学习课程笔记5
上一篇 -> 机器学习课程笔记 4。
生成式对抗网络(Genrative Adversarial Network)
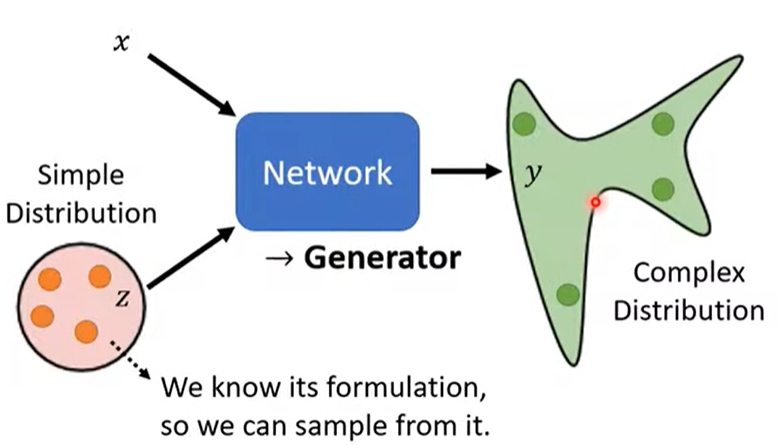
- 输入:X 和简单分布下的随机值Z(每次都随机);
- 输出:复杂分布的 y。
1. 为什么要用 GAN ?
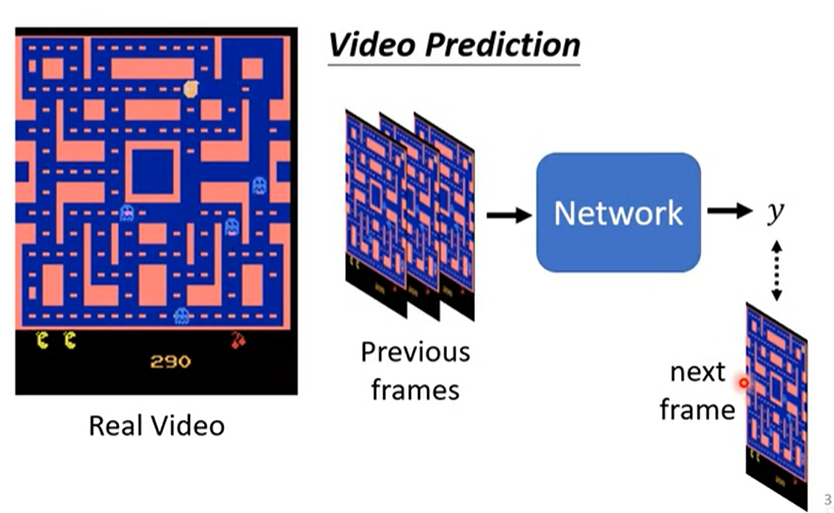
1.1 需求
根据视频中怪物的前几帧的移动,预测其下一帧的运动。
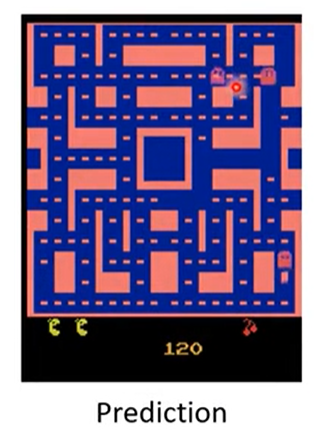
1.2 结果
普通网络学习后,会出现不符合移动的分裂现象,即同一个怪物分成两个,向不同的方向移动,如下图。
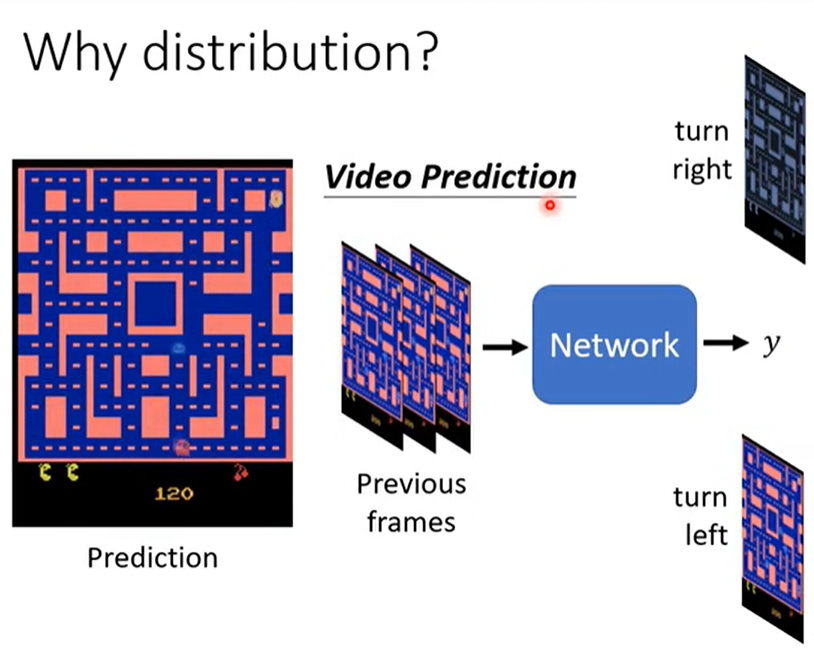
1.3 原因
根据之前学习的帧,相同的位置,怪物存在两种不同方向的位移,所以模型为了“准确”表现学习的效果,在这个出现时,怪物的两种位移同时展现。
1.4 解决方法
GAN神经网络。
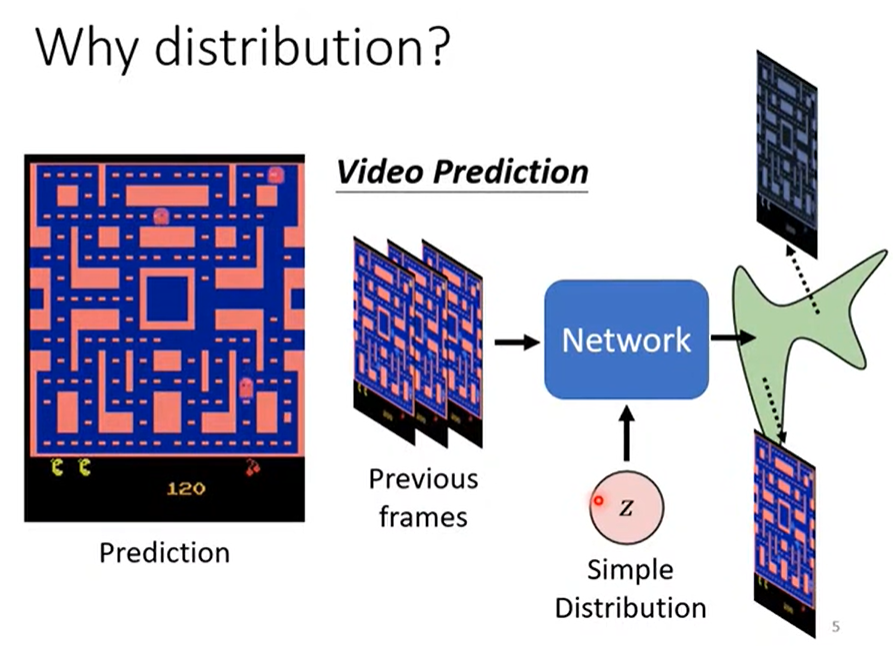
1.5 解决的本质问题
同样的输入可以有多种输出,如下图画画和问答。
2. 怎么训练 GAN ?
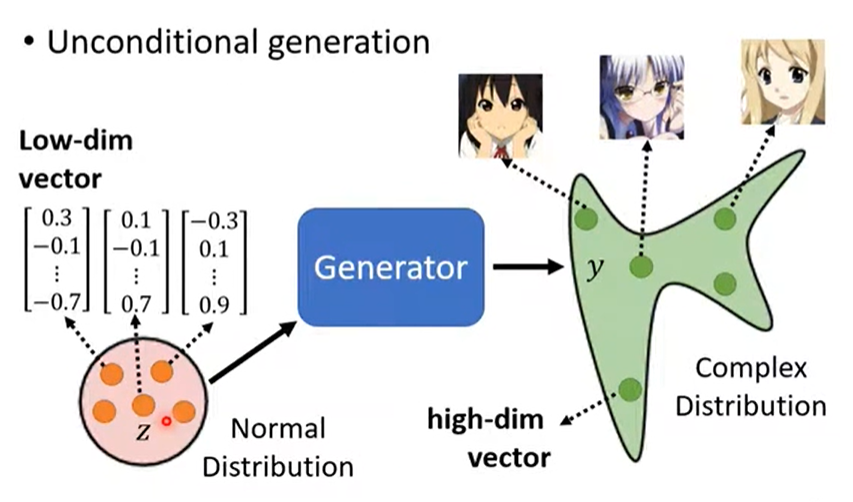
2.1 选择一个简单分布
如利用简单的正态分布作为随机Z输入到网络,训练得到复杂分布的动画人脸。
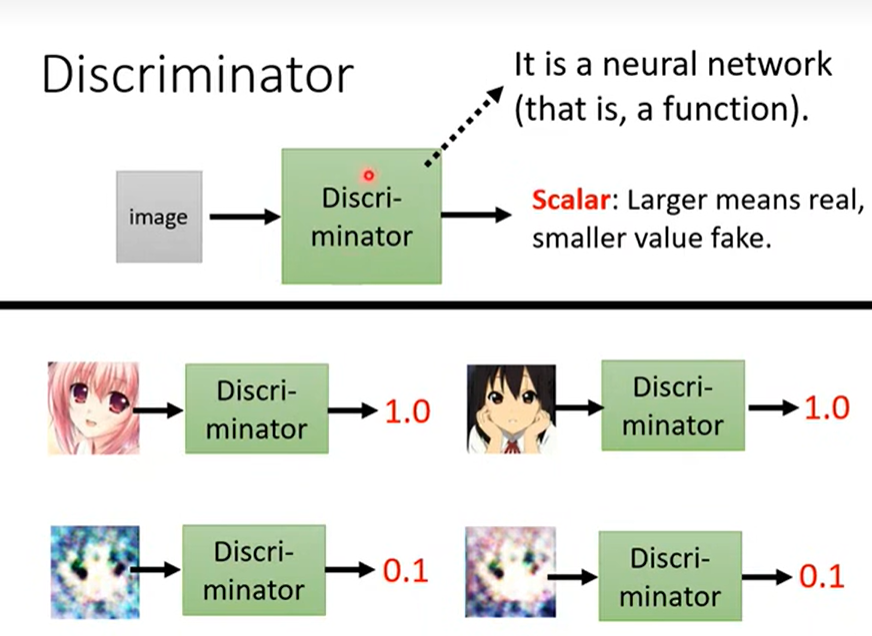
2.2 训练一个鉴别器(Discriminator)
- 鉴别器:仍是一个神经网络,可以用CNN等。
- 作用:输入图片,输出Scalar。
- 量化指标:Scalar越大表示图片越接近真实标签,反之亦然。
2.3 Generator 和 Discriminator
- 本质:“物竞天择”。
- Discriminator 会对 Generator 生成的结果进行打分筛选。
- 每次筛选的打分影响 Generator 后续生成的结果。
- 以此类推,进行“Adversarial 对抗”,直到训练完成。
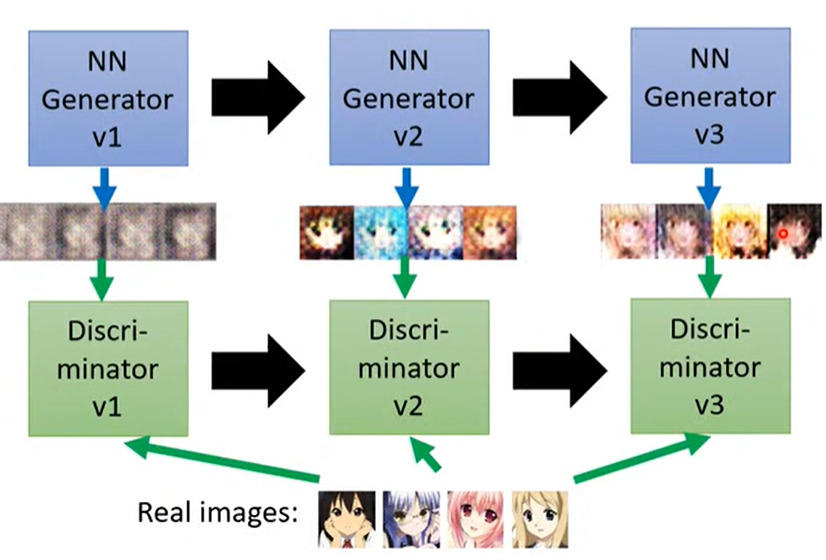
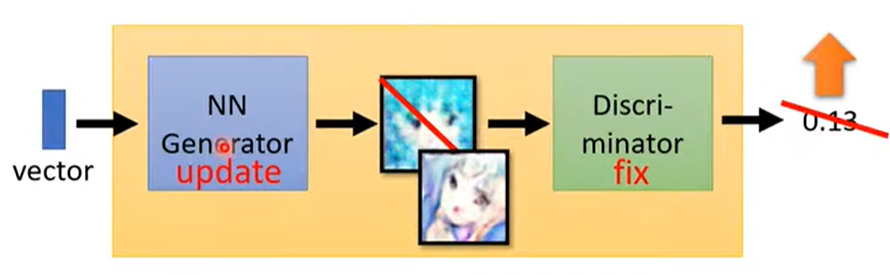
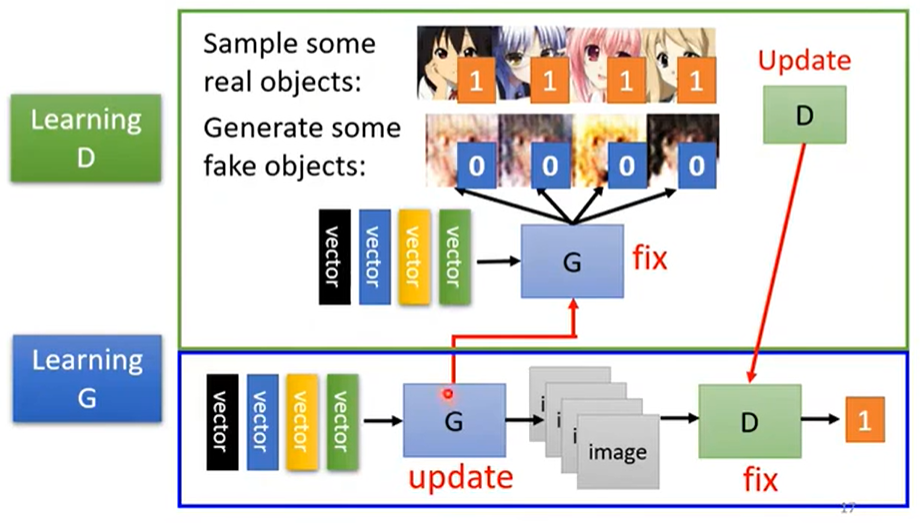
2.4 训练步骤
-
固定 Generator G,训练 Discriminator D。
让 D 学习 G 生成的图片和真实图片的差别。
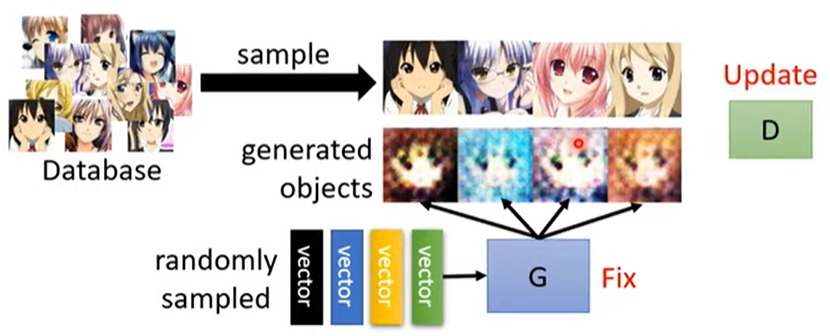
-
固定 Discriminator D,训练 Generator G。
利用 D 给的分数,G 学习如何“骗”过 D。
-
总体
3. GAN 背后的原理
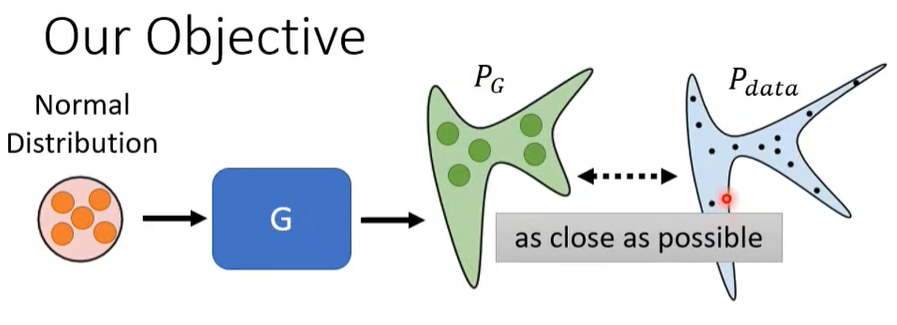
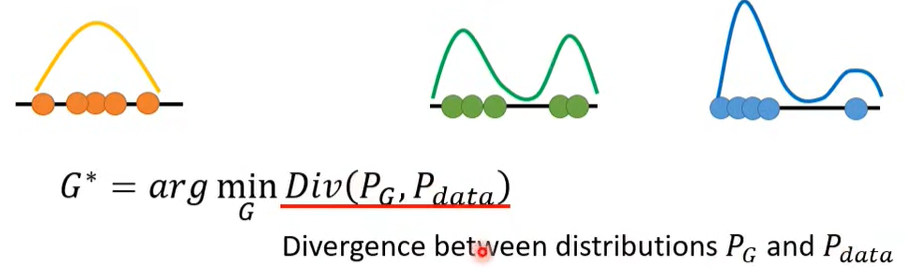
- 找到 可以使预测和真实值之间 Divergence(分歧)最小化的一组参数。
3.1 怎么找?
- 获取分布
- 从真实数据采样处得到真实分布
- 从 G 对采样的简单分布生成的结果处得到预测分布

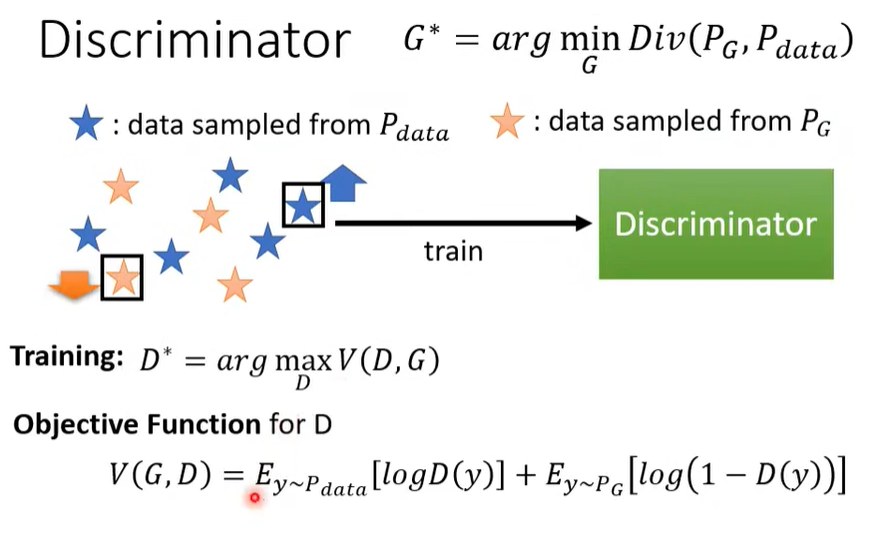
- 训练 Discriminator
- 最大化分辨器 Object Function 的结果
- 因为是\(log\)和加法,即 \(V(G, D)\) 中真实数据的分数 \(D(y)\) 越高, 预测数据的分数 \(1 - D(y)\) 中的 \(D(y)\) 越低,越好。
- \(V(G, D)\) 也可以理解为负交叉熵,即求交叉熵的最小值。

- 通过观察 Object Function 获取 Divergence
- Object Function的值和分歧值有相关性,具体如下图所示。
- 也意味着求分歧可以通过求解最小化的max \(V(G, D)\),即 JS Divergence。
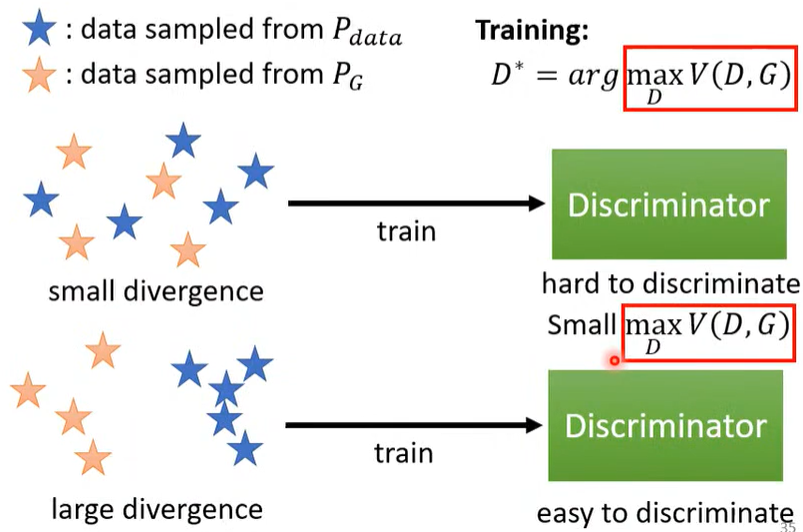


联系之前的具体步骤:

- 那么现在每一种 Object Function 就可以形成一种 Divergence。

4. GAN的小技巧
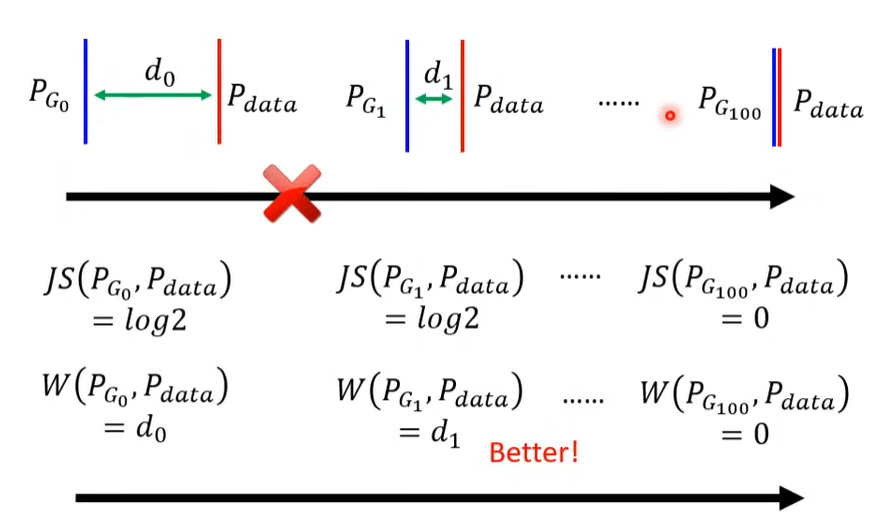
- GAN 不好训练
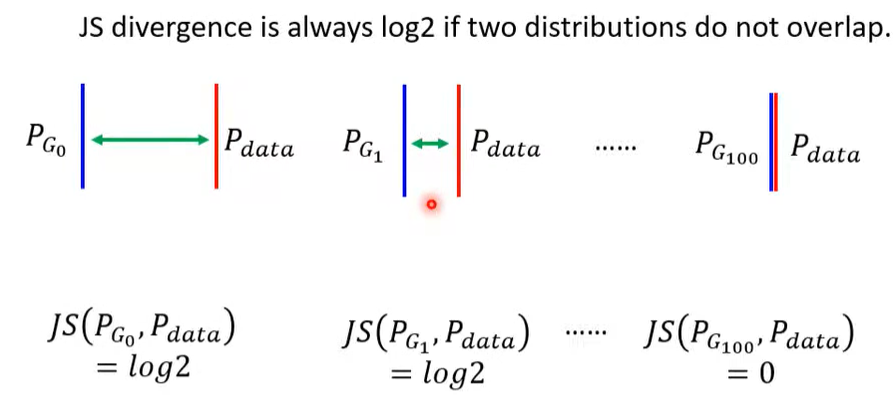
- JS Divergence 不适合
原因如下图

主要就是预测和真实的数据重叠部分很少。
而 JS Divergence 需要数据重叠多,效果才好,具体如下图。


4.1 Wasserstein Distance
抛弃 JS,选用新的 Divergence指标 ---> Wasserstein Distance。
- 调整预测的分布使其接近真实数据的分布。
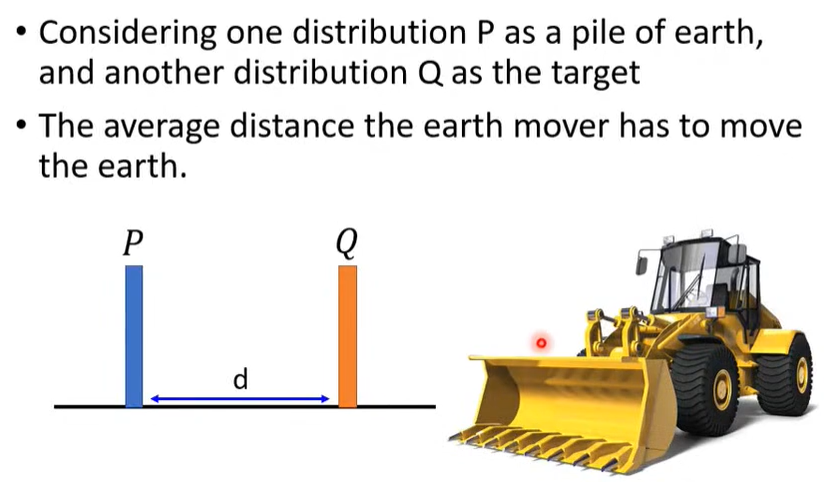
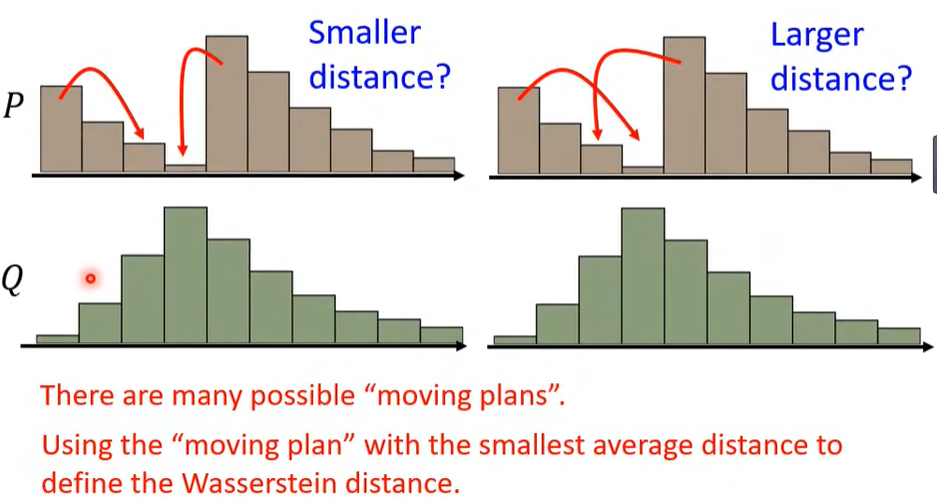
- 选取最合适的调整方案进行调整,即调整所用的平均distance最小。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号