【学习】Xinference在wsl中部署
一、前言
该系列文章主要目的是掌握Dify、Ollama、Xinference工具链的搭建和原理,熟悉后无论是在本地还是云服务器,流程都是一样的(除了远程连接的方法):
- Dify+Ollama+WSL配置
- Dify部署本地知识库并应用
Ollama作为本地大模型管理工具非常好用,但是他Embedding模型很少,Rerank干脆没有,因此我们这里引入Xinference框架,用来管理和维护Embedding和Rerank。
二、部署
2.1 Conda环境
Xinference支持通过库安装到python环境中,也支持Docker集成安装,这里为了方便我们学习和自由度,选择库安装。因此需要conda帮我们维护python环境。
大家可以按照我的版本进行安装,方便排查问题。
- 创建python310环境
conda create -n xinference_env python=3.10
conda activate xinference_env
python -m pip install --upgrade pip
2.2 安装Xinference
后续所有步骤均在conda的xinference_env虚拟环境下执行,不在赘述。
- 固定版本安装Xinference
pip install 'xinference==1.5.0'
- 检查显卡驱动
- 无论是Embedding还是Rerank,在处理大规模数据时,GPU上限更高(笔记本集显后续可以用CPU跑,做技术验证而已,不强求)
~ > nvidia-smi py base 13:30:17
+-----------------------------------------------------------------------------------------+
| NVIDIA-SMI 560.35.02 Driver Version: 560.94 CUDA Version: 12.6 |
|-----------------------------------------+------------------------+----------------------+
| GPU Name Persistence-M | Bus-Id Disp.A | Volatile Uncorr. ECC |
| Fan Temp Perf Pwr:Usage/Cap | Memory-Usage | GPU-Util Compute M. |
| | | MIG M. |
|=========================================+========================+======================|
| 0 NVIDIA GeForce RTX 4090 D On | 00000000:01:00.0 On | Off |
| 32% 32C P8 17W / 425W | 1628MiB / 24564MiB | 47% Default |
| | | N/A |
+-----------------------------------------+------------------------+----------------------+
+-----------------------------------------------------------------------------------------+
| Processes: |
| GPU GI CI PID Type Process name GPU Memory |
| ID ID Usage |
|=========================================================================================|
| No running processes found |
+-----------------------------------------------------------------------------------------+
- 安装torch
pip install -i https://pypi.tuna.tsinghua.edu.cn/simple torch
pip install --upgrade torch torchvision torchaudio --index-url https://download.pytorch.org/whl/cu118
- 安装必要库(摸索过程中发现有些库不装Xinference下载模型时报错)
pip install xoscar==0.6.2
pip install sentence-transformers
pip install sentencepiece transformers torch
pip install protobuf
pip install httpx[socks]
注:如果你使用zsh进行开发,在安装socks时,使用:
pip install 'httpx[socks]'
三、应用
3.1 启动
这里监听所有地址,绑定到指定端口,默认6006
xinference-local --host 0.0.0.0 --port 6006
启动后,在宿主机访问xinference UI
http://localhost:6006
或
http://wsl主机ip:6006
效果:

3.2 安装模型
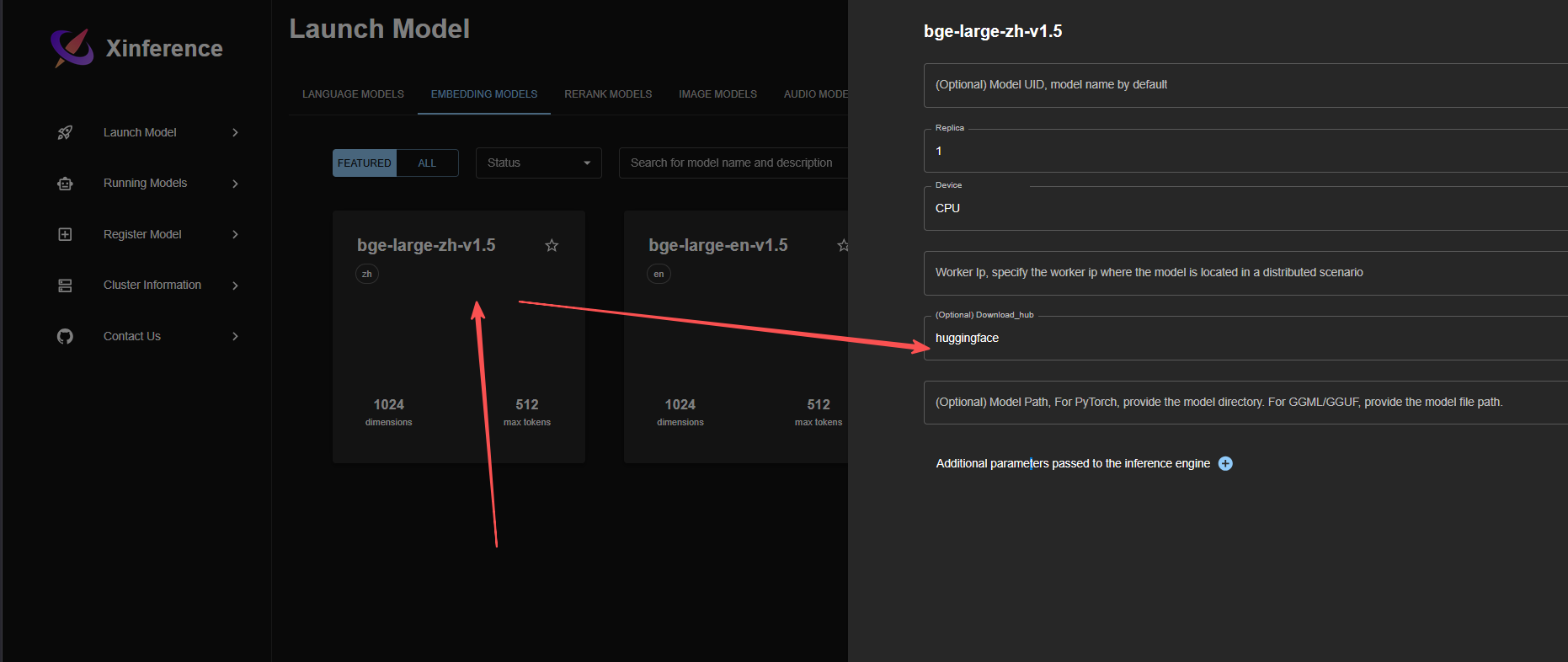
这里比较吃网速和代理,多等一会吧。
Rerank安装方法一致,在Rerank分类中,自定安装即可。
3.3 绑定Dify
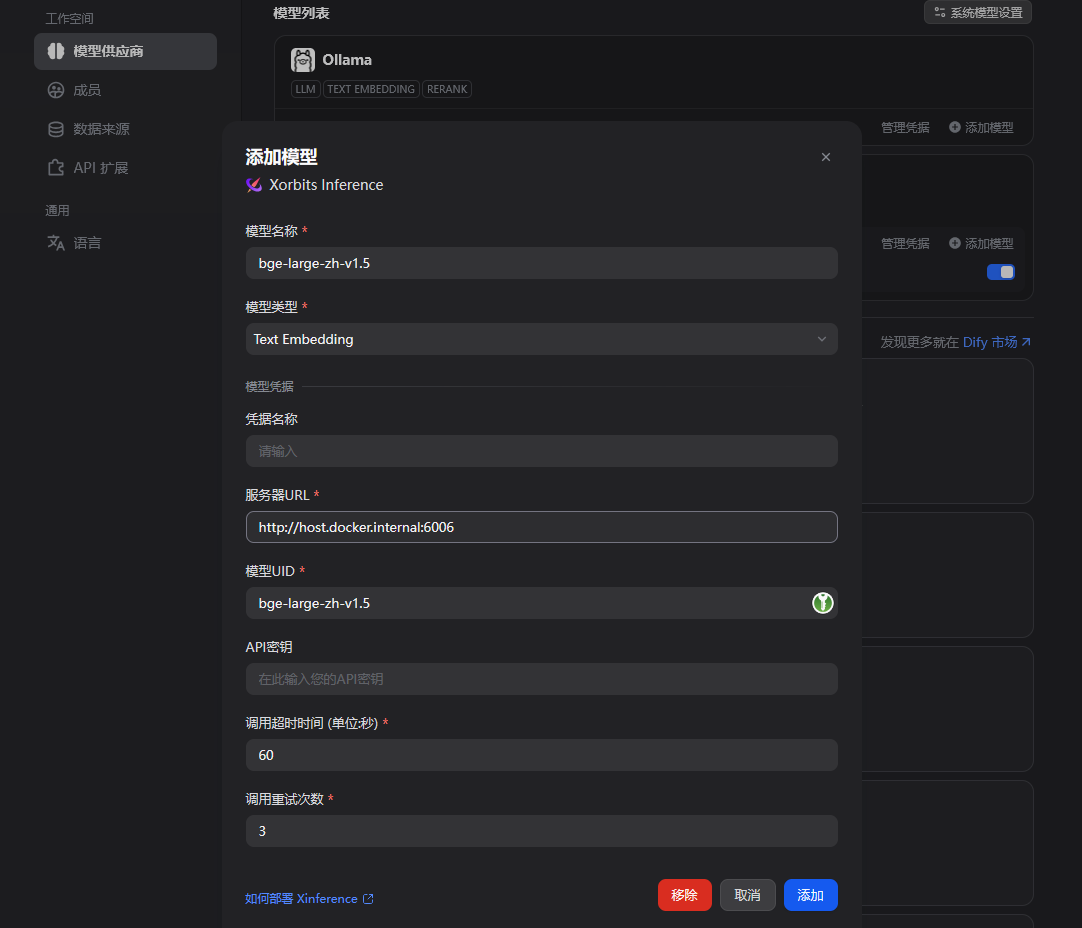
在Dify的模型供应商中安装Xinference的插件

填写必要信息,这里由于我的Dify在Docker中,与Ollama和Xinference在一个wsl实例,因此可通过http://host.docker.internal获取实例ip。
也可以手动hostname -I获取,然后拼接。


 浙公网安备 33010602011771号
浙公网安备 33010602011771号