【学习】Dify和Ollama在wsl中部署
一、部署Ollama
本篇文章使用环境为:
wsl2+ubuntu2404
1.1 安装ollama
找到linux的下载命令
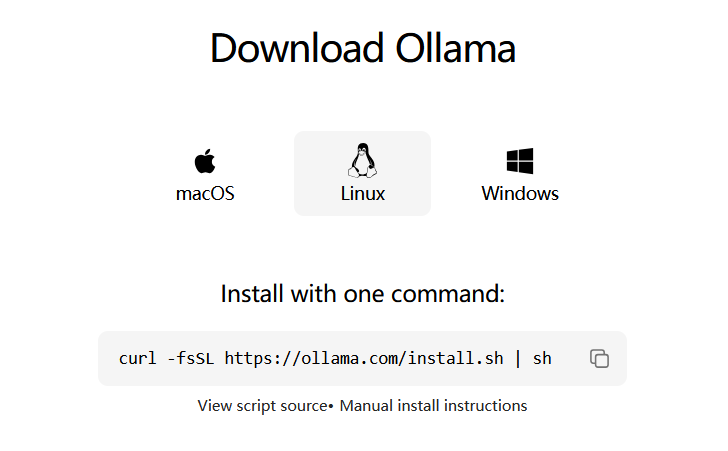
curl -fsSL https://ollama.com/install.sh | sh
下载并安装。
安装完成后,检查是否安装成功:
$ ollama --version
ollama version is 0.11.10
1.2 修改配置文件
停止ollama服务
sudo systemctl stop ollama
修改配置
sudo vim /etc/systemd/system/ollama.service
在[Service]中添加
Environment="OLLAMA_HOST=0.0.0.0"
保存退出后,重启服务
sudo systemctl daemon-reload
sudo systemctl restart ollama
1.3 下载和使用模型
这里我们用通义千问进行后续测试。
ollama官网的Models中包含其支持的各种模型,也可以直接在搜索框中检索想要的模型。
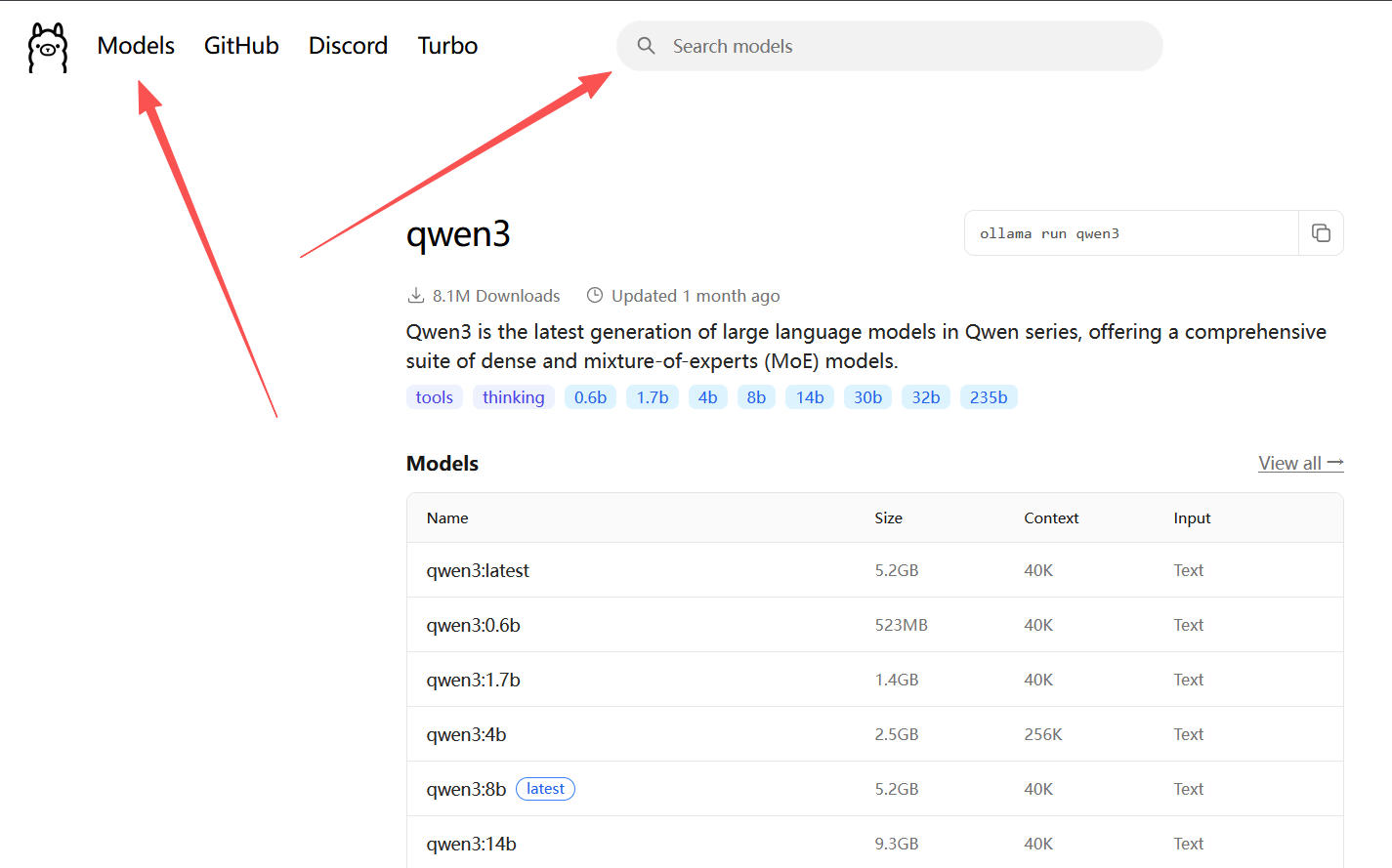
参数可以选择小的,测试而已。
我这里选择了qwen3:4b
点击选中的模型,右上角会给出运行命令(本地没有模型时,ollama会帮助我们进行下载)
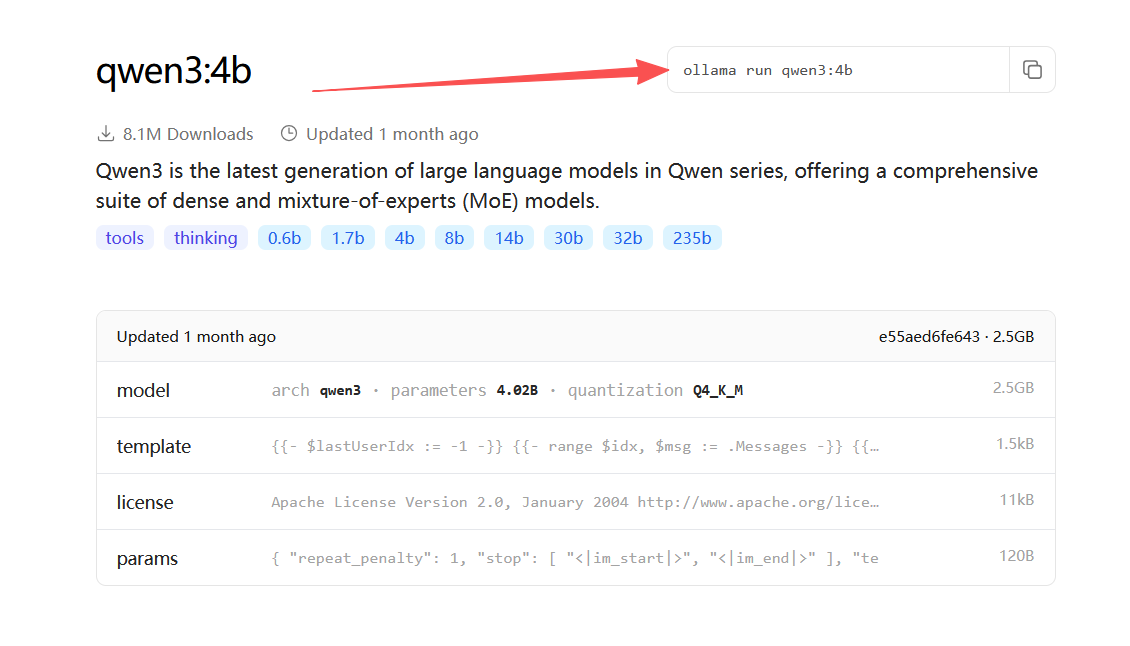
$ ollama run qwen3:4b
pulling manifest
pulling 3e4cb1417446: 100% ▕██████████████████████████████████████████████████████████▏ 2.5 GB
pulling 53e4ea15e8f5: 100% ▕██████████████████████████████████████████████████████████▏ 1.5 KB
pulling d18a5cc71b84: 100% ▕██████████████████████████████████████████████████████████▏ 11 KB
pulling cff3f395ef37: 100% ▕██████████████████████████████████████████████████████████▏ 120 B
pulling e18a783aae55: 100% ▕██████████████████████████████████████████████████████████▏ 487 B
verifying sha256 digest
writing manifest
success
>>>
1.3.1 直接交互测试
此时可以直接与qwen进行交互:
显示目前ollma中的模型:
$ ollama list
NAME ID SIZE MODIFIED
qwen3:4b e55aed6fe643 2.5 GB 3 minutes ago
1.3.2 网络请求测试
Ollama的默认监听端口是:11434
请求路径:/v1/chat/completions
完整请求命令:
curl -s http://127.0.0.1:11434/v1/chat/completions \
-H 'Content-Type: application/json' \
-d '{"model":"qwen3:4b","messages":[{"role":"user","content":"请用一行中文回答:通过自检。"}]}'

1.3.3 Python测试
这里我是用miniconda创建python环境,大家随意。
conda create -n ollama-py python=3.11 -y
conda activate ollama-py
pip install --upgrade pip
pip install "openai>=1.40" httpx tqdm
将ollama固定到这个虚拟环境中
conda env config vars set \
OAI_BASE_URL="http://127.0.0.1:11434/v1" \
OAI_API_KEY="ollama" \
OAI_MODEL="qwen3:4b"
conda deactivate && conda activate ollama-py # 让变量生效
最小功能测试
import os
from openai import OpenAI
base = os.getenv("OAI_BASE_URL", "http://127.0.0.1:11434/v1")
key = os.getenv("OAI_API_KEY", "ollama")
model= os.getenv("OAI_MODEL", "qwen3:4b")
cli = OpenAI(base_url=base, api_key=key)
resp = cli.chat.completions.create(
model=model,
temperature=0.2, max_tokens=32,
messages=[
{"role":"system","content":"只输出最终答案的一句话,不要解释,也不要包含<think>。"},
{"role":"user","content":"请用一行中文回答:小狗可爱吗?"}
],
)
print((resp.choices[0].message.content or "").strip())
二、部署Dify
2.1 安装和部署Docker
https://www.cnblogs.com/quantoublog/articles/19094997
2.2 安装和部署Dify
此处主要参考Dify官方文档:
https://docs.dify.ai/zh-hans/getting-started/install-self-hosted/docker-compose
开始安装前,请自己选好一个放置的目录。
拉取代码库
# 这里我选择了一个较近的release版本,大家可以自己选择版本(或者直接clone,不带branch)
git clone https://github.com/langgenius/dify.git --branch 1.8.1
启动Docker容器(这里没有配置docker和dify的自启,因此重启wsl后,需要再次cd到dify/docker下,执行docker compose)
cd dify/docker
cp .env.example .env # 复制环境配置
docker compose up -d # 如果是docker 1.x版本,这里是 docker-compose up -d
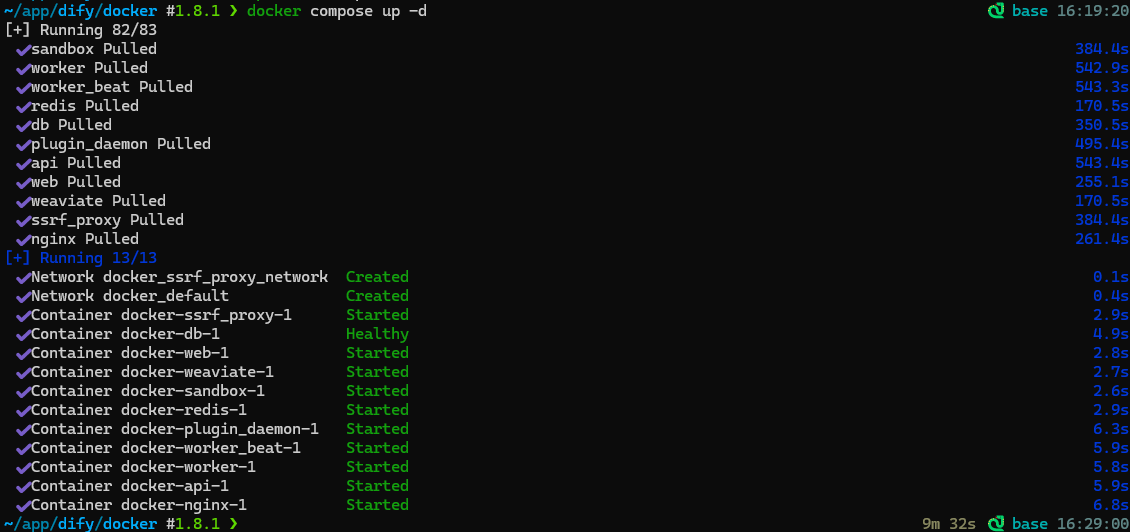
成功后,在浏览器上输入:
http://localhost/install
设置管理员账号并登录。

2.3 移除dify(希望你们用不到)
如果遇到各种无法解决的问题,可以选择移除dify重新配置。
- 进入到dify/docker目录,停止并移除容器
docker compose down -v
- 如果只需要停止不需要移除可以用:
# 进入到dify/docker目录
docker compose stop
三、整合ollama和dify
访问http://localhost/explore/apps
按照下图输入
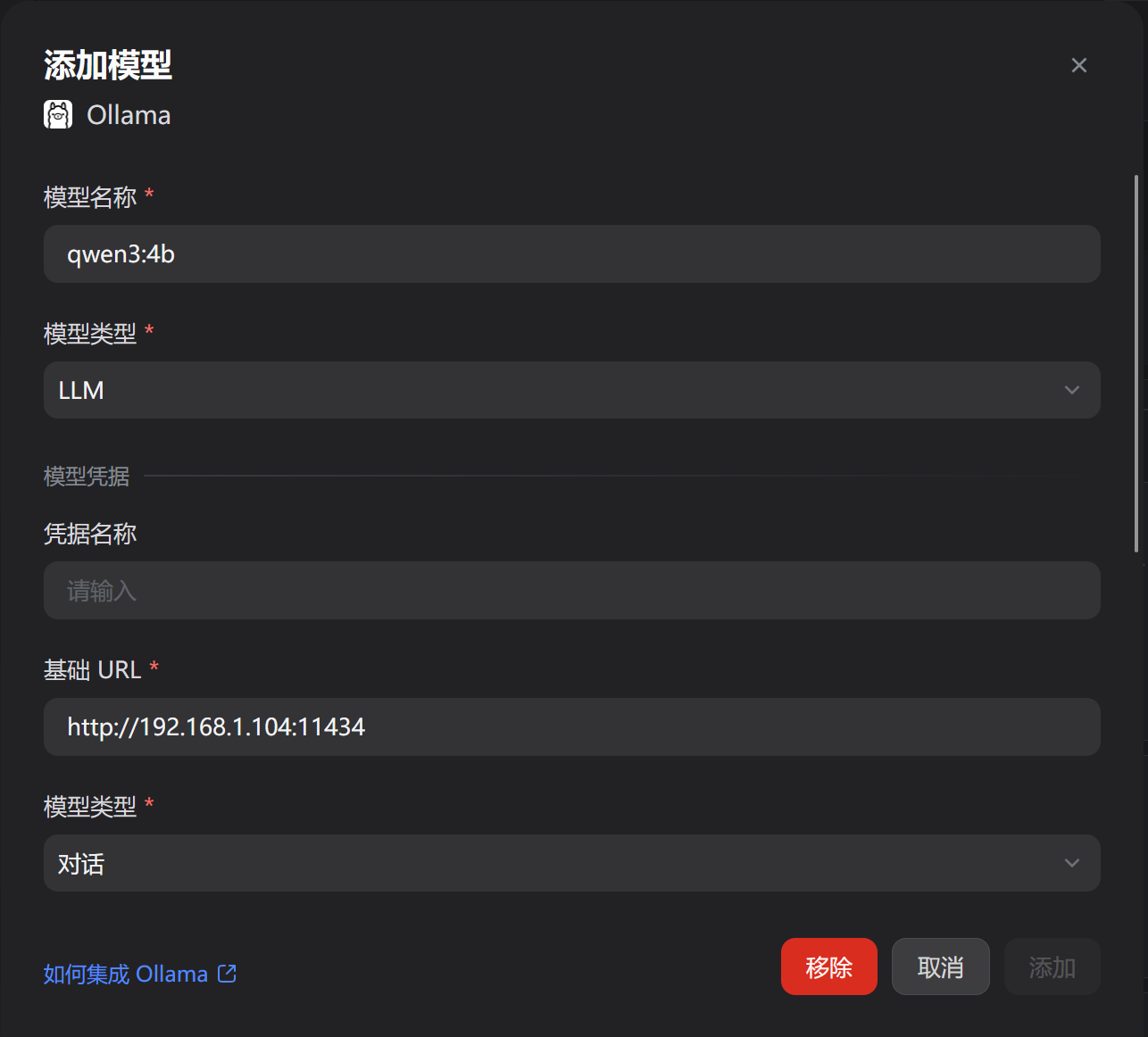
其中,模型名称在wsl中通过ollama list获取。
基础URL的ip地址在wsl中通过hostname -I获取(重启会改变,这里用wsl只是做验证)。
也可以直接通过docker获取到宿主机ip
http://host.docker.internal:11434
四、调用外部模型
本地算力有限,因此我们可以通过导入外部API的形式调用外部模型。
这里我们以Deepseek为例。
同样的,进入模型供应商,在下方找到深度求索
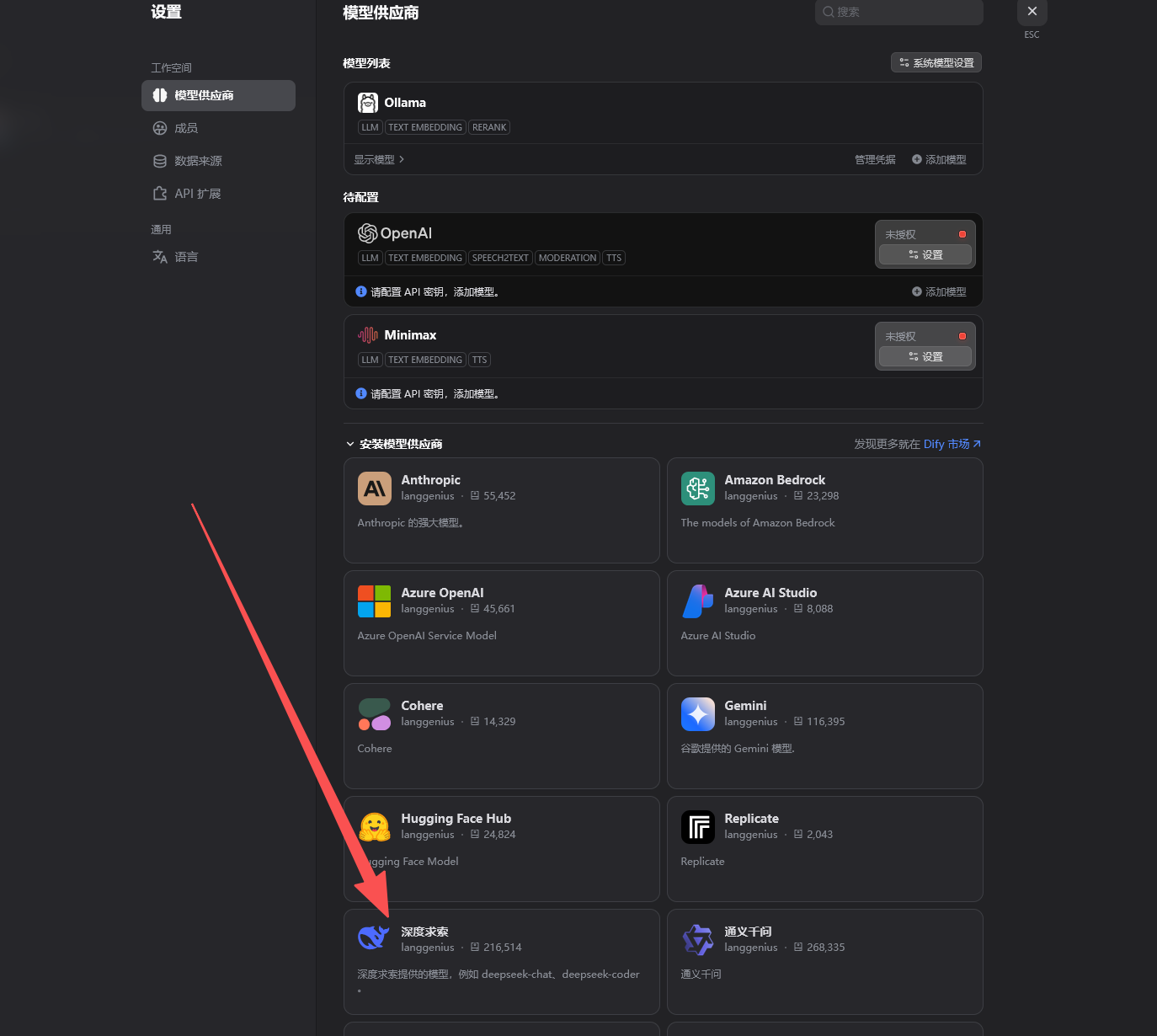
点击安装。
安装后,会出现在待配置列表中:

点击设置,输入必要信息:
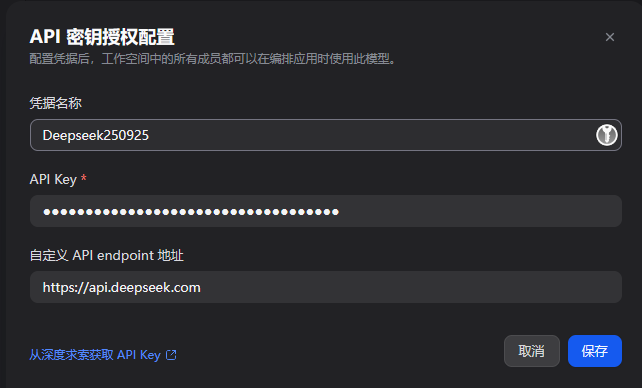
这里的endpoint填写deepseek的base url即可。
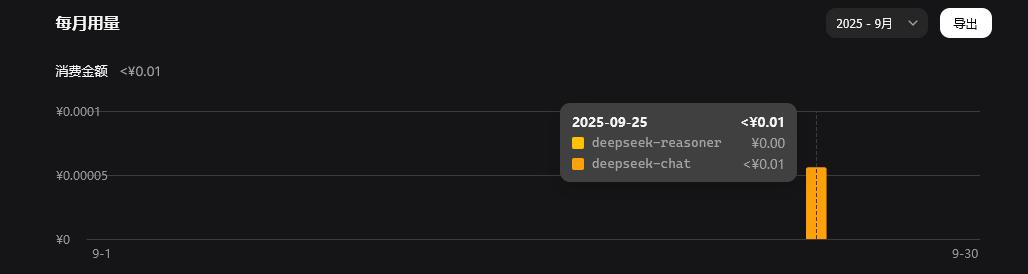
稍等几秒,就能在deepseek的流量统计中,看到dify发出的测试请求了:
五、常见问题
这里收集了我在部署过程中遇到的问题,希望能帮助同样遇到问题的你。
5.1 启动dify提示端口占用
docker compose up -d
Error response from daemon: ports are not available: exposing port TCP 0.0.0.0:80 -> 127.0.0.1:0: listen tcp 0.0.0.0:80: bind: Only one usage of each socket address (protocol/network address/port) is normally permitted.
此时有两种解决办法,一是找到占用进程然后kill掉(win10安装docker后,docker后台进程会占用80,因此这里可以通过方法二修改容器暴漏端口),二是更换端口。
1)方法一,找到占用进程并kill
在宿主机启动控制台,找到占用80端口的进程
netstat -ano | findstr :80
TCP 0.0.0.0:80 0.0.0.0:0 LISTENING 20040
根据进程号查看进程
tasklist /FI "PID eq 20040"
Image Name PID Session Name Session# Mem Usage
========================= ======== ================ =========== ============
com.docker.backend.exe 20040 Console 1 257,768 K
kill(这里不建议kill)
taskkill /f /pid 20040
2)方法二,更改暴露端口
进入dify/docker目录,修改.env文件
EXPOSE_NGINX_PORT=80
修改为任意端口,如8080
EXPOSE_NGINX_PORT=8080
5.2 系统尚未完全配置
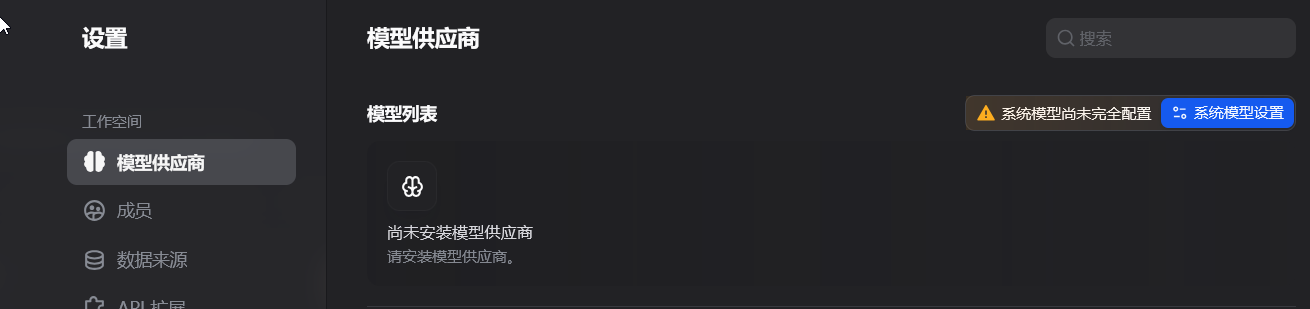
安装本地对应的插件,如ollama,然后按照教程添加模型。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号