动作分类和检测数据集 (Dataset for Action Classification and Detection)
Weizmann Dataset
摘自 2016-Review of Action Recognition and Detection Methods 【这篇综述里有较全面的数据集介绍】
The Weizman dataset was recorded by static camera with clean background.



CMU Crowded Videos Dataset
摘自 2016-Review of Action Recognition and Detection Methods
The CMU Crowded Videos Dataset was recorded by static camera with background motion.


Breakfast Dataset
The breakfast video dataset consists of 10 cooking activities performed by 52 different actors in multiple kitchen locations Cooking activities included the preparation of coffee, orange juice , chocolate milk, tea, a bowl of cereals, fried eggs, pancakes, a fruit salad, a sandwich and scrambled eggs. All videos were manually labeled based on 48 different action units with 11,267 samples.
PKUMMD
PKU-MMD is a large-scale dataset focusing on long continuous sequences action detection and multi-modality action analysis. The dataset is captured via the Kinect v2 sensor. There are 364x3(view) long action sequences, each of which lasts about 3∼4 minutes (recording ratio set to 30FPS) and contains approximately 20 action instances. The total scale of the dataset is 5,312,580 frames of 3,000 minutes with 21,545 temporally localized actions.
可视化链接:PKU-MMD骨架数据可视化程序,动态图,python
something-something Dataset
The 20BN-SOMETHING-SOMETHING dataset is a large collection of densely-labeled video clips that show humans performing pre-defined basic actions with everyday objects. The dataset was created by a large number of crowd workers. It allows machine learning models to develop fine-grained understanding of basic actions that occur in the physical world.
Kinetics 400
DeepMind做的一个数据集。
The dataset contains 400 human action classes, with at least 400 video clips for each action. Each clip lasts around 10s and is taken from a different YouTube video. The actions are human focussed and cover a broad range of classes including human-object interactions such as playing instruments, as well as human-human interactions such as shaking hands.
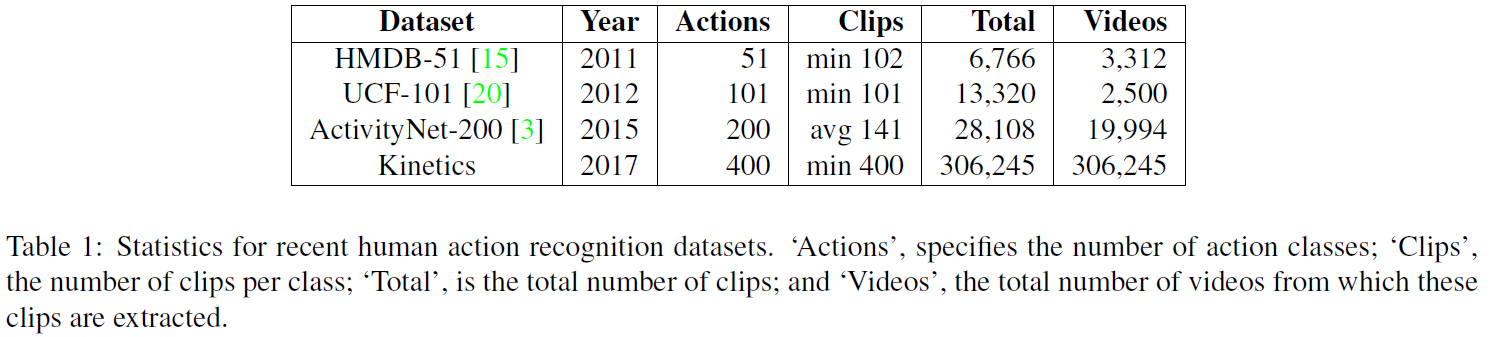
UCF101


UCF101-24



关于UCF101-24更多的介绍,可参考:时空行为检测数据集 JHMDB & UCF101_24 详解
UCF101-24数据集下载链接:MOC_dataset - Google 云端硬盘
UCF-Sports
官网链接:https://www.crcv.ucf.edu/data/UCF_Sports_Action.php
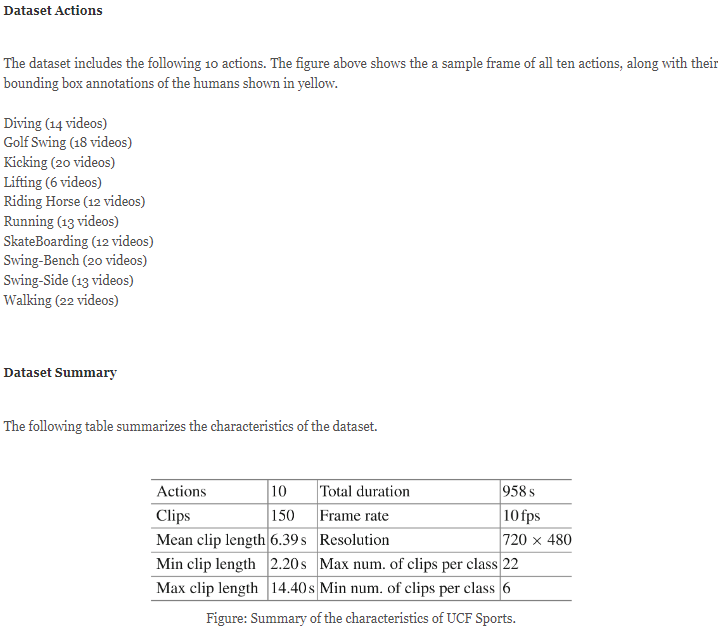

(截图摘自 2016-Multi-region two-stream R-CNN for action detection - ECCV)
MultiSports

(上一截图来自2022-Spatio-Temporal Action Detection Under Large Motion-Arxiv)

HDMB-51
- General facial actions smile, laugh, chew, talk.
- Facial actions with object manipulation: smoke, eat, drink.
- General body movements: cartwheel, clap hands, climb, climb stairs, dive, fall on the floor, backhand flip, handstand, jump, pull up, push up, run, sit down, sit up, somersault, stand up, turn, walk, wave.
- Body movements with object interaction: brush hair, catch, draw sword, dribble, golf, hit something, kick ball, pick, pour, push something, ride bike, ride horse, shoot ball, shoot bow, shoot gun, swing baseball bat, sword exercise, throw.
- Body movements for human interaction: fencing, hug, kick someone, kiss, punch, shake hands, sword fight.

J-HDMB




SBU Kinect Interaction dataset
The SBU Kinect Interaction dataset is a Kinect captured human activity recognition dataset depicting two person interaction. It contains 282 skeleton sequences and 6822 frames of 8 classes. There are 15 joints for each skeleton.

NTU RGB+D
"NTU RGB+D" contains 60 action classes and 56,880 video samples.
"NTU RGB+D 120" extends "NTU RGB+D" by adding another 60 classes and another 57,600 video samples, i.e., "NTU RGB+D 120" has 120 classes and 114,480 samples in total.
These two datasets both contain RGB videos, depth map sequences, 3D skeletal data, and infrared (IR) videos for each sample. Each dataset is captured by three Kinect V2 cameras concurrently.
The resolutions of RGB videos are 1920x1080, depth maps and IR videos are all in 512x424, and 3D skeletal data contains the 3D coordinates of 25 body joints at each frame.
可视化程序:NTU RGB+D数据集,骨架数据可视化

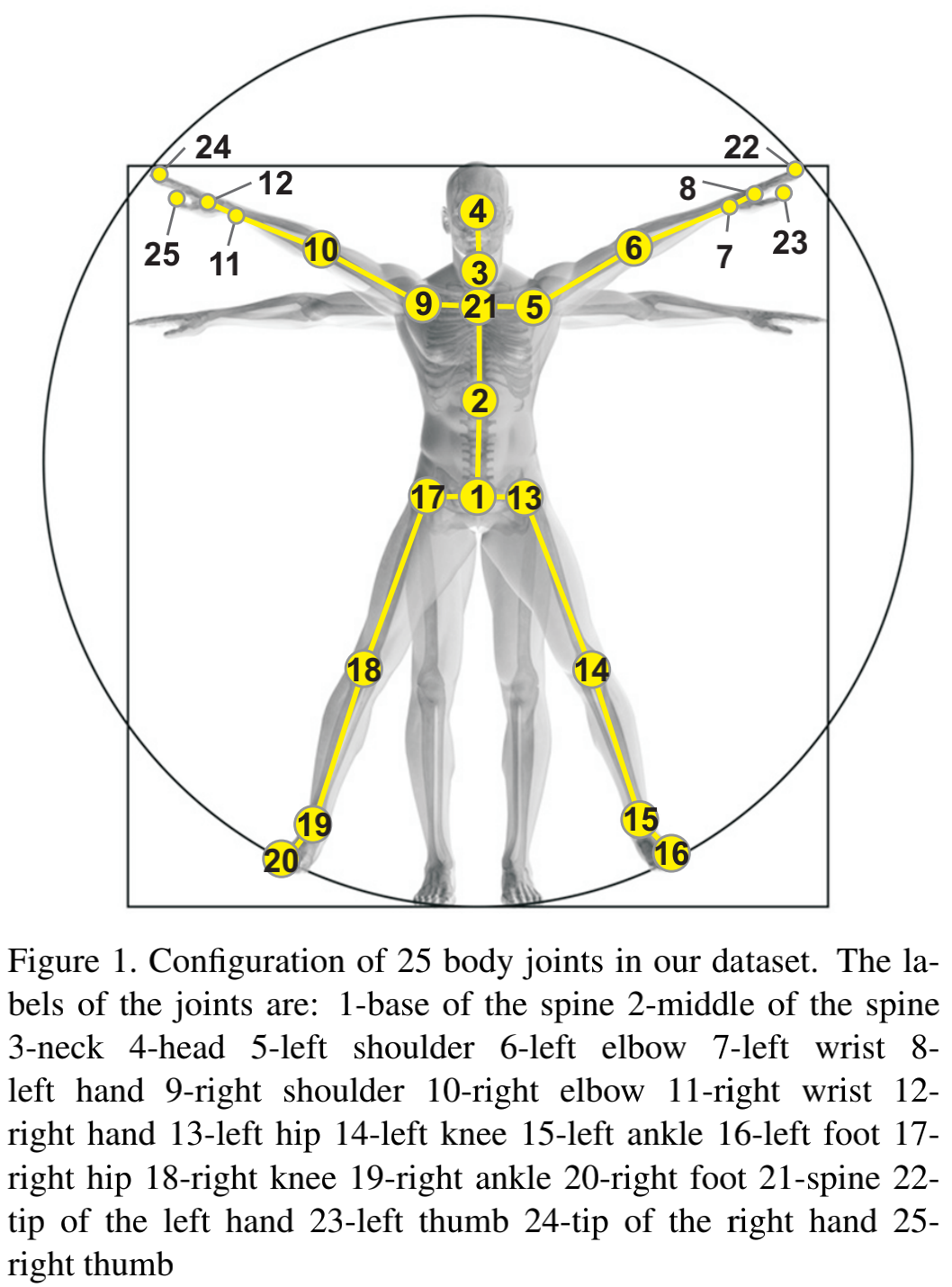
CMU Mocap
N-UCLA



2017PR-Enhanced skeleton visualization for view invariant human action recognition:


UWA3D
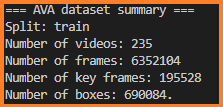
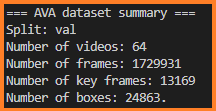
AVA
430 15-minute video clips
1.58M action labels with multiple labels per person
视频来源:The raw video content of the AVA dataset comes from YouTube. 取每个视频的第15分钟~第30分钟。Each 15-min clip is then partitioned into 897 overlapping 3s movie segments with a stride of 1 second.
标注方法:We use short segments (+-1.5 seconds centered on a keyframe) to provide temporal context for labeling the actions in the middle frame. 注意这些segments是有overlap的,stride为1秒。
在AVA数据集里,The corresponding labels are provided for one frame per second.



AVA v2.2 在两个方面与 v2.1 不同。首先人工加入缺失的标签,将注释数量增加了 2.5%。其次,对宽高比远大于 16:9 的少量视频进行了框位置校正。
AVA v2.1 与 v2.0 的不同之处仅在于删除了少量被确定为重复的电影。类列表和标签映射与 v1.0 保持不变。
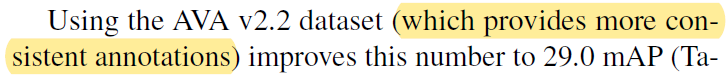




 浙公网安备 33010602011771号
浙公网安备 33010602011771号