【Unity游戏开发】马三的游戏性能优化自留地
一、简介
很久没有更新博客了,最近马三比较忙,一直在处理游戏中优化相关的事务。我们的游戏自从开发以来一直没有做过比较系统的性能优化,最近因为各种原因需要对游戏进行优化,其他同事都有开发任务,因此性能优化的任务就落在了马三身上,说实话马三在性能优化方面也没有太多的经验,都是不断地咨询前辈并且结合网上的资料摸着石头过河。本篇博客中马三就和大家分享一些优化过程中的心得体会,顺便记录一下方便自己日后查阅。
二、优化
1.闪退问题排查
这次优化是因为手机频繁地闪退引起的,我们测试机用的是 iPhone11 Pro 和 iPhone11 Pro Max (博主写下这篇博客的时间是2020年),此时这两款手机可以说是市面上性能最强劲的两款手机了,但是我们的游戏最近跑在上面却频繁地闪退。虽然马三比较有先见之明地接入了Bugly SDK,并且在Bugly控制台上也捕获到了闪退信息,而且进行了符号表解析,但是Bugly上仅仅有下面这张图这样一个简单的堆栈信息,并不能看出具体是因为什么引起的闪退。

此时就需要进行iOS真机调试了,当马三准备真机调试的时候才发现我们打包机的XCode版本是10.x,而我们的测试机的版本是iOS13.4.1,XCode版本太低并不能直接调试。马三按照网上的教程去下载了真机调试包,然后放在指定目录下。但是并没有什么作用,又试了网上各路大神提供的各种奇巧淫技,最后都没能奏效。后来只能老老实实地对XCode进行了升级操作,在升级XCode之前还需要把Mac系统升级到最新,真是蛋疼。不过最后全部升级完以后,去尝试连接真机,果然一瞬间就连上了。此时我突然想起了前辈说过的一句话“没事千万别跟软件较劲”,的确软件该升级就升级,别跟软件较劲,吃力不讨好。
在升级完MacOS系统和XCode软件版本,并且能够连接上真机以后,马三满心期待地点下了Build for running的按钮,并且自信地以为马上就可以看到分析器信息了。但是现实又给了马三残酷的一击,XCode报了一个can not launch的警告信息。马三又是去网上一通查找,把那些方法都试了一遍,还是没有解决问题。后来我怀疑是苹果证书的问题,我们是企业证书,我一度怀疑企业证书打的包不能进行真机调试。后来请教了快手的iOS开发前同事以后,得知了企业证书也可以真机调试,我们这个企业证书不能真机调试的原因很可能是这个企业证书是发布证书,不是Development证书,因此打出的包无法进行调试。时值周六,IT部门并没有上班,因此想去弄一个开发版的企业证书也不现实。后来马三忽然想起苹果现在可以免费申请iOS开发者账户了,于是乎赶紧去申请了一个,然后顺利的打出了包并且进行了真机调试,打开instrument一分析,最后定位到闪退是limit memory of 2GB上面,也就是应用程序占得内存太多了,导致被系统杀死了。
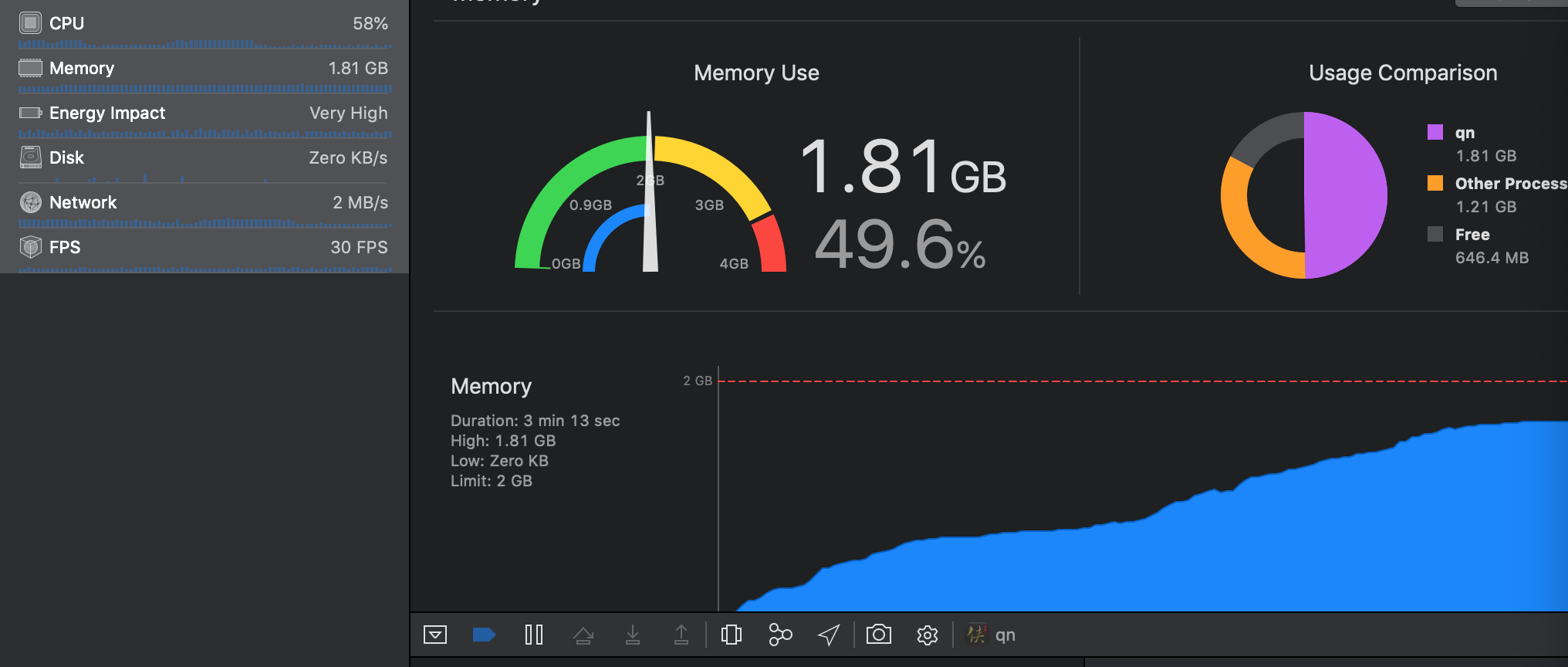
【2021.1.14后记】时隔几个月以后,我们的游戏又出现了闪退的情况,特别是进入某一章关卡战斗的时候必然闪退。连接上instrument分析了一下实时的内存,果然发现了问题,还是出现在内存爆表上。经过一段时间的游戏以后,来到了准备进入战斗前的那个关卡选择UI界面,此时iOS App实时占用内存为1.2G左右,然后进入这个闪退的关卡发现其一下就吞掉了将近900MB的内存,导致内存暴涨,超过了2GB的限制,因此iOS系统直接把游戏应用杀死了。按理来讲这个场景的制作是完全不合理的,不应该占用这么多的内存,经过对场景的进一步检查,发现其中模型用的面数极高,一个简简单单的布景小物件就用了2K的面数,非常浪费。但是此时已经接近版本提交,再重新制作加烘焙这个有问题的场景也不太现实,因此只能采用其他办法了。我们的游戏原来会在场景加载完成以后调用一下System.GC.Collect()和Resources.UnloadUnusedAssets()来释放无用的内存,但是这个时机可能在这种条件下有点晚了,因为有问题的场景会直接撑爆内存。改造方法就是在卸载完上一个场景以后多加一次这两个方法的调用,先清理一步内存占用,腾出一部分的内存空间来,将内存占用先降下来,然后再去加载这个有问题的场景,然后再调用一次释放内存和回收垃圾的操作,此时内存占用就能保证在警戒线以内的了,这也是一个临时救命的trick方法,归根结底,还是要从日常的美术制作标准上做出严格的检查和限制,避免提交不合规的资源进来。
2.ShaderLab内存占用量优化
知道闪退是什么原因导致的,就知道了去向着什么方向进行优化了,内存占用高就去降低内存峰值就好了,连接上了Profiler后,马三一看,好家伙,ShaderLab占用了630MB的内存,按理来说Unity游戏中ShaderLab的内存占用量在40MB上下才是比较合理的,我们这个直接顶到了630MB,不崩溃才怪了。ShaderLab的占用量一般和Shader变体数量有关系,变体数量多的话,编译Shader就需要更长的时间并且占用更多的内存。但是咨询过TA以后,说我们游戏还是DEMO期,并没有使用到很多的Shader,但是为什么分析器中还显示占用了这么多内存呢?马三决定写个Shader变体数量收集统计小工具,批量查询一下游戏中的Shader的变体数量,康康到底的是怎么回事。工具的原理很简单,就是收集项目中所有的Shader文件,然后依次对他们执行通过反射拿到的UnityEditor.ShaderUtil.GetVariantCount方法,获取到变体数量,然后输出到csv文件就好了,csv文件可以用Excel工具打开,可以利用Excel按照变体数量进行排序,然后从高到低逐个优化。
[MenuItem("Tools/AAAAAAAAAAAA")] public static void GetAllShaderVariantCount() { Assembly asm = Assembly.LoadFile(@"D:\Unity\Unity2018.4.7f1\Editor\Data\Managed\UnityEditor.dll"); System.Type t2 = asm.GetType("UnityEditor.ShaderUtil"); MethodInfo method = t2.GetMethod("GetVariantCount", BindingFlags.Static | BindingFlags.Public | BindingFlags.NonPublic); var shaderList = AssetDatabase.FindAssets("t:Shader"); var output = System.Environment.GetFolderPath(System.Environment.SpecialFolder.DesktopDirectory); string pathF = string.Format("{0}/ShaderVariantCount.csv", output); FileStream fs = new FileStream(pathF, FileMode.Create, FileAccess.Write); StreamWriter sw = new StreamWriter(fs, Encoding.UTF8); EditorUtility.DisplayProgressBar("Shader统计文件", "正在写入统计文件中...", 0f); int ix = 0; sw.WriteLine("ShaderFile, VariantCount"); foreach(var i in shaderList) { EditorUtility.DisplayProgressBar("Shader统计文件", "正在写入统计文件中...", ix/shaderList.Length); var path = AssetDatabase.GUIDToAssetPath(i); Shader s = AssetDatabase.LoadAssetAtPath(path, typeof(Shader)) as Shader; var variantCount = method.Invoke(null, new System.Object[] { s, true}); sw.WriteLine(path + "," + variantCount.ToString()); ++ix; } EditorUtility.ClearProgressBar(); sw.Close(); fs.Close(); }
通过上面的工具一查,好家伙,有一个Shader竟然有18.4K个变体,这个数量真是惊人。再次与TA进行沟通了以后,发现这个Shader里面有相当一部分的关键字并没有用到,都是以前遗留下来的,能用到的KeyWord就5个左右。众所周知,Shader的变体数量和关键字数目有关,一般来说一个Shader中的关键字每增加一个,该Shader的变体数量就会x2,是成几何裂变的方式去增加的,着实恐怖啊!赶紧让TA把没用的关键字去掉了,然后再次打包进行观察,发现ShaderLab的占用量一下降低到峰值为260多MB了,是小了不少,但是这个占用量依然不合理,还是太多了。但是此时再次通过上面的工具去排查变体数量,却发现并没有变体数量特别多的Shader了,这时该如何下手呢?幸好 夜莺 大佬给了我一个指点,ShaderControl这个插件可以查看Shader的变体数量,冗余关键字、查看哪些材质引用了这个Shader的哪些关键字。
用ShaderControl插件一看,发现实际打进包中的Shader变体数量和在Editor下预览的还是不一样的,实际打进包中的变体数量要多于Editor下预览的,并且发现了有很多隐藏的关键字,这些关键字其实根本没有显式的引用,但是却在打包的时候出现了,并且增加了Shader变体数量。后来经过请教之前的快手TA前辈,才发现原来Unity关键字有个坑:
材质球里会记录之前使用的关键字,打个比方 :“A Shader 使用的关键字 _WOYAOKAIFEIJI ,B Shader使用率关键字 _WOYEYAOKAIFEIJI ,材质球C 开始使用了Ashader ,那么会把_WOYAOKAIFEIJI这个关键字记录在材质球,由于某个原因这个材质球不想使用Ashader了,这是切换到B Shader ,那么这个材质球就会包含_WOYAOKAIFEIJI、_WOYEYAOKAIFEIJI这两个关键字”。
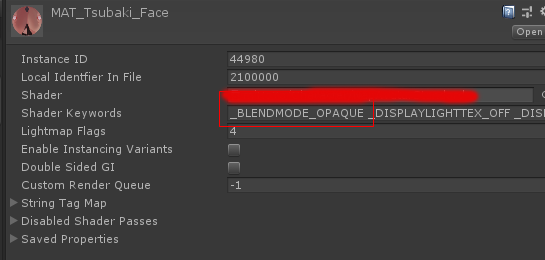
比如下图中的这个关键字,完全没有材质在显式地使用它,但是就可以搜出来有用了这个关键字的材质。然后打开对应材质球的debug面板,可以发现shader keywords这一栏记录了以前的残留。

后来又跟TA优化了一些没用的关键字,并且通过ShaderControl的Clear All Material功能,批量清除了材质球中残留的关键字。之后再一打包测试,发现ShaderLab的内存占用量降到了62MB左右,这次应用再也不会因为内存暴涨的问题闪退了。折腾了近一周的时间,终于把ShaderLab的内存占用量从630MB降到了62MB左右。
经过这次粗犷地优化以后,我们的游戏竟然可以运行在iPhone6s上了,在战斗场景还能流畅地跑到30帧左右,主程连续说了三次不错不错,牛逼啊之类的词汇来表达心里的激动之情。
【2020.11.14后记】时隔4个月之后,在性能测试的过程中马三发现ShaderLab的内存占用又有抬头的趋势,UI界面的Shader占用就有107MB之多,战斗场景的ShaderLab占用竟然又上涨到了150MB,这样会导致GFX的内存压力非常大。“故技重施”之后发现,UberPost和Uber这两个Shader的变体数量太多了,分别是6400和3400个变体。经过与TA确认以后,移除了UberPost中很多没用到的 multi_compile 关键字,变体数量一下缩减到了128个。而Uber这个Shader是PostProcessing这个插件中的,跟TA确认这个插件并不在使用了,但是由于同事的失误,又把这个插件给加回来了,所以直接把这个插件移除掉了,这样3400变体的那个Shader也就没了。经过这样一番的优化以后,效果还是比较明显的:
- 登录界面 107.1MB -> 1.9MB
- 角色界面 110.3MB -> 3.5MB
- 战斗场景 150MB左右-> 15.6MB
【2020.12.23日再后记】仅仅时隔一个月,我们的游戏又被发现频繁闪退,马三监测了一下ShaderLab的内存占用,发现又涨到了250MB,这还仅仅是在UI界面上。战斗场景的ShaderLab内存占用更是有270MB之多。之前明明才优化过ShaderLab的内存占用量的,怎么又上来了呢?经过与TA和引擎同学的沟通得知:我们现在启用了ShaderVariantCollector变体收集器,会在打包的时候把对应平台用到的Shader变体打进包里面,用不到的变体是不进包的。按道理来讲,这样内存占用量应该下降才对啊,为什么又上升了这么多呢?经过进一步的排查发现,无意中又使用了Standard的Shader,这种Shader很耗。最关键的一点是,我们写的很多Shader都是用了multi_compile关键字而不是shader_feature关键字。shader_feature特性在打包时自动剥离,multi_compile特性在打包时不剥离,全量编译。因此尽管有了变体收集器,但是关键字都是multi_compile的,相当于全量编译了,没起到作用。然后在这期间TA又加了很多关键字,导致变体达到了4000 x 2的数量,ShaderLab的内存飙升也就在情理之中了。找到原因以后,先移除了Standard的Shader,再对变体最多、使用了大量multi_compile关键字的Shader初步进行了优化,暂时把ShaderLab的内存占用降到了50MB左右,先保证游戏不闪退,后续有时间再逐个地优化一下。
ShaderLab的内存占用果然是我们项目的老大难问题啊!

3.UI界面的ShaderLab占用竟然比战斗场景内的高
出于提升界面的效果的目的,我们的UI界面上也开了后效处理。与战斗内的后效处理相比,UI界面上的后效处理较为简单,并且没有用到像战斗内那么多的Shader。所以期望的结果是UI场景中的ShaderLab内存是小于战斗内的ShaderLab内存的,但是我在通过Profiler进行分析的时候,却发现恰恰相反,UI界面占用的ShaderLab内存竟然比战斗内的占用还要高。
后来经过进一步的排查发现,UI界面上有个隐藏的Chessboard节点,他上面挂载了一个战斗内的人物角色,这个人物的Avatar使用了很多战斗内的Shader,用到了这些Shader就需要编译,就需要占用内存。并且这个界面上用了非常多的Standard Shader,这个也是非常耗的。因此UI场景占用的ShaderLab实际上就为 UIShader+战斗内Shader > 战斗内Shader。所以就出现了UI界面占用的ShaderLab内存竟然比战斗内的占用还要高的奇怪现象。经过与制作这个UI的程序沟通,确认这个节点是很久之前测试用的,忘记删除了,把它移除掉以后,UI场景的Shader占用就正常了,大概才3MB左右。因此很有必要在实际的项目中制定标准的UIPrefab制作规范和相应的检查工具,从而避免类似的事情再次发生。
4.Odin插件的优化
我们游戏中的很多配置都是通过Odin的SerializedScriptableObject实现的,借助于Odin的可视化界面和强大的序列化、反序列化库,配置游戏的数据非常方便。而且这些数据可以所见即所得,可以在运行的状态下直接修改并且马上就看到效果。但是随着配置规模和数据量变大以后,策划发现每次在改动一些很小的参数的时候都要卡顿半天,非常影响工作效率。后来我开了Profiler的Deep模式对Editor进行了分析,得到了下面的这张图:
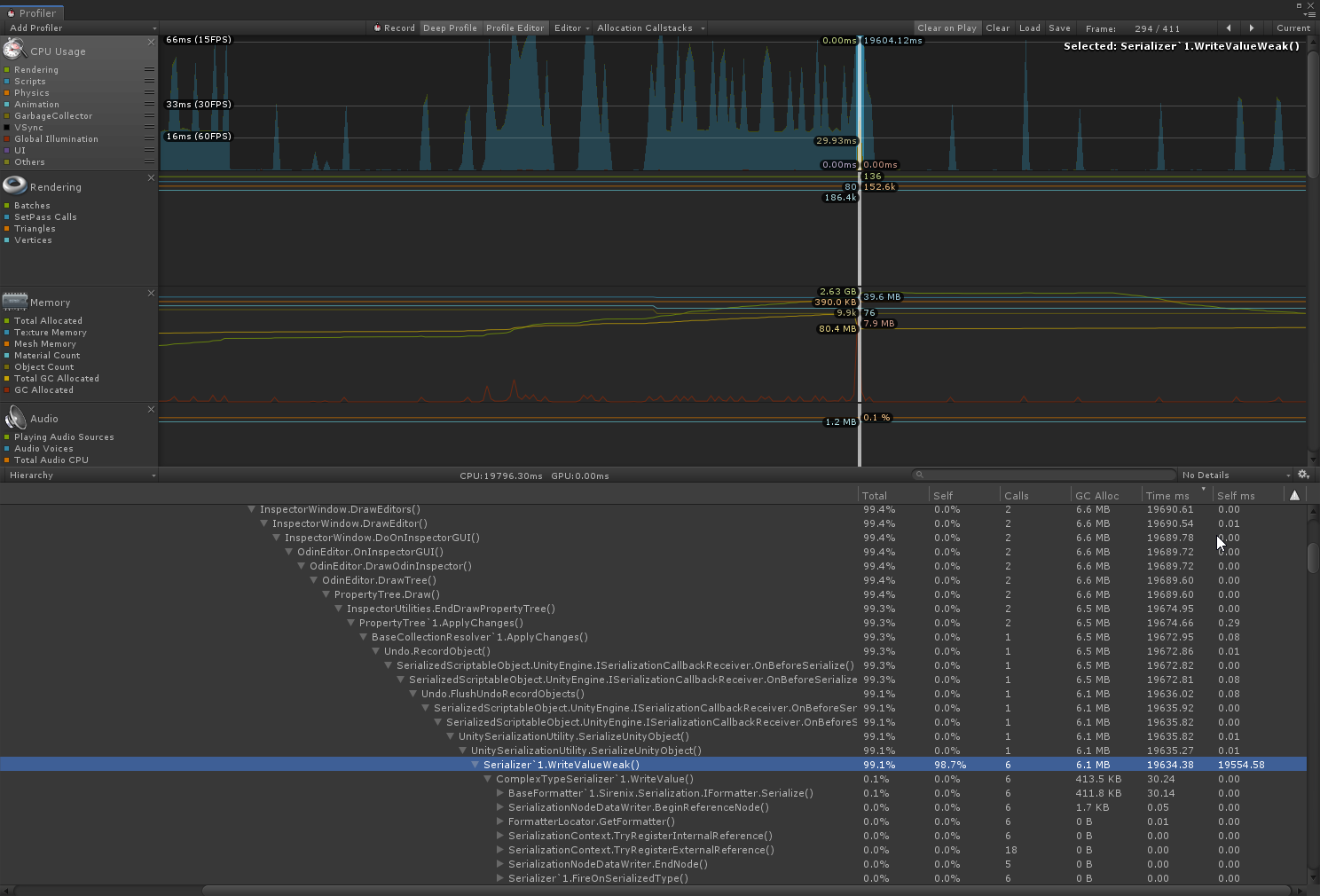
可以看到主要的耗时都发生在了序列化写入这一步,产生了很高的GC,并且这一帧的self time也非常高。再结合Odin的源码进行分析,发现最终的原因就是:“每次在Odin Inspector中修改序列化数据的时候,都会触发ProertyTree重绘,这个重绘里面有个Record UnDo的机制需要保存现场。然后就会触发序列化的行为 会引起很大的GC和耗时。”
又通过不断地翻看Odin论坛的Issue,我发现有人跟我遇到了一样的问题,并且作者亲自下场给出了答复,截图在下面:

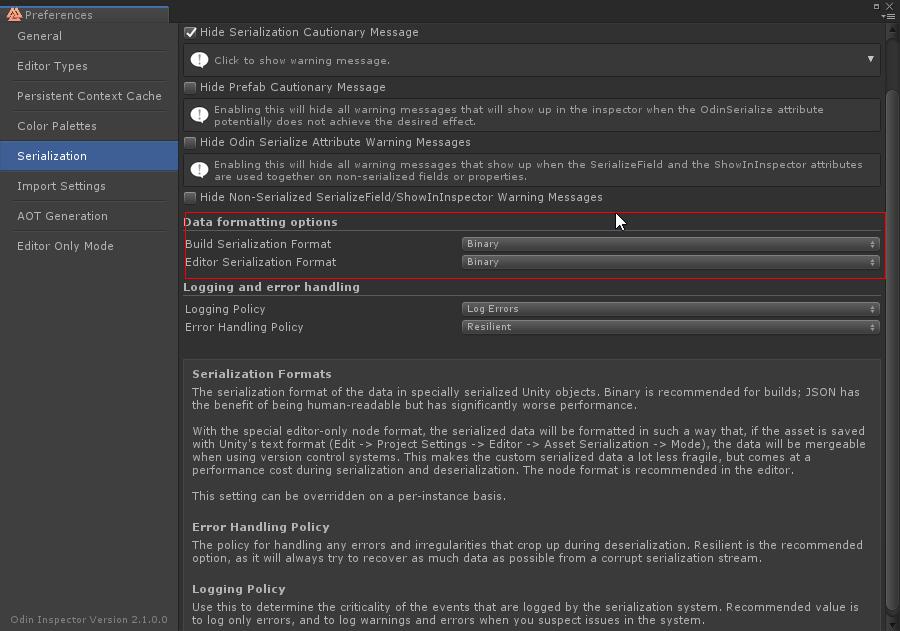
最后的解决办法很简单,在Odin的Perferences配置面板中将Data formatting options的序列化格式都改成bin就不卡了,如下图所示。当Odin的序列化文件以Node的方式保存的时候,这个GC和耗时就很明显,所以就会卡顿。将Odin的序列化文件改为bin就快了,因为二进制的序列化和反序列化是非常快的。Node这种方式,我盲猜会用递归的方式去处理嵌套的每一个节点,所以GC和耗时比较高。
5.Json解析的优化
除了上面所说的Odin的SerializedScriptableObject配置外,我们游戏中还有许多Json格式的配置文件。经过Profiler分析,在批量解析这些Json文件的时候也会产生内存和CPU的峰值,撑大Mono的堆内存。经过进一步的分析,发现是SimpleJson这个插件造成的,我们用的是老版的SimpleJson插件,里面在解析的时候用了很多字符串拼接的操作,众所周知string是不可变的,每次拼接实际上都是产生了一个新字符串出来。解析Json的时候会涉及到大量的字符串拼接,因此GC和CPU峰值也就来了。这个解决办法很简单,我在Github上查看了最新版的SimpleJson插件,其中解析Json部分已经替换成了使用StringBuilder去实现,测试了一下果然效果比之前好了很多,只要把新版和旧版的API接口做一下调整和兼容就可以了,对外接口不变,内部给它翻新一下即可。
6.内存泄漏问题
(1)正常情况下游戏如果一直玩下去,Mono是不是会一直增加? 比如频繁打开一个界面,界面里有脚本会不断创建一些东西 ,那么Mono是否会不断增加?对性能上会不会造成影响呢?
在除开启IL2CPP功能的应用中,Mono 确实是不会下降,但并不应该一直上升。 创建出来的东西,如果被引用在一个容器里,或者被某些脚本的变量引用,那么这部分堆内存就释放不掉;但如果没有被任何容器或者变量引用(比如,临时拼一个 String),那么这部分堆内存会在 GC 的时候释放(释放是指变为空闲的堆内存,堆内存的总量是不会下降的)。 对于后者,频繁地 new 对象虽然不会一直增加堆内存,但是会加速 GC 调用的频率,所以同样是需要尽量避免的。
(2)如果脚本引用了GameObject,那转换场景的时候脚本和GameObject都没了,还会产生堆内存的吗?
如果脚本是MonoBehaviour,而且在切换场景后所挂的Game Object被释放了,那么这个脚本对象所引用的堆内存就会在GC的时候被释放。 但有一种例外,如果是通过Static变量引用的堆内存,那么依然是释放不掉的,除非手动解开引用,比如变量置Null,数组Clear等等。
(3)另外Unity还有一个老生常谈的IsNull问题
在名为A的MonoBehaviour中,有个数组来存放名为B的 MonoBehaviour对象的引用。当我们其他的逻辑去Destroy了B对象所在的GameObject后,在A对象中的数组里,遍历打印,它们(B的引用)都为Null,在Inspector面板上看是missing。而这时候进行GC,堆内存其实并未释放这些B对象。只有当A对象中的数组被清空后,再调用GC,才可释放这些对象所占内存。这种现象是否正常?为什么值为Null但却还是被引用着,无法通过GC释放呢?
首先这种现象是正常的。这是Unity中对Null的检测做了特殊的处理所致,在Unity中MonoBehaviour对象除了存在于Managed Heap中(作为“壳”),在Native内存中还会有一个相对应的“实体”,在调用Destroy时,真正被释放的正是这个“实体”。而在判断一个MonoBehaviour对象是否为Null时,Unity会首先检测“实体”是否已经被销毁,如果是则返回为true,但此时Managed Heap中的“壳”实际上依然是被引用的,从而就会出现对象的Null判断为true,但实际上还是被引用着,无法被GC释放的问题。 相关的细节可见官方blog对Unity中Null判断的解释:http://blogs.unity3d.com/2014/05/16/custom-operator-should-we-keep-it/
如果是Unity.GameObject类型的,查看其是否等于null,如果作为Unity.GameObject对象是null,而作为System.Object对象不是null,说明这个对象已经被Unity标记为销毁了,Unity.GameObject重载的==运算符让游戏逻辑认为它是空的。
7.游戏画面卡死
最近一段时间,我们的游戏经常在真机上卡死,原本以为是只有iOS系统上出现,但是后来打出Android包,发现在Android系统上也会出现游戏运行一段时间以后就卡死的状况,非常严重的是就算什么都不做只要进了战斗在原地待机2-3分钟都会卡死。通过Xcode的instrument工具分析出来的是卡死以后主线程和渲染线程都处于休眠的状态,cpu利用率直接从80%多降到了15%,这显然是不正常的,并且排除掉进入了逻辑上的死循环的可能性。后来通过Profiler终于抓取到了一帧,发现这一帧竟然有10多s之久,然后发现是Gfx.WaitForRenderThread耗时非常多,再进一步展开发现有个semaphore.WaitForSignal花了非常多的cpu时间。这个消耗比较好理解,我们项目开启了多线程渲染,cpu和gpu会有一个同步的过程,当cpu负荷压力比较大的时候,gpu会去等待cpu;而当gpu负荷大的时候,cpu会去等待gpu完成渲染工作。分析一下我们的项目cpu压力没有这么严重,肯定是gpu那边的负荷比较大。后来经过排查发现有个urp的渲染过程,在Update中不断地new Material,一帧就可能创建几百个材质出来,在运行一段时间以后材质数量非常的多。经过测试正常情况下材质数量应该是几百个,而这个bug会导致材质数量暴增到几十万甚至上百万个,内存也会从几mb暴涨到200多mb,造成了严重的内存泄漏,对gpu和cpu的压力都很大。当把这个bug修复以后,画面卡死的情况也就解决了,到现在也没有再出现过。

当游戏画面出现卡死的时候,首先要考虑是不是哪里造成了死循环,然后再考虑分析是cpu的载荷太大了还是gpu的载荷太大了,然后再进一步地进行探测有可能出现问题的点,直到修复为止。借助Profiler和instrument、RenderDoc这类的工具可以更快地帮我们定位问题。
8.游戏运行卡顿、掉帧严重
在优化完上面的游戏画面卡死问题以后,我又发现游戏运行非常的卡顿,掉帧严重,战斗的时候只能跑到20多帧,而我们的目标帧率是60帧。而且代码这边已经优化过了,很少有循环gc alloc或者一帧耗时非常久的函数了。经过Profiler真机分析发现,cpu时间都被渲染工作占用了,每个几帧就有一个非常高的gpu耗时尖刺,看来还是渲染压力太大了。经过排查发现iOS上开启了MSAA抗锯齿,并且采样率值为4,这样是非常消耗的。当把MSAA的采样率调整到2或者直接Disabled以后,游戏轻松就跑到了60帧。看来优化100行代码也不如渲染优化一点点啊。当游戏出现卡顿的时候,首先分析出是代码还是渲染耗时了,然后选择问题比较严重的部分首先去优化,往往可以得到非常显著的效果。也就是分清主次,优化性能首先要找出性能瓶颈,对性能影响最大的地方先优化,接着对次影响的进行优化,以此类推。首先找出性能瓶颈,优化效果最明显。
9.内存优化理论
1.内存压缩,内存移动;内存有压缩比无压缩的管理要好(iOS就比android要好),内存压缩涉及内存移动;内存移动时,时间越短越好,移动数量越少越好。
2.内存复制:一块内存被复制到另一块内存上面,并且之前内存已不用,需要gc,这中间既浪费内存又产生gc。(2倍扩容数组,字符串拼接。数据大量时,需要指定扩容上限与扩容增长模型,或者指定动态增长模型)
3.静态内存,动态内存。静态内存不移动,内存地址稳定,读取消耗少,静态内存最好要应用开启时直接开辟静态内存空间,不被gc和扰动。动态内存灵活性高,随时随地切换,生命周期短,触发gc次数多,瞬时计算肯定是动态内存的读取比较多。可以指定静态内存与动态内存分开,动态内存实行高频gc,静态内存实行低频gc。
三、总结
未完待续...

 浙公网安备 33010602011771号
浙公网安备 33010602011771号