


文章分类 - AI编程实战
本地大模型编程实战(06)从文本中提取重要信息(2)
摘要:本文将演示使用大语言模型从文本中提炼结构化信息。这次我们不直接使用提示词,而是使用大模型的 `few-shot prompting` 特性,即使用很少的例子来引导大模型做推理。
我们将用 `llama3.1` 和 `deepseek` 做一个简单的对比。
> 由于 `langchain` 可能对不同大模型支持程度不同,不同大模型的特点也不同,所以这个对比并不能说明哪个模型更好。
阅读全文
本地大模型编程实战(05)从文本中提取重要信息(1)
摘要:本文将演示使用大语言模型从文本中提炼结构化信息。
我们将用 `llama3.1` 和 `deepseek` 做一个简单的对比。
> 由于 `langchain` 可能对不同大模型支持程度不同,不同大模型的特点也不同,所以这个对比并不能说明哪个模型更好。
阅读全文
本地大模型编程实战(04)给文本自动打标签
摘要:使用本地大模型可以根据需要给文本打标签,本文介绍了如何基于 `langchain` 和本地部署的大模型给文本打标签。
> 本文使用 `llama3.1` 作为本地大模型,它的性能比非开源大模型要查一下,不过在我们可以调整提示词后,它也基本能达到要求。
阅读全文
本地大模型编程实战(03)语义检索(2)
摘要: 本文描述了如何使用 `Chroma` 对csv数据进行矢量化,并且将矢量存储在硬盘中,未来查询矢量数据时,直接从硬盘中读取矢量数据进行查询。
另外,如果数据量大一些,矢量化数据是很花时间的,我们将使用进度条显示嵌入csv的进度。
阅读全文
本文描述了如何使用 `Chroma` 对csv数据进行矢量化,并且将矢量存储在硬盘中,未来查询矢量数据时,直接从硬盘中读取矢量数据进行查询。
另外,如果数据量大一些,矢量化数据是很花时间的,我们将使用进度条显示嵌入csv的进度。
阅读全文
本文描述了如何使用 `Chroma` 对csv数据进行矢量化,并且将矢量存储在硬盘中,未来查询矢量数据时,直接从硬盘中读取矢量数据进行查询。
另外,如果数据量大一些,矢量化数据是很花时间的,我们将使用进度条显示嵌入csv的进度。
阅读全文
本地大模型编程实战(02)语义检索(1)
摘要:本文描述了如何使用 `langchain` 和 `大语言模型` 以及 `矢量数据库` 完成pdf内容的语义检索。
在对内容进行矢量化时使用了 `nomic-embed-text`,这个模型个头小,英文嵌入效果不错。
后面还将涉及到以下内容:
- 文档和文档加载器
- 文本分割器
- 嵌入
- 向量存储和检索器
阅读全文
本地大模型编程实战(01)实现翻译功能
摘要:本文描述了如何使用大语言模型(`LLM`)实现基本的翻译功能,此翻译功能的特点是:无需指定源语言,只需要指定目标语言就可以进行翻译了。
阅读全文
基于langchain+本地大模型+本地矢量数据库的RAG系统介绍
摘要: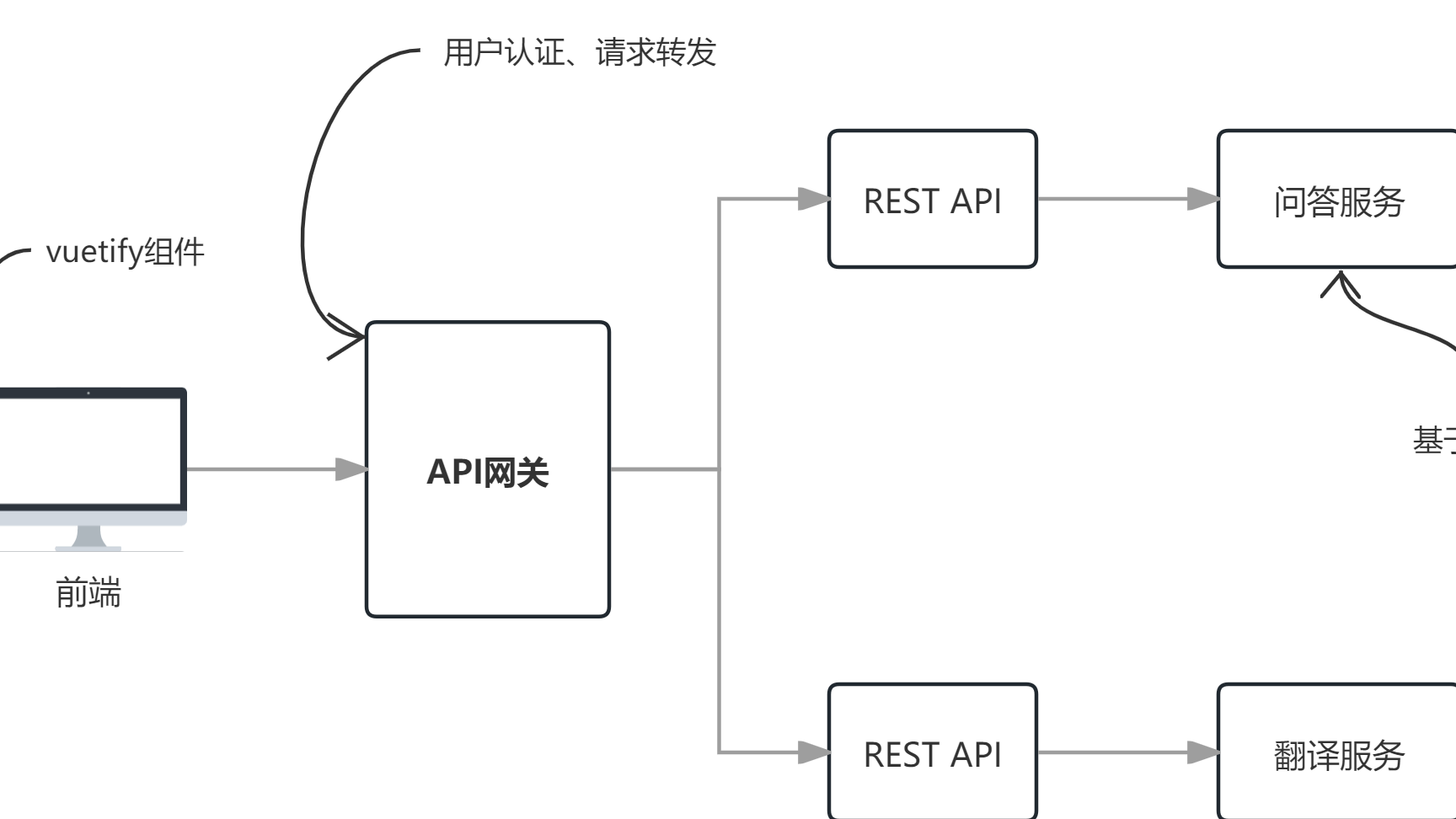 这是一个可以运行完全在本地服务器的`RAG`(`Retrieval Augmented Generation`)系统,它主要包含以下功能:
- 使用本地大语言模型做语言翻译
- 使用本地大语言模型做专业领域的知识问答
阅读全文
这是一个可以运行完全在本地服务器的`RAG`(`Retrieval Augmented Generation`)系统,它主要包含以下功能:
- 使用本地大语言模型做语言翻译
- 使用本地大语言模型做专业领域的知识问答
阅读全文
这是一个可以运行完全在本地服务器的`RAG`(`Retrieval Augmented Generation`)系统,它主要包含以下功能:
- 使用本地大语言模型做语言翻译
- 使用本地大语言模型做专业领域的知识问答
阅读全文
用图形验证码增强用户认证安全性[python+vuetify]
摘要:这里通过代码讲述了使用`python`生成以及校验图片验证码,增强用户认证安全性的过程。
客户端则使用 `vue3` 和 `vuetify3` 框架使用后台API生成的图片验证码。
阅读全文
基于OAuth2.0和JWT规范实现安全易用的用户认证
摘要:遵循`OAuth2.0`和`JWT`规范实现用户认证,不但具有很好的实用性,还能提供很不错的安全保障。 本文结合实用的代码讲述了基于`OAuth2.0`和`JWT`,在前后端分离的系统中,实现用户使用方便而又安全可靠的用户认证的基本思路。 预备知识 OAuth2.0 `OAuth2.0` 是一个关于
阅读全文
使用FastAPI和JWT技术实现OAuth2用户认证
摘要:本文阐述了如何基于FastAPI框架实现OAuth2用户认证,其中使用哈希算法对密码进行了加密,使用JWT持有令牌。 附带完整的代码,避免大家再次踩坑。 关于OAuth2 `OAuth` 是一个关于授权(`authorization`)的开放网络标准,在全世界得到广泛应用。比如:微信登录、Faceb
阅读全文
用FastAPI实现微服务API网关
摘要:本文阐述了基于FastAPI实现一个API网关的详细步骤。这样未来可以不断的在服务端像搭积木一样添加各种服务。
我们即将实现下面的简单的微服务架构,目前它只实现了请求转发功能。
阅读全文
用Flask封装langchain服务为API
摘要:前言 之前使用langserve可以特别轻松的封装langchain服务为API,这些API开放了链的各种能力。 有时候我们实际上只是需要更加简单的接口,并且希望能够更加灵活的对接口进行控制。此时直接使用flask及相关框架可能是更好的解决方案。 概述 本文讲述了如何使用一个利用本地大模型`llam
阅读全文
使用LangServe让本地大模型提供API
摘要:简介 `LangServe` 是一个 `Python` 包,专门用于将基于 `LangChain` 的程序和链部署为生产就绪的 API。 - **易于调试**:它提供了一个 `Playground`,允许开发者实时地与他们的智能机器人互动,测试不同的输入并查看即时输出,这有助于快速迭代和调试。- *
阅读全文
基于langchain和本地大模型以及会话式检索增强生成技术实现知识问答
摘要:简介 本文概述了基于langchian框架和对话式增强生成(`Conversational RAG`(`Retrieval Augmented Generation`))技术实现知识问答。 具体来说,系统自动记录聊天历史,并把它作为上下文提供给大模型,这样它让大模型产生了“记忆”,可以“理解”和关联
阅读全文
基于langchain和本地大模型以及会话式检索增强生成(Conversational RAG)技术实现知识问答
摘要:本文讲述了基于langchian框架,使用本地部署的nomic-embed-text模型做嵌入检索、llama3.1做回答内容生成的知识问答系统实例。
通过对比测试使用历史聊天记录和不使用历史聊天记录(即:以往的问题和答案)两种情况,我们可以明显看出来使用历史聊天记录的优点:它让大模型产生了“记忆”,可以“理解”和关联上下文,体验更好。
阅读全文
基于langchain+本地lamma3.1+本地chroma做RAG增强生成系统
摘要:在实际做RAG(RAG,Retrieval Augmented Generation,即:增强生成)系统时,经常会遇到数据安全、隐私保护等问题,此时使用本地部署的大模型和本地部署的矢量数据库时很必要的。 对一些概念的理解 以下的概念定义不严谨,主要是为了便于理解。实际上这些概念不仅适用于“文本”。
阅读全文
在langchian中集成本地部署的llama3.1大模型
摘要:部署本地大模型llama3.1 Ollama是一个工具和框架,主要用于本地部署和使用大语言模型(Large Language Models, LLMs)。它旨在帮助开发者和组织方便地在本地或私有环境中运行和交互这些模型,避免依赖外部API或云端服务,保护隐私并降低成本。 这些大模型可以利用cpu运行
阅读全文
在VS Code中配置venv
摘要:venv的用途 Python的venv是一个用于创建虚拟环境的模块,主要作用是为每个项目提供一个隔离的 Python 运行环境。这样不同项目的依赖可以相互独立,不会产生冲突。 例如,一个项目可以使用Python 3.8,另一个项目使用Python 3.10,彼此之间不受影响。 相比其他环境管理工具,
阅读全文
 浙公网安备 33010602011771号
浙公网安备 33010602011771号