
部署本地大模型llama3.1
Ollama是一个工具和框架,主要用于本地部署和使用大语言模型(Large Language Models, LLMs)。它旨在帮助开发者和组织方便地在本地或私有环境中运行和交互这些模型,避免依赖外部API或云端服务,保护隐私并降低成本。
这些大模型可以利用cpu运行,只是速度慢。
1. 安装ollama
下载地址:[ollama下载]
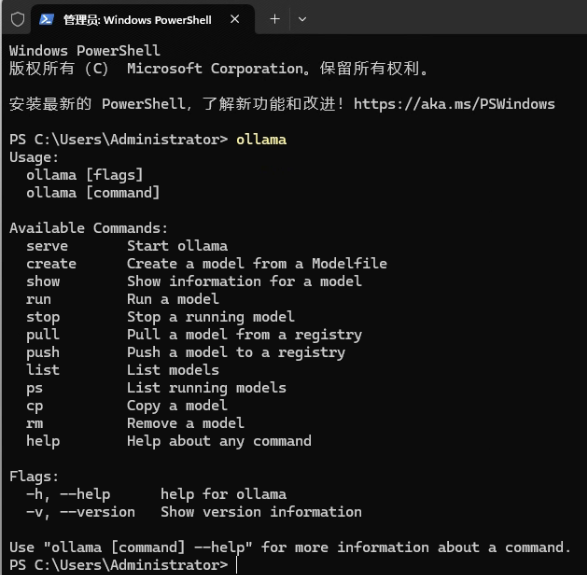
2. 检查是否下载成功
输入命令:
ollama
看到类似下图的提示,代表安装成功:
3. 下载安装llama3
ollama pull llama3.1
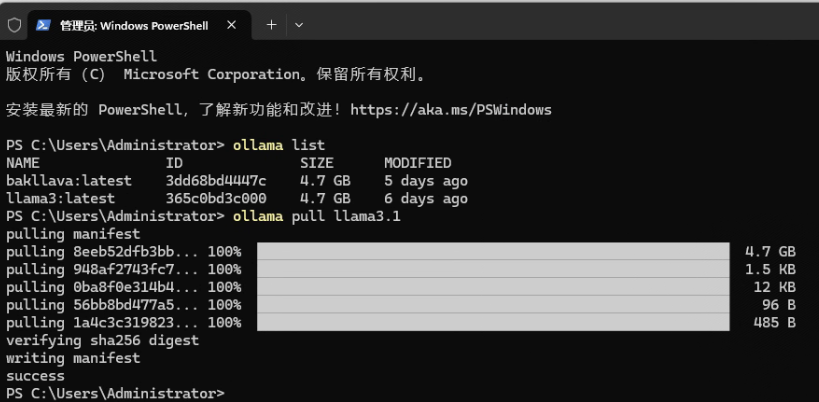
系统自动下载8b(b是billion的意思,8b意味着80亿参数)的模型,根据进度条提示可以看到下载过程:
也可以安装其它版本大模型,例如,使用命令:ollama pull llama3.1:70b 可以安装更大的70b的模型。
ollama中有很多大模型,点击:[浏览ollama模型]可以查找其它大模型。
4. 启动测试大模型
使用命令:
ollama run llama3.1
可以启动大模型,并且可以与大模型聊天,就说明大模型运转正常,如下图:

在langchian中使用本地大模型llama3.1
LangChain是一个开源框架,旨在帮助开发者构建基于大语言模型(LLMs)的应用程序。可以在创建复杂的多步骤任务时,如问答系统、聊天机器人、文档处理和知识库查询等场景使用。
1. 安装依赖环境
pip install langchain pip install -U langchain-ollama
2. 写代码
from langchain_core.prompts import ChatPromptTemplate from langchain_ollama.llms import OllamaLLM # 在调用时替换{question}为实际的提问内容。 template = """Question: {question} Answer: Let's think step by step. 请用简体中文回复。 """ # ChatPromptTemplate是LangChain中的一个模板类,用于定义一个对话提示模板。 prompt = ChatPromptTemplate.from_template(template) # 使用本地部署的lama3.1 model = OllamaLLM(model="llama3.1") # 创建一个简单的链:prompt的输出会传递给model,然后model会根据prompt的输出进行处理 chain = prompt | model # 调用链,传递输入数据并执行链中的所有步骤。 # 该输入中的question键值对被传递到prompt模板中,从而生成完整的对话提示:"Question: Langchain是什么?"。 result = chain.invoke({"question": "Langchain是什么?"}) print(result)
可以在VS Code中执行以上代码:

看看执行结果:

下载源代码
- [gitee]
- [github]
---
## 参考

 浙公网安备 33010602011771号
浙公网安备 33010602011771号