
在实际做RAG(RAG,Retrieval Augmented Generation,即:增强生成)系统时,经常会遇到数据安全、隐私保护等问题,此时使用本地部署的大模型和本地部署的矢量数据库时很必要的。
对一些概念的理解
以下的概念定义不严谨,主要是为了便于理解。实际上这些概念不仅适用于“文本”。
1. 嵌入(embedding)
计算机的强项是计算。在处理文本时,只有把文本转换成“数”以后才能被计算机处理,我们可以认为这个过程就是:嵌入(embedding)。
我们可以用大模型进行这种嵌入:把喂给它的文本转换成“数”。嵌入的过程参见下图:

2. 矢量数据库
在对文本做了“嵌入”以后,文本会被转换成“矢量”。
矢量通常由很多“维度”组成,比如我们常见的笛卡尔坐标:有x轴和y轴,我们可以用(x,y)来表示一个点的位置,这个矢量就是2维的。
“嵌入”的过程实际上也可以称之为“矢量化”,为了能够准确的表示文本的“特征”,通常使用大模型矢量化后的矢量有很多维。

3. RAG(Retrieval Augmented Generation)
由于大模型训练使用的数据通常不是最新的,而且也显然不可能特别全。所以通常在做一些专业领域的系统时,需要借助专业领域的知识库。
有一种有效的方式是:使用矢量数据库把专业的知识存储起来,我们可以叫它“知识库”,在进行专业知识查询时,先在“知识库”种查询关联的知识,然后再巧妙的融入到“提示词”中,喂给大模型,由大模型经过思考后返回“人性化”的答案。
这个过程就是RAG(Retrieval Augmented Generation)。
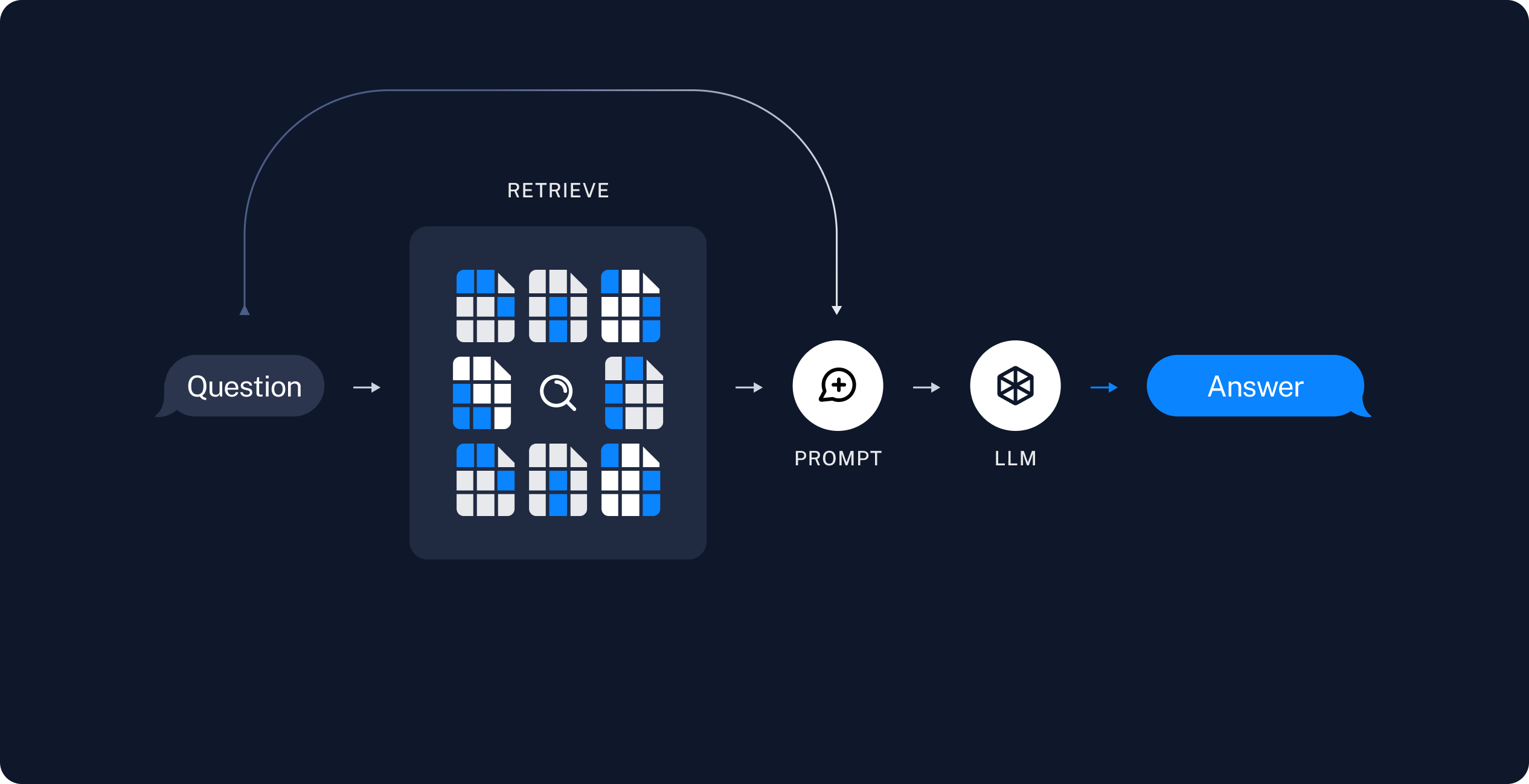
更详细的内容可以参考:[Build a Retrieval Augmented Generation (RAG) App]
使用langchain+本地lamma3.1+本地chroma实现知识问答
1. 安装依赖,在VS Code的terminal/终端中执行。
pip install --upgrade langchain langchain-community langchain-chroma
2. 嵌入和存储
做嵌入和查询时应该使用同一个大模型。如果在做嵌入和执行查询时用不同的大模型,那就不一定能查出什么了:)
from langchain.vectorstores import Chroma from langchain.text_splitter import RecursiveCharacterTextSplitter from langchain.embeddings import OllamaEmbeddings from langchain_ollama.llms import OllamaLLM from langchain.chains import VectorDBQA from langchain.document_loaders import TextLoader persist_directory = 'chroma_langchain_db_test' model_name = "llama3.1" # 定义嵌入。在存储嵌入和查询时都需要用到此嵌入函数。 def get_embedding(): embeddings = OllamaEmbeddings(model=model_name) return embeddings # 对文本矢量化并存储在本地 def create_db(): # 用来加载文本文件。 # 指定文件使用tf-8编码读取,以确保正确处理非ASCII字符。 loader = TextLoader('doc/state_of_the_union.txt',encoding='utf-8') documents = loader.load() # 用于将长文本拆分成较小的段,便于嵌入和大模型处理。 # 每个文本块的最大长度是1000个字符,拆分的文本块之间没有重叠部分。 text_splitter = RecursiveCharacterTextSplitter(chunk_size=1000, chunk_overlap=0) texts = text_splitter.split_documents(documents) # 从文本块生成嵌入,并将嵌入存储在Chroma向量数据库中,同时设置数据库持久化路径。 vectordb = Chroma.from_documents(documents=texts, embedding=get_embedding(),persist_directory=persist_directory) # 将数据库的当前状态写入磁盘,以便在后续重启时加载和使用。 vectordb.persist() create_db()
执行 Chroma.from_documents 开始执行嵌入,这个过程计算量较大,可能比较慢。
嵌入执行完毕后,会在项目文件夹中出现chroma数据库文件:
3. 查询知识
def ask(query): # 创建大模型实例 model = OllamaLLM(model=model_name) # 使用本地矢量数据库创建矢量数据库实例 vectordb = Chroma(persist_directory=persist_directory, embedding_function=get_embedding()) # 处理基于向量数据库的查询回答任务。 # "stuff":意味着模型将所有的上下文一次性处理。 qa = VectorDBQA.from_chain_type(llm=model, chain_type="stuff", vectorstore=vectordb) result = qa.run(query) return result query = "What did the president say about Ketanji Brown Jackson" r = ask(query) print (r)
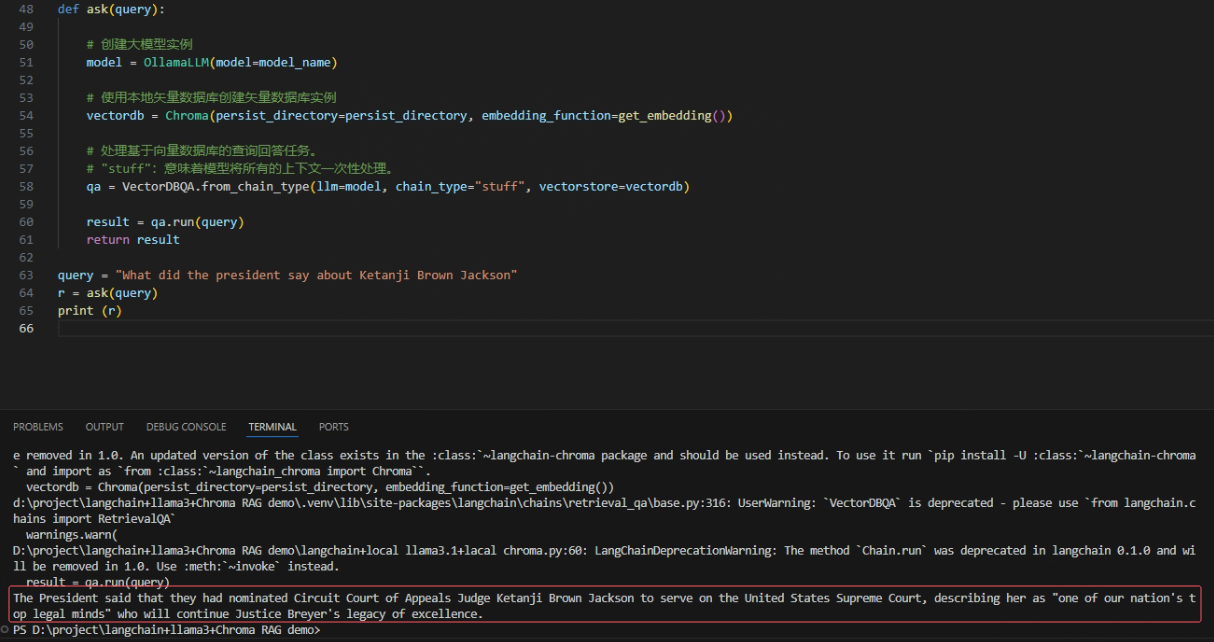
查询结果如下图:
4. 全部代码,仅供参考:
from langchain.vectorstores import Chroma from langchain.text_splitter import RecursiveCharacterTextSplitter from langchain.embeddings import OllamaEmbeddings from langchain_ollama.llms import OllamaLLM from langchain.chains import VectorDBQA from langchain.document_loaders import TextLoader persist_directory = 'chroma_langchain_db_test' model_name = "llama3.1" # 定义嵌入。在存储嵌入和查询时都需要用到此嵌入函数。 def get_embedding(): embeddings = OllamaEmbeddings(model=model_name) return embeddings # 对文本矢量化并存储在本地 def create_db(): # 用来加载文本文件。 # 指定文件使用tf-8编码读取,以确保正确处理非ASCII字符。 loader = TextLoader('doc/state_of_the_union.txt',encoding='utf-8') documents = loader.load() # 用于将长文本拆分成较小的段,便于嵌入和大模型处理。 # 每个文本块的最大长度是1000个字符,拆分的文本块之间没有重叠部分。 text_splitter = RecursiveCharacterTextSplitter(chunk_size=1000, chunk_overlap=0) texts = text_splitter.split_documents(documents) # 从文本块生成嵌入,并将嵌入存储在Chroma向量数据库中,同时设置数据库持久化路径。 vectordb = Chroma.from_documents(documents=texts, embedding=get_embedding(),persist_directory=persist_directory) # 将数据库的当前状态写入磁盘,以便在后续重启时加载和使用。 vectordb.persist() # create_db() def ask(query): # 创建大模型实例 model = OllamaLLM(model=model_name) # 使用本地矢量数据库创建矢量数据库实例 vectordb = Chroma(persist_directory=persist_directory, embedding_function=get_embedding()) # 处理基于向量数据库的查询回答任务。 # "stuff":意味着模型将所有的上下文一次性处理。 qa = VectorDBQA.from_chain_type(llm=model, chain_type="stuff", vectorstore=vectordb) result = qa.run(query) return result query = "What did the president say about Ketanji Brown Jackson" r = ask(query) print (r)
下载源代码
- [gitee]
- [github]

 浙公网安备 33010602011771号
浙公网安备 33010602011771号