[Python3] Python 基础教程
1 概述
1.1 简介
- Python 是一种解释型、面向对象、动态数据类型的高级程序设计语言。
- Python 由 Guido van Rossum 于 1989 年底发明,第一个公开发行版发行于
1991年。 - 像 Perl 语言一样, Python 源代码同样遵循 GPL(GNU General Public License) 协议。
Python 是一个高层次的结合了解释性、编译性、互动性和面向对象的脚本语言。
Python 的设计具有很强的可读性,相比其他语言经常使用英文关键字,其他语言的一些标点符号,它具有比其他语言更有特色语法结构。
Python 是一种解释型语言: 这意味着开发过程中没有了编译这个环节。类似于PHP和Perl语言。
Python 是交互式语言: 这意味着,您可以在一个 Python 提示符 >>> 后直接执行代码。
Python 是面向对象语言: 这意味着Python支持面向对象的风格或代码封装在对象的编程技术。
Python 是初学者的语言:Python 对初级程序员而言,是一种伟大的语言,它支持广泛的应用程序开发,从简单的文字处理到 WWW 浏览器再到游戏。
- Python 2 与 Python 3
- 官方宣布,2020 年 1 月 1 日, 停止 Python 2 的更新。Python 2.7 被确定为最后一个 Python 2.x 版本。
- Python 的 3.0 版本,常被称为
Python 3000,或简称Py3k。相对于 Python 的早期版本,这是一个较大的升级。为了不带入过多的累赘,Python 3.0 在设计的时候没有考虑向下兼容。
1.2 第1个Python程序
#!/usr/bin/python3
print("Hello, World!")
-
Python 常用文件扩展名为
.py。 -
你可以将以上代码保存在
hello.py文件中,并使用python命令执行该脚本文件。
$ python3 hello.py
Hello, World!
1.3 Python的安装/运维
1.3.0 安装 Python
安装方式1(源码编译方式)
- 源码编译式安装(python + pip)
- step1 安装 前置依赖
# 安装 python 的前置依赖 : make
apt-get update
#apt-get -y install vim
apt-get -y install make gcc build-essential
# 安装 pip 的前置依赖: zlib
apt-get -y install zlib1g zlib1g-dev
# yum install zlib*
- step2 编译安装 python
# 安装 python
PYTHON_VERSION=3.12.10
#curl -o /tmp/python.tgz https://www.python.org/ftp/python/3.12.10/Python-3.12.10.tgz
curl -o /opt/python.tgz https://mirrors.aliyun.com/python-release/source/Python-$PYTHON_VERSION.tgz
tar -zxvf /opt/python.tgz -C /opt/
#### 修改 Setup 文件,以确保后续安装 pip 时,不会因所依赖的 zlib 模块异常而报错 (此步骤,即 取消注释掉如下配置行) | 参考文献: 问题解决zipimport.ZipImportError: can‘t decompress data; zlib not availabl - CSDN - https://blog.csdn.net/loovelj/article/details/90274059
#vim /opt/Python-$PYTHON_VERSION/Modules/Setup
echo 'zlib zlibmodule.c -I$(prefix)/include -L$(exec_prefix)/lib -lz' >> /opt/Python-$PYTHON_VERSION/Modules/Setup
echo -e "\n" >> /opt/Python-$PYTHON_VERSION/Modules/Setup
cd /opt/Python-$PYTHON_VERSION
./configure
make && make install
- step3 查验安装信息
# python3 -V
Python 3.12.10
# whereis python3
python3: /usr/local/bin/python3
- step4 手动安装 pip
- step5 添加快捷指令 for python / pip
alias python="python3"
alias pip="pip3"
安装方式2(CENTOS)
yum -y install python3
python3 --version
安装方式3(Ubuntu)
# apt -y install python3
# python3 --version
Python 3.9.2
# whereis python3
python3: /usr/bin/python3 /usr/bin/python3.9 /usr/lib/python3 /usr/lib/python3.9 /etc/python3 /etc/python3.9 /usr/local/lib/python3.9 /usr/share/python3
# alias python=python3
- 推荐文献
安装方式4(基于Ubuntu 24 的 Docker 环境)
此节解决在基于 Ubuntu 24 作为基础镜像 的 Docker 环境中 Python 环境的安装方式(仅供参考)
- Dockerfile
# OS: Ubuntu 24.04
FROM swr.cn-north-4.myhuaweicloud.com/xxx/eclipse-temurin:17-noble
COPY ./target/*.jar /app.jar
COPY ./target/classes/xxx/ /xxx/
# install : python + pip (前置操作: 更新 apt 源)
RUN sed -i 's#http[s]*://[^/]*#http://mirrors.aliyun.com#g' /etc/apt/sources.list \
&& apt-get update \
&& apt-get -y install vim \
&& apt-get -y install --no-install-recommends python3 python3-pip python3-venv \
&& python3 -m venv $HOME/.venv \
&& . $HOME/.venv/bin/activate \ # 注:Linux 中 高版本 Python (3.5以上),必须在虚拟环境下方可正常安装所需依赖包
&& pip install -i https://mirrors.aliyun.com/pypi/simple/ can cantools
# && echo "alias python=python3" >> ~/.bashrc \ # Java程序的子进程调用中试验:未此行命令未生效;但开发者独自登录 docker 容器内,有生效
# && echo '. $HOME/.venv/bin/activate' >> ~/.bashrc \ # Java程序的子进程调用中试验:未此行命令未生效;但开发者独自登录 docker 容器内,有生效
# && echo 'export PYTHON=$HOME/.venv/bin/python' >> /etc/profile \ # Java程序的子进程调用中试验:未此行命令未生效;但开发者独自登录 docker 容器内,有生效
# && echo '. /etc/profile' > $HOME/app.sh \ # Java程序的子进程调用中试验:未测通,有衍生问题未解决掉
# && echo 'java ${JAVA_OPTS:-} -jar app.jar > /dev/null 2>&1 &' >> $HOME/app.sh \ # Java程序的子进程调用中试验:未测通,有衍生问题未解决掉
# && echo 'java ${JAVA_OPTS:-} -jar app.jar' >> $HOME/app.sh \ # Java程序的子进程调用中试验:未测通,有衍生问题未解决掉
# && chmod +x $HOME/app.sh \ # Java程序的子进程调用中试验:未测通,有衍生问题未解决掉
# && chown 777 $HOME/app.sh # Java程序的子进程调用中试验:未测通,有衍生问题未解决掉
EXPOSE 8080
# ENTRYPOINT exec sh $HOME/app.sh # Java程序的子进程调用中试验:未测通,有衍生问题未解决掉
ENTRYPOINT exec java ${JAVA_OPTS:-} -DPYTHON=$HOME/.venv/bin/python -jar app.jar # 通过 Java 获取 JVM 参数( System.getProperty("PYTHON") ) 方式获取 【 Python 可执行文件的绝对路径】的值
- Demo : Java 程序中调用 Python
@Slf4j
public class XxxxGenerator implements IGenerator<XxxxSequenceDto> {
//python jvm 变量 (`-DPYTHON=$HOME/.venv/bin/python`)
public static String PYTHON_VM_PARAM = "PYTHON";//System.getProperty(PYTHON_VM_PARAM)
//python 环境变量名称 //eg: "export PYTHON=$HOME/.venv/bin/python" , pythonEnv="$HOME/.venv/bin/python"
public static String PYTHON_ENV_PARAM = "PYTHON";//;System.getenv(PYTHON_ENV_PARAM);
private static String PYTHON_COMMAND ;
//默认的 python 命令
private static String PYTHON_COMMAND_DEFAULT = "python";
//...
static {
PYTHON_COMMAND = loadPythonCommand();
log.info("PYTHON_COMMAND:{}, PYTHON_VM:{}, PYTHON_ENV:{}", PYTHON_COMMAND, System.getProperty(PYTHON_VM_PARAM), System.getenv(PYTHON_ENV_PARAM) );
//...
}
/**
* 加载 python 命令的可执行程序的路径
* @note
* Linux 中,尤其是 高版本 Python(3.x) ,为避免 Java 通过 `Runtime.getRuntime().exec(args)` 方式 调用 Python 命令时,报找不到 可执行程序(`Python` 命令)\
* ————建议: java 程序中使用的 `python` 命令的可执行程序路径,使用【绝对路径】
* @return
*/
private static String loadPythonCommand(){
String pythonVm = System.getProperty(PYTHON_VM_PARAM);
String pythonEnv = System.getenv(PYTHON_ENV_PARAM);
String pythonCommand = pythonVm != null?pythonVm : pythonEnv;
pythonCommand = pythonCommand != null?pythonCommand : PYTHON_COMMAND_DEFAULT;
return pythonCommand;
}
/**
* CAN ASC LOG 转 BLF
* @param ascLogFilePath
* @param blfFilePath
*/
protected void convertToBlf(File ascLogFilePath, File blfFilePath){
//CanAsclogBlfConverterScriptPath = "/D:/Workspace/CodeRepositories/xxx-platform/xxx-sdk/xxx-sdk-java/target/classes/bin/can-asclog-blf-converter.py"
//String CanAsclogBlfConverterScriptPath = CanAscLogGenerator.class.getClassLoader().getResource("bin/can-asclog-blf-converter.py").getPath();
String canAscLogBlfConverterScriptPath = XxxxGenerator.scriptFilePath;//python 业务脚本的文件路径, eg: "D:\tmp\xxx-sdk\can-asclog-blf-converter.py"
//String [] args = new String [] {"python", "..\\bin\\can-asclog-blf-converter.py", "-i", ascLogFilePath, "-o", blfFilePath};// ascLogFilePath="/tmp/xxx-sdk/can-1.asc" , blfFilePath="/tmp/xxx-sdk/can-1.blf"
String [] args = new String [] { PYTHON_COMMAND, canAscLogBlfConverterScriptPath, "-i", ascLogFilePath.getPath(), "-o", blfFilePath.getPath()};
log.info("args: {} {} {} {} {} {}", args);
Process process = null;
Long startTime = System.currentTimeMillis();
try {
process = Runtime.getRuntime().exec(args);
Long endTime = System.currentTimeMillis();
log.info("Success to convert can asc log file to blf file!ascLogFile:{}, blfFile:{}, timeConsuming:{}ms, pid:{}", ascLogFilePath, blfFilePath, endTime - startTime, process.pid());
} catch (IOException exception) {
log.error("Fail to convert can asc log file to blf file!ascLogFile:{}, blfFile:{}, exception:", ascLogFilePath, blfFilePath, exception);
throw new RuntimeException(exception);
}
//读取 python 脚本的标准输出
// ---- input stream ----
List<String> processOutputs = new ArrayList<>();
try(
InputStream processInputStream = process.getInputStream();
BufferedReader processReader = new BufferedReader( new InputStreamReader( processInputStream ));
) {
Long readProcessStartTime = System.currentTimeMillis();
String processLine = null;
while( (processLine = processReader.readLine()) != null ) {
processOutputs.add( processLine );
}
process.waitFor();
Long readProcessEndTime = System.currentTimeMillis();
log.info("Success to read the can asc log to blf file's process standard output!timeConsuming:{}ms", readProcessEndTime - readProcessStartTime );
log.info("processOutputs(System.out):{}", JSON.toJSONString( processOutputs ));
} catch (IOException exception) {
log.error("Fail to get input stream!IOException:", exception);
throw new RuntimeException(exception);
} catch (InterruptedException exception) {
log.error("Fail to wait for the process!InterruptedException:{}", exception);
throw new RuntimeException(exception);
}
// ---- error stream ----
List<String> processErrors = new ArrayList<>();
try(
InputStream processInputStream = process.getErrorStream();
BufferedReader processReader = new BufferedReader( new InputStreamReader( processInputStream ));
) {
Long readProcessStartTime = System.currentTimeMillis();
String processLine = null;
while( (processLine = processReader.readLine()) != null ) {
processErrors.add( processLine );
}
process.waitFor();
Long readProcessEndTime = System.currentTimeMillis();
log.error("Success to read the can asc log to blf file's process standard output!timeConsuming:{}ms", readProcessEndTime - readProcessStartTime );
log.error("processOutputs(System.err):{}", JSON.toJSONString( processOutputs ));
} catch (IOException exception) {
log.error("Fail to get input stream!IOException:", exception);
throw new RuntimeException(exception);
} catch (InterruptedException exception) {
log.error("Fail to wait for the process!InterruptedException:{}", exception);
throw new RuntimeException(exception);
}
if( processErrors.size() > 0 ) {
throw new RuntimeException( "convert to blf failed!\nerrors:" + JSON.toJSONString(processErrors) );
}
}
}
- 【特别注意】
- Linux 中,尤其是 高版本 Python(3.x) ,为避免 Java 通过
Runtime.getRuntime().exec(args)方式 调用 Python 命令时,报找不到 可执行程序(Python命令)强烈建议: java 程序中使用的
python命令的可执行程序路径,使用【绝对路径】
- 推荐文献
1.3.1 查看安装位置
- Windows CMD (不支持 Power Shell)
C:\Users\xxx> where python
C:\Users\xxx\AppData\Local\Programs\Python\Python310\python.exe
C:\Users\xxx\AppData\Local\Microsoft\WindowsApps\python.exe

- Linux
root@xxxbackend-service-xxx-xxx:/# which python3
/usr/bin/python3
root@xxxbackend-service-xxx-xxx:/# whereis python3
python3: /usr/bin/python3 /usr/lib/python3 /etc/python3 /usr/share/python3
1.3.2 查看版本
- 方式1 命令行
python --version
python3 --version
或
python -V
python3 -V
- 方式2 利用
sys模块
import sys
print(sys.version);
# 或 print(sys.version_info)

- 方式3 利用
platform模块
import platform
print(platform.python_version())
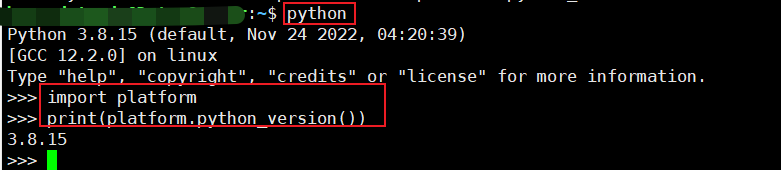
1.3.3 退出 command 模式
>>> exit();
xx@yyyy:~$
1.3.4 Python 安装包源
- 官方安装包源
curl -o /tmp/python.tgz https://www.python.org/ftp/python/3.12.10/Python-3.12.10.tgz
- 第三方安装包源(阿里云)

PYTHON_VERSION=3.12.10
curl -o /opt/python.tgz https://mirrors.aliyun.com/python-release/source/Python-$PYTHON_VERSION.tgz
1.4 Python的发展历程
- Python 是由 Guido van Rossum 在八十年代末和九十年代初,在荷兰国家数学和计算机科学研究所设计出来的。
- Python 本身也是由诸多其他语言发展而来的,这包括 ABC、Modula-3、C、C++、Algol-68、SmallTalk、Unix shell 和其他的脚本语言等等。
- 像 Perl 语言一样,Python 源代码同样遵循 GPL(GNU General Public License)协议。
- 现在 Python 是由一个核心开发团队在维护,Guido van Rossum 仍然占据着至关重要的作用,指导其进展。
- Python 2.0 于 2000 年 10 月 16 日发布,增加了实现完整的垃圾回收,并且支持 Unicode。
- Python 2.7 被确定为最后一个 Python 2.x 版本,它除了支持 Python 2.x 语法外,还支持部分 Python 3.1 语法。
- Python 3.0 于 2008 年 12 月 3 日发布,此版不完全兼容之前的 Python 源代码。不过,很多新特性后来也被移植到旧的Python 2.6/2.7版本。
- Python 3.0 版本,常被称为 Python 3000,或简称 Py3k。相对于 Python 的早期版本,这是一个较大的升级。
1.5 Python的语言特点
- 易于学习:Python有相对较少的关键字,结构简单,和一个明确定义的语法,学习起来更加简单。
- 易于阅读:Python代码定义的更清晰。
- 易于维护:Python的成功在于它的源代码是相当容易维护的。
- 一个广泛的标准库:Python的最大的优势之一是丰富的库,跨平台的,在UNIX,Windows和Macintosh兼容很好。
- 互动模式:互动模式的支持,您可以从终端输入执行代码并获得结果的语言,互动的测试和调试代码片断。
- 可移植:基于其开放源代码的特性,Python已经被移植(也就是使其工作)到许多平台。
- 可扩展:如果你需要一段运行很快的关键代码,或者是想要编写一些不愿开放的算法,你可以使用C或C++完成那部分程序,然后从你的Python程序中调用。
- 数据库:Python提供所有主要的商业数据库的接口。
- GUI编程:Python支持GUI可以创建和移植到许多系统调用。
- 可嵌入: 你可以将Python嵌入到C/C++程序,让你的程序的用户获得"脚本化"的能力。
1.6 开发环境与工具
Python Command : 原始工具
python
VSCode : 支持Python插件/编程的IDE 【主流】
- url
- 定位
VSCode是一款由微软开发的跨平台免费源代码编辑器,支持语法高亮、代码自动补全、调试工具等功能。
它通过插件市场提供丰富的扩展功能,适合中小型项目开发者、Web开发者、数据科学家等使用
PyCharm : 专业的 Python 集成软件开发环境(IDE) 【主流】
- Reference Document
- 定位
PyCharm是一款由JetBrains开发的专业Python IDE,分为免费社区版和付费专业版。
它提供智能代码编辑、调试、版本控制等功能,特别适合大型项目开发、数据科学和Web开发。
社区版适合个人学习和小型项目,专业版则包含更多高级功能,适合企业级应用
Jupter Lab / Jupter NoteBook 【主流】
- 定位
Jupyter Notebook适合数据科学家和机器学习开发者,提供了一个交互式计算平台,支持多种编程语言。
它便于数据分析和科学计算,支持通过邮件、GitHub等方式共享笔记,并集成了大数据工具如Apache Spark
JupyterLab: 用于交互式数据科学和可视化的集成开发环境(IDE)。
- https://jupyter.org
- 支持语言: Jupyter 支持超过 40 种编程语言,包括 Python、R、Julia 和 Scala。
Jupyter是它要服务的三种编程语言(Julia,Python、R)的缩写。
Julia是一个面向科学计算的高性能动态高级程序设计语言。Python是一门编程语言,具有丰富强大的库。Python 也被称为胶水语言,因为它能够把用其他语言制作的各种模块(尤其是C/C++)很轻松地连在一起。R是用于统计分析、绘图的语言和操作环境。
- 共享笔记本 : 可以通过电子邮件、Dropbox、GitHub 和Jupyter Notebook Viewer与他人共享笔记本。
- 交互式输出 : 您的代码可以产生丰富的交互式输出:HTML、图像、视频、LaTeX 和自定义 MIME 类型。
- 大数据集成 : 利用 Python、R 和 Scala 中的大数据工具(例如 Apache Spark)。使用 pandas、scikit-learn、ggplot2 和 TensorFlow 探索相同的数据。
Jupter NoteBookJupyter Notebook是基于网页的用于交互计算的应用程序。其可被应用于全过程计算:开发、文档编写、运行代码和展示结果。
Jupyter Notebook 是用于创建和共享计算文档的原始 Web 应用程序。它提供简单、精简、以文档为中心的体验。
在没有Jupyter Notebook之前,在IT领域工作的程序员是这样工作的:
首先,在普通的 Python shell 或者在IDE(集成开发环境)如Pycharm中写代码,
然后,在word中写文档来说明他的项目。
这个过程很繁琐,通常是写完代码,再写文档的时候还要重头回顾一遍代码。
最麻烦的地方在于,有些数据分析的中间结果,还要重新跑代码,然后把结果弄到文档里给客户看。
有了Jupyter Notebook之后,程序员的世界突然美好了许多,因为Jupyter Notebook可以直接在代码旁写出叙述性文档,而不是另外编写单独的文档。
也就是,它可以能将代码、文档等这一切集中到一处,让用户一目了然。
JupyterLab: 下一代笔记本界面。是最新的基于 Web 的交互式开发环境,适用于笔记本、代码和数据。
其灵活的界面允许用户配置和安排数据科学、科学计算、计算新闻和机器学习中的工作流程。
模块化设计允许扩展以扩展和丰富功能。
- 推荐文献
Jupyter 的安装方法有3种:
- 1、命令行安装 Jupyter Notebook :
pip install jupyter- 2、VSCode 安装 Jupyter Notebook :
Python插件 +Jupyter插件- 3、Anaconda 安装 Jupyter Notebook
版本环境管理 : Conda
包管理 : pip
2 Python3 基础语法
基础语法
编码
- 默认情况下,
Python 3源码文件以UTF-8编码,所有字符串都是unicode字符串。
当然你也可以为源码文件指定不同的编码:
# -*- coding: cp-1252 -*-
或
#!/usr/bin/env python3.8
# -*- coding: utf-8 -*-
上述定义允许在源文件中使用
Windows-1252字符集中的字符编码,对应适合语言为保加利亚语、白俄罗斯语、马其顿语、俄语、塞尔维亚语。
标识符
- 第1个字符必须是字母表中字母或下划线
_。 - 标识符的其他的部分由字母、数字和下划线组成。
- 标识符对大小写敏感。
在
Python 3中,可以用中文作为变量名,非 ASCII 标识符也是允许的了。
python保留字
- 保留字即关键字,我们不能把它们用作任何标识符名称。
Python的标准库提供了一个keyword模块,可以输出当前版本的所有关键字:
>>> import keyword
>>> keyword.kwlist
['False', 'None', 'True', 'and', 'as', 'assert', 'break', 'class', 'continue', 'def', 'del', 'elif', 'else', 'except', 'finally', 'for', 'from', 'global', 'if', 'import', 'in', 'is', 'lambda', 'nonlocal', 'not', 'or', 'pass', 'raise', 'return', 'try', 'while', 'with', 'yield']
注释
- 单行注释 : 以
#开头
示例
#!/usr/bin/python3
# 第一个注释
print ("Hello, Python!") # 第二个注释
out
Hello, Python!
- 多行注释 : 可以用多个
#号,还有'''和"""
#!/usr/bin/python3
# 第一个注释
# 第二个注释
'''
第三注释
第四注释
'''
"""
第五注释
第六注释
"""
print ("Hello, Python!")
out
Hello, Python!
行与缩进
-
python最具特色的就是使用缩进来表示代码块,不需要使用大括号{}。 -
缩进的空格数是可变的,但是同一个代码块的语句必须包含相同的缩进空格数。
示例
if True:
print ("True")
else:
print ("False")
以下代码最后一行语句缩进数的空格数不一致,会导致运行错误:
if True:
print ("Answer")
print ("True")
else:
print ("Answer")
print ("False") # 缩进不一致,会导致运行错误
out
File "test.py", line 6
print ("False") # 缩进不一致,会导致运行错误
^
IndentationError: unindent does not match any outer indentation level
缩进错误: 取消缩进不匹配任何外部缩进级别
多行语句
Python通常是一行写完一条语句,但如果语句很长,我们可以使用反斜杠\来实现多行语句。
例如:
total = item_one + \
item_two + \
item_three
- 在
[],{}, 或()中的多行语句,不需要使用反斜杠\。
例如:
total = ['item_one', 'item_two', 'item_three',
'item_four', 'item_five']
变量:无类型、无需声明、使用前必须赋值、赋值后方才被创建 | 变量赋值
- Python 中的变量不需要声明。每个变量在使用前都必须赋值,变量赋值以后该变量才会被创建。
- 在 Python 中,变量就是变量,它没有类型,我们所说的"类型"是变量所指的内存中对象的类型。
- 等号(
=)用来给变量赋值。 - 等号(
=)运算符左边是一个变量名,等号(=)运算符右边是存储在变量中的值。
例如:
#!/usr/bin/python3
counter = 100 # 整型变量
miles = 1000.0 # 浮点型变量
name = "test" # 字符串
print (counter)
print (miles)
print (name)
out
100
1000.0
test
- 多个变量赋值
- Python允许你同时为多个变量赋值。例如:
a = b = c = 1
以上实例,创建一个整型对象,值为 1,从后向前赋值,三个变量被赋予相同的数值。
您也可以为多个对象指定多个变量。例如:
a, b, c = 1, 2, "test"
以上实例,两个整型对象 1 和 2 的分配给变量 a 和 b,字符串对象 "test" 分配给变量 c。
标准数据类型
-
Python3 中常见的数据类型有:
-
Number(数字)
-
String(字符串)
-
bool(布尔类型)
-
List(列表)
-
Tuple(元组)
-
Set(集合)
-
Dictionary(字典)
-
Python3 的六个标准数据类型中:
- 不可变数据(3 个):Number(数字)、String(字符串)、Tuple(元组);
- 可变数据(3 个):List(列表)、Dictionary(字典)、Set(集合)。
string、tuple和list都属于sequence(序列)。
数据类型的判别
- 内置的
type()函数可以用来查询变量所指的对象类型
>>> a, b, c, d = 20, 5.5, True, 4+3j
>>> print(type(a), type(b), type(c), type(d))
<class 'int'> <class 'float'> <class 'bool'> <class 'complex'>
- 也可以用
isinstance来判断:
>>> a = 111
>>> isinstance(a, int)
True
>>>
isinstance和type()的区别在于:
type(): 不会认为子类是一种父类类型。isinstance(): 会认为子类是一种父类类型。
>>> class A:
... pass
...
>>> class B(A):
... pass
...
>>> isinstance(A(), A)
True
>>> type(A()) == A
True
>>> isinstance(B(), A)
True
>>> type(B()) == A
False
issubclass/is
案例:Python3 中,bool 是 int 的子类,True 和 False 可以和数字相加, True1、False0 会返回 True,但可以通过
is来判断类型。
>>> issubclass(bool, int)
True
>>> True==1
True
>>> False==0
True
>>> True+1
2
>>> False+1
1
>>> 1 is True
False
>>> 0 is False
False
删除引用
- 您也可以使用del语句删除一些对象引用。
del语句的语法是:
del var1[,var2[,var3[....,varN]]]
- 您可以通过使用del语句删除单个或多个对象。例如:
del var
del var_a, var_b
数值运算
>>> 5 + 4 # 加法
9
>>> 4.3 - 2 # 减法
2.3
>>> 3 * 7 # 乘法
21
>>> 2 / 4 # 除法,得到一个浮点数
0.5
>>> 2 // 4 # 除法,得到一个整数
0
>>> 17 % 3 # 取余
2
>>> 2 ** 5 # 乘方
32
- 1、Python可以同时为多个变量赋值,如a, b = 1, 2。
- 2、一个变量可以通过赋值指向不同类型的对象。
- 3、数值的除法包含两个运算符:
/返回一个浮点数,//返回一个整数。 - 4、在混合计算时,Python会把整型转换成为浮点数。
数值类型的示例
| int | float | complex |
|---|---|---|
| 10 | 0.0 | 3.14j |
| 100 | 15.20 | 45.j |
| -786 | -21.9 | 9.322e-36j |
| 080 | 32.3e+18 | .876j |
| -0490 | -90. | -.6545+0J |
| -0x260 | -32.54e100 | 3e+26J |
| 0x69 | 70.2E-12 | 4.53e-7j |
- Python 还支持复数,复数由实数部分和虚数部分构成,可以用
a + bj,或者complex(a,b)表示, 复数的实部 a 和虚部 b 都是浮点型。
数字(Number)类型
python中数字有4种类型:int(整型)、float(浮点数)、bool(布尔值)、complex(复数)
int(整数), 如 1, 只有一种整数类型int,表示为长整型,没有 python2 中的 Long。bool(布尔), 如 True / False。
Python3中,bool是int的子类,True和False可以和数字相加, True1、False0 会返回 True,但可以通过is来判断类型。- 在
Python2中是没有布尔型的,它用数字 0 表示 False,用 1 表示 True。
float(浮点数), 如 1.23、3E-2complex(复数) - 复数由实部和虚部组成,形式为 a + bj,其中 a 是实部,b 是虚部,j 表示虚数单位。如 1 + 2j、 1.1 + 2.2j
- 当你指定一个值时,Number 对象就会被创建:
var1 = 1
var2 = 10
字符串(String)类型
- Python中的字符串用单引号
'或双引号"括起来,同时使用反斜杠\转义特殊字符。
- Python 中单引号
'和双引号"使用完全相同。
- 使用三引号(
'''或""")可以指定一个多行字符串。 - 转义符
\。 - 反斜杠
\可以用来转义,使用r可以让反斜杠不发生转义。
如
r"this is a line with \n"则\n会显示,并不是换行。
- 按字面意义级联字符串,如
"this ""is ""string"会被自动转换为this is string。 - 字符串可以用
+运算符连接在一起,用*运算符重复。 - Python 中的字符串有两种索引方式,从左往右以
0开始,从右往左以-1开始。 - Python 中的字符串不能被修改。
- 与 C 字符串不同的是,Python 字符串不能被改变。向一个索引位置赋值,比如
word[0] = 'm'会导致错误。
-
Python 没有单独的字符类型,一个字符就是长度为
1的字符串。 -
字符串的截取/切片
str[start:end]
- 其中,
start(包含)是切片开始的索引,end(不包含)是切片结束的索引。- 索引值以
0为开始值,-1为从末尾的开始位置。
- 字符串切片可以加上步长参数
step,语法格式:str[start:end:step]
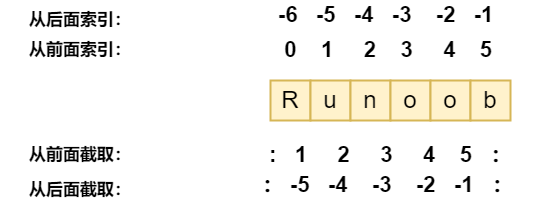
word = '字符串'
sentence = "这是一个句子。"
paragraph = """这是一个段落,
可以由多行组成"""
- Demo
#!/usr/bin/python3
str='123456789'
print(str) # 输出字符串
print(str[0:-1]) # 输出第一个到倒数第二个的所有字符
print(str[0]) # 输出字符串第一个字符
print(str[2:5]) # 输出从第三个开始到第六个的字符(不包含)
print(str[2:]) # 输出从第三个开始后的所有字符
print(str[1:5:2]) # 输出从第二个开始到第五个且每隔一个的字符(步长为2)
print(str * 2) # 输出字符串两次
print(str + '你好') # 连接字符串
print('------------------------------')
print('hello\nworld') # 使用反斜杠(\)+n转义特殊字符
print(r'hello\nworld') # 在字符串前面添加一个 r,表示原始字符串,不会发生转义
这里的 r 指 raw,即 raw string,会自动将反斜杠转义,例如:
>>> print('\n') # 输出空行
>>> print(r'\n') # 输出 \n
\n
>>>
以上代码的输出:
123456789
12345678
1
345
3456789
24
123456789123456789
123456789你好
------------------------------
hello
world
hello\nworld
布尔(bool)类型
-
布尔类型只有两个值:True 和 False。
-
在
Python中,True和False都是关键字,表示布尔值。 -
布尔类型可以用来控制程序的流程,比如判断某个条件是否成立,或者在某个条件满足时执行某段代码。
-
bool是int的子类。
因此,布尔值可以被看作整数来使用,其中 True 等价于 1。
仅Python 3支持 bool 类型
Python3 中,bool 是 int 的子类,True 和 False 可以和数字相加, True1、False0 会返回 True,但可以通过 is 来判断类型。
>>> issubclass(bool, int)
True
>>> True==1
True
>>> False==0
True
>>> True+1
2
>>> False+1
1
>>> 1 is True
False
>>> 0 is False
False
在 Python2 中是没有布尔型的,它用数字 0 表示 False,用 1 表示 True
- 布尔类型可以和其他数据类型进行比较
比如,数字、字符串等。在比较时,Python 会将 True 视为 1,False 视为 0。
- 布尔类型可以和逻辑运算符一起使用,包括 and、or 和 not。
这些运算符可以用来组合多个布尔表达式,生成一个新的布尔值。
- 布尔类型也可以被转换成其他数据类型
比如整数、浮点数和字符串。
在转换时,True 会被转换成 1,False 会被转换成 0。
- 可以使用
bool()函数将其他类型的值转换为布尔值。
这些值在转换为布尔值时为 False:
- None、False、零 (0、0.0、0j)、空序列(如 ''、()、[])和空映射(如 {})。
其他所有值转换为布尔值时均为 True。
在 Python 中,所有非零的数字和非空的字符串、列表、元组等数据类型都被视为 True;
只有 0、空字符串、空列表、空元组等被视为 False。因此,在进行布尔类型转换时,需要注意数据类型的真假性。
- demo
# 布尔类型的值和类型
a = True
b = False
print(type(a)) # <class 'bool'>
print(type(b)) # <class 'bool'>
# 布尔类型的整数表现
print(int(True)) # 1
print(int(False)) # 0
# 使用 bool() 函数进行转换
print(bool(0)) # False
print(bool(42)) # True
print(bool('')) # False
print(bool('Python')) # True
print(bool([])) # False
print(bool([1, 2, 3])) # True
# 布尔逻辑运算
print(True and False) # False
print(True or False) # True
print(not True) # False
# 布尔比较运算
print(5 > 3) # True
print(2 == 2) # True
print(7 < 4) # False
# 布尔值在控制流中的应用
if True:
print("This will always print")
if not False:
print("This will also always print")
x = 10
if x:
print("x is non-zero and thus True in a boolean context")
元组(Tuple)类型
- 元组(tuple)与列表类似,不同之处在于元组的元素不能修改。元组写在小括号 () 里,元素之间用逗号隔开。
- 元组中的元素类型也可以不相同:
#!/usr/bin/python3
tuple = ( 'abcd', 786 , 2.23, 'runoob', 70.2 )
tinytuple = (123, 'runoob')
print (tuple) # 输出完整元组
print (tuple[0]) # 输出元组的第一个元素
print (tuple[1:3]) # 输出从第二个元素开始到第三个元素
print (tuple[2:]) # 输出从第三个元素开始的所有元素
print (tinytuple * 2) # 输出两次元组
print (tuple + tinytuple) # 连接元组
output
('abcd', 786, 2.23, 'runoob', 70.2)
abcd
(786, 2.23)
(2.23, 'runoob', 70.2)
(123, 'runoob', 123, 'runoob')
('abcd', 786, 2.23, 'runoob', 70.2, 123, 'runoob')
-
元组与字符串类似,可以被索引且下标索引从0开始,-1 为从末尾开始的位置。也可以进行截取(看上面,这里不再赘述)。
-
demo
>>> tup = (1, 2, 3, 4, 5, 6)
>>> print(tup[0])
1
>>> print(tup[1:5])
(2, 3, 4, 5)
>>> tup[0] = 11 # 修改元组元素的操作是非法的
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
TypeError: 'tuple' object does not support item assignment
>>>
- 虽然tuple的元素不可改变,但它可以包含可变的对象,比如list列表。
构造包含 0 个或 1 个元素的元组比较特殊,所以有一些额外的语法规则:
tup1 = () # 空元组
tup2 = (20,) # 一个元素,需要在元素后添加逗号
- 如果你想创建只有一个元素的元组,需要注意在元素后面添加一个逗号,以区分它是一个元组而不是一个普通的值。
这是因为在没有逗号的情况下,Python会将括号解释为数学运算中的括号,而不是元组的表示。
如果不添加逗号,如下所示,它将被解释为一个普通的值而不是元组:
not_a_tuple = (42)
这样的话,not_a_tuple 将是整数类型而不是元组类型。
string、list 和 tuple 都属于 sequence(序列)。
列表/数组(List)类型
-
List(列表) 是Python中使用最频繁的数据类型。 -
列表可以完成大多数集合类的数据结构实现。列表中元素的类型可以不相同,它支持数字,字符串甚至可以包含列表(所谓嵌套)。
-
列表是写在方括号
[]之间、用逗号,分隔开的元素列表。 -
和字符串一样,列表同样可以被索引和截取,列表被截取后返回一个包含所需元素的新列表。
-
列表截取的语法格式:
变量[头下标:尾下标]
- 索引值以
0为开始值,-1为从末尾的开始位置
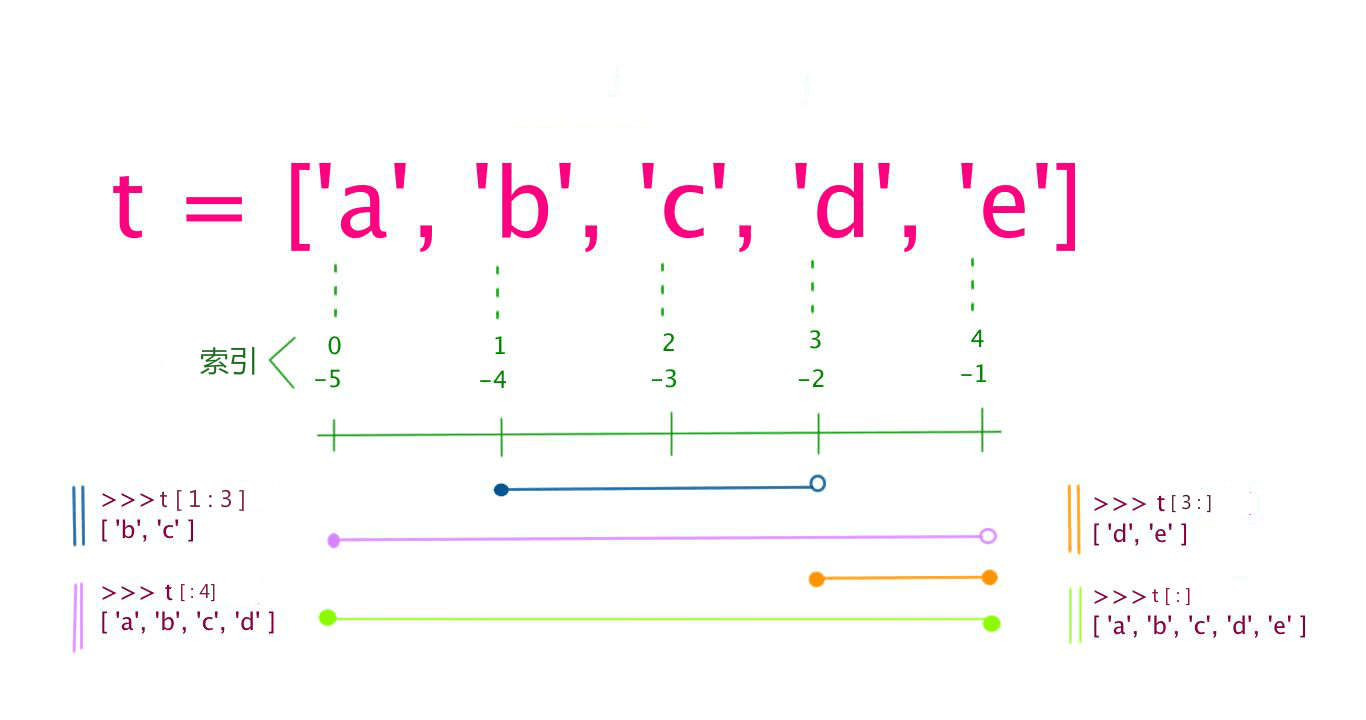
- 加号
+是列表连接运算符,星号*是重复操作。
demo
#!/usr/bin/python3
list = [ 'abcd', 786 , 2.23, 'runoob', 70.2 ] # 定义一个列表
tinylist = [123, 'runoob']
print (list) # 打印整个列表
print (list[0]) # 打印列表的第一个元素
print (list[1:3]) # 打印列表第二到第四个元素(不包含第四个元素)
print (list[2:]) # 打印列表从第三个元素开始到末尾
print (tinylist * 2) # 打印tinylist列表两次
print (list + tinylist) # 打印两个列表拼接在一起的结果
output
['abcd', 786, 2.23, 'runoob', 70.2]
abcd
[786, 2.23]
[2.23, 'runoob', 70.2]
[123, 'runoob', 123, 'runoob']
['abcd', 786, 2.23, 'runoob', 70.2, 123, 'runoob']
- 与Python字符串不一样的是,列表中的元素是可改变/修改的
>>> a = [1, 2, 3, 4, 5, 6]
>>> a[0] = 9
>>> a[2:5] = [13, 14, 15]
>>> a
[9, 2, 13, 14, 15, 6]
>>> a[2:5] = [] # 将对应的元素值设置为 []
>>> a
[9, 2, 6]
-
List 内置了有很多方法,如 append()、pop() 等等
-
Python列表截取可以接收第3个参数,参数作用是截取的步长
demo : 以下实例在索引 1 到索引 4 的位置并设置为步长为 2(间隔一个位置)来截取字符串
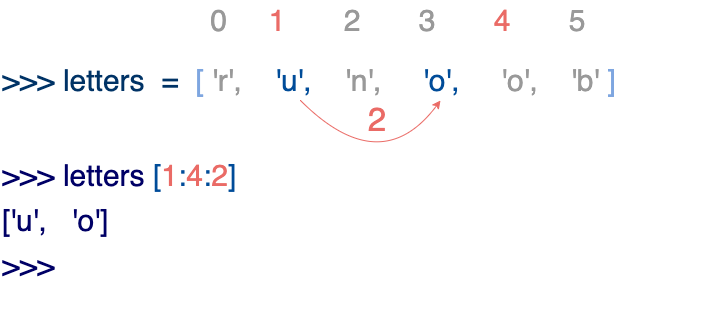
如果第三个参数为负数表示逆向读取
以下实例用于翻转字符串:
def reverseWords(input):
# 通过空格将字符串分隔符,把各个单词分隔为列表
inputWords = input.split(" ")
# 翻转字符串
# 假设列表 list = [1,2,3,4],
# list[0]=1, list[1]=2 ,而 -1 表示最后一个元素 list[-1]=4 ( 与 list[3]=4 一样)
# inputWords[-1::-1] 有三个参数
# 第一个参数 -1 表示最后一个元素
# 第二个参数为空,表示移动到列表末尾
# 第三个参数为步长,-1 表示逆向
inputWords=inputWords[-1::-1]
# 重新组合字符串
output = ' '.join(inputWords)
return output
if __name__ == "__main__":
input = 'I like test'
rw = reverseWords(input)
print(rw)
output
test like I
集合(Set)类型
-
Python中的集合(Set)是一种无序、可变的数据类型,用于存储唯一的元素。 -
集合中的元素不会重复,并且可以进行交集、并集、差集等常见的集合操作。
-
在 Python 中,集合使用大括号
{}表示,元素之间用逗号,分隔。 -
另外,也可以使用
set()函数创建集合。
注意:创建一个空集合必须用
set()而不是{ },因为{ }是用来创建一个空字典。
- 创建格式:
parame = {value01,value02,...}
或者
set(value)
- demo
#!/usr/bin/python3
sites = {'Google', 'Taobao', 'Tencent', 'Facebook', 'Zhihu', 'Baidu'}
print(sites) # 输出集合,重复的元素被自动去掉
# 成员测试
if 'Tencent' in sites :
print('Tencent 在集合中')
else :
print('Tencent 不在集合中')
# set可以进行集合运算
a = set('abracadabra')
b = set('alacazam')
print(a)
print( len(a) ) # 获取 a set 的元素个数
print(a - b) # a 和 b 的差集
print(a | b) # a 和 b 的并集
print(a & b) # a 和 b 的交集
print(a ^ b) # a 和 b 中不同时存在的元素
output
{'Zhihu', 'Baidu', 'Taobao', 'Tencent', 'Google', 'Facebook'}
Tencent 在集合中
{'b', 'c', 'a', 'r', 'd'}
5
{'r', 'b', 'd'}
{'b', 'c', 'a', 'z', 'm', 'r', 'l', 'd'}
{'c', 'a'}
{'z', 'b', 'm', 'r', 'l', 'd'}
字典(Dictionary)类型
- 字典(dictionary)是Python中另一个非常有用的内置数据类型。
- 列表是有序的对象集合,字典是无序的对象集合。两者之间的区别在于:字典当中的元素是通过键来存取的,而不是通过偏移存取。
- 字典是一种映射类型,字典用 { } 标识,它是一个无序的 键(key) : 值(value) 的集合。
- 键(key)必须使用不可变类型。
- 在同一个字典中,键(key)必须是唯一的。
#!/usr/bin/python3
dict = {}
dict['one'] = "1 - 教程"
dict[2] = "2 - 工具"
tinydict = {'name': 'test','code':1, 'site': 'www.test.com'}
print (dict['one']) # 输出键为 'one' 的值
print (dict[2]) # 输出键为 2 的值
print (tinydict) # 输出完整的字典
print (tinydict.keys()) # 输出所有键
print (tinydict.values()) # 输出所有值
out
1 - 教程
2 - 工具
{'name': 'test', 'code': 1, 'site': 'www.test.com'}
dict_keys(['name', 'code', 'site'])
dict_values(['test', 1, 'www.test.com'])
- 构造函数
dict()可以直接从键值对序列中构建字典如下:
>>> dict([('Test', 1), ('Google', 2), ('Taobao', 3)])
{'Test': 1, 'Google': 2, 'Taobao': 3}
>>> {x: x**2 for x in (2, 4, 6)}
{2: 4, 4: 16, 6: 36}
>>> dict(Test=1, Google=2, Taobao=3)
{'Test': 1, 'Google': 2, 'Taobao': 3}
{x: x**2 for x in (2, 4, 6)}该代码使用的是字典推导式
更多推导式内容可以参考:Python 推导式 - 菜鸟教程。
-
另外,字典类型也有一些内置的函数,例如 clear()、keys()、values() 等。
-
注意:
- 1、字典是一种映射类型,它的元素是键值对。
- 2、字典的关键字必须为不可变类型,且不能重复。
- 3、创建空字典使用
{ }。
二进制序列(bytes)类型
- 在 Python3 中,
bytes类型表示的是不可变的二进制序列(byte sequence)。 - 与字符串类型不同的是,
bytes类型中的元素是整数值(0到255之间的整数),而不是Unicode字符。 bytes类型通常用于处理二进制数据
比如,图像文件、音频文件、视频文件等等。
在网络编程中,也经常使用bytes类型来传输二进制数据。
-
创建
bytes对象的方式有多种,最常见的方式是使用b前缀: -
也可以使用
bytes()函数将其他类型的对象转换为 bytes 类型。b
bytes()函数的第1个参数是要转换的对象,第2个参数是编码方式,如果省略第二个参数,则默认使用UTF-8编码
x = bytes("hello", encoding="utf-8")
- 与字符串类型类似,
bytes类型也支持许多操作和方法,如切片、拼接、查找、替换等等。同时,由于bytes类型是不可变的,因此在进行修改操作时需要创建一个新的 bytes 对象。
例如:
x = b"hello"
y = x[1:3] # 切片操作,得到 b"el"
z = x + b"world" # 拼接操作,得到 b"helloworld"
其中
ord()函数用于将字符转换为相应的整数值。
Python数据类型转换
- 有时候,我们需要对数据内置的类型进行转换,数据类型的转换,你只需要将数据类型作为函数名即可。
在 Python3 数据类型转换 - 菜鸟教程 会具体介绍。
有时候,我们需要对数据内置的类型进行转换,数据类型的转换,一般情况下你只需要将数据类型作为函数名即可。
- Python 数据类型转换可以分为两种:
隐式类型转换 - 自动完成
显式类型转换 - 需要使用类型函数来转换
隐式类型转换
-
隐式类型转换
在隐式类型转换中,Python 会自动将一种数据类型转换为另一种数据类型,不需要我们去干预。 -
"较高数据类型"、"较低数据类型"
"较高数据类型"和"较低数据类型"是在隐式类型转换中用于描述数据精度的概念。
精度可以理解为数据类型能够表示的信息量或详细程度。
在Python中,数据类型的"高"和"低"主要根据它们的精度来判断。
这里的"较高"数据类型指的是能够表示更多信息(或更精确信息)的数据类型,而"较低"的数据类型则表示的信息较少。
具体来说,比如浮点数就比整数"高",因为浮点数不仅可以表示整数,还可以表示小数。
所以在下述例子中,整数就会被自动转换为浮点数,以保证信息不丢失。
以下实例中,我们对两种不同类型的数据进行运算,较低数据类型(整数)就会转换为较高数据类型(浮点数)以避免数据丢失。
num_int = 123
num_flo = 1.23
num_new = num_int + num_flo
print("num_int 数据类型为:",type(num_int))
print("num_flo 数据类型为:",type(num_flo))
print("num_new 值为:",num_new)
print("num_new 数据类型为:",type(num_new))
out
num_int 数据类型为: <class 'int'>
num_flo 数据类型为: <class 'float'>
num_new: 值为: 124.23
num_new 数据类型为: <class 'float'>
代码解析:
实例中我们对两个不同数据类型的变量 num_int 和 num_flo 进行相加运算,并存储在变量 num_new 中。
然后查看三个变量的数据类型。
在输出结果中,我们看到 num_int 是 整型(integer) , num_flo 是 浮点型(float)。
同样,新的变量 num_new 是 浮点型(float),这是因为 Python 会将较小的数据类型转换为较大的数据类型,以避免数据丢失。
我们再看一个实例,整型数据与字符串类型的数据进行相加:
num_int = 123
num_str = "456"
print("num_int 数据类型为:",type(num_int))
print("num_str 数据类型为:",type(num_str))
print(num_int+num_str)
以上实例输出结果为:
num_int 数据类型为: <class 'int'>
num_str 数据类型为: <class 'str'>
Traceback (most recent call last):
File "/runoob-test/test.py", line 7, in <module>
print(num_int+num_str)
TypeError: unsupported operand type(s) for +: 'int' and 'str'
从输出中可以看出,整型和字符串类型运算结果会报错,输出 TypeError。 Python 在这种情况下无法使用隐式转换。
但是,Python 为这些类型的情况提供了一种解决方案,称为显式转换。
显式类型转换
在显式类型转换中,用户将对象的数据类型转换为所需的数据类型。 我们使用 int()、float()、str() 等预定义函数来执行显式类型转换。
int()强制转换为整型:
x = int(1) # x 输出结果为 1
y = int(2.8) # y 输出结果为 2
z = int("3") # z 输出结果为 3
float()强制转换为浮点型:
x = float(1) # x 输出结果为 1.0
y = float(2.8) # y 输出结果为 2.8
z = float("3") # z 输出结果为 3.0
w = float("4.2") # w 输出结果为 4.2
str()强制转换为字符串类型:
x = str("s1") # x 输出结果为 's1'
y = str(2) # y 输出结果为 '2'
z = str(3.0) # z 输出结果为 '3.0'
整型和字符串类型进行运算,就可以用强制类型转换来完成:
num_int = 123
num_str = "456"
print("num_int 数据类型为:",type(num_int))
print("类型转换前,num_str 数据类型为:",type(num_str))
num_str = int(num_str) # 强制转换为整型
print("类型转换后,num_str 数据类型为:",type(num_str))
num_sum = num_int + num_str
print("num_int 与 num_str 相加结果为:",num_sum)
print("sum 数据类型为:",type(num_sum))
out
num_int 数据类型为: <class 'int'>
类型转换前,num_str 数据类型为: <class 'str'>
类型转换后,num_str 数据类型为: <class 'int'>
num_int 与 num_str 相加结果为: 579
sum 数据类型为: <class 'int'>
以下几个内置的函数可以执行数据类型之间的转换。这些函数返回一个新的对象,表示转换的值。
| 函数 | 描述 |
|---|---|
| [int(x ,base]) | 将x转换为一个整数 |
| float(x) | 将x转换到一个浮点数 |
| [complex(real ,imag]) | 创建一个复数 |
| str(x) | 将对象 x 转换为字符串 |
| repr(x) | 将对象 x 转换为表达式字符串 |
| eval(str) | 用来计算在字符串中的有效Python表达式,并返回一个对象 |
| tuple(s) | 将序列 s 转换为一个元组 |
| list(s) | 将序列 s 转换为一个列表 |
| set(s) | 转换为可变集合 |
| dict(d) | 创建一个字典。d 必须是一个 (key, value)元组序列。 |
| frozenset(s) | 转换为不可变集合 |
| chr(x) | 将一个整数转换为一个字符 |
| ord(x) | 将一个字符转换为它的整数值 |
| hex(x) | 将一个整数转换为一个十六进制字符串 |
| oct(x) | 将一个整数转换为一个八进制字符串 |
空行
-
函数之间或类的方法之间用空行分隔,表示一段新的代码的开始。
-
类和函数入口之间也用一行空行分隔,以突出函数入口的开始。
-
空行与代码缩进不同:
- 空行并不是
Python语法的一部分。- 书写时不插入空行,Python 解释器运行也不会出错。
- 但是空行的作用在于分隔两段不同功能或含义的代码,便于日后代码的维护或重构。
记住:空行也是程序代码的一部分。
等待用户输入
执行下面的程序在按回车键后就会等待用户输入:
#!/usr/bin/python3
input("\n\n按下 enter 键后退出。\n")
以上代码中 ,\n\n 在结果输出前会输出两个新的空行。一旦用户按下 enter 键时,程序将退出。
同一行显示多条语句
Python可以在同一行中使用多条语句,语句之间使用分号;分割
demo
#!/usr/bin/python3
import sys; x = 'test'; sys.stdout.write(x + '\n')
使用脚本执行以上代码,输出结果为:
test
使用交互式命令行执行,输出结果为:
>>> import sys; x = 'test'; sys.stdout.write(x + '\n')
test
5
此处的 5 表示字符数,test 有 4 个字符,\n 表示一个字符,加起来 5 个字符。
多个语句构成代码组
-
缩进相同的一组语句构成一个代码块,我们称之代码组。
-
像if、while、def和class这样的复合语句,首行以关键字开始,以冒号(
:)结束,该行之后的一行或多行代码构成代码组。 -
我们将首行及后面的代码组称为一个子句(clause)。
if expression :
suite
elif expression :
suite
else :
suite
print 输出
print默认输出是换行的,如果要实现不换行需要在变量末尾加上 end="":
#!/usr/bin/python3
x="a"
y="b"
# 换行输出
print( x )
print( y )
print('---------')
# 不换行输出
print( x, end=" " )
print( y, end=" " )
print()
out
a
b
---------
a b
f-string格式输出
f-string格式输出
在Python编程过程中,字符串格式化是一个常见的任务。无论是在输出数据、生成报告还是调试信息时,使用合适的字符串格式化方法显得尤为重要。
Python为此提供了多种字符串格式化的方法,其中最受欢迎的当属f格式输出(f-strings)。
f格式输出是Python 3.6引入的一种字符串格式化方法。
它以"f"或"F"开头,并允许在字符串中嵌入表达式。
通过使用大括号{}将变量或表达式包裹起来,你可以直接在字符串中引用它们。
yy = None;
if yy is None :
xx=45; print(f"hello, xx :{xx}")
out :
hello, 45
f格式输出与其他字符串格式化方法相比,具有以下几个显著优势:
- 可读性高:通过直观的语法,变量和表达式的插入显得非常自然,使得代码的可读性大大提升。
- 效率高:f格式输出在性能上通常优于 %-formatting 和 str.format() 方法,尤其是在需要重复格式化的情况下。
- 支持复杂表达式:你不仅可以插入变量,还可以在大括号内进行复杂的表达式计算和调用函数。
- 样例:支持复杂表达式的示例
x = 5
y = 10
result = f"The sum of {x} and {y} is {x + y}."
print(result) # 输出: The sum of 5 and 10 is 15.
- 样例:格式化数字
pi = 3.14159265358979
formatted_pi = f"Pi is approximately {pi:.2f}."
print(formatted_pi) # 输出: Pi is approximately 3.14.
- 样例:列表与字典
# 列表
fruits = ["apple", "banana", "cherry"]
output = f"My favorite fruit is {fruits[1]}."
print(output) # 输出: My favorite fruit is banana.
# 字段
person = {"name": "Bob", "age": 25}
output = f"{person['name']} is {person['age']} years old."
print(output) # 输出: Bob is 25 years old.
import 与 from...import
import/from...import
- 在 python 用
import或者from...import来导入相应的模块。
- 将整个模块(
somemodule)导入,格式为:import somemodule
- 从某个模块中导入某个函数,格式为:
from somemodule import somefunction
- 从某个模块中导入多个函数,格式为:
from somemodule import firstfunc, secondfunc, thirdfunc
- 将某个模块中的全部函数导入,格式为:
from somemodule import *
- 导入 sys 模块
import sys
print('================Python import mode==========================')
print ('命令行参数为:')
for i in sys.argv:
print (i)
print ('\n python 路径为',sys.path)
- 导入 sys 模块的 argv,path 成员
from sys import argv,path # 导入特定的成员
print('================python from import===================================')
print('path:',path) # 因为已经导入path成员,所以此处引用时不需要加sys.path
命令行参数
- 很多程序可以执行一些操作来查看一些基本信息,Python可以使用
-h参数查看各参数帮助信息:
$ python -h
usage: python [option] ... [-c cmd | -m mod | file | -] [arg] ...
Options and arguments (and corresponding environment variables):
-c cmd : program passed in as string (terminates option list)
-d : debug output from parser (also PYTHONDEBUG=x)
-E : ignore environment variables (such as PYTHONPATH)
-h : print this help message and exit
[ etc. ]
传递参数方式 x5
1 位置传参
# 位置传递实例:
def fun1(a,b,c):
return a+b+c
print(fun1(1,2,3))
out
6
2 关键字传参
根据每个参数的名字写入函数参数
# 关键字传递
def fun2(a,b,c):
return a+b+c
print(fun2(1,c=3,b=2))
out
6
3 参数默认值传参
给函数的输入参数设定一个默认值,如果该参数最终没有输入,则使用默认参数出入函数.
# 默认值传递
def fun3(a,b=2,c=3):
return a+b+c
print(fun3(a = 1))
out
6
4 包裹传参
在定义函数时,我们有时候并不知道调用的时候会传递多少个参数。这时候,包裹(packing)【位置参数】或者【关键字参数】来进行参数传递会非常有用。
def fun4(*name):
print(type(name))
print(name)
fun4([1,2,3])
fun4((1,2,3))
fun4(1,2,3)
在fun4的参数表中,所有的参数被name收集,根据位置合并成一个元组(tuple),这就是包裹位置传递。
<class ‘tuple’>
([1, 2, 3],)
<class ‘tuple’>
((1, 2, 3),)
<class ‘tuple’>
(1, 2, 3)
5 解包裹传递
def func1(a,b=1,*c,**d):
print(a,b,c,d)
l = [3,4]
dic = {'@':2,'#':3}
func1(1,2,l,dic)
print("---------**------------")
func1(1,2,*l,**dic)
func1(1,2,3,4,**dic)
out
1 2 ([3, 4], {‘@’: 2, ‘#’: 3}) {}
---------**------------
1 2 (3, 4) {‘@’: 2, ‘#’: 3}
1 2 (3, 4) {‘@’: 2, ‘#’: 3}
X 参考文献
拷贝模式:浅拷贝 & 深拷贝
深拷贝和浅拷贝
- 浅拷贝:不拷贝子对象的内容,只是拷贝子对象的引用。
- 深拷贝:会连子对象的内存也全部拷贝一份,对子对象的修改不会影响源对象。
Python 对象赋值的深拷贝与浅拷贝
- 在 Python 中,对象赋值实际上是对象的引用。
当创建一个对象,然后把它赋值给另一个变量的时候,Python 并没有拷贝这个对象,而只是拷贝了这个对象的引用,我们称之为浅拷贝。
在 Python 中,为了使当进行赋值操作时,两个变量互补影响,可以使用copy模块中的deepcopy方法,称之为深拷贝。
Python 函数的参数传递: Python 函数的参数传递都是“引用传递”,不是“值传递”
- 【函数的参数传递】,本质上就是:从实参到形参的【赋值操作】。
Python 中“一切皆对象”,所有的赋值操作都是“引用的赋值”。
所以,Python 中参数的传递都是“引用传递”,不是“值传递”。
- 具体操作时分为两类:
- 对“可变对象”进行“写操作”,直接作用于原对象本身。
- 对“不可变对象”进行“写操作”,会产生一个新的“对象空间”,并用新的值填充这块空间。(起到其他语言的“值传递”效果,但不是“值传递”)
- 可变对象有:
字典、列表、集合、自定义的对象等
- 不可变对象有:
数字、字符串、元组、function 等
- 为了更深入的了解参数传递的底层原理,我们需要讲解一下“浅拷贝和深拷贝”。
我们可以使用内置函数:
copy(浅拷贝)、deepcopy(深拷贝)。
传递可变对象的引用
- 传递参数是可变对象,实际传递的还是对象的引用。在函数体中不创建新的对象拷贝,而是可以直接修改所传递的对象。(这个和
C语言中传递指针一样)
例如:列表、字典、自定义的其他可变对象等。
- 示例
``python
b = [10,20]
def f2(m):
print("m:",id(m)) #b 和 m 是同一个对象
m.append(30) #由于 m 是可变对象,不创建对象拷贝,直接修改这个对象b:
f2(b)
print("b:",id(b))
print(b)
> 执行结果:
```log
m: 45765960
b: 45765960
[10, 20, 30]
传递不可变对象的引用
- 传递参数是不可变对象,实际传递的还是对象的引用。在”赋值操作”时,由于不可变对象无法修改,系统会新创建一个对象。
不会修改原传入参数,在对传入的不可变对象进行修改操作时,会新建一个新的对象。
例如:int、float、字符串、元组、布尔值
- 示例
a = 100
def f1(n):
print("n:",id(n)) # 传递进来的是 a 对象的地址
n = n+200 # 由于 a 是不可变对象,因此创建新的对象 n
print("n:",id(n)) # n 已经变成了新的对象
print(n)
f1(a)
print("a:",id(a))
执行结果:
n: 1663816464
n: 46608592
300
a: 1663816464
显然,通过 id 值我们可以看到 n 和 a 一开始是同一个对象。给 n 赋值后,n 是新的对象。
传递【不可变对象】包含的【子对象是可变对象】的情况
- 示例
# 不可变对象
a = 100
def f1(n):
print("n:",id(n)) #传递进来的是 a 对象的地址
n = n+200 #由于 a 是不可变对象,因此创建新的对象 n
print("n:",id(n))
#n 已经变成了新的对象
# print(n)
f1(a)
print("a:",id(a))
out
a: 41611632
m: 41611632
(10, 20, [888, 6])
m: 41611632
(10, 20, [888, 6])
- 示例
# 浅拷贝和深拷贝
import copy
def testCopy():
'''测试浅拷贝'''
a = [10, 20, [5, 6]]
b = copy.copy(a)
print("a", a)
print("b", b)
b.append(30)
b[2].append(7)
print("浅拷贝......")
print("a", a)
print("b", b)
def testDeepCopy():
'''测试深拷贝'''
a = [10, 20, [5, 6]]
# 深拷贝
b = copy.deepcopy(a)
print("a", a)
print("b", b)
b.append(30)
b[2].append(7)
print("深拷贝......")
print("a", a)
print("b", b)
testCopy()
print("*************")
testDeepCopy()
out
a [10, 20, [5, 6]]
b [10, 20, [5, 6]]
浅拷贝…
a [10, 20, [5, 6, 7]]
b [10, 20, [5, 6, 7], 30]
“*************”
a [10, 20, [5, 6]]
b [10, 20, [5, 6]]
深拷贝…
a [10, 20, [5, 6]]
b [10, 20, [5, 6, 7], 30]
List对象的append()函数
- 当
list类型的对象进行append操作时,实际上追加的是该对象的引用。
对象的id()函数
- id() 函数:返回对象的唯一标识,可以类比成该对象在内存中的地址。
>>> alist = []
>>> num = [2]
>>> alist.append( num )
>>> id( num ) == id( alist[0] )
True
如上例所示,当
num发生变化时(前提是id(num)不发生变化),alist的内容随之会发生变化。往往会带来意想不到的后果,想避免这种情况,可以采用深拷贝解决:
alist.append( copy.deepcopy( num ) )
numpy 模块的深拷贝与浅拷贝
Y 参考文献
Y FAQ for Python
Q: Python工程中,如何安装自己写的模块?
- 要在 Python 中安装自己写的模块,有几种方法,具体取决于你的需求和模块的复杂度
方式1: setup.py + pip install + 本地模块
- 使用 pip 安装本地模块
如果你想要用 pip 安装自己的模块,可以将模块打包成标准格式。假设你的模块结构如下:
my_module/
├── my_module/
│ ├── __init__.py
│ └── my_script.py
├── setup.py
└── README.md
setup.py 是打包的关键文件,内容如下
from setuptools import setup, find_packages
setup(
name="my_module", # 模块名
version="0.1", # 版本号
packages=find_packages(), # 自动查找子包
install_requires=[], # 依赖库
description="My custom module",
author="Your Name",
author_email="your.email@example.com"
)
步骤:
- 在模块的根目录下(即 setup.py 所在的目录),打开终端。
- 运行以下命令:
pip install .这会将 my_module 安装到 Python 环境中,使其可以在任何地方导入。
- 使用 pip 本地链接安装
如果你在开发中不断修改模块,想要在更改后自动生效,可以使用 pip 的开发模式进行安装:
pip install -e .
此时安装的是模块的符号链接版本,修改源代码后无需重新安装。
重新安装的方式: (样例,如: 自定义的模块 autosar)
pip uninstall autosar
pip install .
- 手动复制文件
如果只是一个简单的
.py文件,可以直接将其放入 Python 项目的目录中,或者复制到 Python 的site-packages目录下。
- 使用 PYTHONPATH
可以将模块所在的路径添加到 PYTHONPATH 环境变量中。例如:
export PYTHONPATH=$PYTHONPATH:/path/to/your/module
这样可以直接在代码中导入模块。
方式2: project.toml + pip install + 本地模块
- 推荐文献/参考
Intro
最近打算构建一些开源工具套件,想着能不能把 ruff, darglint, mypy 这些 lint 工具全部 all in one 整合一下,化简配置流程,因此详细看了一下这些框架是怎么做 pyproject.toml 配置的。
在 Python 项目开发的历史长河中,我们经历了从 setup.py 到 requirements.txt,再到 setup.cfg 的变迁。
所以你可以看到到 python 会有各种各样的配置文件,属实有点头疼,各种工具链也到处配置,真的不让人省心...
而现在,pyproject.toml 的出现标志着 Python 项目管理进入了一个新的时代,本文会详细解读一下这个现代 Python 项目管理的核心配置文件。
为什么需要 pyproject.toml?
在传统的 Python 项目中,我们往往需要维护多个配置文件:
setup.py用于项目打包requirements.txt管理依赖setup.cfg存放项目元数据- 各种工具的配置文件(
.pylintrc、pytest.ini等)
这种分散的配置方式带来了几个问题:
- 配置分散,难以统一管理
- 不同文件格式增加学习成本
- 工具配置可能存在冲突
- 项目结构不够清晰
pyproject.toml 的出现就是为了解决这些问题。它提供了一个集中的、标准化的配置方式,让项目管理变得更加简单和清晰。
pyproject.toml 的标准之路
PEP 518:奠定基础
2016 年,PEP 518 提案定义了 pyproject.toml 文件的基本结构和构建系统规范。这个提案主要解决了 Python 项目构建时的依赖问题,让构建过程变得更加可靠。
Link: https://peps.python.org/pep-0518/
PEP 621:统一项目元数据
2020 年,PEP 621 进一步规范化了项目元数据的格式,使得不同的构建后端都能以统一的方式处理项目信息。
Link: https://peps.python.org/pep-0621/
pyproject.toml 的核心结构
1. 构建系统配置
[build-system]
requires = ["setuptools>=42", "wheel"]
build-backend = "setuptools.build_meta"
这部分定义了构建项目所需的工具和后端。
2. 项目元数据
[project]
name = "your-awesome-project"
version = "0.1.0"
description = "一个很棒的项目"
authors = [
{name = "作者名", email = "author@example.com"}
]
dependencies = [
"requests>=2.24.0",
"pandas>=1.0.0"
]
这里包含了项目的基本信息和依赖要求。
3. 开发依赖和可选功能
[project.optional-dependencies]
dev = ["pytest", "black", "mypy"]
docs = ["sphinx", "sphinx-rtd-theme"]
你可以定义不同场景下需要的额外依赖。
4. 工具配置
[tool.black]
line-length = 88
target-version = ['py37']
[tool.isort]
profile = "black"
[tool.pytest.ini_options]
minversion = "6.0"
addopts = "-ra -q"
各种开发工具的配置都可以统一在这里管理。
现代化工具支持
现代 Python 项目管理工具都对 pyproject.toml 提供了很好的支持:
自定义配置信息
如果你有一些自己的配置信息,自己读取 pyproject.toml 也很简单,就像读取 json,yaml 一样,下面是一个示例代码:
import tomli # For Python < 3.11
# For Python 3.11+, you can use: import tomllib
def read_pyproject_toml(file_path="pyproject.toml"):
"""
读取并解析 pyproject.toml 文件
Args:
file_path (str): pyproject.toml 文件的路径
Returns:
dict: 解析后的 TOML 内容
"""
try:
with open(file_path, mode="rb") as fp:
# 使用 rb (二进制读取模式) 来避免编码问题
toml_dict = tomli.load(fp)
return toml_dict
except FileNotFoundError:
print(f"错误: 找不到文件 '{file_path}'")
return None
except Exception as e:
print(f"解析 TOML 文件时出错: {str(e)}")
return None
def print_project_info(toml_dict):
"""
打印项目主要信息
Args:
toml_dict (dict): 解析后的 TOML 字典
"""
if not toml_dict:
return
# 打印项目基本信息
if "project" in toml_dict:
project = toml_dict["project"]
print("项目信息:")
print(f"名称: {project.get('name', '未指定')}")
print(f"版本: {project.get('version', '未指定')}")
print(f"描述: {project.get('description', '未指定')}")
print(f"作者: {project.get('authors', ['未指定'])}")
# 打印依赖信息
if "dependencies" in project:
print("\n依赖项:")
for dep in project["dependencies"]:
print(f"- {dep}")
# 打印构建系统信息
if "build-system" in toml_dict:
build_system = toml_dict["build-system"]
print("\n构建系统:")
print(f"构建后端: {build_system.get('build-backend', '未指定')}")
print(f"依赖项: {build_system.get('requires', [])}")
def main():
# 读取并解析 TOML 文件
toml_dict = read_pyproject_toml()
if toml_dict:
# 打印完整的解析结果
print("完整的 TOML 内容:")
print(toml_dict)
print("\n" + "="*50 + "\n")
# 打印格式化的项目信息
print_project_info(toml_dict)
if __name__ == "__main__":
main()
需要注意的是:
- Python < 3.11 需要安装
tomli:pip install tomli - Python 3.11+ 可以直接使用内置的
tomllib
至此,大致就可以理解各种工具链是如何配置的自己的参数了,当然如何更好地配置,还是要看官方文档(虽然有些文档真的写的很烂,如 darglint)。
Y 推荐文献
- Python
- 菜鸟教程
X 参考文献
QPython OH: Qpython是一个轻量级的、成熟的python编程工具。它配有终端和简单的代码编辑器。它支持安装第三方库。目前,它支持Python 3.6.6,这还不算太老。Aid Learning: 一款很酷的高端移动编程工具,可以直接在app Store中下载和安装。- 现代 Python 项目管理:pyproject.toml 完全指南 - Zhihu

本文链接: https://www.cnblogs.com/johnnyzen
关于博文:评论和私信会在第一时间回复,或直接私信我。
版权声明:本博客所有文章除特别声明外,均采用 BY-NC-SA 许可协议。转载请注明出处!
日常交流:大数据与软件开发-QQ交流群: 774386015 【入群二维码】参见左下角。您的支持、鼓励是博主技术写作的重要动力!

 浙公网安备 33010602011771号
浙公网安备 33010602011771号