解密Prompt系列64. Anthropic Skils的延伸思考
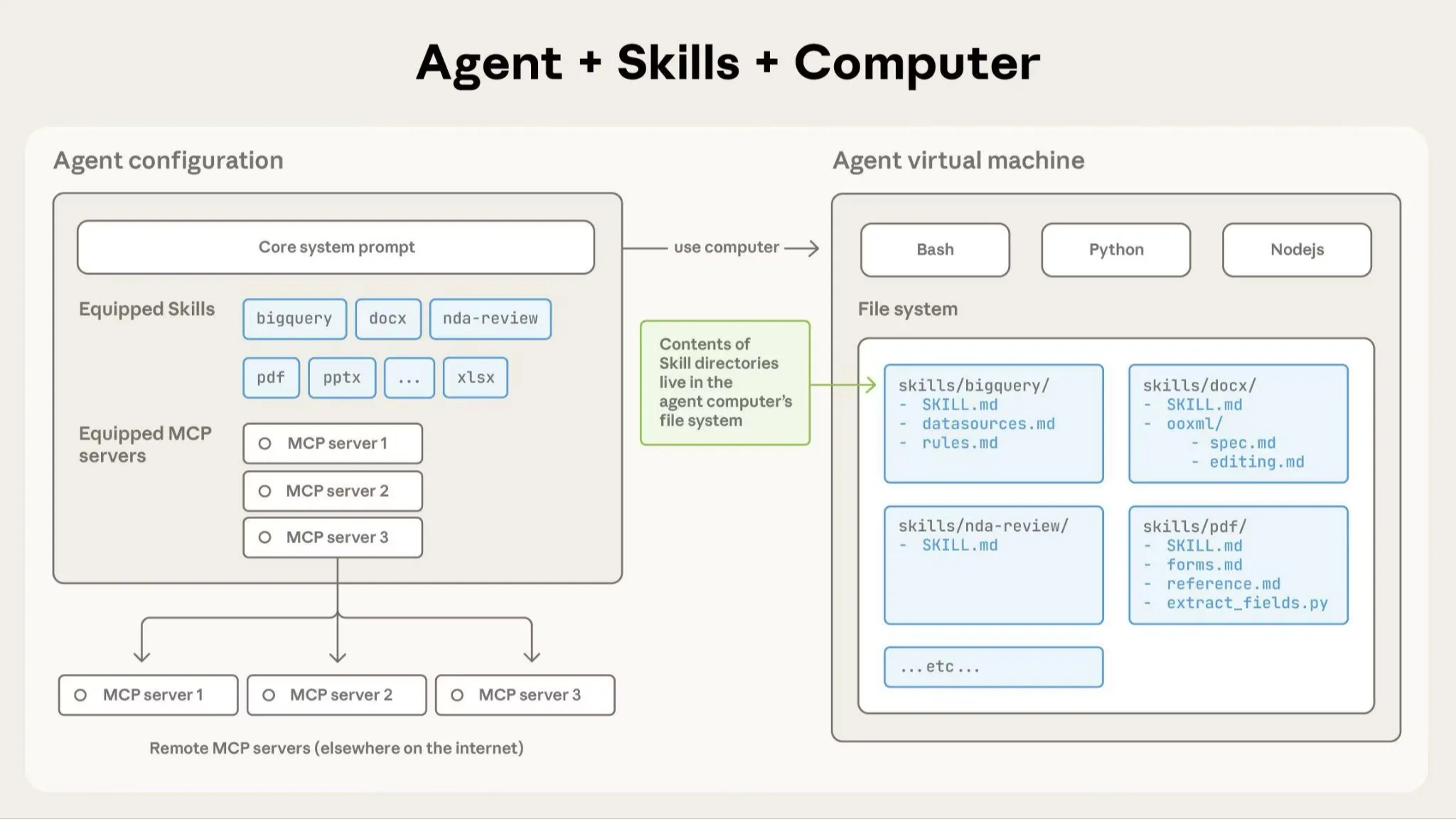 本文将深入解构 SKILLS 的三层分层加载架构,探讨它如何解决传统 Agent 上下文膨胀、领域任务成功率低的核心痛点。我们将通过一个完整流程展示 SKILLS 如何工作,并延伸思考它对现有 MCP、工作流和多智能体范式带来的冲击与重构可能。
本文将深入解构 SKILLS 的三层分层加载架构,探讨它如何解决传统 Agent 上下文膨胀、领域任务成功率低的核心痛点。我们将通过一个完整流程展示 SKILLS 如何工作,并延伸思考它对现有 MCP、工作流和多智能体范式带来的冲击与重构可能。
💡 文章摘要 Anthropic SKILLS 看着只是一堆提示词和脚本,但其精妙在于“大道至简”。本文将深入解构 SKILLS 的三层分层加载架构,探讨它如何解决传统 Agent 上下文膨胀、领域任务成功率低的核心痛点。我们将通过一个完整流程展示 SKILLS 如何工作,并延伸思考它对现有 MCP、工作流和多智能体范式带来的冲击与重构可能。同时,我们也会探讨 SKILLS 在工程实践中面临的挑战,如性能、安全和评估。
🎯SKILL是什么?三层拆解看本质
从表面看,一个Skill非常简单:它就是一个文件夹。
这个文件夹里通常包含:
- SKILL.md(必备):一个Markdown文件。这是Skill的“说明书”或“SOP”。它用自然语言告诉Claude“如何一步步完成某个特定任务”。
- SKILL中包含元数据,告诉模型这个说明书是完成什么任务用的,如下
--- name: pdf-processing description: 提取PDF文本和表格,填写表单...当用户提到PDF时使用。 ---
- SKILL中包含元数据,告诉模型这个说明书是完成什么任务用的,如下
- 弹药库(可选):
- 脚本(scripts/):例如
fill_form.py,是可执行代码,用于处理LLM不擅长或无法完成的确定性任务。 - 其他文档(.md, .txt):例如
API_REFERENCE.md或BRAND_GUIDELINES.md。这些是更深入的“参考资料”,支持模型按需读取。 - 模板(templates/):例如
company_report.pptx、viewer.html是模型完成特定任务的模版。
- 脚本(scripts/):例如
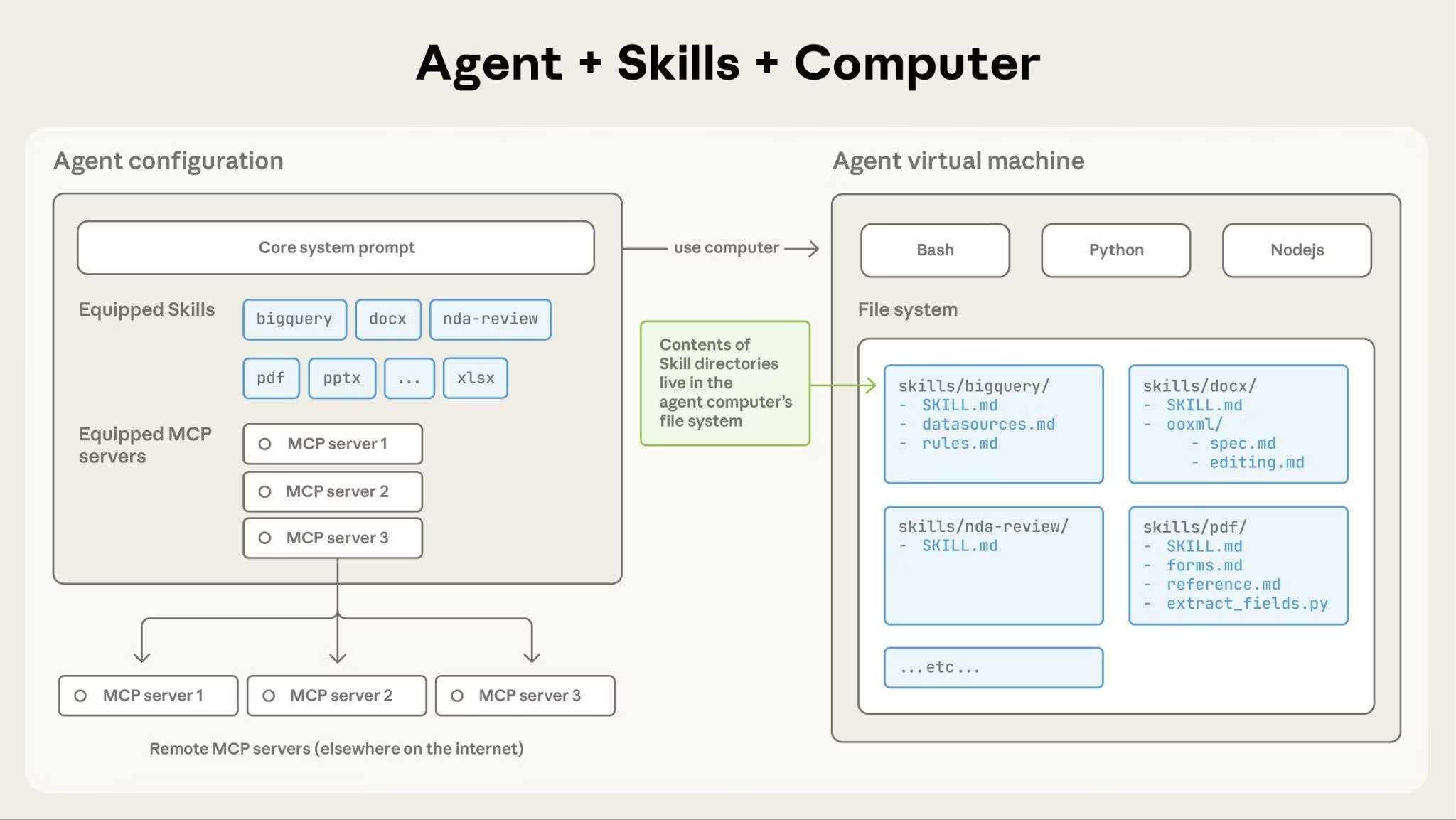
从技术本质来看,SKILLS 的核心创新在于其分层加载机制
┌─────────────────────────────────────────┐
│ Level 1: 元数据(启动时加载) │
│ name + description (~100 tokens) │
│ ✓ 轻量级发现机制 │
└─────────────────────────────────────────┘
↓ 触发时才读取
┌─────────────────────────────────────────┐
│ Level 2: 主指令(SKILL.md body) │
│ 工作流、最佳实践 (<5k tokens) │
│ ✓ 按需加载到上下文 │
└─────────────────────────────────────────┘
↓ 引用时才访问
┌─────────────────────────────────────────┐
│ Level 3: 资源与脚本 │
│ • 额外 markdown(指令) │
│ • Python脚本(可执行直接执行) │
│ • 参考资料(schema、模板) │
│ ✓ 无限量存储,零上下文开销,固定执行效果 │
└─────────────────────────────────────────┘
🔧SKILLS 解决了哪些痛点?
理解了 SKILLS 的分层设计,它所针对的传统 Agent 框架痛点就非常清晰了。SKILLS 主要解决了传统 Agent 框架的以下痛点:
- 智能体上下文无限膨胀:
让我们以金融数据查询智能体为例,它的上下文主要来自几个方面
- 核心指令:如何查宏观数据、个股基本面、技术面...
- 海量资料:超级多的表描述和字段描述。
- 后续操作:如何建模、如何可视化...
在原始的智能体框架下,还没开始任务,上下文就可能“几万字”了。
而在SKILL的加持下,我们可以把每一类数据查询逻辑封装成一个SKILLS,例如宏观数据查询.md。这样在最初的system prompt,我们主需要加载有哪些SKILLS的元数据。当用户提问涉及到宏观数据时,再把对应SKILL.md加载到上下文中。当需要具体查询货币政的时候再进一步读取细分参考材料reference/monetary_policy.md 。
脚本化的本质是将确定性任务从 LLM 推理中剥离。
这一点在处理数据时尤其明显。如果 Agent 要把上一步返回的 CPI 时间序列数据可视化,传统做法是把冗长的数据 作为文本 传递给下一个绘图工具(例如 Echart),这个“Copy”过程会消耗海量 Token。
而 SKILLS 提供了 scripts 方案:代码化 + 文件化。数据通过文件 (cpi.csv) 传递,模型只需推理出一行调用指令,如 python ts_visualize.py --file cpi.csv。整个可视化或建模过程几乎不占用模型上下文。
- 领域任务完成成功率低
领域任务完成率低一般来自两个方面
- 领域数据在整体训练中的频率更低,模型训练的不充分
- 领域本身有大量主观流程和“专家经验”(哈哈,专家们总觉得自己那套最棒)。
SKILLS 通过标准化工作流程(SOP)有效提升领域任务完成率。
这两种情形都可以通过SKILLS提供工作流程说明来提升任务完成效果。但其实在使用时需要注意粒度和任务特性。SKILLS这里提供的其实就是类似前面Memory中我们提到的“Procedural Knowledge”程序性知识,告诉模型当你遇到X情况的时候,第一步做A,第二步做B。
而和领域的契合点在于,公司可以把固有的SOP(如销售物料如何写、个股基本面如何分析)固化到 SKILLS 中。
- 固定流程任务完成稳定性低
对于极致“一致性”要求的任务,不能依赖模型100%的指令遵从,这时scripts的价值就凸显了:
让我们来举两个例子
- 对于投研报告的生成:个股基本面分析的标准指标计算固化为脚本
- 对于营销物料的设计:公司配色和风格通过template固化
脚本提供了无论执行多少次都相同的结果,这才是稳定性的终极保障。
🤖 如何工作?Agent完整的“内心戏”
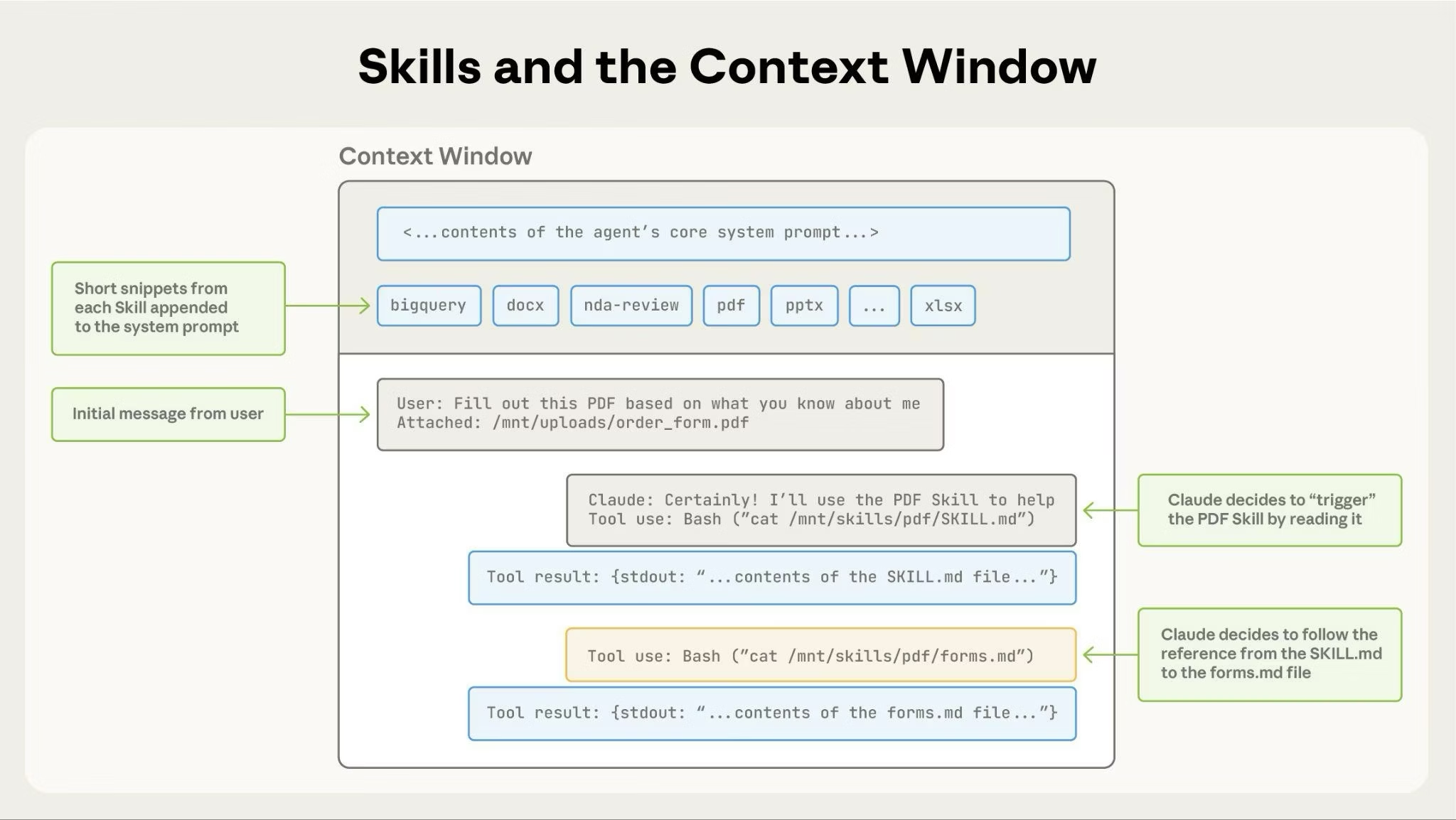
让我们通过一个具体场景,看看Agent使用SKILL的完整流程。这里我们降低对Claude的依赖,以更通用的skill使用为例。
场景:你是一个数据分析Agent,已经安装了"data-analysis" Skill。
- 阶段 1:启动 (Startup & Preload)
- Agent启动,同时启动可访问文件系统的沙箱VM
- 扫描skills/目录,读取所有SKILL的元数据(L1)
- 构建渐渐的系统提示:Agent的System Prompt现在包含如下内容:
可用技能:
- name: data-analysis
- description: 用于数据清洗、分析和可视化。当用户提到CSV、Excel或数据库时使用。
- 阶段 2:对话与触发 (Trigger & Load)
- 用户:“分析一下sales.csv,找出TOP 3销售”
- LLM推理:匹配用户请求与data-analysis技能描述,生成工具调用:
read /mnt/skills/data-analysis/SKILL.md
- 工具输出 & 上下文更新:VM执行read命令,并把工具返回结果也就是SKILL.md的内容补充到当前对话的上下文中。
# Data Analysis Workflow
1. **Load Data**: Use pandas.read_csv() to load the file.
2. **Inspect**: Always print the .head() and .info() first.
3. **Clean**: Check for nulls using .isnull().sum().
4. **Execute**: For complex tasks, use the `scripts/analyze.py` script...
- 阶段 3:执行与推理 (Execute & Reason)
- LLM推理:模型基于更新的上下文进行推理,例如按照说明第一步是加载数据并检查,如果SKILL内部提供已经写好的通用数据EDA的脚本
scripts/inspect_data.py如下
import pandas as pd
def inspect_data(file_name):
df = pd.read_csv(file_name)
print(df.head().to_string())
print(df.info())
print(df.describe())
- 生成脚本调用代码:则模型会生成工具调用来执行对应的脚本代码
python scripts/inspect_data.py --file sale_data.csv - 工具输出 & 上下文更新:VM会执行python代码,并把数据观测的结果更新到上下文,例如
(stdout from python):
SalesID Amount Salesperson
0 1 500 Alice
- LLM继续推理:模型获得DataFrame的head后会继续推理,例如进行数据分析,可以进一步调用数据分析的脚本代码进行例如单因子分析
python scripys/analyze.py --file sale.csv --type single_factor - 循环往复
🧐 实践中的挑战与深入思考
但在实际使用中,你还需要考虑几个工程问题:
- 增加工具推理步骤带来延时: SKILLS的渐进式加载并非完全没有成本,每一次加载都需要一次工具调用,因此需要平衡SKILLS能提供的效率提升,以及增加工具调用的延时。【所以沙箱需要提供很详细的指标监控来进行工程优化,包括SKILL调用数、节省token数etc】
- 何时把SKILL从上下文卸载:哈哈,Claude 的文档只提了加载,没提卸载。动态加载进去了,不卸载不还是会撑爆上下文吗?在长任务中,卸载逻辑至关重要。卸载早了,下次用还得重载;卸载晚了,占用上下文,还可能导致 SKILL 间指令冲突。【可以考虑对SKILL进行多级分层,cold、warm、hot之类,支持不同offload策略】
- SKILL发现和召回:和MCP工具描述相同,SKILL的meta描述直接决定了模型能否在需要时正确、及时加载说明书。【全面的SKILL测试和验证是必要的,MCP也是一样。】
- SKILL增加带来的指令冲突:当 SKILLS 库膨胀时,多个 SKILL 之间的指令可能冲突,scripts 之间可能存在命名空间或依赖冲突。如果自由过了火~~~【提供基于AI的一键优化和生成方案】
💡 更多切入视角
那SKILLS的引入,对之前的MCP,以n8n、Dify、coze为代表的固定工作流,和以MCP + langgraph为代表的自主智能体,有什么影响和改变呢?
脚本化 & 文件化 - 重构部分MCP
这里非替代逻辑,而是从scripts的角度重新考虑一些MCP的设计。
-
高数据输入工具:对于数据处理类 MCP(如绘图、分析、建模),调用时必须把全部数据作为输入 Token 传递。而“文件化”后,只需传递文件名。
-
固定 Coding 任务:对于文件转换(如 HTML2PPTX)、固定设计(如海报模板)等任务,与其依赖模型每次生成不稳定且冗长的代码,不如把流程固化成
scripts或templates直接执行。
可控性 & 稳定性 - 替代部分工作流
为什么在模型能力很强的今天,公司里还在跑大量固定工作流?核心是可控性和稳定性。
SKILLS 正在切入这个领域。对于流程的控制,依赖模型对 SKILLS.md 的指令遵从;对于模型无法理解或不该理解的“玄学”(如量化阈值、销售话术、公司内部系统操作脚本),可以打包放入 scripts 里。
整体上,SKILLS 更适合那些 “在固化中需要一些灵活性” 的任务。对于完全固化、简单的任务流,个人感觉还是拖拉拽的平台对于非技术同学的上手成本更低。
可扩展 & 可组合 - 替代部分多智能体
当前多智能体(Multi-Agent)框架的初衷之一就是系统指令隔离。
例如,一个 Planner Agent 为了不让自己(主智能体)的 System Prompt 过于臃肿,会把“如何搜索”、“如何查询数据库”等复杂逻辑(及其对应的长 Prompt)剥离到子智能体中。
而 SKILLS 几乎完美解决了这个痛点。每个技能的相关说明,都可以通过 SKILL 进行动态加载和卸载。只有当需要时,才把 SOP 加载到上下文中。
优点:相比子智能体模式,SKILLS 模式下上下文共享更完整。子智能体的执行效果极大依赖主智能体传递指令的清晰度,而 SKILLS 是在主智能体的完整上下文中执行 SOP。
缺点:需要更好的上下文管理(如前面提到的卸载机制),以保证主智能体的上下文依然干净。
关于Anthropic SKILLS我们就聊这么多,后面该看看Computer-USE Agent最近有什么新进展了~

 浙公网安备 33010602011771号
浙公网安备 33010602011771号