java IO(三):字符流
字符流按字符个数输入、输出数据。
1.Reader类和FileReader类
Reader类是字符输入流的超类,FileReader类是读取字符的便捷类,此处的便捷是相对于其父类(另一个字符输入流)InputStreamReader而言的。
read()每单字符读取:
import java.io.*;
public class FileR {
public static void main(String[] args) throws IOException {
FileReader fr = new FileReader("D:/temp/hello.txt");
int ch = 0;
while((ch=fr.read())!=-1) {
System.out.println((char)ch);
}
fr.close();
}
}
read(char[] c)读取字符缓冲到字符数组:
import java.io.*;
public class FileR {
public static void main(String[] args) throws IOException {
FileReader fr = new FileReader("D:/temp/hello.txt");
int len = 0;
char[] buf = new char[1024];
while ((len=fr.read(buf))!=-1) {
System.out.println(new String(buf,0,len)); //字符数组转换为字符串输出
}
fr.close();
}
}
2.Writer类和FileWriter类
Writer类是字符输出流的超类,FileWriter类是输出字符的便捷类,此处的便捷是相对于其父类(另一个字符输出流)InputStreamWriter而言的。
import java.io.*;
public class FileW {
public static void main(String[] args) throws IOException {
FileWriter fw = new FileWriter("d:/temp/hellow.txt");
fw.write("a你好,谢谢,再见!");
fw.flush(); //尽量每write一次就flush一次
fw.close();
}
}
flush()和close()的注意点:
(1).close()自带flush(),它在关闭流之前会自动先flush()一次。
(2).flush()后流还能继续使用,而close()后流就被关闭不可再被使用。
(3).为了防止数据丢失,应尽量每write一次就flush一次。但最后一次可不用flush(),因为close()自带flush()。
3.InputStreamReader类和OutputStreamWriter类
FileReader和FileWriter分别是InputStreamReader和OutputStreamWriter的便捷类,便捷类的意思是前两个类可以简化后两个类,同时又能达到相同的目的。实际上,FileReader和FileWriter是InputStreamReader和OutputStreamWriter的子类,等价于它们的默认形式。
InputStreamReader、OutputStreamWriter可以看作是字节流和字符流之间的桥梁。前者将字符按照字符集转换为字节(二进制格式)并读取字符,这称为编码(例如:a->97(01100001));后者将字节(二进制格式)按照字符集转换为字符并写入字符,这称为解码(例如:97(01100001)->a)。
InputStreamReader、OutputStreamWriter的默认字符集采用的是操作系统的字符集,对于简体中文的Windows系统,默认采用的是GBK字符集。
以下是OutputStreamWriter以utf-8编码格式写入字符的示例:
import java.io.*;
public class OutputStreamW {
public static void main(String[] args) throws IOException {
WriteCN();
}
public static void WriteCN() throws IOException {
OutputStreamWriter osw =
new OutputStreamWriter(new FileOutputStream("d:/temp/hellow.txt"),"utf-8");
//new OutputStreamWriter(new FileOutputStream("d:/temp/hellow.txt"));//采用默认gbk字符集写入
osw.write("a你好,谢谢,再见!!!");
osw.flush();
osw.close();
}
}
以下是InputStreamReader读取上述文件d:\temp\hellow.txt中字符的示例,因为hellow.txt中的字符编码为UTF-8,因此读取时必须也也utf-8读取。假如以默认的gbk字符集读取,由于每次读取2个字节,将会把utf-8字符(中文字符占用3个字节)切分开导致乱码:
import java.io.*;
public class InputStreamR {
public static void main(String[] args) throws IOException {
ReadCN();
}
public static void ReadCN() throws IOException {
InputStreamReader isr =
new InputStreamReader(new FileInputStream("d:/temp/hellow.txt"),"utf-8");
// new InputStreamReader(new FileInputStream("d:/temp/hellow.txt"));//默认字符集,乱码
/* int ch = 0;
while ((ch=isr.read())!=-1) {
System.out.println((char)ch);
} */
int len = 0;
char[] buf = new char[1024];
while ((len=isr.read(buf))!=-1) {
System.out.println(new String(buf,0,len));
}
isr.close();
}
}
4.字节流、字符流的关系(编码、解码、编码表(字符集))
首先说明编码、解码和编码表(字符集)的关系。
编码:将字符根据编码表转换为二进制的0/1数字。
解码:将二进制根据编码表转换为字符。
编码表:
1.ascii码表:使用一个字节中的7位二进制就能表示字母、数字、英文标点等字符。
2.iso8859-1码表:(也即latin-1),使用一个字节中的8位二进制,其内包含了ascii码表中的字符,此外还扩展了欧洲一些语言的字符。
3.GB2312:中国自编的编码表,2个字节,两个字节都是负数,收录了6700多个汉字。兼容ascii。
GBK:K代表扩展的意思,是GB2312的扩展,占用2字节,大部分两个字节都是负数,但少数几个字符的第二个字节是正数,其内包含了GB2312的码表,收录了2万多个汉字。
GB18030:新的编码表,变长(可能1、2、4字节),其内包含了GB2312和GBK的码表,收录了7万多个汉字。
4.Unicode:收录了全世界几乎所有的字符,但无论什么字符都占用2个字节,不足两个字节的0占位。
5.UTF-8:解决了unicode的缺点,它使用变长1-4字节来表示一个字符(空间能省则省),其中ascii部分仍占用1个字节(仍兼容ascii)。和Unicode不同的是,UTF-8中的中文字符占用3个字节。
因此,需要知道的是:
- (1)所有字符集都兼容ascii码表;
- (2)一般考虑字符集时,需要考虑的码表大致分:ascii、latin-1、GBK、utf-8。
- (3)不同码表之间,因为编码、解码规则不一样,会导致文本乱码问题。
- (4)GBK不会和ascii冲突。因为GBK即使有正数的字节,也一定是在第二个字节。因为解码时,如果读取的第一个字节为正数,则一定是ascii字符,如果读取的第一个字节为负数,则一定是中文字符,此时会继续读取下一个字节。
- (5)以上都是文本的编码、解码。除了文本,还有媒体类数据,它们都有各自的编码、解码规则。实际使用过程中,采用什么方式编码、解码,取决于打开文件的程序,例如不能用记事本类程序打开媒体类(图片、音频、视频等)文件,不能用视频播放器打开文本文件。
再来说明字符流和字节流的关系,也就是实现字符流的原理。
对于字符串"abcde",使用字节流能够很轻松地读取、写入,但对于字符串"a你好,谢谢,再见!"这样的中文字符(假设它们是gbk编码的),无论是采用字节流的单字节读取还是以字节数组读取多个字节的方式都很难实现读取、写入。例如,一次读取2个字节,则第一次读取的两个字节为a和"你"的前一个字节,a的ascii码为97,"你"的前一个字节也是一个数值,假如为196,gbk对196也有对应的编码,假设对应的字符为"浣",于是第一次的两个字节经过解码,得到"a浣",而非"a你",这已经乱码了。而且很多时候,编码表中有某些数值并没有对应的字符,这时看到的就是乱七八糟的符号。
如果采用字符流读取、写入字符,则会先将其转换为字节数组,再对字节数组中的字节进行编码、解码。也就是说,字符流的底层还是字节流。而且根据不同的编码表(字符集),转换为字节存储到字节数组中时,数值和占用字节数也是不一样的。
以InputStreamReader和OutputStreamWriter这两个字符流按照utf-8字符集解析"你好"两个字符为例。
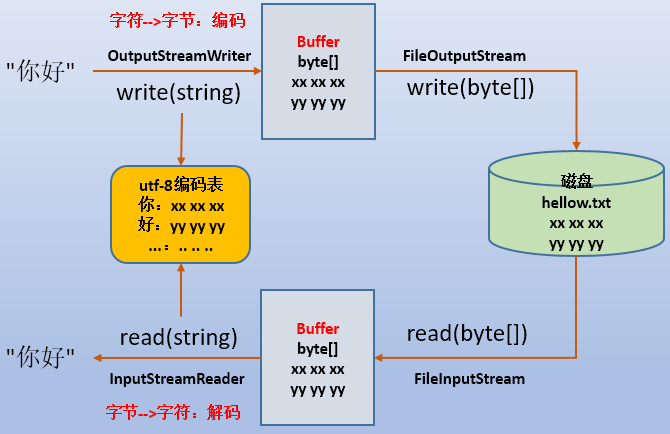
5.InputStreamReader/OutputStreamWriter和FileReader/FileWriter的区别
FileReader/FileWriter类是InputStreamReader/OutputStreamWriter类的子类,它们都能处理字符。区别是前者是后者的便捷类,是后者的默认形式。
也就是说,当InputStreamReader/OutputStreamWriter采用默认字符集时,它们和FileReader/FileWriter是等价的。即以下三条代码是等价的。
InputStreamReader isr = new InputStreamReader(new FileInputStream("a.txt")); //默认字符集
InputStreamReader isr = new InputStreamReader(new FileInputStream("a.txt"),"gbk"); //指定为默认字符集
FileReader fr = new FileReader("a.txt"); //使用便捷类FileReader
所以,如果采用的是默认字符集,最佳方式是采用FileReader/FileWriter,但如果需要指定字符集,则必须使用InputStreamReader/OutputStreamWriter。
6.字符流复制文本类文件
import java.io.*;
public class CopyFileByChar {
public static void main(String[] args) throws IOException {
copy("d:/temp/big.log","d:/temp/big_bak.log");
}
public static void copy(String src,String dest) throws IOException {
//字符集必须设置正确
InputStreamReader isr = new InputStreamReader(new FileInputStream(src),"gbk");
OutputStreamWriter osw = new OutputStreamWriter(new FileOutputStream(dest),"gbk");
int len = 0;
char[] buf = new char[1024];
while((len=isr.read(buf))!=-1) {
osw.write(buf,0,len);
osw.flush();
}
osw.close();
isr.close();
}
}
7.操作行:BufferedReader类BufferedWriter类
它们是缓冲类字符流,分别用于创建带有输入、输出缓冲区的输入、输出字符流。
其实和字符数组的作用差不多,只不过设计为缓冲类后可以使用类的一些方法,最常用的是操作行的方法:
- BufferedReader的readLine()方法:读取一行数据。只要遇到换行符(\n)、回车符(\r)都认为一行结束。当读取到流末尾时返回null。
- BufferedWriter的newLine()方法:写入一个换行符。
例如,下面是用这两个类来复制文本文件d:\temp\big.log。
import java.io.*;
public class CopyByBuffer {
public static void main(String[] args) throws IOException {
copy("d:/temp/big.log","d:/temp/big_bak.log");
}
public static void copy(String src,String dest) throws IOException {
// src buffer & dest buffer
InputStreamReader isr = new InputStreamReader(new FileInputStream(src),"gbk");
BufferedReader bufr = new BufferedReader(isr);
OutputStreamWriter osw = new OutputStreamWriter(new FileOutputStream(dest),"gbk");
BufferedWriter bufw = new BufferedWriter(osw);
String line = null;
while((line=bufr.readLine())!=null) {
bufw.write(line); //此write()方法继承自Writer的write(String str),而非重写后的write()
bufw.newLine();
bufw.flush();
}
bufw.close();
bufr.close();
}
}
对于大文件来说,这BufferedReader类操作数据其实比字符数组的速度要慢,因为每次缓冲一行,一行才不到1k而已(除非行很长),而char[]通常都设置为好几k,一次就能读很多行。
注:若您觉得这篇文章还不错请点击右下角推荐,您的支持能激发作者更大的写作热情,非常感谢!
Linux系列文章:https://www.cnblogs.com/f-ck-need-u/p/7048359.html
Shell系列文章:https://www.cnblogs.com/f-ck-need-u/p/7048359.html
网站架构系列文章:http://www.cnblogs.com/f-ck-need-u/p/7576137.html
MySQL/MariaDB系列文章:https://www.cnblogs.com/f-ck-need-u/p/7586194.html
Perl系列:https://www.cnblogs.com/f-ck-need-u/p/9512185.html
Go系列:https://www.cnblogs.com/f-ck-need-u/p/9832538.html
Python系列:https://www.cnblogs.com/f-ck-need-u/p/9832640.html
Ruby系列:https://www.cnblogs.com/f-ck-need-u/p/10805545.html
操作系统系列:https://www.cnblogs.com/f-ck-need-u/p/10481466.html
精通awk系列:https://www.cnblogs.com/f-ck-need-u/p/12688355.html

 浙公网安备 33010602011771号
浙公网安备 33010602011771号