python列表类型
列表类型简介
列表类型是一个容器,它里面可以存放任意数量、任意类型的数据。
例如下面的几个列表中,有存储数值的、字符串的、内嵌列表的。不仅如此,还可以存储其他任意类型。
>>> L = [1, 2, 3, 4]
>>> L = ["a", "b", "c", "d"]
>>> L = [1, 2, "c", "d"]
>>> L = [[1, 2, 3], "a", "b", [4, "c"]]
python中的列表是一个序列,其内元素是按索引顺序进行存储的,可以进行索引取值、切片等操作。
列表结构
列表是可变对象,可以原处修改列表中的元素而不会让列表有任何元数据的变动。
>>> L = ["a", "b", "c"]
>>> id(L), id(L[0])
(57028736, 55712192)
>>> L[0] = "aa"
>>> id(L), id(L[0])
(57028736, 56954784)
从id的变动上看,修改列表的第一个元素时,列表本身的id没有改变,但列表的第一个元素的id已经改变。
看了下面列表的内存图示就很容易理解了。
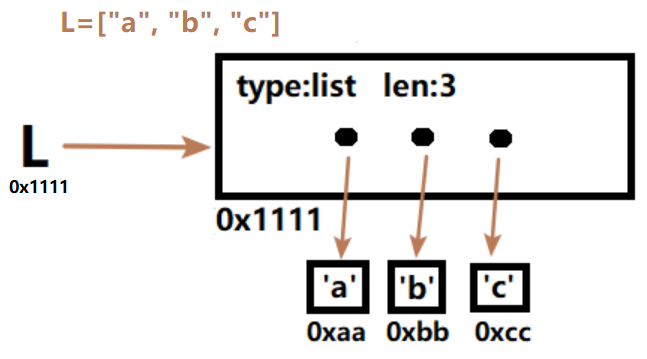
上面是L = ["a", "b", "c"]列表的图示。变量名L存储了列表的内存地址,列表内部包含了类型声明、列表长度等元数据,还保存了属于列表的3个元素的内存地址。需要注意的是,列表元素不是直接存在列表范围内的,而是以地址的形式保存在列表中。
所以,修改列表中的元素时,新建一个元素"aa"(之所以新建,是因为字符串是不可变类型),列表本身并没有改变,只是将列表中指向第一个元素的地址改为新数据"aa"的地址。
因为修改列表数据不会改变列表本身属性,这种行为称为"原处修改"。
所以,列表有几个主要的的特性:
- 列表中可以存放、嵌套任意类型的数据
- 列表中存放的是元素的引用,也就是各元素的地址,因此是列表可变对象
- 列表是可变序列。所以各元素是有位置顺序的,可以通过索引取值,可以通过切片取子列表
构造列表
有两种常用的构造列表方式:
- 使用中括号
[] - 使用list()构造方法
使用(中)括号构建列表时,列表的元素可以跨行书写,这是python语法中各种括号类型的特性。
例如:
>>> [] # 空列表
>>> [1,2,3]
[1, 2, 3]
>>> L = [
1,
2,
3
]
>>> list('abcde')
['a', 'b', 'c', 'd', 'e']
>>> list(range(0, 4))
[0, 1, 2, 3]
上面range()用于生成一系列数值,就像Linux下的seq命令一样。但是range()不会直接将数据生成出来,它返回的是一个可迭代对象,表示可以一个一个地生成这些数据,所以这里使用list()将range()的数据全部生成出来并形成列表。
中括号方式构造列表有一个很重要的特性:列表解析,很多地方也称为"列表推到"。例如:
>>> [x for x in 'abcdef']
['a', 'b', 'c', 'd', 'e', 'f']
list()是直接将所给定的数据一次性全部构造出来,直接在内存中存放整个列表对象。列表推导方式构造列表比list()要快,且性能差距还挺大的。
列表基本操作
列表支持+ *符号操作:
>>> L = [1,2,3,4]
>>> L1 = ['a','b','c']
>>> L + L1
[1, 2, 3, 4, 'a', 'b', 'c']
>>> [1,2] + list("34")
[1, 2, '3', '4']
>>> L * 2
[1, 2, 3, 4, 1, 2, 3, 4]
>>> 2 * L
[1, 2, 3, 4, 1, 2, 3, 4]
可以通过+=的方式进行二元赋值:
>>> L1 = [1,2,3,4]
>>> L2= [5,6,7,8]
>>> L1 += L2
>>> L1
[1, 2, 3, 4, 5, 6, 7, 8]
L1 += L2的赋值方式对于可变序列来说(比如这里的列表),性能要好于L1 = L1 + L2的方式。前者直接在L1的原始地址内进行修改,后者新创建一个列表对象并拷贝原始L1列表。但实际上,性能的差距是微乎其微的,前面说过列表中保存的是元素的引用,所以拷贝也仅仅只是拷贝一些引用,而非实际数据对象。
列表是序列,序列类型的每个元素都是按索引位置进行存放的,所以可以通过索引的方式取得列表元素:
>>> L = [1,2,3,4,5]
>>> L[0]
1
>>> L = [
... [1,2,3,4],
... [11,22,33,44],
... [111,222,333,444]
... ]
>>> L[0][2]
3
>>> L[1][2]
33
>>> L[2][2]
333
当然,也可以按索引的方式给给定元素赋值,从而修改列表:
>>> L = [1,2,3,4,5]
>>> L[0] = 11
通过赋值方式修改列表元素时,不仅可以单元素赋值修改,还可以多元素切片赋值。
>>> L[1:3] = [22,33,44,55]
>>> L
[11, 22, 33, 44, 55, 4, 5]
上面对列表的切片进行赋值时,实际上是先取得这些元素,删除它们,并插入新数据的过程。所以上面是先删除[1:3]的元素,再在这个位置处插入新的列表数据。
所以,如果将某个切片赋值为空列表,则表示直接删除这个元素或这段范围的元素。
>>> L
[11, 22, 33, 44]
>>> L[1:3] = []
>>> L
[11, 44]
但如果是将空列表赋值给单个索引元素,这不是表示删除元素,而是表示将空列表作为元素嵌套在列表中。
>>> L = [1,2,3,4]
>>> L[0] = []
>>> L
[[], 2, 3, 4]
这两种列表赋值的区别,在理解了前文所说的列表结构之后应该不难理顺。
列表其它操作
列表是一种序列,所以关于序列的操作,列表都可以用,比如索引、切片、各种序列可用的函数(比如append()、extend()、remove()、del、copy()、pop()、reverse())等。详细内容参见:python序列操作
除了这些序列通用操作,列表还有一个专门的列表方法sort,用于给列表排序。
列表排序sort()和sorted()
sort()是列表类型的方法,只适用于列表;sorted()是内置函数,支持各种容器类型。它们都可以排序,且用法类似,但sort()是在原地排序的,不会返回排序后的列表,而sorted()是返回新的排序列表。
>>> help(list.sort)
Help on method_descriptor:
sort(...)
L.sort(key=None, reverse=False) -> None -- stable sort *IN PLACE*
>>> help(sorted)
Help on built-in function sorted in module builtins:
sorted(iterable, /, *, key=None, reverse=False)
Return a new list containing all items from the iterable in ascending order.
A custom key function can be supplied to customize the sort order, and the
reverse flag can be set to request the result in descending order.
本文仅简单介绍排序用法。
例如列表L:
>>> L = ['python', 'shell', 'Perl', 'Go', 'PHP']
使用sort()和sorted()排序L,注意sort()是对L直接原地排序的,不是通过返回值来体现排序结果的,所以无需赋值给变量。而sorted()则是返回排序后的新结果,需要赋值给变量才能保存排序结果。
>>> sorted(L)
['Go', 'PHP', 'Perl', 'python', 'shell']
>>> L
['python', 'shell', 'Perl', 'Go', 'PHP']
>>> L.sort()
>>> L
['Go', 'PHP', 'Perl', 'python', 'shell']
不难发现,sort()和sorted()默认都是升序排序的(A<B<...<Z<a<b<...<z)。它们都可以指定参数reverse=True来表示顺序反转,也就是默认得到降序:
>>> L.sort(reverse=True)
>>> L
['shell', 'python', 'Perl', 'PHP', 'Go']
在python 3.x中,sort()和sorted()不允许对包含不同数据类型的列表进行排序。也就是说,如果列表中既有数值,又有字符串,则排序操作报错。
sort()和sorted()的另一个参数是key,它默认为key=None,该参数用来指定自定义的排序函数,从而实现自己需要的排序规则。
例如,上面的列表不再按照默认的字符顺序排序,而是想要按照字符串的长度进行排序。所以,自定义这个排序函数:
>>> def sortByLen(s):
... return len(s)
然后通过指定key = sortByLen的参数方式调用sort()或sorted(),在此期间还可以指定reverse = True:
>>> L = ['shell', 'python', 'Perl', 'PHP', 'Go']
>>> sorted(L,key=sortByLen)
['Go', 'PHP', 'Perl', 'shell', 'python']
>>> L.sort(key=sortByLen,reverse=True)
>>> L
['python', 'shell', 'Perl', 'PHP', 'Go']
再例如,按照列表每个元素的第二个字符来排序。
def f(e):
return e[1]
L = ['shell', 'python', 'Perl', 'PHP', 'Go']
sorted(L, key=f)
L.sort(key=f)
更多的排序方式,参见:sorting HOWTO。比如指定两个排序依据,一个按字符串长度升序排,长度相同的按第2个字符降序排。用法其实很简单,不过稍占篇幅,所以本文不解释了。
列表迭代和解析
列表是一个序列,可以使用in测试,使用for迭代。
例如:
>>> L = ["a","b","c","d"]
>>> 'c' in L
True
>>> for i in L:
... print(i)
...
a
b
c
d
再说列表解析,它指的是对序列中(如这里的列表)的每一项元素应用一个表达式,并将表达式计算后的结果作为新的序列元素(如这里的列表)。
通俗一点的解释,以列表序列为例,首先取列表各元素,对每次取的元素都做一番操作,并将操作后得到的结果放进一个新的列表中。
因为解析操作是一个元素一个元素追加到新列表中的,所以也称为"列表推导",表示根据元素推导列表。
最简单的,将字符串序列中的各字符取出来放进列表中:
>>> [ i for i in "abcdef" ]
['a', 'b', 'c', 'd', 'e', 'f']
这里是列表解析,因为它外面使用的是中括号[],表示将操作后的元素放进新的列表中。可以将中括号替换成大括号,就变成了集合解析,甚至字典解析。但注意,没有直接的元组解析,因为元组的括号是特殊的,它会被认为是表达式的优先级包围括号,而不是元组构造符号。
取出元素对各元素做一番操作:
>>> [ i * 2 for i in "abcdef" ]
['aa', 'bb', 'cc', 'dd', 'ee', 'ff']
>>> L = [1,2,3,4]
>>> [ i * 2 for i in L ]
[2, 4, 6, 8]
>>> [ (i * 2, i * 3) for i in L ]
[(2, 3), (4, 6), (6, 9), (8, 12)]
解析操作和for息息相关,且都能改写成for循环。例如,下面两个语句得到的结果是一致的:
[ i * 2 for i in "abcdef" ]
L = []
for i in "abcdef":
L.append(i * 2)
但是解析操作的性能比for循环要更好,正符合越简单越高效的理念。
学过其他语言的人,估计已经想到了,解析过程中对各元素的表达式操作类似于回调函数。其实在python中有一个专门的map()函数,它以第一个参数作为回调函数,并返回一个可迭代对象。也就是说,也能达到和解析一样的结果。例如:
>>> def f(x):return x * 2
...
>>> list(map(f,[1,2,3,4]))
[2, 4, 6, 8]
map()函数在后面的文章会详细解释。
Linux系列文章:https://www.cnblogs.com/f-ck-need-u/p/7048359.html
Shell系列文章:https://www.cnblogs.com/f-ck-need-u/p/7048359.html
网站架构系列文章:http://www.cnblogs.com/f-ck-need-u/p/7576137.html
MySQL/MariaDB系列文章:https://www.cnblogs.com/f-ck-need-u/p/7586194.html
Perl系列:https://www.cnblogs.com/f-ck-need-u/p/9512185.html
Go系列:https://www.cnblogs.com/f-ck-need-u/p/9832538.html
Python系列:https://www.cnblogs.com/f-ck-need-u/p/9832640.html
Ruby系列:https://www.cnblogs.com/f-ck-need-u/p/10805545.html
操作系统系列:https://www.cnblogs.com/f-ck-need-u/p/10481466.html
精通awk系列:https://www.cnblogs.com/f-ck-need-u/p/12688355.html

 浙公网安备 33010602011771号
浙公网安备 33010602011771号