
摘要:
 At first,计算机中绝大部分数据都放到内存中的,不同的数据放到不同的内存区域中。But,内存角度没有数据类型,只有二进制;数据以字节(8位二进制)为单位存取。不同数据类型占据不同的字节,例如在32位系统中:int 为4个字节,short为2个字节(下面如未特殊声明,均为32为系统环境下的说明)。下面我们看看int类型、short类型和double类型的数字分别在内存中如何存储: 阅读全文
At first,计算机中绝大部分数据都放到内存中的,不同的数据放到不同的内存区域中。But,内存角度没有数据类型,只有二进制;数据以字节(8位二进制)为单位存取。不同数据类型占据不同的字节,例如在32位系统中:int 为4个字节,short为2个字节(下面如未特殊声明,均为32为系统环境下的说明)。下面我们看看int类型、short类型和double类型的数字分别在内存中如何存储: 阅读全文
At first,计算机中绝大部分数据都放到内存中的,不同的数据放到不同的内存区域中。But,内存角度没有数据类型,只有二进制;数据以字节(8位二进制)为单位存取。不同数据类型占据不同的字节,例如在32位系统中:int 为4个字节,short为2个字节(下面如未特殊声明,均为32为系统环境下的说明)。下面我们看看int类型、short类型和double类型的数字分别在内存中如何存储: 阅读全文
posted @ 2015-07-18 14:56
EdisonZhou
阅读(2277)
评论(0)
推荐(2)
摘要:
 GCC(GNU Compiler Collection)是一套功能强大、性能优越的编程语言编译器,它是GNU计划的代表作品之一。GCC是Linux平台下最常用的编译器,GCC原名为GNU C Compiler,即GNU C语言编译器,随着GCC支持的语言越来越多,它的名称也逐渐变成了GNU Compiler Collection。下面对GCC的基本使用方法进行介绍。这里我们主要使用Windows系统进行C程序的开发调试,所以我们选择GCC for Windows版本的编译器。 阅读全文
GCC(GNU Compiler Collection)是一套功能强大、性能优越的编程语言编译器,它是GNU计划的代表作品之一。GCC是Linux平台下最常用的编译器,GCC原名为GNU C Compiler,即GNU C语言编译器,随着GCC支持的语言越来越多,它的名称也逐渐变成了GNU Compiler Collection。下面对GCC的基本使用方法进行介绍。这里我们主要使用Windows系统进行C程序的开发调试,所以我们选择GCC for Windows版本的编译器。 阅读全文
GCC(GNU Compiler Collection)是一套功能强大、性能优越的编程语言编译器,它是GNU计划的代表作品之一。GCC是Linux平台下最常用的编译器,GCC原名为GNU C Compiler,即GNU C语言编译器,随着GCC支持的语言越来越多,它的名称也逐渐变成了GNU Compiler Collection。下面对GCC的基本使用方法进行介绍。这里我们主要使用Windows系统进行C程序的开发调试,所以我们选择GCC for Windows版本的编译器。 阅读全文
posted @ 2015-07-18 13:21
EdisonZhou
阅读(2854)
评论(1)
推荐(2)
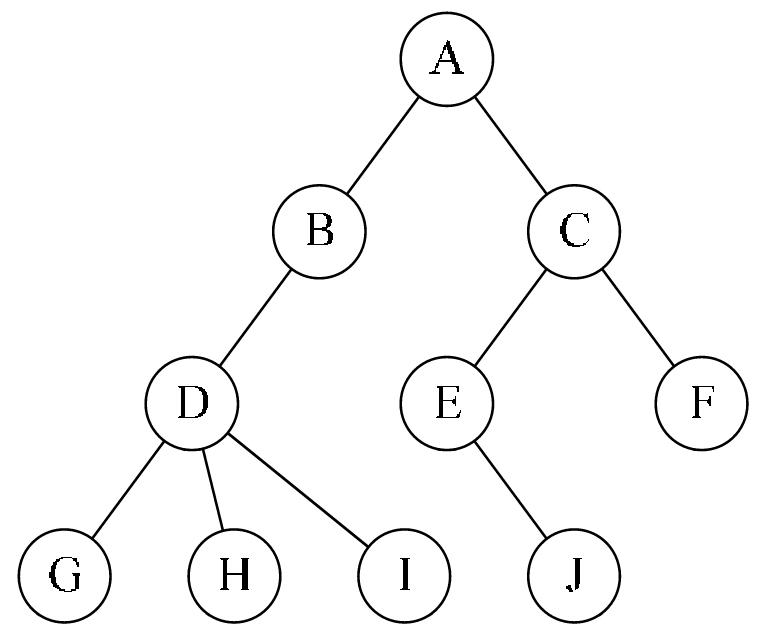 上面两篇我们了解了树的基本概念以及二叉树的遍历算法,还对二叉查找树进行了模拟实现。数学表达式求值是程序设计语言编译中的一个基本问题,表达式求值是栈应用的一个典型案例,表达式分为前缀、中缀和后缀三种形式。这里,我们通过一个四则运算的应用场景,借助二叉树来帮助求解表达式的值。首先,将表达式转换为二叉树,然后通过先序遍历二叉树的方式求出表达式的值。
上面两篇我们了解了树的基本概念以及二叉树的遍历算法,还对二叉查找树进行了模拟实现。数学表达式求值是程序设计语言编译中的一个基本问题,表达式求值是栈应用的一个典型案例,表达式分为前缀、中缀和后缀三种形式。这里,我们通过一个四则运算的应用场景,借助二叉树来帮助求解表达式的值。首先,将表达式转换为二叉树,然后通过先序遍历二叉树的方式求出表达式的值。  最近看了看一个C#游戏开发的公开课,在该公开课中使用面向对象思想与Unity3D游戏开发思想结合的方式,对一个简单的赛车游戏场景进行了实现。原本在C#中很方便地就可以完成的一个小场景,使用Unity3D的设计思想(即一切游戏对象皆空对象,拖拽组件才使其具有了活力)来实现却需要花费大量时间与精力,究竟它神奇在什么地方?本文通过实现这个小例子来看看。
最近看了看一个C#游戏开发的公开课,在该公开课中使用面向对象思想与Unity3D游戏开发思想结合的方式,对一个简单的赛车游戏场景进行了实现。原本在C#中很方便地就可以完成的一个小场景,使用Unity3D的设计思想(即一切游戏对象皆空对象,拖拽组件才使其具有了活力)来实现却需要花费大量时间与精力,究竟它神奇在什么地方?本文通过实现这个小例子来看看。  在日常生活中,队列的例子比比皆是,例如在车展排队买票,排在队头的处理完离开,后来的必须在队尾排队等候。在程序设计中,队列也有着广泛的应用,例如计算机的任务调度系统、为了削减高峰时期订单请求的消息队列等等。与栈类似,队列也是属于操作受限的线性表,不过队列是只允许在一端进行插入,在另一端进行删除。在其他数据结构如树的一些基本操作中(比如树的广度优先遍历)也需要借助队列来实现,因此这里我们来看看队列。
在日常生活中,队列的例子比比皆是,例如在车展排队买票,排在队头的处理完离开,后来的必须在队尾排队等候。在程序设计中,队列也有着广泛的应用,例如计算机的任务调度系统、为了削减高峰时期订单请求的消息队列等等。与栈类似,队列也是属于操作受限的线性表,不过队列是只允许在一端进行插入,在另一端进行删除。在其他数据结构如树的一些基本操作中(比如树的广度优先遍历)也需要借助队列来实现,因此这里我们来看看队列。 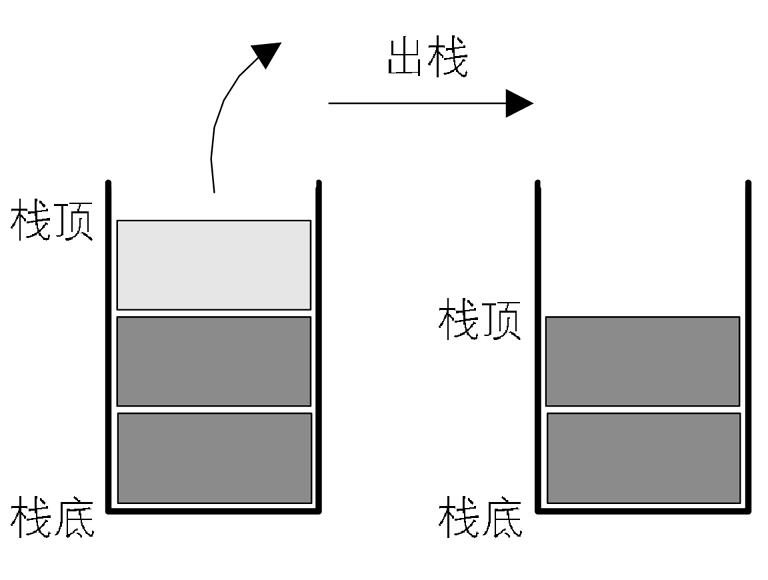 现实生活中的事情往往都能总结归纳成一定的数据结构,例如餐馆中餐盘的堆叠和使用,羽毛球筒里装的羽毛球等都是典型的栈结构。而在.NET中,值类型在线程栈上进行分配,引用类型在托管堆上进行分配,本文所说的“栈”正是这种数据结构。栈和队列都是常用的数据结构,它们的逻辑结构与线性表相通,不同之处则在于操作受某种特殊限制。因此,栈和队列也被称为操作受限的线性表。这里,我们首先来了解一下栈。
现实生活中的事情往往都能总结归纳成一定的数据结构,例如餐馆中餐盘的堆叠和使用,羽毛球筒里装的羽毛球等都是典型的栈结构。而在.NET中,值类型在线程栈上进行分配,引用类型在托管堆上进行分配,本文所说的“栈”正是这种数据结构。栈和队列都是常用的数据结构,它们的逻辑结构与线性表相通,不同之处则在于操作受某种特殊限制。因此,栈和队列也被称为操作受限的线性表。这里,我们首先来了解一下栈。  在上一篇中,我们了解了单链表与双链表,本次将单链表中终端结点的指针端由空指针改为指向头结点,就使整个单链表形成一个环,这种头尾相接的单链表称为单循环链表,简称循环链表(circular linked list)。循环链表和单链表的主要差异就在于循环的判断条件上,原来是判断p.next是否为空,现在则是p.next不等于头结点,则循环未结束。本文还会使用循环链表以及.NET中内置的LinkedList解决约瑟夫问题。
在上一篇中,我们了解了单链表与双链表,本次将单链表中终端结点的指针端由空指针改为指向头结点,就使整个单链表形成一个环,这种头尾相接的单链表称为单循环链表,简称循环链表(circular linked list)。循环链表和单链表的主要差异就在于循环的判断条件上,原来是判断p.next是否为空,现在则是p.next不等于头结点,则循环未结束。本文还会使用循环链表以及.NET中内置的LinkedList解决约瑟夫问题。  Hadoop2相比较于Hadoop1.x来说,HDFS的架构与MapReduce的都有较大的变化,且速度上和可用性上都有了很大的提高,Hadoop2中有两个重要的变更:
(1)HDFS的NameNode可以以集群的方式布署,增强了NameNodes的水平扩展能力和高可用性,分别是:HDFS Federation与HA;
(2)MapReduce将JobTracker中的资源管理及任务生命周期管理(包括定时触发及监控),拆分成两个独立的组件,并更名为YARN(Yet Another Resource Negotiator);
Hadoop2相比较于Hadoop1.x来说,HDFS的架构与MapReduce的都有较大的变化,且速度上和可用性上都有了很大的提高,Hadoop2中有两个重要的变更:
(1)HDFS的NameNode可以以集群的方式布署,增强了NameNodes的水平扩展能力和高可用性,分别是:HDFS Federation与HA;
(2)MapReduce将JobTracker中的资源管理及任务生命周期管理(包括定时触发及监控),拆分成两个独立的组件,并更名为YARN(Yet Another Resource Negotiator);  一、为何要学习Hadoop? 这是一个信息爆炸的时代。经过数十年的积累,很多企业都聚集了大量的数据。这些数据也是企业的核心财富之一,怎样从累积的数据里寻找价值,变废为宝炼数成金成为当务之急。但数据增长的速度往往比cpu和内存性能增长的速度还要快得多。要处理海量数据,如果求助于昂贵的专用主机甚至超级计
一、为何要学习Hadoop? 这是一个信息爆炸的时代。经过数十年的积累,很多企业都聚集了大量的数据。这些数据也是企业的核心财富之一,怎样从累积的数据里寻找价值,变废为宝炼数成金成为当务之急。但数据增长的速度往往比cpu和内存性能增长的速度还要快得多。要处理海量数据,如果求助于昂贵的专用主机甚至超级计  浙公网安备 33010602011771号
浙公网安备 33010602011771号