cloudpickle —— Python分布式序列化的专用模块
给出cloudpickle的GitHub地址:
https://github.com/cloudpipe/cloudpickle
=======================================================
单机的Python序列化模块有自带的pickle,但是在Python的分布式计算中进行序列化则是使用cloudpickle。之所以在分布式计算中Python的序列化使用cloudpickle模块的原因有:
1. cloudpickle是使用value序列化的方式,而pickle则是使用reference序列化的方式。因此在反序列化时pickle需要运行环境内存在序列化对象的定义,因为pickle进行序列化的只是对象(函数、类对象)的参数;而cloudpickle在序列化时会把对象的定义和参数值一并序列化,所以在分布式计算中传递cloudpickle序列化对象时接受方可以没有对象的定义(如果序列化的是类对象,那么接收方可以没有类的定义)。
例子:
import pickle class A():pass a=A() a_pick = pickle.dumps(a) a_unpick = pickle.loads(a_pick) print(a_unpick) del A b_unpick = pickle.loads(a_pick)

import cloudpickle as pickle class A():pass a=A() a_pick = pickle.dumps(a) a_unpick = pickle.loads(a_pick) print(a_unpick) del A b_unpick = pickle.loads(a_pick)

--------------------------------------------------------
import cloudpickle, pickle CONSTANT = 42 def my_function(data: int) -> int: return data + CONSTANT pickled_function = cloudpickle.dumps(my_function) pickled_function_2 = pickle.dumps(my_function) CONSTANT = 0 depickled_function = cloudpickle.loads(pickled_function) depickled_function_2 = pickle.loads(pickled_function_2) print(depickled_function(43)) print(depickled_function_2(43))

2. pickle模块不能序列化lambda函数,cloudpickle可以序列化lambda函数。
例子:
import pickle squared = lambda x: x ** 2 pickled_lambda = pickle.dumps(squared) new_squared = pickle.loads(pickled_lambda) new_squared(2)

import cloudpickle as pickle squared = lambda x: x ** 2 pickled_lambda = pickle.dumps(squared) new_squared = pickle.loads(pickled_lambda) new_squared(2)

===========================================
从上面的例子可以看出,cloudpickle更像是打包序列化,在序列化一个对象时会把该对象设计到的参数和定义也一并打包进行序列化。那么cloudpickle有没有打包不了的对象呢,这个确实还是有的,那就是序列化对象(函数、类对象)中如果包含有import语句的并不会把import语句中所涉及的对象进行一并打包。对于cloudpickle不能把序列化对象中包含的import引入的对象一并打包这个事情我个人的观点是其实现的难点在于import对象中会涉及大量的对象,这样进行一并打包要包含哪些对象难以确定、并且全部打包也是会造成序列化后对象字节码过长、序列化用时过长等问题。
例子:
模块: another_module.py

def g(): print("hello world") return 100
模块 x.py:
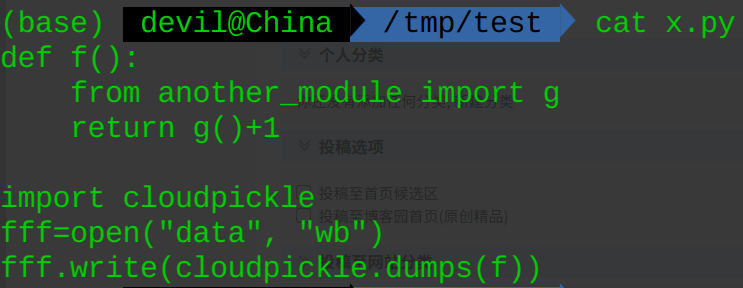
def f(): from another_module import g return g()+1 import cloudpickle fff=open("data", "wb") fff.write(cloudpickle.dumps(f))
运行 x.py,把序列化后字节数据存入data文件中:
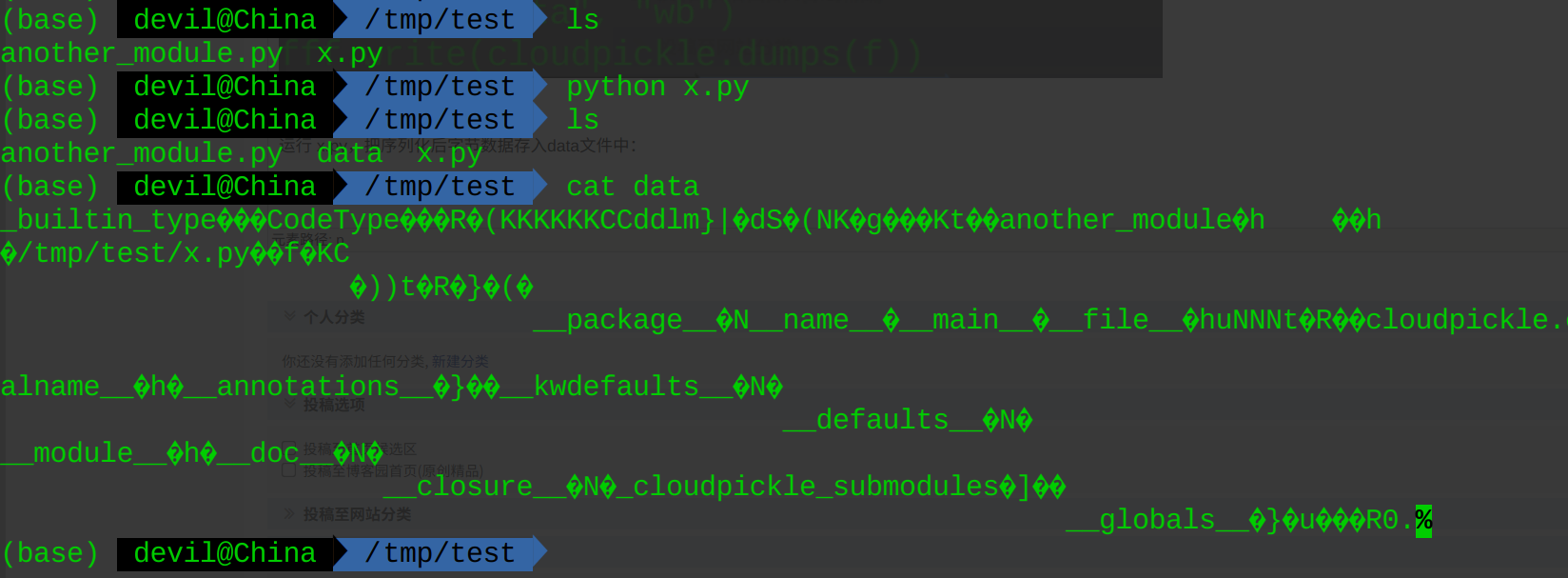
----------------------------------
给出反序列化文件 y.py:
import cloudpickle fff=open("data", "rb") f = cloudpickle.loads(fff.read()) f()
如果把序列化文件data和反序列化文件y.py放在另一个单独的文件夹中并运行y.py,结果如下:
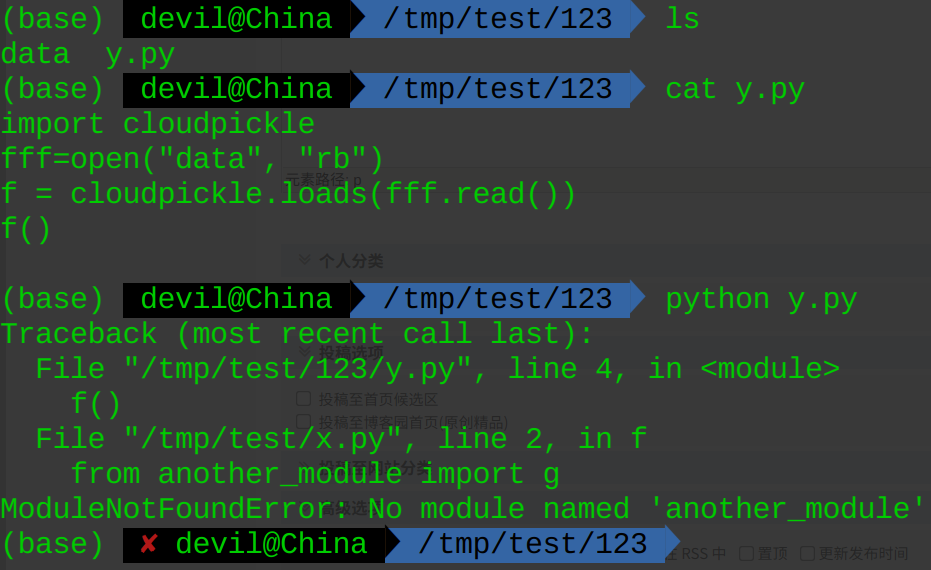
可以看到,使用cloudpickle并没有把涉及到的import语句中引入的对象进行一并的打包序列化。
PS: cloudpickle的底层实现依旧是调用pickle模块,可以说cloudpickle模块是对pickle模块的进一步包装,其实现的功能就是把pickle序列化中没有打包的对象以value的形式进行一并打包。
====================================================
posted on 2022-12-14 15:08 Angry_Panda 阅读(1834) 评论(4) 收藏 举报


 浙公网安备 33010602011771号
浙公网安备 33010602011771号