线段树详解
之后很长一段时间都不会怎么深度碰 OI 了,防止哪天自己忘掉。
作用
线段树是算法竞赛中常用的用来维护区间信息的数据结构。
线段树可以在 \(\mathcal O\left(\log n\right)\) 的时间复杂度内实现单点修改、区间修改、区间查询(区间求和,求区间最大值,求区间最小值)等操作。
原理(维护区间和)
虽然,我觉得叫“区间树”更为合理,然而几乎所有人都叫“线段树”......
例题 \(1\)。
已知一个数列,你需要进行下面两种操作:
- 将某区间每一个数加上 \(k\)。
- 求出某区间每一个数的和。
以区间和为例。
初始时给出序列 \(a[1...n]\)。
基本结构

如图,线段树将原区间 \([1,7]\) 拆成 \([1,4],[5,7]\),\([1,4]\) 又拆成 \([1,2],[3,4]\)......直到拆成区间大小为 \(1\)。
存储
完全二叉树
我们使用一个数组 \(t\) 存储线段树。
那么对于每一个元素 \(t[i]\) 维护一个区间,需要维护的值有 \(l,r,sum,tag\),\(sum\) 表示区间 \([l,r]\) 的和,\(tag\) 见懒标记。(\(l,r\) 可以不维护,具体见题解:色板游戏的“\(30\) 棵线段树”的 AC 代码)。
我们在 \(t\) 上建一棵树。
令 \(mid=\left\lfloor\dfrac{t[i].l+t[i].r}{2}\right\rfloor\),那么 \(t[i]\) 的左子节点维护区间 \([l,mid]\) 的信息,右子节点维护区间 \([mid+1,r]\) 的信息。
现在的问题就是如何找到左右子节点。
考虑建一棵完全二叉树,那么我们对于 \(t[i]\),仅仅需要访问 \(t[i\times 2],t[i\times 2+1]\) 即可。
注意,整个 \(t\) 数组构成的树是一棵满二叉树。
\(4\) 倍数组空间
当 \(n\) 为 \(2\) 的正整数次幂时,显然是最优情况——此时整个线段树为一棵有效的满二叉树。
此时的节点总数就是 \(1+2+4+ \cdots + \dfrac{n}{2} + n=2n-1\)。

那么我们考虑最劣情况:\(n=2^k+1\),其中 \(k\) 为自然数。

此时就会多开一层,最底层的节点个数为 \(\left \lceil \log_2n \right \rceil=2(n-1)=2n-2\)。
那么总节点个数便是 \(1+2+4+\cdots \dfrac{2n-2}{2} + (2n-2)=2(2n-2)-1=4n-5\)。
因此一般来讲,线段树会开 \(4\) 倍数组空间。
如果你想省点空间,那就是 \(2\times \left \lceil \log_2n \right \rceil -1\)。
参考代码
const int N=1e5;
struct node{
int l,r;
ll sum,tag;
}t[4*N+1];
建树
树型结构,考虑递归。
定义递归函数 \(build(p,l,r)\),表示 \(t[p]\) 维护区间 \([l,r]\)。
那么就有 \(t[p].l=l,t[p].r=r\),而 \(t[p].sum\) 即 \(t[p\times 2].sum+t[p\times 2+1].sum\)。
但是明显在执行 \(build(p,l,r)\) 时,我们并不知道 \(t[p\times2].sum,t[p\times2+1].sum\),因此我们需要先递归建出左右子树。
令 \(mid=mid=\left\lfloor\dfrac{l+r}{2}\right\rfloor\) ,则先执行 \(build(p\times 2,l,mid),build(p\times 2+1,mid+1,r)\)。
那么递归边界如上图所述,即 \(l=r\) 时,显然 \(t[p].sum=a[l]\)。
定义函数 \(up(p)\),表示可以更新 \(t[p]\),其内容就是 \(t[p].sum=t[p\times 2].sum+t[p\times 2+1].sum\)。
参考代码
void up(int p){
t[p].sum=t[p*2].sum+t[p*2+1].sum;
}
void build(int p,int l,int r){
t[p].l=l,t[p].r=r;
if(l==r)t[p].sum=a[l];
else{
int mid=(l+r)/2;
build(p*2,l,mid);
build(p*2+1,mid+1,r);
up(p);
}
}
注意:根节点为 \(t[1]\)。
区间修改
懒标记
懒标记是什么?
首先我们不可能在 \(t\) 上找到所有的满足 \(t[i].l=t[i].r \land l \leq t[i].l \leq r\) 的 \(i\),然后去修改以后向上递归执行 \(up(i)\) 一直到根节点 \(1\)——这样的效率甚至不如朴素 \(\mathcal O(n)\)。
因此引入了懒标记。
定义函数 \(add(p,l,r,k)\) 表示将区间 \([l,r]\) 加上 \(k\),\(p\) 仍然作为 \(t[p]\) 的下标,详见下文。
\(add(p,l,r,k)\) 是递归执行的。
在递归的过程中,如果出现了 \(t[p].l \leq l\leq r\leq t[p].r\),那么我们直接:
其中,\(size(p)\) 表示区间 \(\left[t[p].l,t[p].r\right]\) 的大小,具体而言就是 \(size(p)=t[p].r-t[p].l+1\)。
代码:
int size(int p){
return t[p].r-t[p].l+1;
}
解释一下 \(t[p].tag\) 的含义:\(t[p]\) 的左、右子树未进行的加法操作所需加的数,初始值为 \(0\)。
这样,\(p\) 的子树便不需要继续递归。
那么复杂度为什么是 \(\mathcal O\left(\log n\right)\) 呢?
首先,考虑到完全二叉树的性质,树高为 \(\mathcal O\left(\log n\right)\)。
先说结论:每一层至多访问 \(4\) 个节点。
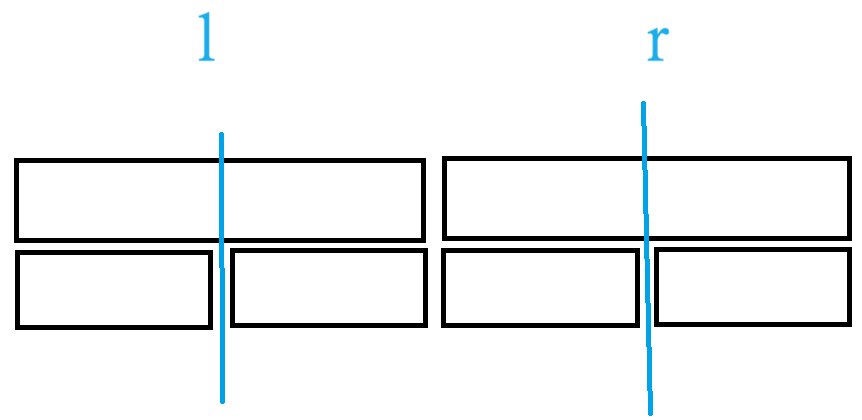
如上。
关于正确性,考虑反证。假设能够访问到至少 \(5\) 个节点。
则如图:

根本不会访问到 \(a,b\),因为在节点 \(c\) 时便已经由于懒标记停止递归了。
如若 \(t[p].l \leq l\leq r\leq t[p].r\) 不成立,我们就需要分别看看左右子树的覆盖区间是否与 \([l,r]\) 重合,重合了就递归,否则不执行。
懒标记下传
定义函数 \(down(p)\) 来下传懒标记。
那么在 \(add(p,l,r,k)\) 递归之前一定要下传懒标记。
因为在下传懒标记之前,其祖先的 \(tag\) 不为 \(0\),则该节点的 \(sum\) 值是不可信的,而在 \(add(p,l,r,k)\) 的最后会 \(up(p)\) 来更新 \(t[p]\) 加完之后新的区间和,因此子节点的 \(sum\) 值必须是真实的,因此一定要下传。
区间和的懒标记下传也很简单,对于 \(sum\),就是加上区间大小乘懒标记;对于 \(tag\),直接加上懒标记即可。
下传后清空懒标记(置 \(0\))。
参考代码
void down(int p){
if(t[p].tag){
t[2*p].sum+=size(2*p)*t[p].tag;
t[2*p].tag+=t[p].tag;
t[2*p+1].sum+=size(2*p+1)*t[p].tag;
t[2*p+1].tag+=t[p].tag;
t[p].tag=0;
}
}
void add(int p,int l,int r,int k){
if(l<=t[p].l&&t[p].r<=r){
t[p].sum+=size(p)*k;//一定不要忘记乘size!
t[p].tag+=k;
}else{
down(p);
if(l<=t[p*2].r)add(p*2,l,r,k);
if(t[p*2+1].l<=r)add(p*2+1,l,r,k);
up(p);//不要忘记上传更新
}
}
区间查询
与区间修改类似,定义函数 \(query(p,l,r)\) 表示区间 \(a[l,r]\) 的和,那么当 \(l\leq t[p].l \leq t[p].r \leq r\) 时,有 \(query(p,l,r)=t[p].sum\)。
否则判断左、右子区间是否与区间 \([l,r]\) 重合,有则递归查询,最后返回答案即可。
参考代码
typedef long long ll;
//...
ll query(int p,int l,int r){
if(l<=t[p].l&&t[p].r<=r)return t[p].sum;
down(p);
ll ans=0;
if(l<=t[p*2].r)ans+=query(p*2,l,r);
if(t[p*2+1].l<=r)ans+=query(p*2+1,l,r);
//此处可以不上传更新,因为根本没有更新
return ans;
}
线段树 1 AC 代码
//#include<bits/stdc++.h>
#include<algorithm>
#include<iostream>
#include<cstring>
#include<iomanip>
#include<cstdio>
#include<string>
#include<vector>
#include<cmath>
#include<ctime>
#include<deque>
#include<queue>
#include<stack>
#include<list>
using namespace std;
typedef long long ll;
const int N=1e5;
struct node{
int l,r;
ll sum,tag;
}t[4*N+1];
int n,m,a[N+1];
void up(int p){
t[p].sum=t[p*2].sum+t[p*2+1].sum;
}
void build(int p,int l,int r){
t[p].l=l,t[p].r=r;
if(l==r)t[p].sum=a[l];
else{
int mid=(l+r)/2;
build(p*2,l,mid);
build(p*2+1,mid+1,r);
up(p);
}
}
int size(int p){
return t[p].r-t[p].l+1;
}
void down(int p){
if(t[p].tag){
t[2*p].sum+=size(2*p)*t[p].tag;
t[2*p].tag+=t[p].tag;
t[2*p+1].sum+=size(2*p+1)*t[p].tag;
t[2*p+1].tag+=t[p].tag;
t[p].tag=0;
}
}
void add(int p,int l,int r,int k){
if(l<=t[p].l&&t[p].r<=r){
t[p].sum+=size(p)*k;//一定不要忘记乘size!
t[p].tag+=k;
}else{
down(p);
if(l<=t[p*2].r)add(p*2,l,r,k);
if(t[p*2+1].l<=r)add(p*2+1,l,r,k);
up(p);//不要忘记上传更新
}
}
ll query(int p,int l,int r){
if(l<=t[p].l&&t[p].r<=r)return t[p].sum;
down(p);
ll ans=0;
if(l<=t[p*2].r)ans+=query(p*2,l,r);
if(t[p*2+1].l<=r)ans+=query(p*2+1,l,r);
//此处可以不上传更新,因为根本没有更新
return ans;
}
int main(){
/*freopen("test.in","r",stdin);
freopen("test.out","w",stdout);*/
scanf("%d %d",&n,&m);
for(int i=1;i<=n;i++)scanf("%d",a+i);
build(1,1,n);
while(m--){
int op,x,y,k;
scanf("%d %d %d",&op,&x,&y,&k);
switch(op){
case 1:
scanf("%d",&k);
add(1,x,y,k);
break;
case 2:
printf("%lld\n",query(1,x,y));
break;
}
}
/*fclose(stdin);
fclose(stdout);*/
return 0;
}
维护区间最值
这适用于动态更改的区间最值,否则直接使用 ST 表 即可。
具体而言,就是对于节点 \(t[p]\),维护 \(l,r,tag,max\),\(max\) 表示区间 \([l,r]\) 的最大值,\(tag\) 是懒标记表示区间赋值为 \(tag\),初始值可以设为一个值域之外的数(比如 \(10^9+1\))。
那么在 \(down(p)\) 时就是判断如果 \(tag\) 在值域之内,就有:
而 \(up(p)\) 即:
例题 2:线段树 2
已知一个数列,你需要进行下面三种操作:
- 将某区间每一个数乘上 \(x\);
- 将某区间每一个数加上 \(x\);
- 求出某区间每一个数的和。
懒标记
需要支持两个操作,一个是乘法,一个是加法。
在此题中,明显需要打两个懒标记,不妨令 \(tag_1\) 表示乘法初始值为 \(1\),\(tag_2\) 表示加法初始值为 \(0\)。
那么运算顺序就变得重要了,我们采取先乘后加——这也是四则运算的顺序。
也就是说,对于一个节点 \(t[p]\) 的子节点 \(t[q]\),有:
懒标记更新
这是个问题。
对于一个节点 \(t[p]\) 的子节点 \(t[q]\),我们知道了如何处理 \(t[q].value\),还要更新 \(t[q].tag_1,t[q].tag_2\)。
我们不妨考虑一下 \(t[q]\) 的子节点 \(t[x]\)。
那么先将 \(t[q]\) 的懒标记下传,有:
此时我们清空 \(t[q]\) 的懒标记后再下传 \(t[p]\) 的懒标记,有:
那么稍微回代一下,就有:
很明显,即:
于是一个 \(down(p)\) 就写完了。
对于 \(up(p)\),仍然是区间和。
AC 代码
//#include<bits/stdc++.h>
#include<algorithm>
#include<iostream>
#include<cstring>
#include<iomanip>
#include<cstdio>
#include<string>
#include<vector>
#include<cmath>
#include<ctime>
#include<deque>
#include<queue>
#include<stack>
#include<list>
using namespace std;
typedef long long ll;
const ll N=1e5;
struct node{
//tag_1:乘法标记,tag_2:加法标记
ll l,r,value,tag_1,tag_2;
}t[4*N+1];
ll n,q,M;
ll a[N+1];
inline void up(ll p){
t[p].value=t[p*2].value+t[p*2+1].value;
t[p].value%=M;
}
void build(ll p,ll l,ll r){
t[p].l=l,t[p].r=r,t[p].tag_1=1;
if(l==r)t[p].value=a[l];
else{
ll mid=(l+r)/2;
build(p*2,l,mid);
build(p*2+1,mid+1,r);
up(p);
}
}
inline ll size(ll p){
return t[p].r-t[p].l+1;
}
inline void down(ll p){
t[p*2].value=(t[p*2].value * t[p].tag_1 + size(p*2)*t[p].tag_2)%M;
t[p*2].tag_1=t[p*2].tag_1*t[p].tag_1%M;
t[p*2].tag_2=(t[p*2].tag_2*t[p].tag_1+t[p].tag_2)%M;
t[p*2+1].value=(t[p*2+1].value * t[p].tag_1 + size(p*2+1)*t[p].tag_2)%M;
t[p*2+1].tag_1=t[p*2+1].tag_1*t[p].tag_1%M;
t[p*2+1].tag_2=(t[p*2+1].tag_2*t[p].tag_1+t[p].tag_2)%M;
t[p].tag_1=1;
t[p].tag_2=0;
}
//乘法
void solve1(ll p,ll l,ll r,ll k){
if(l<=t[p].l&&t[p].r<=r){
t[p].value*=k;
t[p].value%=M;
t[p].tag_1*=k;
t[p].tag_1%=M;
t[p].tag_2*=k;
t[p].tag_2%=M;
}else{
down(p);
ll mid=(t[p].l+t[p].r)/2;
if(l<=mid)solve1(p*2,l,r,k);
if(mid<r)solve1(p*2+1,l,r,k);
up(p);
}
}
//加法
void solve2(ll p,ll l,ll r,ll k){
if(l<=t[p].l&&t[p].r<=r){
t[p].value+=size(p)*k;
t[p].value%=M;
t[p].tag_2+=k;
t[p].tag_2%=M;
}else{
down(p);
ll mid=(t[p].l+t[p].r)/2;
if(l<=mid)solve2(p*2,l,r,k);
if(mid<r)solve2(p*2+1,l,r,k);
up(p);
}
}
ll query(ll p,ll l,ll r){
if(l<=t[p].l&&t[p].r<=r)return t[p].value;
down(p);
ll mid=(t[p].l+t[p].r)/2,ans=0;
if(l<=mid)ans+=query(p*2,l,r);
ans%=M;
if(mid<r)ans+=query(p*2+1,l,r);
ans%=M;
return ans;
}
main(){
/*freopen("test.in","r",stdin);
freopen("test.out","w",stdout);*/
scanf("%lld %lld %lld",&n,&q,&M);
for(ll i=1;i<=n;i++)scanf("%lld",a+i),a[i]%=M;
build(1,1,n);
while(q--){
ll op,x,y;
ll k;
scanf("%lld %lld %lld",&op,&x,&y);
switch(op){
case 1:
scanf("%lld",&k);
solve1(1,x,y,k%M);
break;
case 2:
scanf("%lld",&k);
solve2(1,x,y,k%M);
break;
case 3:
printf("%lld\n",query(1,x,y));
break;
}
}
/*fclose(stdin);
fclose(stdout);*/
return 0;
}
例题
[AHOI2009] 维护序列
几乎与线段树 2 一模一样。
中位数
本来可以使用权值线段树求解,然而考虑到不如“权值树状数组+倍增/二分答案”,且存在对顶堆甚至是“插入排序”等方法,此处不再给出代码。
详见“题解:中位数”。
无聊的数列
见“题解:无聊的数列”。
色板游戏
见“题解:色板游戏”。
贪婪大陆
见“题解:贪婪大陆”
标记永久化
所谓“标记永久化”,是因为有些时候懒标记上传、下传都不那么方便,这种时候就可以使用标记永久化解决。
标记永久化流程:
-
设修改区间为 \([L,R]\)。
修改时,若 \([l,r]\subseteq[L,R]\),则可以更新对应节点的标记 \(\textit{tag}\)。
否则若 \([l,r]\cap[L,R]\neq\varnothing\),则更新对应节点的值 \(\textit{value}\)。
-
设查询区间为 \([L,R]\)。
查询时,若 \([l,r]\subseteq[L,R]\),则答案就是对应节点的值 \(\textit{value}\)。
否则若 \([l,r]\cap[L,R]\neq\varnothing\),则对应节点的答案是 \([l,r]\) 的 \(\textit{tag}\) 在 \([l,r]\cap[L,R]\) 上的贡献与左右子区间答案之和。
过于抽象。
标记永久化常用于树套树/可持久化。
以维护区间和为例。
void add(int p,int l,int r,ll k){
t[p].value+=(min(r,t[p].r)-max(l,t[p].l)+1)*k;
if(l<=t[p].l&&t[p].r<=r){
t[p].tag+=k;
return;
}
if(l<=t[p<<1].r){
add(p<<1,l,r,k);
}
if(t[p<<1|1].l<=r){
add(p<<1|1,l,r,k);
}
}
ll query(int p,int l,int r){
if(l<=t[p].l&&t[p].r<=r){
return t[p].value;
}
ll ans=(min(t[p].r,r)-max(t[p].l,l)+1)*t[p].tag;
if(l<=t[p<<1].r){
ans+=query(p<<1,l,r);
}
if(t[p<<1|1].l<=r){
ans+=query(p<<1|1,l,r);
}
return ans;
}
线段树合并
一般合并动态开点权值线段树,且两棵树的根节点区间相同,对应节点也相同。可以做到 \(\mathcal O(n\log n)\) 合并。
参见此处。
总结
事实上,线段树最难的部分就是设计状态与状态转移,尤其是懒标记。
也就是设计 \(down(p)\)。
只能说还是要多练,熟能生巧。
而且线段树确实灵活,但是也确实容易写错,以后要多注意。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号